1. 引言
茶叶是我国的主要经济作物之一,在农村产业结构调整,增加农民收入,加速农民致富奔小康中起到积极的作用 [1] 。然而,茶树在种植过程中容易受到细菌、真菌和病毒等的入侵而感染病害,这些病害会大大降低茶叶的产量和质量。若不能及时发现这些病害并加以控制,将会导致茶叶种植者和整个行业的巨大经济损失 [2] 。传统上,对于茶叶病害的诊断主要是依赖于有经验的生产者的视觉观察 [3] 。然而,这种方法主观性强、耗时长,容易出错。此外,这种方法需要对于茶叶病害有专业的知识,不具有普适性。因此,寻找一种快速、准确地识别对茶叶病害进行诊断具有重要的现实意义。
随着计算机技术的发展,众多研究人员使用机器学习和图像处理方法来鉴定农作物疾病 [4] [5] 。余秀丽等 [6] 对小麦叶部病害图像去噪及分割病斑,然后提取病斑特征,最后使用SVM算法对小麦叶部病害图像进行分类识别。张云龙等 [7] 使用分割算法对病斑区域进行分割,并计算病斑的颜色特征和差直方图,结合SVM分类器,对3种常见苹果叶部病害图像识别率达96.52%。林彬彬等 [8] 在分割病斑区域基础上,使用多种方法提取病斑的颜色特征,进行特征选择后使用K近邻算法进行茶叶病害的智能诊断识别。然而早期机器学习方法需要人为进行特征提取和选择,较为复杂且识别效果差,难以推广和应用。
近年来,深度学习的快速发展,卷积神经网络由于其出色的特征提取能力,因此越来越多的学者使用卷积神经网络对农作物病害进行识别 [9] [10] [11] 。贾璐等 [12] 提出了一种MANet葡萄病害识别模型,对4种常见葡萄叶片图像的识别准确率达87.93%。杨康等 [13] 基于SSD模型架构,使用MobileNet替换SSD模型的原始主干网络,并构建了RFB模块实现多尺度检测,对4类三七病害的检测精度达82.0%。李就好等 [14] 对Faster-RCNN进行改进,增加建议框的尺寸个数,并在特征提取网络ResNet-50的基础下融入了FPN网络,改进网络的识别准确率达到86.39%。孙道宗等 [15] 对YOLOv4模型的主干网络进行改进,并在模型中嵌入CBAM注意力机制,对3类病害的识别精度达93.85%。杨文姬等 [16] 设计一种基于改进Yolov5的深度学习方法,用于检测苹果和番茄病害,改进后的Yolov5病害检测算法mAP达到95.7%。李伟豪等 [17] 提出了一种Yolov7-TSA模型对茶叶病害检测和分类,对7类茶叶病害和健康茶叶的识别准确率达94.2%。然而,尽管上述研究都取得了较好的识别结果,但仍存在一些问题。如模型参数量大,难以部署在茶园边缘设备上,识别准确率不佳等。为解决这些问题,本文提出了一种改进YOLOv7的茶叶病害识别模型。
2. 数据集描述
2.1. 数据采集
本文实验数据分别采集自贵州省贵阳市花溪区久安古茶园和羊艾茶园,拍摄时间分别为2023年4月1日至7日时间段,此时正处于茶叶病害的高发期,便于病害图像的采集。拍摄时,手持拍摄设备(OPPO Reno Ace智能手机)距茶叶病害叶片10~20 cm处进行拍摄,保存格式为JPG。在不同光照条件和不同成像背景情况下,采集到4类茶常见茶叶病害图像共1083张,其中,茶芽枯病(TBB) 335张,茶轮斑病(TGB) 312张,茶藻斑病(TALS) 221张,茶叶枯病(TLB) 215张。
2.2. 数据集预处理
训练深度学习模型时,训练样本的多样性能增强模型的学习能力,提高模型的泛化能力。由于茶树大多生长在崎岖山区,数据采集较为困难,采集到的样本有限,因此考虑采用数据增强方法来扩充样本。我们使用随机旋转、随机翻转(水平和垂直两个方向)、高斯模糊、亮度调整和添加高斯噪声等五种数据增强方法对部分茶叶病害样本进行增强,增强结束后共得到4333张茶叶病害图像。对增强后的茶叶病害图像,使用LabelImg标注工具对进行标注,标注后生成与每张病害图像种类信息、病害位置信息相对应的xml文件,与茶叶病害图像组成最终的数据集。图1显示了图像标注示例和标注后生成的对应xml文件。最后,按照7:3将最终数据集划分为训练集和验证集,其中训练集图像数量为3033张,验证集图像数量为1300张。
 xml文件中,第一个框为病害图片信息,大小为640 × 640 × 3,第二个框为病害种类名称,第三个框为标注框的位置信息。
xml文件中,第一个框为病害图片信息,大小为640 × 640 × 3,第二个框为病害种类名称,第三个框为标注框的位置信息。
Figure 1. Example of disease image annotation with generated xml file
图1. 病害图像标注示例与生成xml文件
3. 改进的YOLOv7茶叶病害检测模型设计
3.1. YOLOv7简述
YOLOv7模型由Chien-Yao Wang等人 [18] 于2022年7月提出,较YOLO系列的其它模型相比,其具有更快的检测速度、更高的识别精度、易于部署等优点。YOLOv7的检测思路与YOLOv5相似,其结构如图2所示。从结构图可以看到它由四个部分组成,即输入模块(Input)、主干网络(Backbone)、特征融合网络(Neck)和预测网络(Head)。
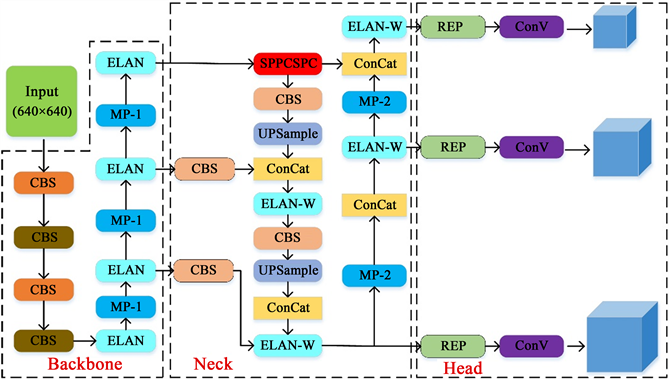
Figure 2. YOLOv7 network architecture diagram
图2. YOLOv7网络结构图
其中,输入模块主要是将输入图像尺寸统一缩放到640 × 640大小,并对输入图像进行数据增强操作等预处理。主干网络由多个基础卷积模块(CBS)、扩展高效聚合网络(ELAN)和最大池化卷积模块(MP)组成,主要负责对输入图像进行特征提取,得到三个不同尺度的特征图。特征融合网络由路径聚合特征金字塔网络(PAFPN)组成,通过引入自上而下的路径,使得底层信息更容易向高层传递,从而实现不同层次特征的高效整合。预测网络由重参数化卷积(RepConv)对从特征融合网络输入的三个特征图通道数进行调整,最后分别通过1 × 1卷积预测目标的置信度、类别和位置。
3.2. 改进的YOLOV7模型
3.2.1. 注意力机制
在注意力机制中,卷积注意力模块多注重输入与输出间的关系,而自注意力模块则着重于输入与输入之间内部关联。因此,人们通常认为它们是独立的两个注意力模块。但潘旭然等发现卷积注意力模块和自注意力模块都严重依赖1 × 1卷积操作,基于这一发现提出了一种混合注意力机制ACmix模块 [19] ,其结构如图3所示。该模块结合了卷积操作和自注意力模块的优点,具有更强的特征提取能力,更小的计算开销。
具体来说,ACmix模块原理如下:第一阶段,先通过3个1×1卷积将H×W×C的输入特征进行投影,并分别重构为N部分,得到3N个尺寸为H × W × C/N的中间特征。第二阶段,对于卷积路径,中间特征通过
的全连接层后,对生成的特征进行移位和聚合以及卷积处理,得到H × W × C的特征;对于自注意力路径,将中间特征聚合到N组中,每组包含三个特征,每个特征来自不同的1×1 卷积输出,对应的3个尺寸为H × W × C/N的特征图分别作为查询、键和值,并遵循传统的多头自注意力模型,通过移位、聚合、卷积处理得到H × W × C的特征。最后,将两条路径的输出进行相加操作,强度由两个可学习的标量控制,如式(1)所示:
(1)
式中,
表示路径的最终输出;
表示自注意力分支的输出;
表示卷积注意力分支的输出;α和β的值均为1。
3.2.2. C3模块
YOLOv7网络中包含了大量的E-ELAN模块,该模块在特征提取方面效果不佳,此外E-ELAN结构中包含了较多卷积模块和残差连接,会使网络的计算量增加,推理速度降低。C3模块为YOLOv5 [20] 中重要特征提取模块,它由三个标准卷积和多个瓶颈层组成,结构图如图4所示。其原理是一个分支经过1 × 1卷积降低特征通道数,另一个分支经过1 × 1卷积和N个Bottleneck先降低通道数再进一步提取和增强特征信息,最后两个分支拼接在一起并通过1 × 1卷积来融合它们。
C3结构采用了多尺度特征融合和跨通道信息传递,增强了模型的特征表达能力。因此,为解决使用E-ELAN模块带来的不利影响,本文拟将特征融合网络部分E-ELAN替换为C3模块,以进一步增强YOLOv7网络的特征提取能提和融合能力,同时提高模型推理速度。
3.2.3. 改进损失函数
目标检测是通过边界框回归来定位图像中的物体,因此良好的边界框损失函数对于准确定位目标极其重要。在早期的目标检测任务中,常采用IoU作为定位损失函数。但IoU损失存在两个问题:一是预测框与真实框不相交时,IoU损失会造成梯度消失问题,导致收敛速度变慢,检测不准确。二是预测框和真实框相交时无法反映重叠程度。为了解决这两个问题,后来研究人员又提出了几种改进IoU损失,如GIoU、DIoU和CIoU等等。在YOLOv7模型中,便采用了CIOU损失函数进行边界框回归。CIoU损失函数考虑了三个几何因素,包括归一化中心点距离的最小化以及重叠区域和长宽比的一致性。但当预测框与真实框的长宽比相同且共中心点时CIOU会退化为IOU,CIoU损失函数将得不到稳定表达。
基于上述原因,本文采用Alpha-IoU损失函数 [21] 改进原网络中的CIOU损失函数。Alpha-IoU损失函数通过控制功率参数α,提高了边界框回归的精度,同时考虑了距离、角度及重叠面积这三个关键因素,从而加快了模型收敛速度。改进损失函数如式(2)所示:
(2)
式中,
代表2个中心点之间的欧氏距离,
表示预测框和真实框的中心点坐标,c表示能够同时
包含预测框和真实框的最小外接矩形的对角线距离,
表示真实框的宽高比,
表示预测框的宽高比。
本实验中α设为3,更有利于提升模型的精度。
4. 实验结果与分析
4.1. 实验环境
本实验使用python语言并基于PyTorch深度学习框架进行开发,硬件及软件配置如表1所示。

Table 1. Configuration of the experimental environment
表1. 实验环境配置表
实验中输入图像尺寸为640 × 640大小,训练迭代次数为500轮,批量大小为16,优化器为SGD优化器,学习率设为0.001。
4.2. 评价指标
为了评估改进模型对茶叶病害识别性能,采用查准率(Precision, P)、查全率(Recall, R)、平均准确率(mAP)、检测速度(FPS)、模型参数量(Params)作为评价指标。各评价指标定义公式如下:
(3)
(4)
(5)
(6)
式中,TP为检测出正确的正样本数;FP为检测出错误的正样本数;FN为检测出错误的负样本数;N为检测的类别数;frameNum为检测图片的总数;elapsedTime为耗费的总时间。
4.3. 消融实验
为了验证我们所提出改进点对YOLOv7模型的影响,本实验部分在自制茶叶病害数据集上进行了四组消融实验,实验结果见表2所示。
从表2可知,加入ACmix注意力模块后,mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5提升了1.1个百分点,模型参数量略有增加,而FPS略有下降,但是变化幅度都不大,这说明加入ACmix注意力在不增加参数量的同时显著提高了网络的特征提取能力;用C3模块替换ELAN-W之后,mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5和模型参数量都略微有所下降,其中mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5下降0.2个百分点,FPS提升为82帧,而模型参数量下降了4.4 M,这表明加入C3模块后显著减少了模型的计算量和参数量;使用Alpha-IoU优化原损失函数后,在没有FPS和模型参数量增加的条件下,mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5增加了0.6个百分点。最后,加入所有改进点之后,mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5较基准模型提升了1.8个百分点,FPS提升为79帧,模型参数量下降了3.5 M。消融实验结果表明,加入三个改进点后的模型效果最佳,兼具精度、速度和模型大小。
为了更直观地展示改进后模型的性能,我们选取不同病害图片进行展示,对比改进前后模型的检测效果,如图5所示。
从图5可以看出,对于第一行图像中目标,原始YOLOv7可以较好的检测出茶芽枯病,但发生了两处误检。而改进后的YOLOv7消除了误检,对茶芽枯病的置信度更高,识别更准确。对于第二行图像中目标,虽然YOLOv7能准确检测出茶藻斑病和茶轮斑病两个目标,但置信度不高,而改进后模型对两个目标的置信度更高。对于第三行图像中目标,原始YOLOv7能准确识别出茶轮斑病,但是置信度过低,而改进后的YOLOv7提高了对茶轮斑病的置信度。对于第四行图像中茶叶枯病,原始YOLOv7的目标框发生了重叠,而改进后的YOLOv7消除了这个情况并提升了目标框的置信度。

Figure 5. Comparison of recognition effect of YOLOv7 before and after improvement
图5. 改进前后YOLOv7的识别效果对比
4.4. 不同模型性能对比
为了验证本文所提出的改进模型的有效性,将改进后YOLOv7模型与当前主流检测模型在自制茶叶病害数据集上进行对比实验,实验结果如表3所示。
通过表3结果可以看出,本文模型各方面都优于基准模型。此外,在多个指标上与先进方法相比,均具有明显优势。其中,P、R和mAP@0.5均是最优的,分别为94.1%、92.3%和93.3%。在检测速度方面,YOLOV7-Tiny检测速度最快,本文改进模型为79 f/s,高于YOLOv7 14 f/s。在参数量方面,YOLOV7-Tiny参数量最低,仅为6.1 M,而本文改进模型排第三名,为33.7 M。综合准确率、检测速度和模型大小等评价指标考虑,本文改进模型综合性能更具有优势。
Table 3. Comparison of the improved model with other detection models
表3. 改进模型与其他检测模型的对比
5. 结论
本文提出了一种改进的YOLOv7茶叶病害识别模型,其mAP@50和FPS分别高于原始YOLOv7模型1.8个百分点和14帧,参数量减少了3.5 M,改进模型较原始模型性能有较大提升。此外,将改进后模型与当前主流目标检测网络YOLOv4、YOLOv5s以及YOLOV7-Tiny相比,其精确率、召回率和mAP@0.5为最佳,参数量大小和FPS分别为第三名。综合各项评价指标来看,本文改进模型满足茶园环境中茶叶病害识别的需要,可以将模型部署到茶园终端,对茶叶发病情况进行监控,为茶产业的智能化发展提供了研究基础,具有重要的理论价值和实际意义。
基金项目
贵州省基础研究项目(No. ZK [2023]060)。
NOTES
*通讯作者。