1. 绪论
1.1. 研究背景
随着现代化水平的迅速提高,安全监控系统在生活中的应用越来越普遍。目前,监控系统主要依赖于视频信息来进行监控,但是基于视频的系统存在一些问题。相比图像信号,声音信号的计算量较小,包含更多信息,并且更具隐私性。此外,音频设备相对简单且稳定性较高,异常声音能够有效地揭示异常情况和突发事件,从而弥补视频监控的不足。音频监控系统通过检测和识别区域内的声音信息来进行监控,实现更高的自动化和智能化,对于智能监控系统和安全防护至关重要。近年来,工业机器在国防建设、石油化工、电力部门以及日常生活的交通出行中得到了广泛应用。各种工业机器不断朝着集成化、大型化和一体化的方向发展,它们的结构变得越来越复杂。一旦出现故障,不仅设备会失效,还可能导致巨大的经济损失和严重的安全事故。声音异常检测可以及时准确地判断机器是否发生故障,提前预测和处理潜在的故障状态,预防性地维护可能出现的故障,从而减少维修成本和支出。此外,通过实时监测和定期检查机器状态,可以在不影响整体生产的情况下进行维修,防止故障进一步恶化,延长机械设备的使用寿命,最大化使用效率。声音异常检测还能了解机器运行状态的变化,确保机器连续稳定地工作,有助于更精确地管理和控制机器。
1.2. 研究现状
为了可以通过提取机器运行的声音特征来判断机器是否出现问题。在最近的几年的研究中,从模型角度出发对声音识别的研究可以分为3类:① 将其底层声学特征输入到通用背类模型GMM-UBM [1] [2] 中,建立对应语种的识别模型以进行识别 [3] 。② 基于端到端的语种识别模型,提取深度语种特征并进行识别。③将声学特征图像化,借助卷积神经网络进行语种识别库设置和帧移动下的语种识别 [4] 。从特征角度出发对语种识别进行研究的学者则使用梅尔频率倒谱系数(MFCC, Me-scale frequency cepstral coefficients) [5] ,伽马频率倒谱系数(GFCC, Gammatone frequency cepstral coefficients) [6] 等单一声学特征进行语种识别。但在这些年的发展中,研究者们也不仅仅将目光局限在单一的方法之中,从而出现了很多具有融合特征的方法 [7] - [13] ,例如孙颖团队将MFCC和韵律的特征融合 [7] ;张科团队将MFCC和GFCC特征融合 [8] ;MTS等将MFCC和能量归一化倒诺系数(PNCC, power normalized cepstral coefficient)融合 [9] ,从而进行语音识别。但以上融合特征的方法仍然有着诸多缺陷,比如这些方法都是利用提升特征的维度但牺牲了算力来提升语种识别性能。所以也有很多研究者开始转向如何在融合特征的基础上并且降维提高高噪声下的音频识别速率和准确率 [14] [15] [16] 。如周萍,沈昊,郑凯鹏的基于MFCC与GFCC混合特征参数的说话人识别 [14] ,Anirban,Bhowmick的基于奇异值分解的特征嵌入的印度区域语言的识别 [15] ,邵玉斌,刘晶,龙华,等的面向实噪声环境的语种识别 [16] 。
2. 相关理论和技术
2.1. 特征提取
MFSC (log Mel-frequency spectral coefficients)的提取过程包括预处理、快速傅里叶变换、Mel滤波器组、对数运算、动态特征提取共五个步骤:
① 预处理过程:是对其原始音频数据进行数字化、预滤波、预加重、端点检测、分帧、加窗等操作,使其信号特征更加明显,去除冗余数据。
(1)
② 快速傅里叶变换过程:快速傅里叶变换即利用计算机计算离散傅里叶变换(DFT)的高效、快速计算方法的统称,简称FFT。将音频从时域转换为频域。
(2)
③ Mel滤波器组过程:研究表明,人类对频率的感知并不是线性的,并且对低频信号的感知要比高频信号敏感。对1 kHz以下,与频率成线性关系,对1 kHz以上,与频率成对数关系。频率越高,感知能力就越差。为了模拟人耳的听觉机制。从而研制出来了Mel滤波器组。所以,Mel滤波器组的在低频密集,高频稀疏。
(3)
④ 对数运算:对数运算包括取模和log运算。将原始语音信号经过傅里叶变换得到频谱:取模是仅使用幅度值,忽略相位的影响,因为相位信息在语音识别中作用不大。log运算是为了分别包络和细节,包络代表音色,细节代表音高。显然语音识别是为了识别音色。另外,人的感知与频域的对数成正比,正好使用log运算对上述梅尔语谱图的纵轴进行对数缩放,可以放大低频率处的能量差异。
⑤ 动态特征提取:标准的倒谱参数MFSC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。实验证明:把动、静态特征结合起来才能有效提高系统的识别性能。差分参数的计算可以采用下面的公式:
(4)
其中,dt表示第t个一阶差分,Ct表示第t个倒谱系数,Q表示倒谱系数的阶数,K表示一阶导数的时间差,可取1或2。将上式的结果再代入就可以得到二阶差分的参数。
因此,MFSC的全部组成其实是由:N维MFSC参数(N/3个MFSC系数 + N/3个一阶差分参数 + N/3个二阶差分参数) + 帧能量(此项可根据需求替换)。这里的帧能量是指一帧的音量(即能量),也是语音的重要特征。
2.2. 深度学习模型
2.2.1. 自编码器(AE)
自编码器(Autoencoder, AE)是一个无监督学习模型,通过对大量的无标签数据压缩重构,自动学习数据特征,因此该神经网络模型在机器异常检测领域中被广泛使用。该模型由输入层、隐藏层和输出层组成,通过使用神经网络对数据进行编码和解码 [17] 。自编码器结构如图1所示。隐藏层输出作为样本的抽象特征表示,AE首先通过输入层接收样本,隐藏层将其转换成高效的抽象表示,而后输出层将原始样本重构并对输入进行特征学习,并将学习到的特征重组作为输出,目标是降低输入和重构输出之间的损失,使重构的输出与输入的相似度越来越接近 [18] 。
自编码的过程可以分为两部分:输入层到隐藏层为编码过程和隐藏层到输出层为解码过程。编码过程是将高维的输入样本映射到低维,以此实现样本压缩与降维;解码过程则是将抽象表示样本转换为期望输出,目的是输入样本的重构。
在训练阶段中,编码过程对输入样本进行编码操作得到编码层;解码过程对编码层进行解码操作得到输入样本的重构,并通过调整网络参数使重构误差达到最小值,获得输入特征的最优抽象表示。
编码过程如下:
(5)
解码过程如下:
(6)
式中:
表示AE的输入;
表示隐藏层;
表示重构数据;
表示非线性激活函数;
、
、
、
表示神经网络参数。在重构过程中,若要使重构输出的
和输入
尽可能一致,需要用最小化负对数似然的损失函数来训练模型。
(7)
2.2.2. MobileNetV2
MobileNet网络模型在2017年被谷歌团队提出,该模型是一个轻量级深度神经网络模型,具有精度高、计算量小、体积小,适用于运算能力有限和资源受限的平台,目前已有的三个版本,分别为MobileNetV1、MobileNetV2、MobileNetV3 [17] 。
MobileNetV2由谷歌团队在2018年提出的一种新型卷积神经网络,可用于目标检测和分割,相比于传统的深度神经网络,该模型准确率更高,推理速度更快和模型更小。MobileNetV2在MobileNetV1的基本概念构建上,使用在深度上可分离的卷积作为高效的构建块,基于大量的反向残差结构对数据特征进行提取,设计了反向残差块(Inverted resi-dual block)和线性瓶颈(Linear bottleneck),提高了检测的精度。反向残差块结构如图2所示。因为反向残差模块是中间维度大,两边维度小,反向残差块将低维特征使用点卷积1 × 1升维,之后使用深度卷积3 × 3 + Relu对信息特征进行提取,最后使用点卷积1 × 1 + Linear对特征再降维,得到本层特征的输出,并进行一次点卷积的结果和输入相加。
线性瓶颈层的输入通过点卷积1 × 1 + Relu进行升维,从k维增加到
维;之后通过点卷积3 × 3 + Relu可分离卷积对样本进行特征提取采样(stride > 1时),此时特征维度已经为
维度,最后通过点卷积1 × 1 (无Relu)进行降维,维度从
降低到
维。为防止使用Relu的某通道的信息进行处理后会不可避免的有信息丢失,为此在最后降维中使用Linear替代Relu,以防止Relu破坏了数据的特征,使有效信息得到保留 [19] 。
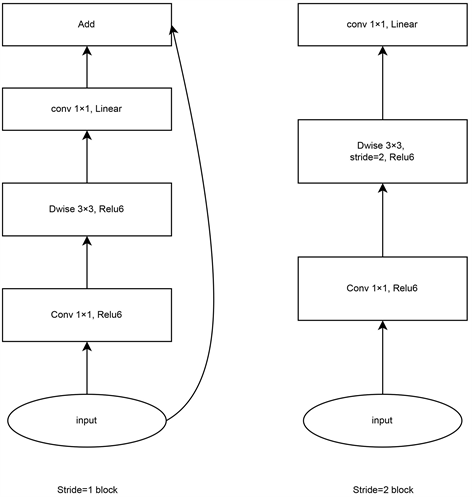
Figure 2. Iverse residual block structure
图2. 反向残差块结构
3. 实验与设置
梅尔标度滤波器由多个三角滤波器组成滤波器组,低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。正常所用的滤波器形式叫做等面积梅尔滤波器(Mel-filter bank with same bank area),在人声领域(语音识别,说话人辨认)等领域应用广泛,但是如果用到非人声领域,就会丢掉很多高频信息。因而本文采用等高梅尔滤波器(Mel-filter bank with same bank height)进行实验。
3.1. 实验数据集
数据集使用DCASE Challenge 2021 Task2开发数据集,由MIMII数据集和ToyADMOS数据集组成。数据集包括开发数据集和评估数据集。MIMII数据集是用于故障工业机器调查和检查的声音数据集,记录了7种不同类型的工业机器的正常和异常声音,即fan、gearbox、pump、slider、valve和ToyADMOS数据集的两种机器类型(即ToyCar和ToyTrain)。每种数据中包含完训练集和测试数据集,即train、source_test、target_test,每个数据集中又设置3个类别的声音Section00、Section01、Section02,每段声音约10秒,包含了机器运作声音和环境噪声 [20] [21] [22] [23] 。
3.2. 参数设置
采用亚当(Adam)优化算法,学习率为0.00001。训练时迭代次数设置为20次,每一批数据的大小(Batch size)为32。
3.3. 评估指标
本实验使用AUC和pAUC进行评估。pAUC是根据预先指定目标范围内的ROC曲线的一部分计算得出的AUC。在本次实验的指标中,pAUC计算为低假阳性率(FPR)范围内的AUC [0, p],p为0.1。每种机器类型、类别和域的AUC和pAUC定义为
(8)
(9)
m表示机器类型;n表示机器的某个类别;d = {源域,目标域}用于确定一个域;H(x)当x > 0时返回1,否则返0;
表示某个机器类型某个类别某个域的正常样本,
表示某个机器类型某个类别某个域的异常样本;
表示某个机器类型某个类别某个域的正常样本数量,
表示某个机器类型某个类别某个域的异常样本数量。
3.4. 结果分析

Table 1. Comparison of experimental results of some machines with baseline systems
表1. 部分机器的实验结果与基线系统的对比
本文所采用的方法通过对比实验,从表1的结果可看出ToyCar、Valve的算数平均pAUC分别提升了0.9%,3.21%。
4. 总结
本作品描述了一种基于深度学习的机器异常声音检测方法,主要是对音频数据集进行声音特征提取后使用自编码器(AE)模型和MobileNetV2模型进行训练,将训练好的模型使用开发数据集的测试数据进行评估检测模型。再通过模型输出的逻辑回归值来计算异常分数和确定异常阈值,然后判断机器是否异常。实验证明了通过对原始音频进行特征提取后训练的模型可以获得一定的异常检测效果。在未来的工作中,将考虑到数据集容量,需要扩大数据量,进一步检验方法的有效性,同时考虑采用更加合理的网络来提升模型的整体性能,进一步发挥深度学习网络的优势,并选择更加适合的分类器,以进一步提高异常检测的效果。
基金项目
上海大学生创新创业训练项目(项目编号:S202211458045),上海电机学院电子信息学院“工业大数据开发技术”课程建设。
NOTES
*通讯作者。