1. 引言
对于开发团队来说,提供安全可靠的软件是一个基本的要求。然而,软件中潜在的缺陷对软件的质量构成了严重的威胁,在软件开发的各个阶段中,由于人为因素、沟通问题、技术挑战等不可避免地引入各种缺陷。为此需要在软件发布前进行测试,找出软件中存在的问题并修复。在实际的开发过程中,对软件进行完备的测试需要投入大量的人力,而项目留给测试的资源往往是有限的,因此需要对那些最可能存在缺陷的模块进行测试。
软件缺陷预测(Software Defect Prediction, SDP)利用历史数据训练机器学习、数据挖掘或统计模型,并建立预测模型来预测未来引入的实例(如文件、模块或类)是有缺陷还是无缺陷 [1] 。准确的预测结果可以指导软件测试人员更有效地分配测试资源。软件缺陷预测的流程如图1所示,研究人员收集与软件开发相关的数据,包括代码库、版本控制历史、缺陷报告、代码度量等,从收集的数据中提取有助于预测缺陷的特征。接着将数据集划分为训练集和测试集,选择合适的机器学习、数据挖掘或统计模型作为学习器训练预测模型并使用测试集评估模型的性能。
大多数软件在实际运行中都是正常的,因此采集到的软件缺陷数据集中缺陷类别的样本数量远远少于非缺陷类别 [2] ,导致模型在预测时对数量较多的类别(非缺陷类)更敏感,而对数量较少的类别(缺陷类)效果较差。而实际情况与数据集的分布相反,对缺陷类的预测精确度要求比非缺陷类更高。软件缺陷预测的预测结果有错误与正确两种,预测错误会对项目进展产生不利影响。其中错误的预测又分为两种,分别是将有缺陷的模块预测为无缺陷的模块和将无缺陷的模块预测为有缺陷的模块,第一类错误会将有缺陷的模块留在软件中,对软件的质量产生重大的不利影响,而第二类错误会增加测试的模块数量,增加测试成本。与第一类错误相比,第二类错误的代价成本明显更低,因此需要着重增加预测模型对缺陷类的预测效果。最近的相关研究表明,将代价敏感引入缺陷预测模型中可以有效的解决类不平衡引起的少数类预测效果不佳的问题 [3] 。
软件缺陷数据集的采集往往有不同的来源,如缺陷跟踪系统、版本控制系统、代码审查工具等,每个来源都可能提供不同或相同类型的信息,导致高维度和冗余特征的问题。高维度和冗余特征会使得数据分析和模型训练变得困难,模型容易变得过于复杂,过度拟合训练数据,从而在未见数据上的泛化能力下降 [4] 。常见的解决方法是进行特征选择或者使用降维技术(如主成分分析、因子分析等),将高维度数据映射到低维度空间,保留主要信息的同时降低维度。
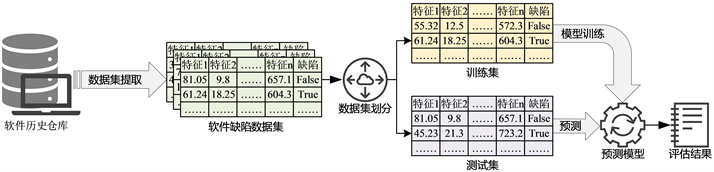
Figure 1. Software defect prediction process
图1. 软件缺陷预测流程
当前研究人员用于软件缺陷预测的方法主要包括深度学习(Deep Learning, DL)、随机森林(Random Forest, RF)、支持向量机(Support Vector Machines, SVM)、逻辑回归(Logistic Regression, LR)、朴素贝叶斯(Naive Bayes, NB)、集成方法(Ensemble Methods, EL)等 [5] 。然而这些方法在面对上述提到的类不平衡、误分类代价不同、高维度和冗余特征等问题时不能得到良好的分类结果。
李等人 [6] 提出了CSBst (Cost Sensitive Boosting)算法,该方法使用决策树桩(decision stump)作为集成模型的基分类器,在模型训练过程中增加产生第一类错误样本的权重,并在分类器最终集成的时候采用阈值移动的方法提高缺陷类的预测精度。其在集成阶段将阈值偏向于缺陷类的做法虽然会提高缺陷类的召回率,但由于非缺陷类占多数的数据分布,会使得整体的准确率大大降低。李勇等人 [7] 提出C-AdaBoost模型的集成算法,使用逐步回归前向算法选择最优特征子集,并在模型训练过程中使用C函数寻找每个基分类器的最优学习率,该模型优化了集成函数并在一定程度上降低了特征的维度,从而实现了更好的分类效果。Guo等人 [8] 提出了RSMOTE算法,用于从高维采样空间生成少数类样本,以处理软件缺陷预测中的不平衡分布问题,通过合成少数类的方法可以从数据上解决不平衡问题,但合成的样本无法捕捉到原始数据集中的所有细微特征和分布,且与真实世界的数据可能不匹配。因此可能产生过拟合和降低预测精度的问题。Lu等人 [9] 提出AEUB (Adaptive Ensemble Undersampling-Boost)算法用于处理不平衡学习问题,将欠采样集成(Ensemble of Undersampling, US)技术、Real Adaboost、代价敏感的权重修改和自适应边界决策策略相结合,构建了一个混合算法。该方法将多种优化方法应用于预测模型上,可以有效的提升模型的预测性能,但同时也提高了模型的复杂度。饶珍丹等人 [10] 提出了一种多层次过采样集成的不平衡数据缺陷预测模型(AJCC-Ram + XGBoost, XG-AJC),用于处理软件缺陷预测中不平衡数据的分类问题。该模型采用了多层次的过采样集成策略,针对类边缘和类中心分别采用不同的过采样算法来生成新的样本,并对生成的样本进行了噪声过滤处理。与传统的采样算法相比,这种方法在预测性能上表现更出色。
针对上述问题,本文提出了一种集成特征选择的代价敏感Boosting软件缺陷预测方法(Cost-Sensitive Boosting for Feature Selection, CSBFS),在特征选择与集成学习两个阶段同时使用代价敏感方法,解决不平衡数据集中少数类预测性能差的问题。提出一种新的特征选择方法,根据样本特征的边际贡献与代价函数得到特征的贡献值,并选择其中产生正面贡献的特征作为最终的特征集合。将特征选择融入到集成学习的过程之中,在每个基分类器训练前为其选择最合适的特征,以提高其预测性能,避免产生过拟合的同时提高各基分类器的多样性,以提升加权集合阶段的性能。
2. 相关工作
2.1. 代价敏感方法
代价敏感方法是一种在机器学习中用于处理不同类别分类错误代价不同的技术 [11] 。在许多实际应用中,不同类别的错误可能会导致不同的后果,因此传统的分类算法可能无法很好地满足实际需求。代价敏感方法通过考虑不同类别的代价,帮助机器学习模型更好地适应这种情况。在一些算法中,如逻辑回归(LR)和支持向量机(SVM),可以通过调整样本的权重来引入代价敏感性。错误分类的样本被赋予更高的权重,从而在模型训练中更加关注这些错误。如图2所示,LR和SVM应用代价敏感方法后在多个数据集上召回率均有显著的提升。

Figure 2. Comparison before and after using cost-sensitive methods
图2. 使用代价敏感方法前后对比
代价矩阵是代价敏感分方法的核心 [12] ,在二分类问题中它是一个二维矩阵,其中的元素表示在不同真实类别和预测类别之间的分类代价。如表1所示,行表示预测类,列表示实际类。为表方便用“−”表示负类别,“+”表示正类别,
表示真反例(True Negatives, TN)的代价,
表示真正例(True Positive, TP)的代价,
表示假正例(False Positives, FP)的错分代价,
表示假反例(False Negatives, FN)的错分代价。代价矩阵反映了在错误分类时可能产生的不同后果。
2.2. 特征选择方法
特征选择是指从原始特征集中选择一部分最具有代表性和信息量的特征,用于模型训练 [13] 。特征选择的目的是在减少特征维度的同时,保留对问题最有帮助的信息,以提高模型性能、降低过拟合风险、加快训练速度。软件缺陷预测中常用的特征选择方法主要有两类:过滤式(Filter)和包裹式(Wrapper)。如图3所示,过滤式特征选择是在模型训练之前对特征进行筛选,它通常将特征之间的统计量或相关性作为评价准则来评估特征的重要性。过滤式方法通常不涉及模型的训练,因此计算效率较高 [14] 。包裹式特征选择则是在特征选择过程中使用机器学习模型,通过不断训练模型来评估不同特征的重要性。包裹式方法的优点是可以考虑特征与目标之间的影响,更能准确地评估特征的重要性 [15] 。而由于需要多次训练模型,它的计算成本通常比过滤式高。
2.3. Boosting集成学习
集成学习是一种机器学习方法,它将众多的弱学习器通过一定方法组合成一个强学习器,从而提高模型预测的准确性 [16] 。Boosting方法是集成学习中的一种,通过迭代地训练模型,并增加错分样本权重,从而使模型更关注于错误分类的样本,进而提高整体性能。如图4所示,首先初始化每个样本的权重都为
,其中
是样本总数。接着使用当前的样本权重和样本训练弱学习器,计算学习器的错误率,并增加分类错误的样本在下一轮迭代中的权重。重复上一步直至迭代训练完所有的学习器,将各个弱学习器按其权重进行加权组合,形成一个强学习器。
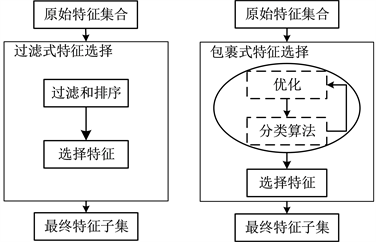
Figure 3. Workflow for filter and wrapper feature selection
图3. 过滤式和包裹式特征选择的工作流程

Figure 4. Boosting algorithm process
图4. Boosting算法流程
3. CSBFS方法
集成特征选择的代价敏感Boosting软件缺陷预测方法主要由两部分构成:代价敏感的特征选择算法和代价敏感的Boosting算法。由于软件工程实践中对不同错分的代价不同,因此需要在特征选择与集成两个阶段分别使用代价敏感方法,最后将两个算法组合成为CSBFS方法。
3.1. 代价敏感的特征选择算法
为了有效地识别软件缺陷数据集中的冗余和不相关特征,并且保留与缺陷类别相关度高的特征,本文提出了一种代价敏感的特征选择算法。该方法基于合作博弈论,通过计算各样本特征的Shaplely值 [17] 确定特征的边际贡献。并在此基础上加入代价敏感思想,对产生第一类、第二类错误的样本特征根据代价矩阵降低相应的贡献值。最后将各特征的贡献值相加取平均作为平均贡献值,并选择其中对预测结果起正向作用的特征作为最终的特征子集。
1) 计算特征贡献值
使用Shaplely值来度量特征对预测结果的贡献度,对于每个特征,将其在不同特征顺序下的平均边际贡献相加,得到该特征的Shapley值:
(1)
其中
是第
个特征的Shapley值,S是除xi外的所有特征子集,x是计算贡献值的样本实例
,
n为特征总数。
是特征子集S的权重。
是在特征子集S上的模型预测,可以用如
下公式计算:
(2)
其中
是x的预测,
是预测平均值,
是对不属于特征子集S中的特征进行多次积分。
由(1)式求得的Shapley值
是一个任意实数,可以是正数、负数或零。正数表示该特征对于模型预测有正向贡献,负数表示负向贡献,而零表示该特征对预测没有影响。由于所求的Shapley值没有大小限制,过大或过小都会影响分类性能,因此通过式(3)将其值映射到
之间,得到归一化的Shapley值
,同时便于接下来的代价敏感实现。
(3)
2) 引入代价敏感方法
从表1中可知
表示第一类分类错误的代价,
表示第二类分类错误的代价,通常将第二类错误代价设为1,而第一类错误的代价大于1,具体的值视实际情况而定。代价敏感方法的计算可以如下公式实现:
(4)
(5)
其中
代表实际值,
代表模型预测值,
代表样本x的代价调整函数。对于分类正确的样本,
,其特征的
值保持不变。对于第一类错分样本,
,e的指数项小于零,其值由代价矩阵控制,减少相应特征的
值。对于第二类错分样本,
,e的指数项同样小于零,但由于第二类错分的代价小于第一类,因此对应特征的
值减少量少于第一类。综合考虑上述的三种情况,最终得到代价敏感的归一化Shapley值
。
3) 进行特征选择
在选择特征之前,需要考虑特征在所有样本中的贡献情况,特征的平均贡献计算方法如下,其中m为样本的总数量,所得的
为第i个特征在当前数据集下对模型的贡献程度。
(6)
特征选择的目的是选择对预测贡献最大的特征,因此根据(6)式求得的特征贡献度选择最终的特征。特征选择的方法如下,选择对预测模型产生正向贡献的特征加入到最终特征子集
中,最终的
即为所求特征集合。
(7)
3.2. 代价敏感的Boosting算法
为了使预测模型更关注于第一类分类错误问题,将代价敏感方法引入Boosting算法中。通过调整算法训练中数据的分布权重,使得下一个学习器更关注被我们提高权重的样本。对于第一个学习器,初始
化每个样本的权重都相同,即
。计算学习器的错误率
,并根据错误率计算学习器的权重
。
前面的方法与Adaboost [18] 方法相同,不同之处在接下来的数据权重更新阶段,根据代价矩阵更新样本权重,权重更新方法入下所示。
(8)
为更新完的数据权重,通过指数内部的
代价敏感地调整数据权重,指数中的
参数从式(4)取得,由代价矩阵将样本数据划分为三个重要等级,按重要程度分别是第一类错误样本、第二类错误样本和分类正确样本,从而在下一轮的训练中按照这三个重要等级训练学习器。迭代训练完所有的学习器后按照式(9)将所有弱学习器集成为一个强分类器,集成时按照错误率加权弱学习器并对加权结果使用符号函数
得到最终的预测结果。
(9)
3.3. CSBFS方法实现
CSBFS由2.1中的特征选择算法和2.2中的集成算法共同组成,将代价敏感的特征选择算法融入到集成算法之中。通过在每个弱学习器前添加特征选择算法,选择最适合当前弱学习器的特征子集以提高其预测性能,CSBFS方法的流程如图5所示。由于各个弱学习器的关注点不同,其重要特征也各不相同,因此特征选择可以提高各弱学习器的多样性,最终提高集成模型的预测性能。CSBFS方法将代价敏感思想同时应用在特征选择与集成两个阶段,以减少第一类分类错误的产生,提高预测性能。
4. 实验研究
4.1. 数据集简介
本文使用Shepperd等人 [19] 对NASAMDP缺陷数据集清洗后的CleanNASA数据集、D’Ambros等人 [20] 收集的AEEEM数据集和Wu等人 [21] 收集的ReLink数据集共三个数据集进行试验。其中CleanNASA中包含CM1、JM1、KC1、KC3、MC1、MC2、MW1、PC1、PC2、PC3、PC4、PC5共12个数据集,缺陷类占比最低为2.31%,最高为27.57%,类不平衡现象较为突出。AEEEM中包含EQ、JDT、LC、ML、PDE共5个数据集,特征数量为21个,缺陷类占比最低为8.26%,最高为39.81%。ReLink中包含Apache、Safe、Zxing3个数据集,特征数量为26个,缺陷类占比最低为29.57%,最高为50.52%,类别分布比较平衡,数据集的详细信息如表2所示。
4.2. 实验设置
本文使用表2中3个来源的共20个数据集进行实验,采用5折交叉法,进行10次实验取平均值。选取RandomForest、DecisionTree、AdaBoost 、CAdaboost和CSBst方法作为对比实验,对各实验的结果进行统计。并选取不同的代价因子
进行实验,以探究代价矩阵对预测结果的影响以及代价因子取何值时预测效果最佳。
Continued
由于软件缺陷预测是一个二分类问题,因此可以用表3所示的混淆矩阵表示缺陷预测结果,其中TN (True negative)表示无缺陷且预测正确的样本数量,TP (True positive)表示有缺陷且预测正确的样本数量,FP (False positive)表示无缺陷但预测为有缺陷的样本数量,FN (False negative)表示有缺陷但预测为无缺陷的样本数量。根据混淆矩阵可以计算出其它评价指标如精确率(Precision)、召回率(Recall)、误报率(FPR)、F1分数(F-measure)、G均值(G-mean)。其中Precision表示模型预测为缺陷类的样本中有多少是真正有缺陷的,计算公式为:
Recall,也叫做TPR,表示模型预测正确的缺陷类样本占所有实际有缺陷样本的比例,计算公式为:
FPR表示无缺陷样本被错误地预测为有缺陷样本所占的比例,算公式为:
F-measure综合考虑了精确率和召回率,取值范围是0到1,得分越接近1,表示模型在精确率和召回率之间取得了良好的平衡,模型性能越好,计算公式为:
G-mean是一种综合评估指标,同时考虑对缺陷类和无缺陷类的预测能力,取值范围是0到1,G-mean值越接近1,表示模型在缺陷类和无缺陷类上的预测能力都很好。对于不平衡数据集,G-mean值越高表明模型有效地识别了两个类别,计算公式为:
AUC表示模型在不同阈值设置下TPR与FPR之间的面积。取值范围:0.5到1。当AUC等于0.5时,表示模型性能等同于随机猜测。AUC越接近1,表示模型对正类别和负类别的分类能力越好。
本实验使用Python语言,开发环境为PyCharm2023,使用的操作系统为Windows10,CPU为AMD Ryzen 5 5600 6-Core Processor 3.50 GHz,内存为16GB。
4.3. 结果分析
4.3.1. 实验效果对比
本文对20个数据集使用不同预测模型进行实验,分别记录下它们的F1、Recall、AUC、G-mean等评价指标。如表4所示,为6种预测模型在20个数据集上预测结果的F1值,实验结果表明,本文提出的CSBFS方法在绝大多数的数据集上的预测效果都比其他5个方法具有更高的F1值,只在2个数据集上小幅度地落后于具有最高F1值的分类算法,在4个数据集上的F1值与最高的预测算法持平。在PC2数据集上,由于该数据集的缺陷占比低至2.15%,所有预测算法的性能都比较低,随机森林算法的F1值更是低至0,这表明其对于缺陷类别的预测效果为零,而CSBFS算法相较于其他算法均有一定程度的领先。在KC3、MW1、PC1数据集中,CSBFS算法相对于其他算法的提高程度最高。

Table 4. F1 of 6 algorithms on 20 datasets
表4. 6种算法在20个数据集上的F1值
图6、7、8分别展示了6种算法在20数据集上的Recall、AUC和G-mean。从图6中可以看出CSBFS在绝大多数数据集上的Recall都优于其他5个算法,这表明CSBFS算法相比其他算法对少数类拥有更高的预测性能,对缺陷类样本更加敏感。图7展示的柱状图表明CSBFS算法在多数数据集上比其他算法的AUC指标更高,说明其在不同概率阈值下都能够有效地区分有缺陷和无缺陷的样本,CSBFS算法的整体预测性能比其他5个算法更高。从图8中可以看出CSBFS算法在20个数据集上都拥有较高的G-mean值,相较于其他5个算法,除了在Apache和Safe数据集上排在第二,在其他的数据集上都持平或一定程度的领先于其他5个算法。这表明CSBFS算法在缺陷类和无缺陷类之间的平衡较好,在类别不平衡问题中的性能较高。

Figure 6. Recall of 6 algorithms on 20 datasets
图6. 6种算法在20个数据集上的Recall
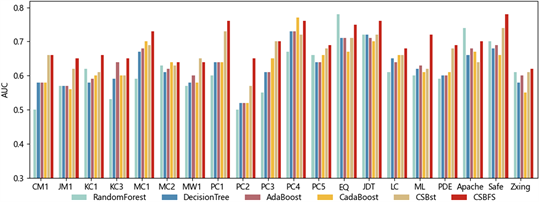
Figure 7. AUC of 6 algorithms on 20 datasets
图7. 6种算法在20个数据集上的AUC
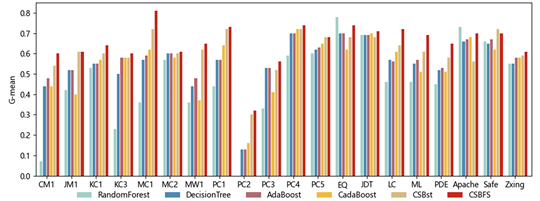
Figure 8. G-mean of 6 algorithms on 20 datasets
图8. 6种算法在20个数据集上的G-mean
由上述可知除了个别数据集,CSBFS算法在大多数数据集上的各项评价指标都领先于其他算法。经观察可知这些数据集分别是MC2、EQ、Apache、Safe、Zxing,这些数据集的缺陷占比分别是35.2%、39.81%、50.52%、39.29%、29.57%,都是比较平衡的数据。由此可知CSBFS算法在平衡数据上的预测效果与其他算法区别不大,而在不平衡数据上相比其他算法有着较大的领先,因此CSBFS算法更适合于不平衡数据的预测。
4.3.2. 缺陷占比的影响
为了探究CSBFS算法在不同缺陷占比下的预测性能,将数据集的缺陷占比及它们的评价指标绘制成图9所示的折线图,其中横坐标为缺陷占比,纵坐标为各指标的值。由图可知随着缺陷占比的不断提升,预测模型的性能也随之提升。在缺陷占比较低时预测模型性能提升速度较快,缺陷占比在20%之后性能提升变得比较平稳,由此可知CSBFS算法在预测缺陷占比高于20%的数据时都会有较好的预测结果。

Figure 9. Performance of CSBFS algorithm under different defect proportions
图9. 不同缺陷占比下CSBFS算法的性能
4.3.3. 代价因子的选择
代价敏感方法中代价因子的选择是一个关键点,合适的代价因子可以提高模型的预测性能,为了找出最合适的代价因子,我们使用平衡值 [22] (bal)评价指标作为判断是否取得最佳代价因子的依据。bal综合了FPR和TPR两个指标,同时考虑FPR和TPR的影响,是一个综合评价指标,bal的值越高表明模型预测效果越好,其计算公式为:
为了探究最佳代价因子的取值,我们取不同的代价因子进行实验,并统计它们的TPR、FPR及bal值。代价因子取值从1开始每次增加0.1直到4进行实验,每次实验进行10次取平均值记录结果,将所有结果标记在图中连线得到代价曲线。如图10为PC3数据集的代价曲线,由图像可知随着代价因子的取值不断增加,TPR和FPR的值也随着增加,而bal的值先是增加,到达最高值0.75后开始下降,bal最大时代价因子的取值为2.6,因此PC3数据集的最佳代价因子为2.6。从图中可以看出代价因子取值大于2.9之后TPR趋于平和而FPR仍然持续上涨,最终导致预测效果开始下降。
为了探究最佳代价因子的取值规律,对所有数据集按上文中的方法求得最佳代价因子,并将数据集按缺陷占比从小到大排列得到图11。图11展示的为最佳代价因子与缺陷占比的关系,从图中可知随着缺陷占比的增加,最佳代价因子的取值逐渐下降,最佳代价因子与缺陷占比呈负相关。缺陷占比越低即数据集越不平衡时,所取的最佳代价因子就越高,但代价因子的取值也不会一直上涨,从图中来看最高的代价因子在3.5左右。随着缺陷占比的提高,即数据集越来越平衡,最佳代价因子的取值也就越来越接近1。
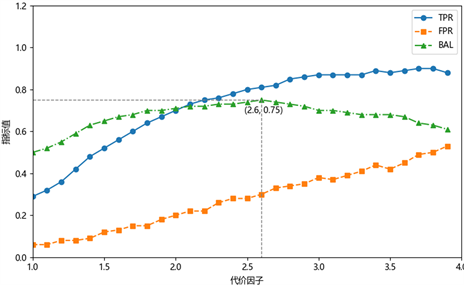
Figure 10. The impact of different cost factors on prediction results
图10. 不同代价因子对预测结果的影响
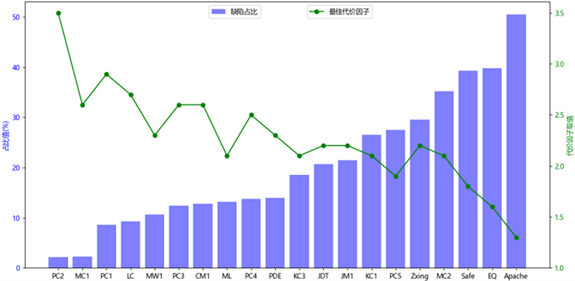
Figure 11. The relationship between the value data sets of the optimal cost factor
图11. 最佳代价因子的取值数据集的关系
5. 结束语
本文针对软件缺陷预测领域广泛存在的类不平衡及高维度问题,提出了一种集成特征选择的代价敏感Boosting软件缺陷预测方法。
首先,为解决高维度问题,提出一种代价敏感的特征选择方法,通过计算各样本特征的边际贡献值来选择特征。同时为了在选择特征子集时更多地保留与缺陷类样本相关的特征,在计算特征贡献度的过程中引入代价敏感思想,根据代价矩阵更改不同特征的贡献值,从而减少错误的产生。
其次,将代价敏感的特征选择方法嵌入进集成学习中,为每个基学习器添加特征选择方法,有效提高了基学习器的预测性能,避免了基学习器之间的同质化,增加了基学习器预测的多样性。同时在集成学习中引入代价敏感思想,在样本迭代时根据样本的错分情况及代价矩阵调节样本权重,可以让第一类错误样本在下一轮训练中得到更多的关注。
此外,由于软件缺陷数据集中不可不免地存在一些噪声数据,而Boosting算法在迭代过程中可能会将噪声数据作为分类错误的数据,从而过度关注噪声数据,影响最终的预测性能。因此在未来的研究中,我们会着重探究在Boosting方法中噪声可容忍的处理方法及剔除噪声数据的方法。
基金项目
黑龙江省高等教育教学改革项目(SJGY20210457);2023年哈尔滨师范大学研究生创新项目(HSDSSCX2023-6)。