1. 引言
人脸三维重建,作为计算机视觉领域的一个关键分支,致力于从单张或多张人脸图像中还原人脸的三维几何结构。单目人脸重建方法,相较于多目方法,具备更低的图像获取成本和更快的数字人物头部网格生成效率。
传统的人脸三维重建方法主要依赖几何学和计算机视觉技术,如多视角几何、结构光、稠密重建等。这些方法通过特征提取和模型匹配等步骤,以图像本身表达的信息,如视差和相对高度,完成三维模型的还原。林琴等人 [1] 结合局部立体匹配算法,对初步估计的脸部稠密视差值进行平滑处理,重建人脸的点云信息,在人脸数据库Bosphorus上获得了更加精确的重建结果。Castelan等人 [2] 引入SFS (Shape From Shading)方法,利用成像表面亮度的变化,解析出人脸表面的矢量信息,从而重建出人脸深度信息。叶于平等 [3] 提出了基于3D优化的标定方法优化结构光系统标定参数来提高重建精度,通过基于GPU的非刚性配准算法和纹理融合等算法重建出高精度高保真度的人脸动画表情。Blanz等人 [4] 提出了基于变形模型的方法,该方法通过调整3DMM模型(3D Morphable Model)中描述不同形状和纹理的PCA系数拟合三维人脸模型,利用自适应对齐算法将目标图像进行对齐,使得生成模型更好的匹配目标图像;Cao等人 [5] 又在3DMM的基础上增加了人脸表情。
随着深度学习方法在单目人脸三维重建中的迅速发展,人脸重建质量得到了显著提升。一些研究探索了卷积神经网络(CNN)的应用,以解决在人脸重建领域的困难。Tuan Tran等人 [6] 提出3DMM CNN方法使用卷积神经网络ResNet101 [7] 对3DMM模型的形状系数和纹理系数直接进行了回归。Zhu等人 [8] 针对3DMM的输入只有一张图像的问题,将RGB图像和PNCC (Projected Normalized Corrdinate Code)特征合并输入,通过权重调整的方式优先拟合关键形状参数,提高了模型的精度。Feng等人 [9] 提出的PRNet模型利用UV位置图描述三维形状并在计算损失函数时对不同区域的顶点加权,以更精准的预测坐标,实现了以端到端的方式实现人脸三维重建。
经典的基于3DMM模型的研究 [10] 都会面临着数据采集和处理方面的严重困难,而且难以精确捕捉人脸形状和纹理的复杂变化。为了解决这一问题,近年来提出了FLAME头部模型 [11] ,它通过整合多源异构数据集构建了更为精确的模型,可同时描述形状和纹理。Detailed Expression Capture and Animation (DECA)模型 [12] 则进一步引入深度学习技术,以生成UV图和细节、形状和表情等参数,从而更为鲁棒地重建人脸的形状和表情。
DECA作为单目人脸重建领域的深度学习模型,在提高人脸几何结构和还原面部纹理上发挥着重要作用。尽管它成功结合了的FLAME模型,但在实验中,DECA模型在重建精度方面表现不佳,且容易受到过拟合问题的影响。本文引入了Vision Transformer (ViT)作为特征提取器 [13] ,并采用DropKey技术 [14] 改善训练问题。ViT是一种强大的深度学习架构,因其卓越的特征提取能力而有望提高人脸几何结构的精度和纹理的还原质量,从而提供更精准的面部信息。同时,DropKey技术的引入有助于减轻过拟合问题的影响,增强DECA模型的泛化性能,提高模型在不同数据集和场景中的表现。
2. 改进DECA模型
2.1. 整体框架
DECA模型是基于FLAME模型的进一步发展,它使用深度学习技术从一个低维的潜在表征中生成UV位置图,并通过训练回归器来预测细节、形状和表情等参数。改进的DECA模型以二维人脸图像为输入,经过Encoder层进行特征编码,在Encoder层中采用了ViT模型和DropKey相结合的方法来提取图像的特征。随后,这些特征通过一个全连接层被映射为一个低维的潜在编码,包括相机编码(camera code)、反射率编码(albedo code)、光照编码(light code)、形状编码(shape code)、姿势编码(pose code)和表情编码(expression code)。这个潜在编码进一步被用于解码,其中反射率编码通过生成网络DA输出反射率贴图,用于体现模型的纹理和颜色;FLAME模型通过形状编码,姿势编码和表情编码对3D模型进行形变调整;最后利用可微渲染器(Differentiable Renderer)渲染最终的二维人脸图像以及通过最小化输入图像和输出图像之间的差异来进行模型的优化。整体框架如图1所示。

Figure 1. Improve the overall DECA frame diagram
图1. 改进DECA整体框架图
2.2. Vision Transformer
ViT作为深度学习模型架构,旨在将自然语言处理领域的Transformer模型中的注意力机制引入到计算机视觉任务中,在图像分类,目标检测和图像特征提取等多项视觉任务上获得了与CNN相媲美甚至更出色的表现。
与传统的CNN不同,ViT无需手动设计卷积核或池化层来提取特征,它将输入图像分割成小图像块(patch),然后通过Embedding层将这些图像块转换为token序列并将这些token作为模型的输入。在token输入Transformer Encoder之前额外加入[class]token和位置编码,位置编码使得模型可以理解输入图像块之间的相对位置关系,有助于模型对图像全局结构的理解。Transformer Encoder层从输入的token中提取关键特征,其中自注意力机制用于理解输入图像块之间的关系,多头注意力机制使得模型能够在不同空间位置上关注不同特征,有助于捕捉图像的全局和局部信息。最后,MLP Head层对从Transformer Encoder 层得到的特征进行进一步的处理和输出。MLP Head由一个或多个全连接层组成,其目的是将高维的特征向量转换成适合于不同具体任务的结果,例如生成用于图像分类的类别标签、用于目标检测的边界框和类别信息,以及用于语义分割的像素级别掩模。ViT的网络结构如图2所示。
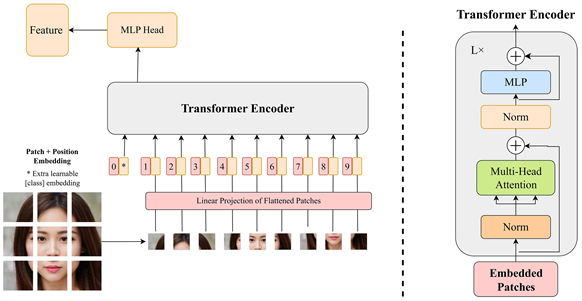
Figure 2. Vision Transformer network structure diagram
图2. Vision Transformer网络结构图
2.3. DropKey策略
当面临相对较小的数据集时,基于Transformer的算法容易受到过拟合问题的困扰,当前的ViT模型通常采用CNN中常见的Dropout正则化策略,即在注意力权重图上进行随机Drop并为不同深度的注意力层设置统一的Drop概率。然而,在Softmax归一化后进行随机Drop可能会破坏注意力权重的概率分布,且无法对权重峰值进行惩罚,导致ViT过拟合局部特定信息,如图3(b)所示。另一方面,不同深度的注意力层需要不同的Drop概率,恒定的Drop概率会导致训练不稳定,使得模型高维语义信息缺失或者低维细节特征过拟合。
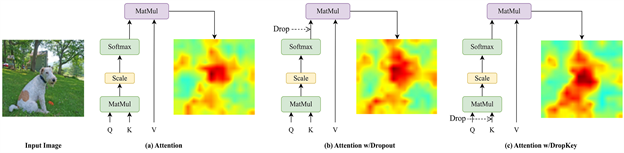
Figure 3. Attention-layer comparison map based on DropKey and Dropout
图3. 基于DropKey和Dropout的注意力层对比图
为了克服CNN采用的Dropout策略在ViT上缺乏有效性的问题,DropKey将Key设置为Drop对象,能够对注意力峰值进行惩罚,使得ViT模型可以更关注与目标有关的其他图像块,有助于捕捉全局特征,如图3(c)所示。与Dropout不同,DropKey为不断加深的注意力层设置递减的Drop概率策略,防止ViT模型过拟合并且有足够的高维特征进行稳定的训练,DropKey的具体操作如表1所示。

Table 1. Attention with DropKey code
表1. 使用DropKey的注意力机制代码
2.4. 损失函数
改进DECA模型的损失函数由多个损失组成,定义如下:
(1)
其中,
为人脸特征点重投影损失,
为眼睛闭合损失,
为光度损失,
为身份损失,
为形状一致性损失,
为正则化损失。
人脸特征点重投影损失用于度量人脸图像中2D人脸特征点真实值
与FLAME模型表面上对应的特征点
,经由估计的相机模型投影到图像中的误差,定义如下:
(2)
眼部闭合损失表示上眼睑和下眼睑对应的特征点
和
的相对偏移,并度量其与FLAME模型表面上的对应特征点
和
投影到二维图像中的偏移之间的误差,定义如下:
(3)
其中,E是上眼睑和下眼睑特征点对的集合。
光度一致性损失表示输入图像和输出的渲染图像之间的误差,定义如下:
(4)
其中,
为值为1的人脸遮罩,
为逐元素乘积。
身份损失函数表示将人脸编码成低维嵌入向量之间的误差,定义如下:
(5)
形状一致性损失表示给定同一个人物的两个不同的图像
和
,编码器Encoder应该输出相同的形状参数即
。利用这一特点,用
替换
,同时保持所有其他参数不变,这组新参数可以很好地重建图像
,定义如下:
(6)
表示对形状、光照和反照率的正则化损失,定义如下:
(7)
其中,
表示形状的正则化损失,
表示光照的正则化损失,
表示反照率的正则化损失。
2.5. 评价指标
实验采用NoW基准测试 [15] ,该基准测试为从单目人脸图片中进行三维重建的项目提供评估数据集,包括100个受试者的2054张人脸图像以及每个受试者的一个3D人脸扫描网格。评价指标为已重建3D网格进行刚性对齐(旋转,平移,缩放)到扫描3D网格中,计算预测和扫描网格中一系列相对应的特征点数值之间的误差Edis,定义如下:
(8)
其中,N为采样点个数,
为对应点计算误差的函数,
为扫描网格采样点的真实值,
重建网格采样点的预测值。
3. 实验和结果
3.1. 定量评估
实验训练所采用的数据集包括VGGFace2数据集 [16] 、BUPT-Balancedface数据集 [17] 和通过StyleGan2模型 [18] 生成的黄种人数据集,这些数据集需要经过二维人脸关键点检测算法 [19] 进行人脸68个特征点标注以及使用人脸分割模型 [20] 进行人脸遮罩的标注。设置四种算法模型(1) DECA/ResNet50;(2) DECA/ViT;(3) DECA/ViT + DropKey (ratio = 0.01);(4) DECA/ViT + DropKey (ratio = 0.05),分别计算NoW评估数据集的评价指标Edis的中位数,平均数和标准差误差,对比结果如表2所示。
Table 2. Comparison of the results of the four algorithms in the NoW dataset
表2. 四种算法在NoW数据集的结果对比
表2数据表明,模型(2)将特征提取器替换成ViT模型后,可以达到和使用卷积神经网络ResNet50的模型(1)重建三维人脸相对等的结果;然而,可以从图4看出,引入ViT模型后,训练会出现强烈的损失曲线震荡且容易过拟合。模型(3)中的DropKey策略(ratio = 0.01)可以激励模型更多关注与目标有关的其他图像块,有助于捕捉全局鲁棒特征,避免了模型过度拟合低维特征。模型(4)将Drop概率设置为0.05,提高了模型对高注意力值部分的惩罚程度,保证了模型有充足的高维特征进行稳定的训练,提升了模型的性能。
3.2. 定性分析
图5中,(a)为StyleGan2数据集上的人脸图像和标签图片;(b)为(a)通过使用ViT模型和DropKey策略的DECA模型预测的人脸特征点和FLAME头部模型;(c)为使用Albedo贴图渲染后的三维人脸模型。可以看出,改进DECA模型对人脸特征点预测准确以及对人脸图片进行三维重建的效果较好。


 (a) 原始和标签图像(b) 模型重建效果(c) 渲染效果
(a) 原始和标签图像(b) 模型重建效果(c) 渲染效果
Figure 5. Face 3D reconstruction effect chart
图5. 人脸重建效果图
4. 结论
本文通过引入Vision Transformer模型和DropKey策略对DECA模型进行改进,并将改进后的模型用于单目人脸三维重建。改进后的DECA模型对于二维人脸图像重建三维人脸有着良好的效果:一方面,Vision Transformer模型中多头注意力使得模型能够在不同的位置关注不同特征,有利于捕捉图像的全局和局部信息;另一方面,DropKey的注意力峰值惩罚和随加深的注意力层递减Drop概率的策略,防止了ViT模型过拟合和有足够多的高维特征进行稳定训练。实验结果表明,改进后的DECA模型对人脸特征点预测准确,纹理逼近真实图像,模型重建精度得到提高。
基金项目
省部级社科类重点项目(项目名称:弘扬地质精神,传承优良学风;项目编号:XFCC2023ZZ028)。
参考文献
NOTES
*通讯作者。