1. 概述
为积极响应习总书记提出的“档案工作要由封闭向开放、由重保管向重服务转变,要及时向领导机关、向社会提供有价值的信息,为经济建设、社会发展服务”的号召,通过对成都市城市建设档案进行全面的挖掘和综合分析,构建城建档案知识图谱,以城市建设为脉络,形成集城市建设历史、空间地理信息等数据于一体的知识图谱体系,记录成都市建设践行新发展理念的公园城市的发展历程,为未来城市规划设计、建设和管理提供信息协同分析,为城市社会治理提供辅助决策分析的数据支撑。
成都市城市建设和自然资源档案馆收集、接收、保管(存)、利用城市建设和自然资源档案,主要有民用建筑、工业建筑、市政工程、公用设施、交通运输等城市建设工程档案和城市建设管理档案。目前,馆藏档案共有纸质档案240万余卷、20万余件,电子档案光盘3万余张,图书、资料及报刊4000余本(册)等。其中,城市建设档案约174万余卷、7万余件(城市建设工程档案170万余卷,城市建设管理档案4万余卷、7余万件)。
知识组织是图书情报学领域研究的核心内容,是对无序、混乱、分散的知识进行整理、提取、排列和序化,使之成为一个有序的结构化系统,从而使知识得到增值。知识组织从早期对纸质文献的分类、排架、主题标引、编撰主题词表到如今在技术赋能下挖掘知识之间的关联性来构建复杂网络,其组织程度和粒度在不断加深,组织方式也从手工操作过渡到机器理解并推理 [1] 。纵观国内外知识组织相关的研究文献,可以将其概括为以下3个方面,即知识组织理论研究 [2] - [10] 、知识组织工具方法研究 [4] - [14] 、知识组织应用领域非常广泛,在档案领域相关研究主要聚焦于以下6大研究领域。1) 图书馆知识组织图书馆领域知识组织对象早期以纸质版文献为主,采用卡片索引等传统方式进行资源组织 [1] [2] ;2) 医学领域知识组织 [3] [4] [5] ;3) 网络社区知识组织 [6] [7] [8] ;4) 科技文献知识组织 [2] [3] ;5) 政府资源组织 [4] [5] [6] ;6) 数字人文领域知识组织 [7] [8] [9] 。
综上,知识组织理论研究始终是图情档学科研究的重心和热点,是需要伴随时代变迁、技术进步而动态更新其研究内容,传统的理论研究只能局限于当下的时代背景,而如今在大数据时代,知识组织方法技术及应用场景都在发生变革,以知识图谱为研究手法,挖掘档案数据的知识组织,成为当前的热点。
研究按照知识图谱组织全流程“描述–抽取–关联–应用”逻辑思路展开,从“外因牵引”和“内因驱动”两个维度解析语义化知识组织必要性,分析城建档案知识组织目标及原则;其次,基于城建档案结构语义和内容语义特征构建城建档案语义化知识组织逻辑框架,并根据框架逐层解构,进行城建档案知识元描述、抽取、关联和应用。研究技术路线如图1所示。
2. 研究内容
研究以城建档案语义化知识组织为核心,通过引入知识元理论,从城建档案知识元描述、抽取、关联和应用4个维度构建知识图谱。具体研究内容如下。
1) 城建档案语义化知识组织体系框架构建。从“外因牵引”和“内因驱动”两个维度分析语义化知识组织的目标和原则,进而基于城建档案结构语义和内容语义来构建城建档案知识图谱框架。
2) 城建档案知识元语义描述。从元数据描述和本体描述两个层面分别构建城建档案知识元元数据描述规范和知识元本体语义描述模型。
3) 城建档案知识元抽取。根据词法、句法特征,采用机器学习方法抽取城建档案中知识元实体(标识术语)及知识项。其中知识元实体是指城建档案中包含的项目名称、建设单位、时间、空间、建设管控等知识,知识项是指描述实体的属性值,通过选取触发词作为抽取规则和人工梳理方式抽取知识项。
4) 城建档案知识元关联。从知识元外部结构和内部结构两个维度对知识元关系进行分类,对于外部结构——知识元实体之间的关系,采用深度学习模型CNN和Bi-LSTM两种方法识别知识元实体关系;对于内部结构——知识元实体与属性关系,采用规则模板方式抽取,并以知识图谱可视化方式进行呈现。
3. 城建档案知识图谱框架构建
城建档案知识组织是一个系统的工程架构,研究从知识细粒度控制单位——知识元视角入手,基于城建档案结构语义和内容语义来构建知识组织逻辑框架体系,即知识元描述、知识元抽取、知识元关联及知识元应用。
3.1. 知识元描述
1、提取知识元核心要素
结合城建档案特征,并参考现有的成熟元数据标准,提炼知识元核心要素,即形式要素、物理要素和保存要素(表1)。

Table 1. Core elements of the knowledge meta-core for urban construction archives
表1. 城建档案知识元核心要素
2、复用成熟的元数据标准
复用元数据需要充分考虑城建档案资源特征,选择恰当适用的元数据标准,在元数据描述时需考虑其档案及城市建设属性。从通用资源元数据标准、档案资源元数据标准及空间数据元数据标准三个维度探讨描述规范,选取适用于城建档案描述的元数据标准,即DC、EAD和相关政策依据。
参考选用的2个元数据标准,复用DC标准4个元素(题名(项目名称)、其他贡献者(建设单位)、类别(建设类型)、描述),复用EAD标准2个元素(编号、来源)。针对城市建设目前尚未有合适的元数据标准能够充分描述。研究依据相关政策依据形成5个元素(建设强度、建筑密度、公服服务人口、地下空间开发强度、绿化服务人口),具体信息见表2。
Table 2. A Metadata description framework for urban archives knowledge metadata
表2. 城建档案知识元元数据描述框架
3.2. 知识元抽取
研究采用深度学习、主题建模等技术从档案内容中抽取出各类型知识元实体和知识项,实现知识组织从物理层次向认知层次的知识单元转换 [2] 。知识元抽取是知识提炼挖掘的关键步骤,能为档案的语义化检索和深层次组织提供参考,并为知识元关联关系构建奠定基石。图2展示了城建档案知识元抽取逻辑框架。
由图2可以看出,知识元抽取分为2个部分,即知识元实体抽取和知识项抽取。知识元实体又被称作“标识术语”,即表达某一实体概念的语词,如项目名称知识元实体“正兴街道中铁天圆大厦建设项目”。知识项是指描述实体(标识术语)的属性值,如“正兴街道中铁天圆大厦建设项目”字或号等属性。
知识元实体抽取是围绕6个知识元展开的,抽取方法主要是基于深度学习框架和规则模板。本文主要采用深度学习算法Bi-LSTM + CRF、CRF和BERT三个模型进行命名实体识别,采用规则模板方式抽取事件信息,主题建模方式抽取档案中城市建设主题知识元,人工检索方式抽取文献知识元。
城建档案知识项抽取分为2个部分,即对象属性抽取和数值属性抽取。对象属性抽取即是对知识元实体之间的关系进行识别,本文主要采用深度学习算法训练标注好的知识元实体关系数据,从而抽取知识元实体之间的关系;数值属性抽取是指通过全面衡量知识元属性特征,以人工审阅方式抽取属性值。
3.3. 知识元关联
知识元关联是指知识单元之间存在的各种关系的总和 [4] ,是由知识因子和知识因子之间的相关关联所构成的语义网络 [5] 。知识元关联是构成档案知识网络的核心要素和条件,强调知识元概念及其语义关系,以此揭示知识元内部和外部结构特征,从而寻求档案内容中隐含知识中的潜在模式和规律,挖掘构建不同类型的关联关系,实现档案中城市建设资源的深层次语义化组织。
温有奎等提出知识元语义链接模型(图3)来表示知识内容的逻辑关系,从知识元和信息导航两个方面构建知识元链接模型(表2),通过信息导航的逻辑链接性促进知识结构演变和进化 [1] 。

Figure 3. Knowledge meta-relational dimension
图3. 知识元关系维度
Table 3. Meta-categorization of knowledge on urban construction archives
表3. 城建档案知识元分类
本文依据4元组Km=
知识元语义描述模型,参考政策依据,以科学城天府科创园及配套项目7号地块工程(6#地块)项目中知识元“空间知识元”为例进行描述,如
表4所示。
Table 4. Samples of spatial knowledge meta-processing
表4. 空间知识元处理结果样例
参考政策依据,以科学城天府科创园及配套项目7号地块工程(6#地块)项目中知识元“建设单位知识元”为例进行描述,如表5所示。
Table 5. Samples of construction unit knowledge meta-processing
表5. 建设单位知识元处理样例
3.4. 知识元语义网络
城建档案知识元语义网络是在城建档案知识元4元组语义描述模型基础上进行构建的,将知识元概念引入到语义网络结构中,从细粒度视角对8种知识元实体进行抽象概括,梳理知识元标识术语和知识项两方面的内容,从而建构城建档案知识元语义网络。例如以项目知识元《科学城天府科创园及配套项目7号地块工程(6#地块)》项目中“建设管控”为例,构建基于建设管控知识元的知识元语义网络,如图4所示。
项目知识元“科学城天府科创园及配套项目7号地块工程(6#地块)”项目建设时间、建设地址、建设类型、建设单位、建设管控,关联关系分别是建设强度/容积率、建筑密度、公服密度、地下空间开发强度、绿地率,且四川科学城天府科创园及配套项目7号地块工程(6#地块)项目属于居住类建设。通过以“项目”
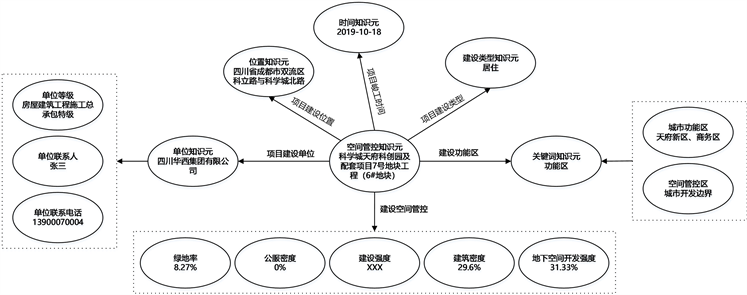
Figure 4. Samples of a knowledge meta-semantic network for building archive projects
图4. 建设档案项目知识元语义网络示例
为核心的网络关系构建直观再现了各个知识元之间的关系。在该网络中,知识元具有独立性、链接性和拓扑性特征 [1] 。独立性是指每个知识元可以独立成为一个整体,揭示概念的知识内涵;链接性是指不同知识元之间通过关系属性进行链接,以解构知识之间的关联性;拓扑性是指知识元语义网络具有扩展性,有益于实现知识的链式拓展。此外,该知识元语义网络区别于传统的知识网络,从更细粒度视角深入到知识内涵层面,从知识元维度对知识内容进行深层分析和探索,有益于提高对建设项目知识的整体认知,满足用户对知识的精细化检索需求。
4. 城建档案知识图谱成果
在知识元描述基础上,基于语料库,根据词法、句法特征及算法抽取城建档案中知识元实体(标识术语)及知识项。知识元实体(标识术语)是指城建档案中包含的:时间、类型、位置以及建设强度/容积率、建筑密度、公服密度、地下空间开发强度、绿地率等知识,前3项知识元实体识别任务相当于命名实体识别,后5项则根据特定的规则和建模方法来抽取知识元。
知识项是指描述实体(标识术语)的属性值,需要选取触发词作为抽取规则或人工梳理方式抽取知识项,构建城市建设档案语义数据库,将建设类型、建设时间、建设位置知识元实体(标识术语)归为命名实体识别任务,采用Bi-LSTM + CRF、CRF++、BERT模型抽取五大类标识术语;事件知识元抽取采用规则模板及人工梳理方式;主题知识元抽取采用LDA主题建模方法;实体知识元采取人工检索知识库方式获取;知识项抽取是通过综合技术经济指标表扫描件,以人工设置触发词等方式实现。
4.1. 数据预处理
城建档案目前主要有两种存储形式:
1) 以传统纸质文档存储,并扫描存储为PDF形式的电子文档。馆藏档案共有纸质档案240万余卷、20万余件,电子档案光盘3万余张,图书、资料及报刊4000余本(册)等。其中,规划和自然资源档案约66万余卷、13万余件,城市建设档案约174万余卷、7万余件(城市建设工程档案170万余卷,城市建设管理档案4万余卷、7余万件)。
对于纸质档案,采用加强OCR技术,提取档案中的关键信息“综合技术经济指标表”,如下图所示。通过数据增加和机器学习等方法,大大提高OCR识别精度,将“综合技术经济指标表”数据转换为文字和数据,并存储到数据库中。
在上述数据基础上,引入gensim库构建词典dictionary和语料库corpus,进行tf-idf计算,tfidf=models.TfidfModel(corpus),构建tf-idf语料库,即corpus_tfidf=tfidf[corpus]。
2) 以注录手段,建立关键数据的数据库文件。在档案整理环节,通过对档案进行准确全面的著录,能够更好地为档案检索、管理、开发以及利用服务。成都市城市建设和自然资源档案馆针对不同类别档案制定著录细则,明确著录规范和标准,形成丰富立体且有价值的著录体系。以城市建设工程档案为例,著录项包括工程名称、工程地址、用地面积、建筑面积、建筑结构、建设幢数、建筑高度、开工时间、竣工时间、总投资以及各类证号和相关参建单位等50个工程著录字段,形成档案数据库。
4.2. 知识元实体抽取
知识元实体(标识术语)是指城建档案中包含的:时间、类型、位置以及建设强度/容积率、建筑密度、公服密度、地下空间开发强度、绿地率等知识,前3项知识元实体识别任务相当于命名实体识别,后5项则根据特定的规则和建模方法来抽取知识元。
通过对语料库进行实体统计,运用正则表达式re.findall('[\u4e00-\u9fa5]+/标识符',txt)抽取建设强度/容积率、建筑密度、公服密度、地下空间开发强度、绿地率五大类实体,统计结果如图5。可以看出,建设强度/容积率两类,3个数据,出现频率90%;建筑密度一类,1个,出现频率85%;公服密度(卫生、学校、文体、公用)三类,20个,出现频率55%;地下空间开发强度一类,1个,出现频率85%;绿地率一类,1个,出现频率70%。
4.3. 城建档案知识图谱
研究对城建档案知识元语义关系进行挖掘。首先,界定城建档案知识元语义关系,主要从知识元外部结构和内部结构两个维度对知识元关系进行分类,将其划分为29种知识元实体之间的关系(对象属性)和24种知识元实体与其属性关系(数值属性),并构建知识元语义关联模型。其次,根据上述关联模型采用SPO三元组形式对知识元关联关系进行抽象化表示,并以RDF形式语言Turtle进行存储。最后,以本文所构建的城建档案语料库为数据源,采用CNN和Bi-LSTM模型抽取知识元实体之间的关系,并结合知识元属性值抽取结果,借助Neo4j图数据库对知识元关系进行可视化图谱展示,用Cypher语言进行查询,形成城建档案知识图谱(图6)。

Figure 6. Knowledge atlas of urban construction archives
图6. 城建档案知识图谱
4.3.1. 项目知识元展示
为了清晰地展示知识元实体之间的以及实体与属性之间的关系,我们基于Cypher语言进行简要查询。如我们需要查询“九里堤幼儿园”项目的相关信息,使用的Cypher语句是“MATCH (n{name:'九里堤幼儿园'}) RETURN*”(图7)。
从图谱中可以清晰的了解到幼儿园的建设单位、容积率、地址等档案中保存有的相关信息。
4.3.2. 时间知识元
空间知识元包括项目发证时间以及档案入库时间两个属性,通过构建的图谱,可以很方便的对时间相关的信息进行查询与展示。对“发证时间”进行查询,使用“MATCH (n:`竣工时间`{name:'2018-10-16'}) RETURN*”可以获取到发证时间为2018年10月16日的相关项目,并对项目展开,方便查看项目详细信息(图8)。
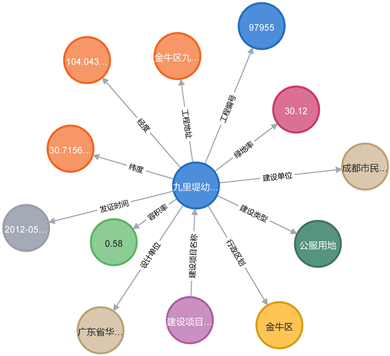
Figure 7. Relationship mapping of Jiulidi kindergarten
图7. “九里堤幼儿园”关系图谱
4.3.3. 空间知识元
空间知识元属性包括地址、经度、纬度、城市功能区、空间管控区四个属性,我们可是使用每一个属性进行关联检索,比如使用“MATCH (n:工程地址) WHERE n.name CONTAINS”武科西四路“RETURN n LIMIT 25”可以查询到工程地址在金马街道的所有项目信息,结果如图9所示。
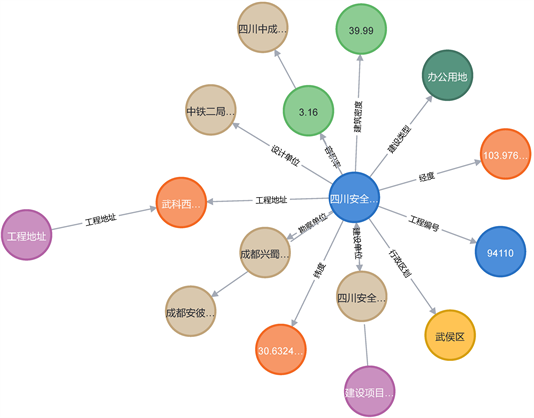
Figure 9. “Construction project address” search
图9. “工程地址”查询示意图
也可以利用行政区划属性对同一行政区划的项目信息进行检索,如使用“MATCH (n:`行政区划`{name:'双流'}) RETURN*”可以检索到双流区的相关项目信息,结果如图10所示。
4.3.4. 建设类型知识元
建设类型知识元属性包括居住、工业、商业。可以查询其中每一类建设类型所关联的项目情况。比如使用“MATCH (n:建设类型) WHERE n.name CONTAINS”工业“RETURN *”可以查询到建设类型为工业的有关信息,结果如图11所示。
4.3.5. 建设单位知识元
通过建设单位知识元,我们可以查询到某建设单位承担的所有项目、以及项目的具体情况。比如使用“MATCH (n:建设单位) WHERE n.name CONTAINS”成都华润置地驿都房地产有限公司“RETURN *”可以查询到建设单位为成都华润置地驿都房地产有限公司的相关建设项目,结果如图12所示。从图中可以直观的看出该单位承建的居住项目容积率多为2.0、绿地率为30%。
4.3.6. 建设管控知识元
建设管控知识元属性包括容积率、建设密度、地下空间开发强度以及绿地率等信息。可以从不同的纬度出发对图谱信息进行查看,例如使用“MATCH (n:`容积率`{name:2.2})RETURN*”可以查询到容积率为2.2的有关项目。具体如图13所示。
5. 结论与建议
在知识、知识元、知识图谱视域下探讨城建档案的语义化知识组织相关问题,将知识元理论引入到组织过程中,从知识细粒度视角着手解构城建档案内部知识结构,延展了相关理论的适用范畴。
1) 构建了城建档案语义化知识组织逻辑体系框架。从实践和概念层面探讨了城建档案语义化知识组织的必要性、目标及原则,在此基础上构建城建档案知识元描述、抽取、关联及应用的知识组织核心框架,并对2010~2020年的城建档案进行应用探索,使得该框架更具有实践性、通用性和合理性。
2) 实现了更细粒度的城建档案语义化知识组织。引入知识元理论,从知识细粒度视角着手,探讨城建档案知识内核,深入到城建档案中的项目、单位、时间、地点、空间管控等知识元,并解构知识元之间的语义关联性,组织粒度更加细化。
3) 扩展了城建档案结构化语义描述功能。根据城建档案特征及内容描述的需要,从形式维度和内容维度对城建档案进行语义描述。在内容维度上,将知识元和本体概念融合,提出4元组方式描述城建档案内容信息,并构建城建档案知识元语义互联网络,以此建立城建档案知识元语义描述的统一规范。