1. 引言
国内生产总值(GDP)是国民经济核算中的重要参数之一,它能够综合反映一个地区或国家在经济发展方面的实际情况。准确预测未来的GDP对于引导宏观经济的健康发展至关重要,能够为决策机构提供有益的指导,帮助他们做出更明智的决策。浙江省是中国长江经济带的重要的省份之一,不仅是21世纪海上丝绸之路圈定的五省之一,也是长江经济带三极之一长江三角洲城市群的重要组成部分。浙江省GDP的发展在一定程度上会受到国家生产总值的影响,因此,研究浙江省的GDP发展趋势,有利于对其发展方案的制定提供一个科学的参考。
田美雪 [1] 使用山东省1990~2020年的GDP数据,采用ARIMA模型进行建模分析。结果显示,2021年山东省GDP总量稳步提升,预测增幅为5.7%,而2021年山东省GDP实际值增幅为8.3%,误差为2.6%。这充分表明该模型拟合效果好,预测精度高。杨忠裕和薛紫玥 [2] 使用ARIMA模型预测甘肃省未来两年的GDP数值,为政府部门制订宏观经济计划提供依据和参考。结果表明,ARIMA模型适用于GDP的增长预测。查华、石舢 [3] 在分析江苏省GDP的发展状况时,采用了ARIMA模型进行预测分析。经过比较,他们确定了ARIMA(0,1,1)模型对GDP数据的拟合效果更好。实验结果也表明两年来江苏省GDP呈现出稳步增长的趋势。张文韬、李瑛琪 [4] 对河南省GDP数据进行了分析,并利用残差自回归模型对建立的ARIMA(0,1,4)模型进行验证,结果表明该模型可以用于预测河南省的GDP,同时也提出,该模型仅适用于短期预测,无法对河南省GDP未来的趋势做出准确预测。
本文通过ARIMA模型来进行建立模型,选用浙江省1952~2018年的GDP数据,对浙江省未来三年GDP进行预测,以期为政府制定经济政策提供参考和依据。
2. 数据来源及ARIMA模型
2.1. 数据来源
GDP国民经济发展的重要指标,它代表着一个国家或者地区的发展状况和人民的生活状况。GDP从某一方面说明着生活的发展、经济的增长、价格的变化和地区发展速度等,所以GDP指标对于一个地区制定其相应的政策和明确经济发展方向有着至关重要的作用。为了更好地探究浙江省未来几年的经济发展趋势,同时也为了保证数据的真实性与准确性,本文使用国泰安数据库的“区域经济”子数据库中的相关文件中1952~2018年GDP历史数据如表1,建立浙江省GDP收入的ARIMA模型,分析其发展趋势,预测浙江省未来三年GDP收入(单位:亿元)。

Table 1. GDP data of Zhejiang Province from 1952 to 2018
表1. 1952~2018浙江省历年GDP数据
2.2. ARIMA模型简介
ARIMA模型,即差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model),是Box-Jenkins在20世纪70年代提出的一种著名时间序列预测方法。其基本思想是将随时间变化而形成的数据序列视为一个随机序列,并使用数学模型来描述和近似该序列。一旦模型被识别出来,就可以利用时间序列的过去值和现在值来预测未来值 [5] 。ARIMA模型的一般形式为ARIMA(p,d,q),其中p、d、q分别指自回归阶数、差分阶数和移动平均数。主要应用于分析非平稳且不带有明显季节性变化趋势的时间序列。ARIMA模型的结构如下所示:ARIMA(p,d,q)。其中,p表示自回归系数,q表示移动平均阶数,d表示差分次数 [6] 。
对d阶齐次非平稳序列
而言,
是一个平稳序列,设其适合ARIMA(p,q)模型,即
为d阶差分。
2.3. ARIMA模型建立及预测
2.3.1. 模型识别
确定合适的p、d、q值是识别ARIMA模型的首要任务。首先需要检验时间序列数据是否平稳。可以通过观察时间序列折线图初步判断,看其是否在一个固定值附近波动。若是平稳的,可以进一步使用ADF单位根检验方法进行验证,这种方法更准确且更具说服力。如果折线图呈增长或下降趋势,则意味着序列不平稳。此时,可以尝试取对数或进行差分操作来处理数据,再判断处理后的序列是否趋于平稳。如果仍然不平稳,需要重复这个过程,直到序列变为平稳状态。处理过程中所进行的差分次数即为d的值。一旦时间序列平稳,就可以使用ARMA模型求解问题。因此,ARIMA(p,d,q)模型的问题转变为ARMA(p,q)模型的问题。然而,为了保证模型简洁且准确,需要避免过多差分导致的误差问题。
要得到平稳时间序列,可以通过绘制自相关图(ACF)和偏自相关图(PACF)来进行观察和分析,初步判断从而选择ARIMA模型中的p和q值。根据表2中的准则,对于不同的p和q值,所选取的ARIMA(p,d,q)模型也会有所不同。此时,可以根据AIC或BIC准则来评估模型的优劣。当AIC或BIC值最小时,说明相应的ARIMA(p,d,q)模型拟合效果最好。通过这种方法,可以为模型选择提供指导,并找到最佳的ARIMA模型。
Table 2. Selection principles for the ARMA(p,q) model
表2. ARMA(p,q)模型的选择原则
2.3.2. 模型估计
在ARIMA模型的估计中,通常采用极大似然估计法来估计ARIMA(p,d,q)模型中的未知参数。极大似然估计是一种常用的参数估计方法,通过最大化观测数据的似然函数,确定模型中未知参数的值。在ARIMA模型中,极大似然估计法的目标是找到使观测数据的似然函数达到最大的参数值。具体而言,首先是根据所选择的(p,d,q)阶数,通过遍历不同的参数组合,建立多个ARIMA模型。然后,使用训练数据集对每个ARIMA模型进行拟合。
2.3.3. 模型检验
模型检验是用来评估时间序列模型的拟合质量的方法。如果模型的拟合效果较差,就需要进行模型的重新选择,直到得到最佳的拟合效果。模型检验包括对参数估计值和残差序列的检验。常用的检验指标包括参数估计值的显著性和残差序列是否为白噪声。当参数估计值显著,并且残差序列满足白噪声的条件时,可以认为模型的拟合效果较好,通过了模型检验。相反,如果参数估计值不显著,或者残差序列不满足白噪声的条件,就需要重新选择模型,使其通过模型检验。在模型检验中,可以使用Ljung-Box统计量检验来判断残差序列是否满足白噪声的条件。Ljung-Box统计量是基于残差序列的自相关函数(ACF)和偏自相关函数(PACF)构建的,用于检验残差序列的相关性是否显著。如果残差序列通过Ljung-Box统计量检验,即相关性不显著,可以认为残差序列是白噪声。
2.3.4. 模型预测
根据模型检验和比较的最终结果,在R Studio软件中利用构建的ARIMA(p,d,q)模型进行预测。预测功能可以用来描绘原始时间序列图的未来变化趋势,并通过对比预测值与实际值进行误差分析,进一步验证模型的可行性。
3. 浙江省GDP时间序列ARIMA模型的应用
本文对浙江省1952~2020年的69个GDP数据进行了分析,为了检验模型的说服力以及正确性,现在选取前面67个GDP数据用来建模,并用后面2年的数据来检验模型的拟合效果,最后再来预测2021~2023年的GDP。
3.1. 数据平稳性检验与处理
根据1952~2018年的浙江省GDP数据,画出时间序列图,如图1所示。
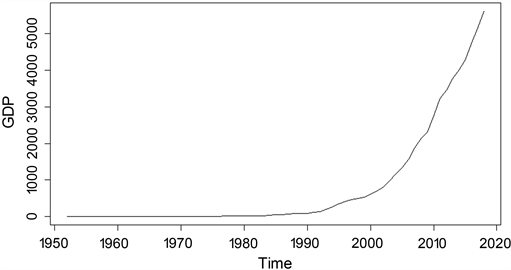
Figure 1. Time series plot of GDP of Zhejiang Province, 1952~2018
图1. 1952~2018年浙江省GDP的时间序列图
从图中可以观察到GDP数据呈现增长趋势,没有出现周期性和季节性波动,显然,这个时间序列初步被判定为非平稳。为了进一步验证,对该时间序列进行了ADF单位根检验,结果显示三个模型的统计量P值都为0.99,大于显著性水平0.05,因此可以得出这个时间序列是非平稳的结论
对于这个非平稳的序列,进行了第一次差分操作后,得到了一次差分后的时序图,如图2所示。在图中可以明显看到增长趋势,初步表明序列仍然不平稳。进行了单位根检验后,发现三个类型的模型的统计量的P值,均大于0.05,这进一步证明了序列的非平稳性。
为了进一步处理这个序列的非平稳性,需要进行第二次差分操作。经过二次差分后得到的时序图如图3所示。从图中可以观察到序列在0值附近上下波动,但仍需进行单位根检验以得出结论。进行了单位根检验后,发现三个类型的模型的统计量的P值,均为0.01,小于0.05,说明此时的时间序列达到了平稳性要求。因此,可以确定在ARIMA(p,d,q)模型中,取d = 2。

Figure 2. First-order differential GDP time series plot
图2. 一阶差分GDP时间序列图

Figure 3. Second-order differential GDP time series plot
图3. 二阶差分GDP时间序列图
3.2. 确定ARIMA模型的阶数
从上述分析得到,二次差分后的浙江省GDP序列是平稳的,利用R Studio软件,画出二次差分后序列的自相关ACF图和偏自相关PACF图,如图4和图5所示。
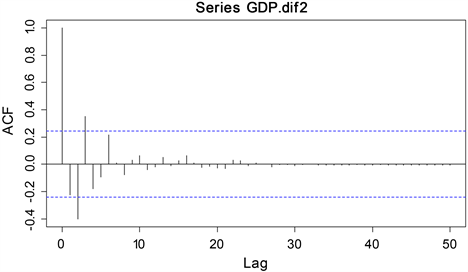
Figure 4. Autocorrelation plot after second-order difference
图4. 二阶差分后的自相关图
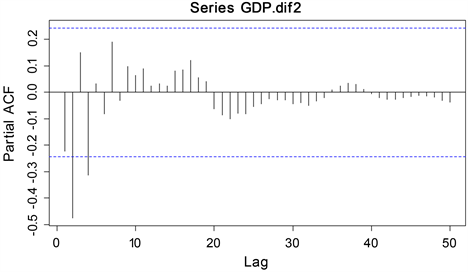
Figure 5. Partial autocorrelation plot after second-order difference
图5. 二阶差分后的偏自相关图
观察分析两个图可以得到,自相关系数在3阶之后是逐渐趋于零的,偏自相关系数在4阶之后是也逐渐趋于零的,因此,P值取4,q值取3。但是,需要注意的是,这样选择模型的过程具有一定的主观性。为了消除误差,建立了多个ARIMA模型,并分别选择了ARIMA(0,2,2),ARIMA(0,2,3),ARIMA(2,2,2),ARIMA(4,2,2),ARIMA(4,2,3)等。针对每个模型,计算了相应的AIC值,具体数据结果可见于表3。从表中观察可以得出,ARIMA(4,2,3)模型的AIC值最小,所以可以认为该模型是最佳选择。
Table 3. Comparison of ARIMA models
表3. ARIMA模型的比较
3.3. 模型的检验
对ARIMA(4,2,3)模型的残差进行白噪声检验。通过Ljung-Box统计量检验,在给定的显著性水平下,观察残差的P值。具体检验结果及图示可参考表4。根据检验结果,得到残差序列的P值分别为0.9956和0.9999,均大于显著性水平0.05。因此,可以认为该模型通过了白噪声检验,表明残差序列符合白噪声性质。基于这一结论,可以使用该模型进行预测。
Table 4. Residual white noise test results
表4. 残差白噪声检验结果
3.4. 模型的预测
利用通过检验的ARIMA(4,2,3)模型,预测2019~2023年的浙江省GDP,预测结果如表5和图6所示。同时,将2019年和2020年的预测结果与实际结果进行对比,并计算相对误差和实际误差,结果如表6所示。
Table 5. Predictions of the ARIMA(4,2,3) model
表5. ARIMA(4,2,3)模型的预测结果
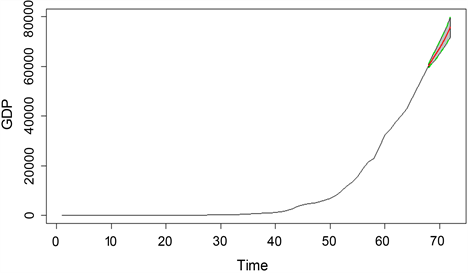
Figure 6. Trend plot of prediction results of ARIMA(4,2,3) model
图6. ARIMA(4,2,3)模型的预测结果趋势图
Table 6. ARIMA(4,2,3) comparison of predicted and actual values
表6. ARIMA(4,2,3)预测值与实际值比较
根据表中的结果分析,平均相对误差为2.28%。从数据上来看,该模型在短时间内对GDP的预测相对准确。浙江省在1952年至2000年左右的GDP增长相对平稳,但自2001年至2020年,增长非常迅速。这可能与阿里巴巴公司在杭州成立以及电子商务时代的到来有关。据此,我们可以推断,未来浙江省的GDP将持续增长并继续突破。
根据所得模型,预测浙江省2021年至2023年的GDP分别为67498亿元、71468亿元和75757亿元。然而,由于自2020年起新冠肺炎疫情及国际疫情变异的影响,预测未来三年的GDP可能会受到影响并增加误差。因此,所预测的数据仅作为参考。
4. 结论
时间序列是一种广泛应用于预测未来数据的方法,它利用过去和现在的观测数据,其模型相对简单,对数据要求不高。
在建立模型、分析和预测过程中,首先要确保建模数据满足平稳性的条件。如果不满足平稳性,需要进行相应的处理,例如差分或取对数。然后,根据绘制的自相关图(ACF)和偏自相关图(PACF)来确定模型,本文中为ARIMA(4,2,3)。接着,通过参数的显著性检验和残差的白噪声检验来增加模型的可信度和说服力。同时,比较预测结果与实际值之间的误差,也可以证明模型的可行性。
在实际应用中,我们需要注意,ARIMA模型虽然在短期预测方面表现良好,但随着预测时间的延长,模型的误差会逐渐增大。这是因为ARIMA模型无法考虑到一些特殊的经济因素,比如国内外新冠肺炎疫情的影响、中国进口博览会等大型活动的举办以及国家和地区政策的推行等。这些因素都可能对GDP增长产生重要影响,但ARIMA模型无法直接体现。
因此,在使用ARIMA模型进行预测时,需要将其仅作为参考,结合其他经济模型或考虑额外的经济因素来提高预测的准确性和可靠性。
基金项目
上海市科委软科学重点项目“数字化驱动上海制造业绿色创新的机制及路径研究”(22692105100)。
附录
#读入数据
getwd()
setwd(dir = C:/Users/10475/Desktop/时间序列)
library(readxl)
ZJGDP <- read_excel(C:/Users/10475/Desktop/时间序列/ZJGDP.xlsx)
View(ZJGDP)#导入Excel数据
#创建时间序列
G=ZJGDP$gdp
GDP=ts(G,start = c(1952),frequency = 1)
#数据平稳性检验与处理
plot(GDP)
adf.test(GDP,nlag = 2)#单位根检验GDP
GDP.dif<-diff(GDP)
plot(GDP.dif)#一阶差分及时序图
adf.test(GDP.dif,nlag = 2)#单位根检验GDP.dif
GDP.dif2<-diff(GDP,1,2)
plot(GDP.dif2)#二阶差分及时序图
adf.test(GDP.dif2,nlag = 2)#单位根检验GDP.dif2
acf(GDP.dif2,50)
pacf(GDP.dif2,50)#自相关和偏自相关
#模型建立
GDP.fit<-arima(GDP,order = c(4,2,3))
GDP.fit#拟合模型选取AIC值最小的模型
for(i in 1:2) print(Box.test(GDP.fit5$residuals,lag = 6*i))#残差白噪声检验
GDP.fore<-forecast(GDP.fit5,5)#预测未来五年数据
NOTES
*通讯作者。