1. 引言
在修缮文物时,应考虑文物固有的历史价值和稳定性。在兼顾社会、历史和艺术三个方面,尽可能地恢复其真正的价值。而且,这些文化遗产最显著的特点是其真实性和珍贵性,它们是不可再生的资源。由于缺乏对文物的保护意识,特别是对文物古迹的不当使用,使文物的价值和完整性遭到破坏。为此,必须采用合理的方法对文物进行保护和修复,利用科学技术来弥补它的不足,促进它的完善,并赋予它更鲜活的生命。在当今的文物修复中,人们通常会利用现代化的技术手段,来构建文物的保护与修复资讯知识库。与文物本身所构建的信息库相比,知识库与其本身所构建的信息库有很大的区别。知识库通常采用分块的方式进行处理,这样可以提高数据的处理效率和精度。同时也可以使用Python等技术对WEB进行收集和处理,并对相应的数据进行分析。
在ETL处理技术方面,通常使用Hadoop、Spark、Flink等平台来确定是否采用流式处理和批量处理等管理方法。促进它们完成数据提取、整理和转换等数据挖掘、分析技术,增强对信息知识的检索和分析能力。然而,目前我国文物修缮工作的发展状况是:大量的残损文物深埋于地下,专业的修复者极其匮乏,而传统文物的修缮工作费时费力。
本文目的是研究将计算机视觉技术应用于文物修复领域。文物修复,首先应考虑到文物自身承载的历史价值及稳定性,在平衡社会、历史与艺术价值的基础上,尽量还原其本真价值。并且文物明显特点是真实性与高价值,且属于不可再生资源。人们不重视文物保护,尤其是历史建筑景区的不恰当行为,导致文物的价值、完整性受到影响。对此,应采取合理方式保护、修复文物,用科技弥补历史文物缺陷,促使文物达到完美境界,同时也使其生命力更加鲜明 [1] 。现今文物修复会借助现代科技,建立文物保护修复的信息知识数据库。知识数据库同文物自身所建立的信息库相比,存在一定差异。知识库一般应用分区化处理原则,数据处理效率会更高,处理结果也更加准确。利用PHHON等技术采集处理WEB中的內容,分析其对应的数据。对于ETL处理技术,通常采用HADOP、框架及风暴技术平台,选择是否进行流处理和批处理等管理技术,促使其完成数据提取、清理及转化等数据挖掘、分析技术,从而加强信息知识的查询与分析功能。但当今文物修复发展现状是大量残缺文物深藏库房和专业修复人员的极度稀缺,传统文物修复耗时长,工作量大。
随着计算机技术的快速发展,计算机视觉已经广泛应用于各个领域,例如皮革加工领域:Gerber公司在皮革裁剪系统中加入CCD相机,在检测皮革缺陷的同时提高了裁剪效率;Lectra公司在皮革裁床中引入视觉检测,实现了对皮革的分类 [2] 。近年来,基于计算机视觉的目标定位逐渐成为研究热点。Ji等提出了一种苹果识别定位的方法,通过对苹果图像进行预处理,利用支持向量机实现苹果目标定位 [3] 。Meng等利用边缘检测算法提取目标物与图像背景间的边界线来检测目标,采用Canny算子和霍夫变换对目标轮廓进行检测,实现对果实的精确识别定位 [4] 。李致金等对采集的图像进行预处理,采用主轴法对工件轮廓进行识别,计算出工件的矢量位置 [5] 。王丹丹等首先利用K-mean聚类算法得到苹果轮廓,通过去噪、平滑处理,利用转动惯量法提取目标对称轴,实现目标的二维定位 [6] 。在文物修复过程中,计算机视觉的前沿技术可以在出土文物的碎片拼接、复原以及原初形态的数字化重建方面发挥协助作用。“比如有些器形出土后,它的材料酥了或者折损了,那么通常就可以用AI建模来进行修复,从而实现在虚实集成世界里面做复原,考古拼接的效率就会大大提高。”著名考古学家、南方科技大学讲习教授唐际根说。
在此基础上,提出利用计算机视觉进行文物复原的新思路与新技术,探索其应用于文物复原的优点与局限。同时,本论文还将分析计算机视觉与传统文物修复技术的结合,以及该领域的未来发展趋势和前景。
2. 图像采集与预处理
2.1. 计算机视觉
计算机视觉要研究怎样让电脑来理解并解读影像。该方法涉及到图像处理,图像分析,模式识别,机器学习等各个方面,为计算机提供了一种新的方法。目前,基于深度学习的机器视觉技术与人类大脑的运作原理相似。人类的视觉系统是这样的:首先,人类的眼睛会捕捉到一个像素点,然后进行初级加工,这时大脑会判断出一个物体的形状,最后,大脑会判断出这个物体的形状为球体,如图1所示。
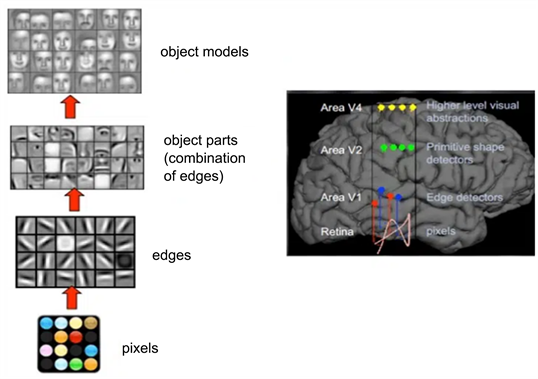
Figure 1. Schematic diagram of human vision
图1. 人类的视觉原理图
机器的方式也相似:建立多层神经网络,低层识别基本的图像特征,一些底层特征构成更高层特征,最终通过多个层级的组合,最终在顶层做出分类,如图2所示。

Figure 2. Image acquisition and pre-processing
图2. 图像采集与预处理
2.2. 基于数据驱动的算法及图像灰度化处理的Candy算法
在计算机视觉的研究中,已经发展出了一套完整的基于数据的方法。该方法无需在编码时直接定义每种图像的类别,而是根据不同类别的图像,设计相应的学习算法,通过分析不同类别的图像,进而学习每个类别的视觉特征。在此基础上,本文提出了一种基于图像的图像分类方法,该方法首先采用带有标记的图像,然后将其输入计算机,然后对其进行处理。因此,按照下面的步骤来分解:
(1) 训练集将由N个图像组成,包含M个类别,每个图像都被标记为其中一个类别。
(2) 将训练好的分类器应用于每一类外部特征的训练中。
(3) 通过对新生成的图像样本进行类别预测,评价分类效果,并与实际图像进行比较。
当前主流的图像分类方法主要是卷积神经网络(CNN)。该算法先把图像输入到网路中,再由网路将图像归类。卷积神经网络首先是“扫描仪”的输入,这个“扫描仪”也无法一次把全部的训练资料都分析出来。例如,如果你想要一张100 × 100的图片,那么你就不必用10,000个结点组成的网页了。取而代之的是,你首先要建立一个10 × 10的扫描图层,以此来扫描图片10 × 10像素。接着,扫描器回将右边的一个象素移到另一个10 × 10的象素上,以形成滑动窗口,如图3所示。
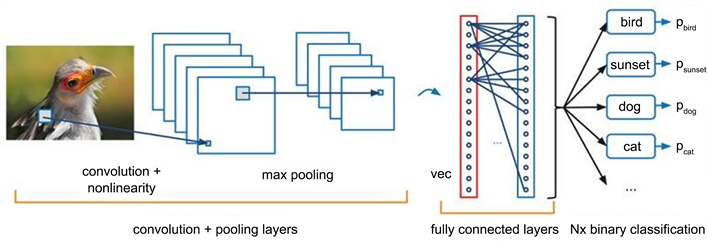
Figure 3. Image classification architecture
图3. 图像分类架构
将数据传输到卷积神经网络而不是传统的网络层。在此基础上,本文提出了一种基于卷积神经网络的多层神经网络模型,该模型仅对与其最近的邻域节点进行操作。通常情况下,除了卷积层之外,还会存在一个池化层。“池化”是一种对具体信息进行筛选的方式,常用的“最大池”技术就是将具有最多特征的“2*2”矩阵进行传输。
目前,绝大部分图像的分类技术都是基于训练于ImageNet数据集的模型。这个数据集包含了大约120万张高分辨率训练的图像。这些测试图像并没有初始注释(也就是没有分割或者标签),由此,算法必须产生一些必要的标签来指定这些测试图像中存在哪些对象。
现有的许多机器视觉演算法,都是由牛津,INRIA,XRCE等顶尖电脑视觉研究小组以ImageNet为基础,开发出一套完整的图像处理系统。一般情况下,机器视觉系统采用的是一个复杂的多层次通道,而且,在前期的研究中,大多数算法都是通过对少量参数进行人工调整。
Alex Krizhevsky (NIPS 2012)是第一次ImageNet比赛的得主,基于Yann LeCun提出的神经网络模型,提出了一种深层卷积神经网络。网络结构共有7个隐藏层,其中第一层是卷积层,第二层是全连接层。在各隐藏层中,该方法的启动函数是线性的,其学习速度和性能均优于传统的逻辑元。此外,该系统还利用竞争归一化的方法,在邻近单位的活跃程度较高时,抑制隐性活动,从而促进了强度的改变,如图4所示。
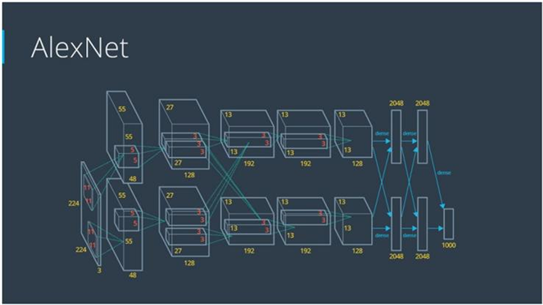
Figure 4. Deep convolutional neural networks
图4. 深度卷积神经网络
在硬件需求方面,Alex已经在两块 NvidiaGTX 580 GPU上实现了一个效率极高的卷积网络,其运算速度可达1000多个要想法就是在一张图片上寻找亮度改变最大的地方。最大的变化,就是在一个梯度的方向上。通过索贝尔算子计算光滑图像中每个像素点的梯度,具体步骤如下:
1. 将彩色图像转换为灰度图。
2. 为了减轻边缘检测对噪音的过度敏感,研究人员可以采用高斯滤波器等对图像进行平滑处理,以去除干扰信号。
3. 寻找图像的灰度梯度。Canny的主要想法就是在一张图片上寻找亮度改变最大的地方。最大的变化,就是在一个梯度的方向上。可通过索贝尔算子得到光滑图像中各象素点的梯度:
(1) 首先,可以利用Sobel算子求出x轴、y轴两个方向上的梯度值,然后求出它们的斜率;
(2) 再根据G_X、G_Y,可以求出各象素点上的梯度幅度G;
(3) 接下来,用G来取代每个象素点。当边界发生剧烈变化时,随着G值的增大,相应的色彩也会呈现出白色;
(4) 最后,由于边界一般很厚,很难确定其真实的位置,因此梯度的方向θ也必须被保存。
4. 采用非最大压缩技术,将所述像素点沿梯度θ方向进行比较,如果与两边相比最大,所述象素点被保持,反之,则被压制(设置为0)。这个步骤的目的是将模糊的边界变得清晰,剔除一大部分不是边缘的点。
5. 双门限边沿连通法。
规则:设置最小值和最大值(mainVal和maxVal)。大于maxVal的边缘一定是边缘(即保持),而低于mainVal的边缘为非边缘(即舍弃)。对于在这两个区间内的数值,可以判定它是不是连接到真实边界(强边界)上,相连就保持,否则放弃。
6. 二值化图像输出结果。
2.3. 对象检测之基于区域的卷积神经网络(R-CNN)算法
进行目标识别时,一般需要对个别目标进行封闭框和标记。这不同于分类/定位任务——对大量对象进行分类和查找,而非单一对象。对于对象的认知,你只要将对象分为两类:对象围绕框和没有对象围绕框。例如,在汽车辨识中,必须使用边界盒子对已知图像中的所有车辆进行检测。
当采用滑动窗的方法进行图像分类、定位等时,就必须对多种对象进行卷积神经网络。因为卷积神经网路会把影像中的每一个目标都当作目标或是背景来辨识,所以必须要在大范围、大范围内利用卷积神经网路来辨识目标,但这样做的代价太大!
针对这个问题,研究者们提出了一种新的方法,即将图像中的“斑点”区域提取出来,以此来发现物体所在的区域。这将极大地加快运算速度。一类是基于区域卷积神经网络(R-CNN)。此模式的运算法则是:
在R-CNN模型下,可以先使用选择搜寻算法来侦测到可能的目标,再产生约2000个区域建议。在这些区域建议上执行一次卷积神经网络。最后,将各卷积神经网络的输出输入到支撑向量机(SVM)中,通过线性回归对目标边缘框进行修正,如图5所示。

Figure 5. Convolutional Neural Network (R-CNN) algorithm
图5. 卷积神经网络(R-CNN)算法
在本质上,将目标发现问题转变为了图像分类的一种形式。然而,这种方法也有一些缺点:学习速度较慢,占用的硬盘空间较大,而且运算速度较慢。
快速R-CNN是R-CNN的第一个升级版本,通过引入一系列改进措施,大幅度地提升了目标检测速度。在特征提取之前,实施抽取操作,以让卷积神经网络只需一次完成整个图像的处理。也就是说,研究人员可以使用一个softmax层代替支撑向量机,随后再通过扩展神经网络对图像进行预测,如图6所示。
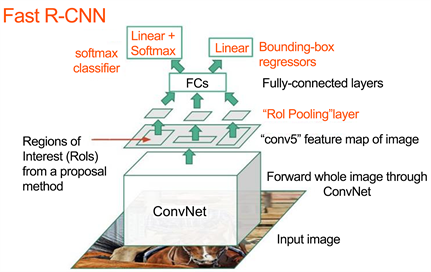
Figure 6. Convolutional neural network in the upgraded Fast R-CNN algorithm
图6. 升级版Fast R-CNN算法中的卷积神经网络
FastR-CNN的运算速度远超R-CNN,因为在同一张图片上,只有一个CNN可以训练。然而,使用择性搜索算法产生局部特征值的过程耗时较长。快速卷积神经网络是一种利用深度学习进行目标检测的方法。针对这一问题,本项目拟研究一种新的局部最小化算法:RPN (RPN)。RPN决定要看一看“哪里”,这样就可以简化整个推论的过程。RPN对每个位置进行快速而有效的扫描,以判断某个区域中是否还需做更多的处理,如图7所示。
一旦得到了区域建议,研究人员可以直接输入到Fast R-CNN模型中。此外,还可以加入一个池化层、若干全连接层、一个softmax分类层以及一个边界框回归器。
总的来说,Faster R-CNN是一种更快、更准确的方法。尽管后续的算法对其进行了大量的改进,但是很少有算法能比FasterR-CNN更好。换言之,快照R-CNN或许算不上最容易或最快的对象侦测,但仍不失为最佳的侦测方式。
近几年来,主要的目标检测算法都在向着更快速更有效的方向发展。这种趋势在You Only Look Once (YOLO),单帧多框检测(SSD)、区域全卷积神经网络(R-FCN)等方法中表现得尤为突出。所以,这三种方法与上面提到的3种成本高昂的R-CNN方法还是有区别的。
2.4. 目标跟踪算法之生成算法和判别算法
目标追踪,就是在一个特定的场景中,追踪一个或多个特定的物体的过程。传统的方法是将视频与现实环境进行互动,并在发现原始物体后再进行观测。如今,物体追踪技术在无人驾驶方面也非常重要,比如优步、特斯拉的无人汽车。根据观察模型,目标跟踪算法可分为两种类型:生成算法和判别算法。生成算法不需要考虑背景信息,而采用了生成模型描述表观特征,通过最小化重建误差搜索目标,达到跟踪目的。一个例子是主成分分析算法(PCA)。判别算法被用于区分物体和背景,其表现更具有稳健性,逐渐成为跟踪对象的主导方法(判别算法又被称为“检测跟踪法”),是基于深度学习的判别模型。目前,Deep Learning Tracker (DLT),即基于深度学习的目标跟踪网络,是目前最受欢迎的目标跟踪方法。该方法采用了离线预训练和在线微调的两个阶段进行实验。具体流程如下:
(1) 离线非监督预训练方法利用海量自然影像样本获取具有普遍意义的物体表征,并在此基础上对层叠降噪自编码器进行预训练。层叠降噪自编码器通过引入噪声处理和重建的方式,提升了输入图像的特征表达能力。
(2) 在此基础上,利用原始图像中的正、负样本对神经网络进行精细调整,从而实现目标与背景的有效分离。DLT将粒子滤波器应用于意图模式中各区块的概率,也就是该类别的可信度,并选取可信度较高的区块为目标。
DLT在模型更新时采用有限阈值,如图8所示。

Figure 8. Deep Learning Tracker (DLT)
图8. 基于深度学习的目标跟踪网络(DLT)
由于CNN在图像分类、物体检测等领域具有独特的优点,目前已经成为当前计算机视觉与视频跟踪领域中最主要的一种深度学习方法。通常情况下,大型卷积神经网络不仅可以用来做分类器,也可以用来追踪。以FCNT、MD Net为代表的目标跟踪方法是一种基于卷积神经网络的方法。
在本研究中,充分探讨并充分利用了VCG的卷积4-3和5-3卷积的特征选择网络。在此基础上,为了防止噪声过拟合,FCNT还分别设计了两条附加信道(SNet): GNet用于提取物体的类信息。SNet在区分这个物体时,将其与外部相似的背景进行了区分。
这两种网路的工作方式为:先利用第一框架内已知的包围盒来建立物件的影像。然后将新的图像分割成两个部分,然后将图像中的图像分割成两部分,然后再将图像中的图像分割出来,然后将图像中的图像分割成两部分。最终,通过结合SNet和GNet,分类器获取了两种不同的预测误差,并基于干扰程度,跟踪器来决定使用哪种投影作为最终目标。
FCNT如图9所示。
相对于FCNT的思路,在MD Net中利用视频的全部序列来追踪物体运动。与此不同的是,前者为深度学习,以最小化重建误差搜索目标,但这一思想与追踪有一些偏差。在同一个视频中,一个类别的物体也可能是另一个视频中的背景。因此,MD Net提出了“多域”这一概念,结合共享层和新的全连接层,能够在每个域独立区分对象和背景。如图10所示,MD Net可被划分为两个组成部分,包括K个特定目标分支层和一个共享层:每个分支包含一个具有softmax损失的二进制分类层,用于区分每个域中的对象和背景;共享层与所有领域共享,以确保通用表达。
这些年来,深度学习研究人员尝试了不同的方法来适应视觉跟踪任务的特征,而且已经探索很多方法:
· 应用到诸如循环神经网络(RNN)和深度信念网络(DBN)等其他网络模型;
· 设计网络结构来适应视频处理和端到端学习,优化流程、结构和参数;
· 将深度学习与传统计算机视觉或者其他领域的方法(例如语言处理和语音识别)相结合。
2.5. 语义分割之全卷积网络(FCN)
在机器视觉中,分割是一项重要的工作,FCN对图像像素级的分类,解决语义级别的图像分割(semantic segmentation)问题并加以标注和归类。对于每个像素,语义划分指对其角色进行语义分析。确定它是一种具体的什么物体。正如上面所示,除了辨认人物,道路,车辆,树等等,还要界定每一个对象的界限。所以,必须使用模型来预测稠密的像元。
与其他计算机视觉任务相似,卷积神经网络在分割任务方面取得了巨大的成功。其中一种最被广泛采用的方法是通过滑动窗口对块进行分类,利用每个像素周围的图像块来对每个像素进行分类。然而,由于不能在重叠的块之间重复使用共享特征,这种方法的计算效率非常低。
解决方案就是加州大学伯克利分校提出的全卷积网络(FCN),FCN可以接受任意尺寸的输入图像,利用了反卷积层对最后一个卷积层进行了上采样的方法,使它能恢复尺寸,对像素产生预测,最后在上采样特征图进行逐像素的分类,如图11。
然而,仍然存在一个困扰的问题:进行卷积运算时,原始图像分辨率的计算成本非常高。为了解决这个问题,FCN在网络的内部采用了下采样和上采样两种策略:下采样层被称为条纹卷积(striped convolution),而上采样层则被称为反卷积(transposed convolution),如图12所示。
当前的语义分割研究主要倚赖于完全卷积网络,例如空洞卷积、DeepLab和RefineNet。
2.6. 实例分割
除语义划分外,示例分割还对不同种类的示例进行了分类,例如5种颜色对5辆车进行了标识。在实践中,常会遇到一些较为复杂的难题。我们将面对由多个目标相互叠加、背景各异的场景组成的复杂场景,我们不但要对其进行归类,更要明确其边界、差异及相互间的联系!
至今为止,我们已经展示了多种富有创意的方法,利用卷积神经网络的特征,以高效的方式定位图像中的不同对象。我们是否能够进一步推广这项技术?也就是说,对每个对象的精确像素进行定位,而不仅仅是用边界框进行定位?Facebook AI则使用了Mask R-CNN架构对实例分割问题进行了探索,如图13所示。
与Fast R-CNN和Faster R-CNN类似,Mask R-CNN的底层是参考Faster R-CNN在目标检测方面表现出色。可以借鉴其思想,进一步将其应用于像素级分割。
为进行像素级分割,Mask R-CNN在Faster R-CNN模型的基础上增加了一个分支。这分支会生成一个二进制掩码来表示每个像素是否属于目标对象。该分支是基于卷积神经网络特征映射的全卷积网络。将给定的卷积神经网络特征映射作为输入,输出为一个矩阵,其中像素属于该对象的所有位置用1表示,其他位置则用0表示,这就是二进制掩码。
此外,在未作任何改动的情况下,在原FasterR-CNN框架下,所选取的特征映射区(RoIPool)或者原图的区域略微交错。因为图象的分割是一种与包围盒不一样的象素级别的特征,所以它的检测结果是不精确的。asR-CNN通过对 RoIPool进行改进,采用了目标区域对齐算法,提高了算法的准确性。在实际应用中,RoIlign采用了双线性内插的方法,以消除对图像的舍入,从而降低了对图像的检测与分割的准确性。
一旦产生这些掩码,Mask R-CNN将结合RoIAlign和Faster R-CNN的分类和边界框,以实现准确的分割,如图14所示。
3. 研究结论
在本研究中,设计了一种基于计算机视觉的方法来进行文物修复,并且展示了该方法在文物修复中的性能和效果。据实验与结果分析,得出以下结论:
1) 文物修复方法的有效性:本课题的研究成果显示,利用机器视觉技术进行文物复原,可以明显提高文物的损毁程度。通过对文物的损毁识别,图像复原,以及对其进行三维重构,最终实现了对该建筑的原始风貌和完整的复原。
2) 文物修复中计算机视觉的重要性项目研究结果表明,基于机器视觉的文物恢复方法能够显著提升文物的损伤水平。通过对遗址的损伤辨识、影像恢复、三维重建等手段,使其恢复到原有的面貌和完整性。
3) 应用前景:利用计算机视觉的文物修复方法具有广阔的应用前景。本项目研究成果可用于博物馆、文物保护单位、文物修缮专家等领域,实现对文物的自动、高效修复。另外,由于电脑视觉科技的进步,这将在文物修复领域发挥巨大作用,为文物保护和文化传承带来更大的贡献。
综上所述,本研究通过实验和结果分析,展示了基于计算机视觉的文物修复方法的性能和效果。强调了计算机视觉在文物修复中的重要性和应用前景,相信这项研究将对文物保护和文化传承产生积极的影响。
即使使用了上采样和下采样层,由于在池化过程中造成的信息丢失,FCN会产生相对粗糙的分割映射。SegNet是一种比FCN (使用最大池化和编码解码框架)更高效的内存架构。在SegNet解码技术中,从更高分辨率的特征映射中引入了shortcut/skip connections,以改善上采样和下采样后的粗糙分割映射。
基金项目
2023年大学生创新创业训练计划项目(S202312715062):计算机视觉:让文物“活”过来;西京学院横向课题:基于5G物联网技术的智慧粮仓监控系统的开发。