1. 介绍
长期以来,追求准确及时的股票价格预测一直是金融研究的前沿课题之一。由于股票市场固有的波动性,再加上众多经济、政治和公司特定因素的复杂相互作用,股票价格预测是一项极具挑战性的任务。金融监管机构和政策制定者正在共同努力,利用先进的预测工具来避免金融危机。股票价格预测技术经历了创新演变,从时间序列分析方法 [1] 过渡到机器学习 [2] ,并进一步发展到深度学习 [3] 。
对于金融数据作为一种特殊的时间序列,传统的计量经济学模型如ARIMA和Goach一直被用于价格预测 [4] ,但金融数据的非线性和非光滑性导致这类模型的预测有很多局限性 [5] 。近年来,随着机器学习技术的飞速发展,一些经典算法在股价预测中得到了广泛的应用。将支持向量机(SVM)与KNN相结合的融合框架应用于沪深股指的价格回归预测 [6] 。随机森林已被用于股票市场趋势预测,准确率为85%~95% [7] 。众多学者和专家对启发式算法在股票预测中的应用进行了探索。金等人在 [8] 开发了一个智能决策支持系统,以确定最佳的交易规则,然后采用制定最佳的买入或卖出策略。Das等人 [9] 提出了一种基于进化框架的萤火虫算法,通过对OSELM模型的变换来最小化特征,从而提高未来股价预测的准确性。SrijiranonK等人 [10] 提出了一种基于主成分分析(PCA)和长短期记忆(LSTM)的股票价格预测模型,实验论证该模型能够准确预测股价波动趋势。
本文的结构如下:第2章介绍研究所需要用到的理论知识;第3章介绍模型的构建思路和基本流程;第4章介绍实验论证所提出模型的优越性,并设置两个模型来进一步说明。
2. 背景理论
本部分介绍了本研究所使用的相关理论。包括主成分分析、完全经验模式分解和长短期记忆网络。
2.1. 主成分分析(PCA)
主成分分析(PCA)是最知名的减少消耗的技术之一 [11] 。PCA是一种特征变换方法,用于通过将许多变量转化为更少的变量来降低海量数据集的维度,同时保留大集合中的大部分信息。这种技术节省了运行模型的资源并提高了准确性。在股票预测领域,由于技术指标取决于趋势、波动率、成交量、动量和每日回报,因此它们可以推广到各种场景 [12] 。PCA可以将大量技术指标视为输入特征,而不会遇到维数灾难。PCA的优点可以应用于各种数据源和应用,例如游客行为分析和海上风力涡轮机选择。此外,一些研究表明,将机器学习和PCA相结合可以显著改善模型,特别是与成熟的降维技术相比。PCA的基本步骤如下:
1) 对原始数据进行标准化,以确保每组数据对分析的贡献相等。在数学上,归一化方程表示为式(1),其中
和
分别表示特征的最小值和最大值,x表示原始值,而
表示归一化后的新值。
(1)
2) 根据归一化数据矩阵建立协方差矩阵。由于数据集是n维的,这将导致一个表示为矩阵A的
维的协方差矩阵。
3) 第三步是计算协方差矩阵的特征向量和特征值来识别主成分。矩阵A的特征值
通过求解式(2)来找到,其中I表示与A相同维的单位矩阵,目的是满足矩阵减法的基本要求。对于每个
,可以通过求解式(3)来找到对应的特征向量v。
(2)
(3)
4) 通过将具有相应特征值的特征向量从最大到最小排序来减少原始矩阵。具有最高特征值的特征向量成为数据的主成分。在此之后,首先选择p个特征值以降低维度,然后接收主成分。
2.2. 改进完全集合经验模态分解(ICEEMDAN)
ICEEMDAN是一种时域信号分解方法,是EMD的改进版本。为了提高后者对模态混叠的敏感性,提出了CEEMDAN分解来消除噪声的影响,以减少模态混叠;为了进一步改进CEEMDAN分解,提出了ICEEMDAN分解,它改进了噪声添加策略,以自适应地添加噪声。ICEEMDAN还包括对噪声添加的优化,以提高分解质量和效率。
2.3. 长短期记忆神经网络(LSTM)
LSTM的门结构一共有3个,分别是遗忘门(Forget Gate)、更新门(Input Gate)以及输出门(Output Gate) [13] 。相比于原始的RNN的隐含层(Hidden State),LSTM增加了一个细胞状态
(Cell State)。神经元结构图如图1所示。它们对应的计算公式分别为:
(4)
其中,
是上一时刻的隐藏状态,
为激活函数,通常是sigmoid函数,
、
和
分别为遗忘门、输入门和输出门状态结算结果,
、
和
分别为遗忘门、输入门和输出门的权重矩阵,
、
和
分别为遗忘门、输入门和输出门的偏置项,LSTM的最终输出由输出门和单元状态共同确定。
在图1中,
为候选值向量,输入值和候选值向量的乘积用来更新细胞状态,计算过程如下:
(5)
(6)
(7)
(8)
(9)
其中,
为输入单元状态权重矩阵,
为输入单元状态偏置项,tanh为激活函数。遗忘门控制当前时刻细胞状态丢弃信息的多少,
为神经元输出值,
为当前时刻隐藏状态。
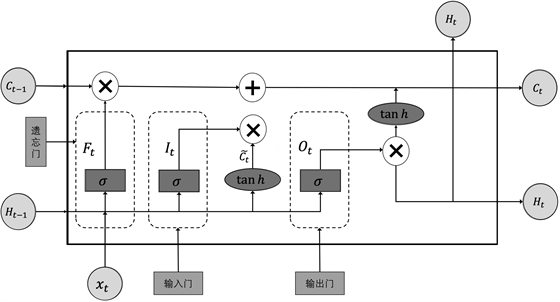
Figure 1. LSTM neuron structure diagram
图1. LSTM神经元结构图
3. 模型介绍
本研究的目的是使用PCA、ICEEMDAN和LSTM的组合为中国股票市场的收盘价提出一个混合框架。所提出的模型的总体架构如图2所示。该架构分为特征工程和预测模型两个部分。
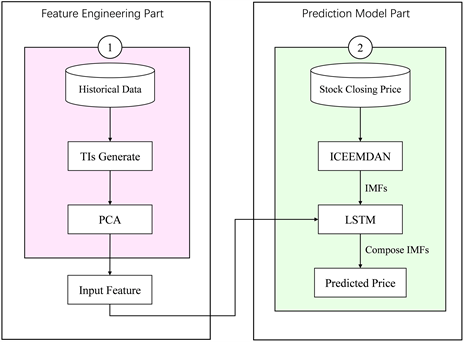
Figure 2. The specific process of the proposed fusion framework
图2. 所提出融合框架的具体流程
3.1. 特征工程
本小节描述了为预测模型构建输入特征的过程。本研究选取了8个技术指标作为模型的输入特征。简单地说,特征越多,过度适应的风险就越高。为了解决这一问题,采用主成分分析对特征空间进行精简,同时考虑一组主特征。为了从PCA创建主成分,需要遵循图3所示的步骤。首先,从https://www.tushare.pro/获得历史数据,包括开盘、高点、低点、收盘价和成交量数据。此后,使用https://github.com/bukosabino/ta中的“ta”包来生成技术指标。然后,在使用主成分分析进行数据降维之前,对技术指标进行归一化处理。主成分分析的结果是主成分,在本研究中,主成分是从第一个主成分开始,直到解释的方差比率之和大于95%。因此,这表明技术指标中95%的信息可以用“n-principl”原理来解释。
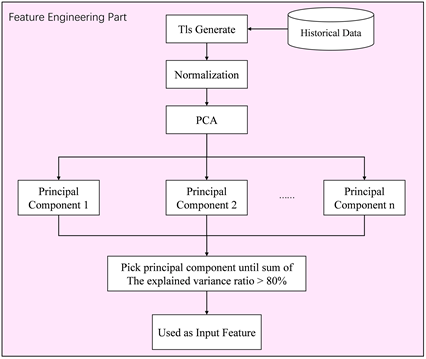
Figure 3. Constructing principal components of technical indicators
图3. 技术指标主成分构建过程
3.2. 预测模型
本研究提出了一种基于ICEEMDAN和LSTM相结合的集成预测模型,以最大限度地提高预测效果,并最大限度地降低计算复杂度。所提出的模型如图2所示,包括以下四个步骤:
1) 首先,应用ICEEMDAN算法将原始股票收盘价时间序列分解为多个独立的IMF分量和一个残差分量Residue。
2) 其次,将来自特征工程部分的主成分作为模型的输入特征。
3) 接着,LSTM模型被用作每个IMF分量的预测工具,相应的分量获取相应的预测值。其中,LSTM是由每个IMF单独训练的,因此,网络参数、神经元数目和批量大小等参数都是为每个IMF专门调整的。这是混合ICEEMDAN-LSTM模型优于单一LSTM模型的显著差异。
4) 最后,在获得IMF的预测结果后,使用组合每个预测IMF以获得最终的预测股票收盘价。然后,使用性能指标与其他模型的结果进行了比较。
3.3. 评价指标
为了论证所提出模型的好处,本研究采用了四个指标:平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和决定系数(R2)。令
表示实际数据,
表示预测结果,其中N表示时间序列的长度。详细描述见表1。
4. 实验部分
本节介绍利用所提出混合模型来预测中国股市股票指数价格的实验内容。
4.1. 数据收集
本研究以中国股市收盘价为例,以一步预测验证所提出模型的预测准确性。从https://www.tushare.pro/获得包括开盘价、当日最高价、当日最低价、成交量、成交额、收盘价,时间跨度是从2018年1月2日到2022年12月30日,只选取交易日的数据用于研究。所选数据的收盘价走势在图4中可视化。
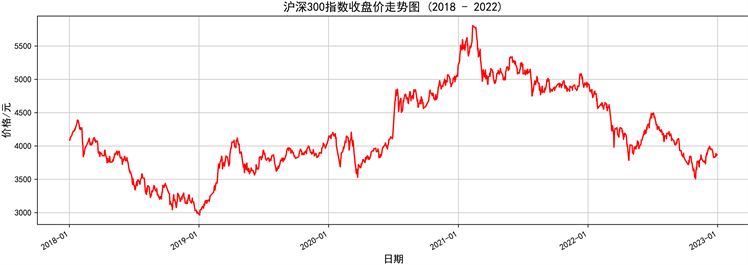
Figure 4. The daily closing price of CSI 300
图4. 沪深300的每日收盘价
4.2. 技术指标
技术指标是计算机系统按照一定的数学统计方法,运用一定的数学计算公式或定量模型,生成的一定的指标值或图形曲线。用指数技术判断股价未来走势的分析方法,就是技术指数分析法,属于技术分析。本研究选取了与股市收盘价相关的8项技术指标。类别和名称见表2。
4.3. 实验结果
ICEEMDAN分解分量及其预测结果
在建立预测模型时,利用ICEEMDAN将股票收盘价格作为历史数据转化为新的数据。如图5所示,
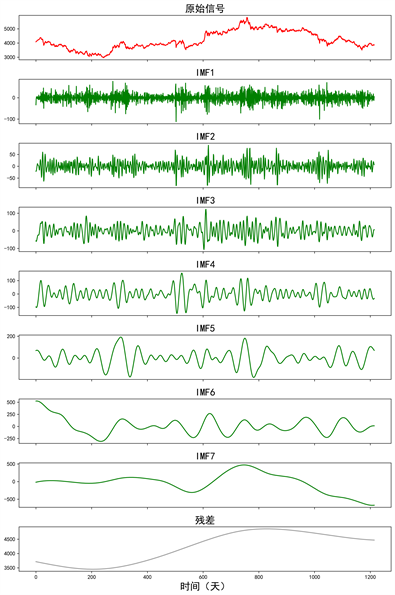
Figure 5. Original closing price and decomposed IMFs
图5. 原始收盘价和分解后的IMFs
演示了使用ICEEMDAN创建IMF的分解结果。其中的6个IMF是从最初的收盘价序列和从高到低频率的顺序来分解的。然而,根据原始数据,IMF的数量是不同的。重复ICEEMDAN过程,直到在图5中的残差项上只有一个全局最大值和最小值。如果原始数据更改,IMF的数量也将更改。另一方面,当ICEEMDAN应用于相同的数据时,IMF的数量仍然是相同的值。另外还需要注意的是,IMF是通过从原始收盘价中减去得到的,因此所有IMF的总和与原始的完全相同。因此,所有IMF的预测结果的总和可以被认为是对原收盘价的预测结果,本研究后续得到的最终结果基于该思路。
图5表明,它可分为三组。第一组是原始数据中的高频分量。这一组是由最初的几个IMF代表的,噪音很大。第二组是中频分量。由具有中等噪声的中心IMF表示。最后一组是低频分量。这一组由最近几个几乎没有噪音的IMF代表。而且,最后的残差项是和一只股票的走势相媲美的。假设LSTM能够准确地预测低频IMF,但它不能很好地预测高频IMF。为了最大限度地提高预测效率,LSTM是由每个IMF单独训练。因此,每个IMF的超参数、隐含层数和权重也是不同的。
本研究选取的技术指标共有8个,它们对应的类共有22个,将它们都用作特征不仅会加大计算量,还容易导致过拟合,因此,我们采用了PCA对22个待选特征进行筛选,实验得到7个主成分,即他们的方差贡献率大于等于95%,如图6所示。接着将对收盘价进行ICEEMDAN分解得到的7个IMF和1个残差项分别作为目标变量,单独训练每一个LSTM,训练所用的超参数见表3。
对每一个LSTM来说,我们统一设置数据集的30%为训练集,70%为测试集,经过PCA降维后,得到的7个主成分作为输入特征,每一个LSTM中IMFs分别作为目标变量,训练后的预测结果如图7所示。从图7中可以看到,紫色虚线与红色实线拟合程度更好,其次是绿色虚线,最差的是红色虚线,也就是说,本文提出的ICEEMDAN-PCA-LSTM的预测效果优于ICEEMDAN-LSTM和LSTM模型。

Figure 6. Change in principal component variance contribution rate
图6. 主成分方差贡献率变化

Table 3. Configuration of hyperparameters for each LSTM
表3. 各个LSTM的超参数配置
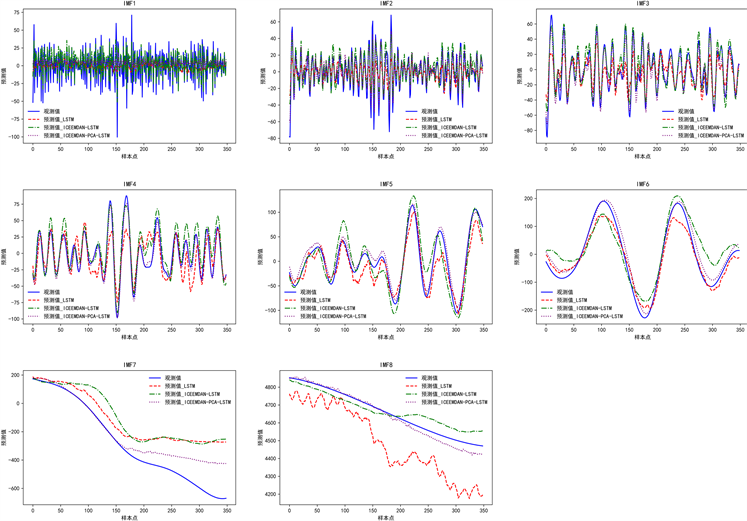
Figure 7. Comparison of IMFs prediction results figs
图7. IMFs预测结果对比
接下来,本研究将以上各个IMF分量的预测结果对应相加,最终得到原始数据集的预测结果对比图8。与预期结果基本吻合,本文提出的ICEEMDAN-PCA-LSTM的预测效果最佳,其次是ICEEMDAN-LSTM,最差的是LSTM,得到它们的评价指标如表4。
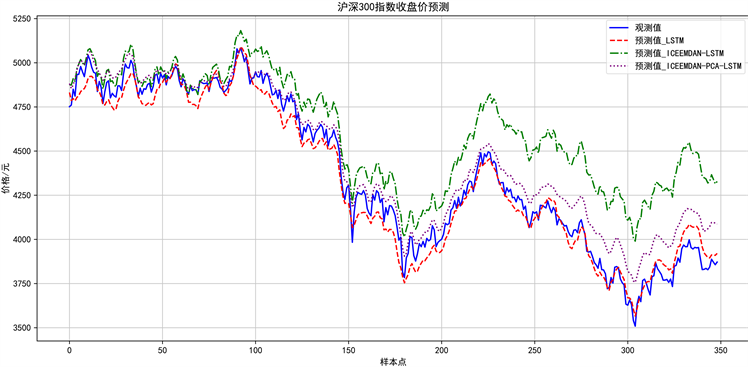
Figure 8. CSI 300closing price forecast
图8. 沪深300指数收盘价预测
Table 4. Comparison of four evaluation indicators
表4. 3种评价指标对比
5. 结论与讨论
本研究旨在探讨股票价格时间序列的预测问题,选取了Tushare大数据社区提供的沪深300指数历史数据作为研究样本。运用数学统计方法计算了如MACD、RSI、MA等多种技术指标,这些指标基于历史的收盘价、开盘价、当日最高价和最低价等基础数据,以反映股票市场的波动特征。
研究初步选定了八个技术指标作为预测模型的输入变量,并通过PCA主成分分析方法进行降维处理,筛选出主成分贡献率超过95%的技术指标,作为最终的输入特征。同时,采用完全自适应经验模态分解法(ICEEMDAN)对收盘价进行分解,得到七个本征模态函数(IMF)和一个残差项。以PCA筛选的主成分变量作为特征,七个IMF和残差项作为目标变量,分别构建八个长短期记忆(LSTM)网络进行训练和预测。预测结果通过重构相加,得出最终的收盘价预测值。
为了验证模型效果,本研究设立了两个对照模型,并选用四个评价指标作为模型效能的衡量。模型比较的图示展示于图8,评价指标的比较结果列示于表4。通过对比分析,可以看出三种模型的预测效果呈递增趋势。其中,ICEEMDAN方法能有效提升LSTM预测的准确度,这是因为在未分解的收盘价时间序列中含有大量噪声,这些噪声若直接用LSTM预测会影响结果。ICEEMDAN能有效压制噪声,保留时间序列中更多信息。此外,PCA主成分分析在输入特征的降维过程中,排除了那些贡献率较低的特征,这些特征可能增加模型复杂度且不增加预测效果,因此最佳的策略是将它们排除。在构建数据集之前无法识别并排除这些特征,因此采用降维方法排除贡献率较低的特征以提升预测性能。