1. 引言
提高居民消费,扩大有效需求,是经济可持续发展的基础,目前对居民消费的研究集中在影响研究上,黄家林 [1] 基于中国家庭追踪调查数据,研究大病医疗保险对居民消费的影响,姚战琪 [2] 研究数字经济对居民人均消费支出的影响,罗正媛 [3] 分析城市人口密度对居民消费的影响,倪坤 [4] 以相关资料和理论为基础,研究近代中国居民消费影响因素,鲜有文献对居民人均消费支出预测进行研究。因此,本研究基于1980~2021年我国居民人均消费支出数据,构建ARIMA模型与协整模型,对2022~2026年居民人均消费支出进行预测研究,为居民消费研究提供一种新的思路。
2. 基于ARIMA模型对我国居民人均消费支出的预测
ARIMA模型用于时间序列数据,能反映动态数据变化规律,对未来趋势进行预测 [5] 。本节采用ARIMA模型对2022~2026的居民人均消费支出进行预测。
2.1. 数据描述
研究对象为我国的居民人均消费支出{c},选用来自国家统计局1980~2021年我国居民人均消费支出数据,数据连续完整,可靠性强,作为本节研究的原始数据,如表1所示。

Table 1. Per capita consumption expenditure of Chinese residents from 1980 to 2021 (yuan)
表1. 1980~2021年我国的居民人均消费支出(元)
2.2. 平稳性及白噪声检验
对时间序列数据进行研究,首先要对数据的平稳性进行检验 [6] 。利用时序图对平稳性进行简单判别,考虑到该序列有呈指数上升的趋势,对序列{c}作对数变换得到序列{lnc},绘制出序列{c}与序列{lnc}时序图,如图1所示。
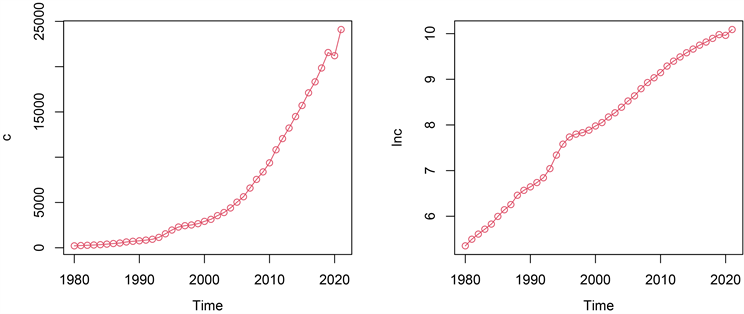
Figure 1. The timing diagram of the sequence {c} and the sequence {lnc}
图1. 序列{c}和序列{lnc}的时序图
由图1可知,序列{c}与序列{lnc}都有明显递增趋势,均为非平稳序列,再对序列{lnc}进行一阶差分,得到序列{dlnc1},绘制出时序图,如图2所示。

Figure 2. Timing diagram of the sequence {dlnc1}
图2. 序列{dlnc1}的时序图
由图2可知,序列{dlnc1}在一定范围内来回波动,不能准确判定{dlnc1}是否为平稳序列,再进行ADF检验 [7] ,如表2所示。
由表2可知,只含漂移项与含漂移项和趋势项两种类型的p值均小于显著性水平0.05,可认为{dlnc1}序列显著平稳,且{dlnc1}的确定性部分可以用只含漂移项与含漂移项和趋势项等多种模型结构进行拟合。为判定序列{dlnc1}是否具有建模的价值,进行白噪声检验 [8] ,如表3所示。
Table 3. Sequence {dlnc1} white noise test results
表3. 序列{dlnc1}白噪声检验结果
由表3可知,序列{dlnc1}检验p值为0.002442,远小于显著性水平0.05,表明序列{dlnc1}是平稳非白噪声序列,可以进行后续建模。
2.3. ARIMA模型的建立与检验
绘制出自相关图和偏自相关图,进行模型定阶的尝试 [9] ,如图3所示。
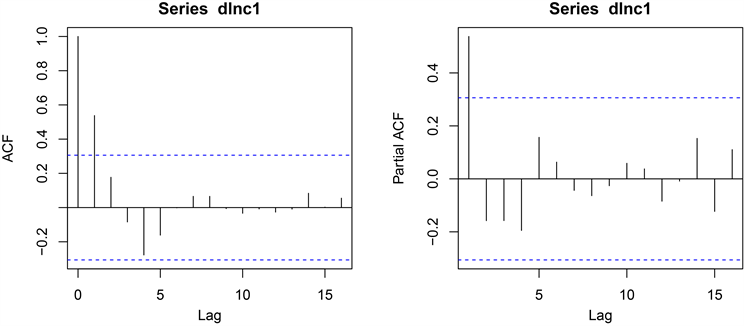
Figure 3. Autocorrelation plots and partial autocorrelation plots of the sequence {dlnc1}
图3. 序列{dlnc1}的自相关图和偏自相关图
由图3可知,{dlnc1}自相关图1阶截尾,偏自相关图拖尾,再结合ADF检验结果,使用带有漂移项的ARIMA(0,1,1)模型拟合序列{c}。为检验模型各参数的显著性,进行参数估计 [10] ,如表4所示。
Table 4. Parameter estimation results
表4. 参数估计结果
由表4可知,模型参数估计值均大于2倍标准差,认为参数显著非零。为检验拟合模型是否显著,对拟合模型残差序列进行白噪声检验,若残差序列为白噪声序列,则模型显著成立,如表5所示。
Table 5. Results of the white noise test for the residual sequence
表5. 残差序列白噪声检验结果
由表5可知,残差序列p值为0.6546,远大于显著性水平0.05,表明残差序列是白噪声序列,因此,构建带有漂移项的ARIMA(0,1,1)模型显著成立,可以进行后续预测。
2.4. 模型的预测
以构建的ARIMA模型为依据,对1980~2021年我国居民人均消费支出进行拟合,如图4所示。
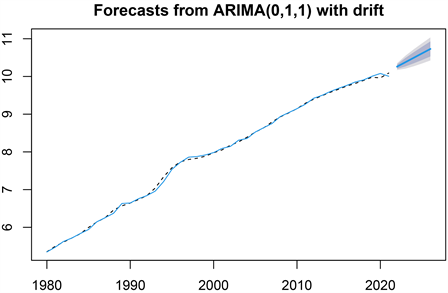
Figure 4. ARIMA(0,1,1) model fit plot with a drift term
图4. 带有漂移项的ARIMA(0,1,1)模型拟合曲线图
由图4可知,最优拟合数据与实际数据较吻合,能够描述出我国居民人均消费支出的增长趋势,模型拟合效果较好。因此,利用ARIMA模型预测2022~2026年的居民人均消费支出,如表6所示。
Table 6. The forecast value of resident per capita consumption expenditure in 2022~2026
表6. 2022~2026的居民人均消费支出预测值
3. 基于协整模型对我国居民人均消费支出的预测
协整模型是有效描述非平稳变量关系的方法,可实现时间序列分析中短期和长期模型优势的有力结合 [11] ,本节采用协整模型对2022~2026的居民人均消费支出进行预测。
3.1. 数据的描述
相关研究指出,居民人均消费支出受居民人均可支配收入的影响最大,其次是人均GDP [12] 。因此,本节选用来自国家统计局1980~2021年我国的居民人均消费支出{c}、居民人均可支配收入{r}和人均GDP{g}等数据,作为本节研究的原始数据,如表7,表8所示。
Table 7. Per capita disposable income of Chinese residents from 1980 to 2021 (yuan)
表7. 1980~2021年我国居民人均可支配收入(元)
Table 8. 1980~2021 China’s per capita GDP (yuan)
表8. 1980年~2021年我国人均GDP(元)
3.2. 平稳性检验
对多元时间序列数据进行研究,首要考虑的是数据序列的平稳性。为消除数量级的影响,将原序列做对数变换,得到输入序列{lnr}和{lng},输出序列{lnc},并绘制出时序图,如图5所示。
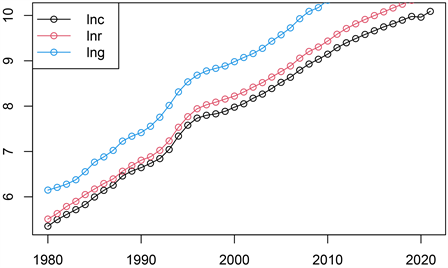
Figure 5. Time timing diagram of {lnc}, {lnr} and {lng}
图5. {lnc}、{lnr}和{lng}的时序图
由图5可知,序列{lnc}、{lnr}和{lng}呈现出一致的增长趋势,均为不平稳序列,再进行一阶差分,并对一阶差分后的序列{dlnc1}、{dlnr1}和{dlng1}进行具有漂移项的ADF检验,如表9所示。
在滞后阶数为1时,序列{dlnc1}、{dlnr1}和{dlng1}均达到了平稳。原序列为非平稳序列,一阶差分后达到平稳,可认为原序列是同阶单整的,再采用EG两步法检验序列{lnc}、{lnr}和{lng}间是否存在协整关系,若存在,则可构建协整模型 [13] 。
3.3. 协整模型的构建与检验
首先,需要建立响应序列与输入序列之间的回归模型。本研究有多个输入序列,考虑到不同的输入序列对输出序列的影响可能会不同,绘制出{lnc}分别与{lnr}、{lng}的互相关图,如图6所示。
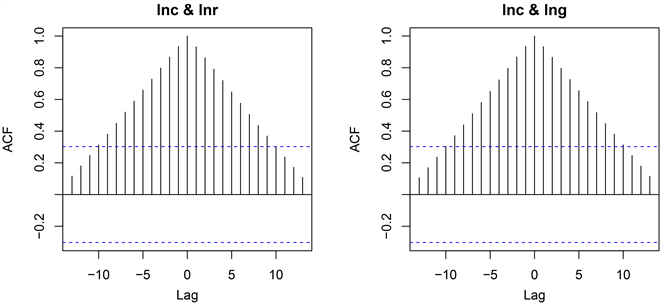
Figure 6. Cross-correlation plot of the input and output sequences
图6. 输入序列与输出序列的互相关图
由图6可知,输入序列{lnr}、{lng}对输出序列{lnc}的影响均在当期达到最大,利用当期序列建立如下回归模型:
利用R进行拟合后得到以下模型:
为检验模型各参数的显著性,进行参数估计,结果如表10所示。
由表10可知,参数估计值均大于2倍标准差,认为参数显著非零。
其次,对回归残差序列进行平稳性检验,如表11所示。
Table 11. Results of the regression residual sequence stationarity test
表11. 回归残差序列平稳性检验结果
由表11可知,不含漂移项和趋势项的p值小于显著性水平0.05,认为该序列显著平稳,再对拟合模型残差序列进行白噪声检验,如表12所示。
Table 12. Results of the regression residual sequence white noise test
表12. 回归残差序列白噪声检验结果
由表12可知,残差序列检验p值为0.01277,远小于显著性水平0.05,表明残差序列为平稳非白噪声序列。通过残差序列的自相关图和偏自相关图,进一步提取残差序列中的信息,如图7所示。
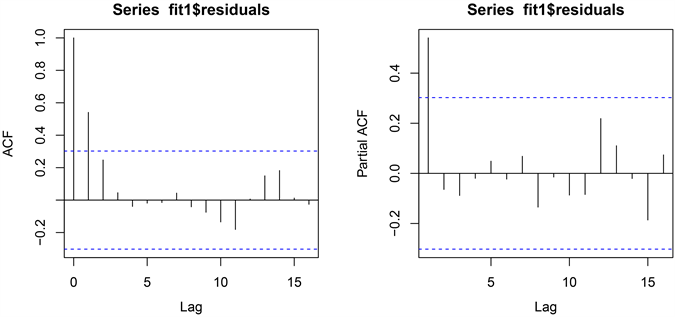
Figure 7. Autocorrelation plots and partial autocorrelation plots of the residue sequence
图7. 残差序列的自相关图和偏自相关图
由图7可知,自相关图拖尾,偏自相关图1阶截尾,采用AR(1)模型拟合残差序列,最终拟合的协整模型如下:
构建出协整模型后,对模型进行参数估计和显著性检验,如表13和图8所示。
由表13可知,参数估计值均大于2倍标准差,认为参数显著非零。
由图8可知,p值均显著大于0.05,说明残差序列为白噪声序列,即该拟合模型显著有效。
3.4. 模型预测
首先,通过单变量拟合方法获得序列{lnr}和{lng}的预测值。采用auto.arima函数对序列{lnr}和{lng}进行拟合,得到序列{lnr}拟合模型为带有漂移项的ARIMA(2,1,2),{lng}拟合模型为带有漂移项的ARIMA(0,1,2),两种拟合模型的参数估计结果如表14,表15所示。
Table 14. ARIMA (2,1,2) with drift parameter estimation results
表14. ARIMA(2,1,2) with drift参数估计结果
Table 15. ARIMA(0,1,2) with drift parameter estimation results
表15. ARIMA(0,1,2) with drift参数估计结果
由表14,表15可知,参数估计值均大于2倍标准差,认为参数显著非零。协整模型由{lnr}、{lng}和残差序列三项构成,且各项的系数已确定,只需获取2022~2026年序列{lnr}、{lng}和残差序列的值,再利用协整模型即可得到序列{c}的预测值,如表16所示。
Table 16. Forecast value of household per capita consumption expenditure from 2022 to 2026
表16. 2022~2026年的居民人均消费支出预测值
4. 基于ARIMA模型与协整模型的比较分析
本节将从模型拟合效果和预测精度等两方面来对ARIMA模型和协整模型进行比较分析,筛选出较优的模型,确定出2022~2026年居民人均消费支出预测值。
首先,从模型拟合效果的角度分析,比较ARIMA模型和协整模型的AIC值,如表17所示。
由表17可知,与协整模型相比,ARIMA模型的AIC值相对较小。ARIMA模型是根据居民人均消费支出随时间的变化而构建的单变量模型,不受其他变量的干扰,而协整模型是考虑其他变量而构建的多变量模型,考虑因素更多,更容易受到干扰,会在一定程度上增大模型拟合的误差。
其次,从预测精度的角度分析,将ARIMA模型与协整模型对1980~2021年我国居民人均消费支出的最优拟合值导出,并与实际值进行比较。为方便说明,用实际值与最优拟合值之间的相对误差率来说明预测模型的精度,如图9所示。
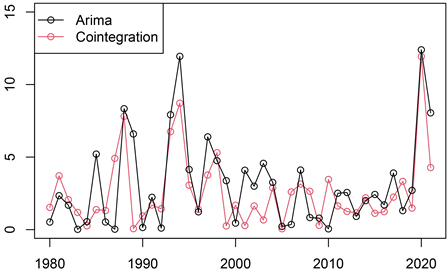
Figure 9. The relative error rate comparison in Fig
图9. 相对误差率对比图
由图9可知,两者的相对误差率均在0%~15%内波动,协整模型相对误差率波动比ARIMA模型小,但整体趋势接近,难以区分哪种模型预测精度会更高。因此,在预测精度大体相同时,选择AIC值更小的ARIMA模型预测值作为本研究的预测结果,如表18所示。
Table 18. Forecast value of household per capita consumption expenditure from 2022 to 2026
表18. 2022~2026年的居民人均消费支出预测值
由表18可知,未来五年居民人均消费支出仍呈增长趋势,并且将在2025年突破4万元。
5. 总结
本研究以1980~2021年居民人均消费支出数据为基础,构建出ARIMA模型与协整模型,进行模型的对比分析,得到2022~2026年居民人均消费支出预测值。本研究巧妙地将ARIMA模型与协整模型运用到居民消费预测上,为该研究领域提供了一种新的思路,而由于数据收集的困难,本研究只选择了42年的数据,若增加数据量,获取更长期的变动趋势,预测结果将会更加精准。