1. 引言
随着股票价格指数的发展与演变,指数型衍生品创新日益成为了当今全球金融市场上的一大亮点。在金融危机中表现突出,被大多数投资者和机构所采用,如何用部分股票来追踪目标指数就成为是否采用指数法进行投资的关键所在。股票指数追踪研究的内容是通过权重的优化再配置来寻找部分股票构成的最优的追踪组合,所谓的最优就是使得该组合相对标的指数的追踪误差最小。其目的在于复制与该指数同样收益水平的一个投资组合,实现组合收益与指数涨跌基本一致.此研究具有高精度、低交易成本、且能保证追踪组合的高流动性,具有重要的意义。
目前已有不少学者对此进行了研究,Roll (1992) [1] 以经典的均值—方差模型为切入点采用追踪误差最小化为目标函数。Alexander和Baptista (2010) [2] 提出了追踪边缘的曲率。Gotoh和Takeda (2011) [3] 就范数约束和惩罚对投资组合选择问题进行研究,研究发现范数约束可被看作与收益向量有关的稳健约束。梁斌等(2011) [4] 提出非负LASSO模型用以追踪指数,实证结果表明非负LASSO模型表现较好。刘睿智和周勇(2015) [5] 将自适应LASSO变量选择方法运用于指数追踪模型中并得到较好追踪效果。苏治等(2016) [6] 基于规则化方法构建稀疏指数追踪模型具有较好的外推预测效果。胡梦婷(2017) [7] 提出了指数追踪的分位数回归模型,并得到结论在不同的选股法下K值的改变对模型的影响不同。马景义(2017) [8] 构建了可以调节追踪误精和超额收益的增强型指数追踪模型,并给出了广义最小角度回归算法。用以计算调节参数作用下模型解的折中路径。彭胜银(2019) [9] 指出非负分位数估计作为两步估计方法,不仅保证了追踪组合内的股票权重的非负性;同时,还可以自动剔除一些相关性较高的成分股,降低追踪误差,提高追踪组合的样本内外预测能力,减少交易成本,说明该方法在股指追踪上的有效性和可行性。
本文在解决股票指数追踪问题时,先采用不同的变量选择方法和指数追踪方法,从而进行对比选择最优模型进行指数追踪。本文将以上证50指数为研究对象,对传统的指数化投资方法进行实证研究。
2. 数据说明
数据选取:2021年8月1日到2022年7月1日的上证50指数的日线收盘价数据,共207组样本,我们将数据集进行划分:2/3训练集,则训练集数据有138个样本,1/3测试集,则测试集数据有69个样本。表1为上证50指数上证(000016.SH)的50只成分股。
首先我们先介绍一下追踪偏差(Tracking deviation,简写为
)的概念,是指追踪组合的日收盘价与上证50指数的日收盘价之间的偏差,一般都用以下公式计算:
(1)
本文判断追踪能力的方法具体描述如下:
残差平方和(Residual Sum of Squares):
平均残差平方和(Mean Residual Sum of Squares):
残差标准差(Residual Standard Deviation):
其中,
是指追踪组合的日收盘价,
上证50指数的日收盘价。
3. 逐步回归指数追踪模型
逐步回归是通过剔除变量中不太重要又和其他变量高度相关的变量,降低多重共线性程度。将变量逐个引入模型,每引入一个解释变量后都要进行F检验,并对已经选入的解释变量逐个进行t检验,当原来引入的解释变量由于后面解释变量的引入变得不再显著时,则将其删除,以确保每次引入新的变量之前回归方程中只包含显著性变量。这是一个反复的过程,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止,以保证最后所得到的解释变量集是最优的。
逐步回归法的好处是将统计上不显著的解释变量剔除,最后保留在模型中的解释变量之间多重共线性不明显,而且对被解释变量有较好的解释贡献。但逐步回归法可能因为删除了重要的相关变量而导致设定偏误。
逐步回归的方法有两种,一种是向前法,另一种是向后法,本文通过采用函数step(),选择AIC信息量为准则,默认向后法,从所有变量开始,逐步通过选择最小的AIC信息量达到增删变量的目的。首先通过逐步回归剔除7个变量
,余下43个变量,对于第
个变量,虽然不显著,但删除后AIC和平均残差平方和、残差标准差等有所增加,因此不删除。所选择的变量给出的参数估计,得到回归模型如下:
(2)
在
模型下对应的拟合残差图、预测残差图、上证50指数预测图、上证50指数跟踪图,如下图1所示。
从图1中的拟合残差图可知,该拟合残差在0上下波动,无明显趋势效应;从预测残差图显示,不是该残差白噪声序列;上证50指数预测图可以看出随着时间的增加,预测误差越大,预测值显著低于实际值,可以看出预测效果不好;上证50指数跟踪图可以看出跟踪效果不佳。综上所述,此时在
模型下的指数追踪效果并不好。
4. LASSO回归指数追踪模型
考虑线性模型
,误差向量
满足
,样本数据为
其中,
是自变量,
是因变量,假设这些观测值是相互独立的,或者在给定
的情况下,
是独立的,所有
是标准化了。
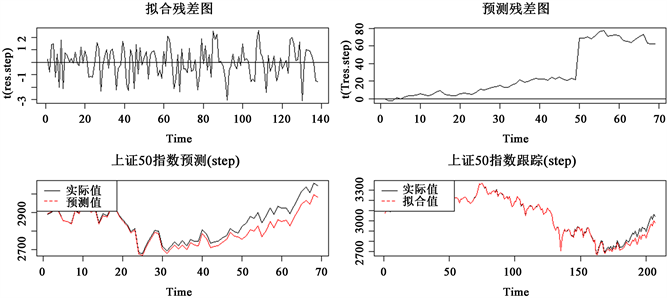
Figure 1.
model of fitting residual graph, forecast residual graph, SSE 50 index forecast graph, SSE 50 index tracking graph
图1.
模型的拟合残差图、预测残差图、上证50指数预测图、上证50指数跟踪图
设
,由
,岭估计其实就是使下式达到最小的参数估计
(3)
因此,岭估计可以看成是具有二次约束的回归参数估计,注意,当数据是标准化的时候有
,又
的解为
,所以式
中不含常数项,等同于使下面的式子最小化
(4)
绝对约束估计(LASSO: the least absolute shrinkage and selection operator)就是要找到使下式
(5)
达到最小的
,
是一个调整参数,它控制着对估计压缩的程度,设
是普通最小二乘估计,
,当
,将会引发趋向0的压缩,因而绝对约束估计也是压缩估计。
总所周知,传统的方法要丢弃如此众多的变量非常困难。而绝对约束估计(LASSO)具有的稀疏性。下面先用LARS的
值选择模型,在
准则下,选择最小的
值对应的变量集。结果显示,最小值
,对应的变量集包含49个变量,即通过变量选择,从原始50个变量选择了49个变量进行指数追踪。运用plot.lars可以直观的显示各组变量系数,得到回归模型如下:
(6)
从中
模型可以看出,剔除变量
,
变量系数被压缩为0,从而变量选择保留49个变量。在
模型下对应的拟合残差图、预测残差图、上证50指数预测图、上证50指数跟踪图如下图2所示。
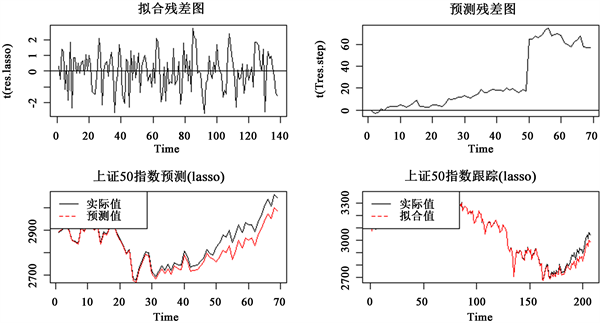
Figure 2.
model of fitting residual graph, forecast residual graph, SSE 50 index forecast graph, SSE 50 index tracking graph
图2.
模型的拟合残差图、预测残差图、上证50指数预测图、上证50指数跟踪图
从图2的拟合残差图可知,该拟合残差在0上下波动,无明显趋势效应;从预测残差图显示,不是该残差白噪声序列;上证50指数预测图可以看出随着时间的增加,预测误差越大,预测值显著低于实际值,可以看出预测效果不好;上证50指数跟踪图可以看出跟踪效果不佳,与基于逐步回归的指数追踪图十分相似,两者无太大别。
5. 弹性约束估计建立上证50指数与成分股的回归方程
虽然绝对约束估计在很多情况下都得到很大的认可,但有效性在某些条件下也会受到限制,主要在如下三个方面:
1) 在p > n的情况下,绝对约束估计最多只能选择出n个变量。
2) 在一组相关性较高的变量中,绝对约束估计只能在这些变量中选择其中的一个,而不考虑其他具有较高相关性的变量,选择也是随意的。
3) 就低维情形,p < n的情况下,如果预测值之间有较高的相关性,那么岭回归估计比绝对约束估计表现要好。
2005年Zou H和Hastie T提出合并考虑岭回归和LASSO的约束方式,提出了弹性约束估计,称之为Elasticnet,定义如下:
(7)
等价于找到使得下式
(8)
达到最小的
。
当
时弹性约束估计就是岭回归,当
弹性约束估计就是绝对约束估计,因此,弹性约束估计同时具有绝对约束估计和岭估计的特点。
用弹性约束估计建立上证50指数与成分股的回归方程。比较方便的是函数CV.glmnet可以自动进行CV交叉验证,从而确定出最佳的
值,
,
值的选择如图3所示。
图3中横轴是对数
值,纵轴是均方误差。红点代表均方误差和上下一倍标准差,均方误差越小模型越好;上方数量表明模型仍存在的自变量个数(不一定是单调递减)。第一条虚线处表明均方误差最小值;第二个虚线标出最低点的一倍标准差的位置,表示牺牲一倍标准差的情况下可以得到的最简单的模型。按此参数值,保留变量个数是28个,残差平方和为8105.894,对应的残差图如下图4所示。
作为基金公司,需要用最少的变量达到对指数的跟踪,从而实现股票与股指期货的对冲,达到保值目的,这时太多的股票,全部持有几乎不可能,有必要进一步进行变量选择。
而本例通过CV准则得到的最优解仅仅包含28只成分股,已经能够满足持股和利用股指期货实现风险对冲的目的。根据glmnet程序此时给出的系数估计,得到回归模型如下所示,对应的基于弹性约束估计所选择的上证50指数上证(000016.SH)的28只成分股回归模型如下所示,表2为其对应的28只成分股。
(9)
这些成分股在2021年下半年至2022上半年左右了上证50指数的走势,根据弹性约束建立的模型,完全可以模拟出上证50指数的实际走势,如图5所示。
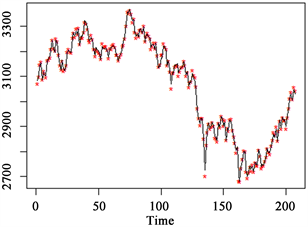
Figure 5. The tracking effect of the remaining 28 constituent stocks on the trend of SSE 50 index
图5. 剩余28只成分股对上证50指数走势的跟踪效果
图5中星号是实际上证50指数每日的收盘价,实线是模型曲线。易见,实际走势和28只成分股的跟踪走势基本重合,基本跟踪到了指数的运行趋势,与指数运行合拍,对于以上证50为标的股指期货空单有较好的对冲效果。此外,还本文还采用LASSO交叉验证法。
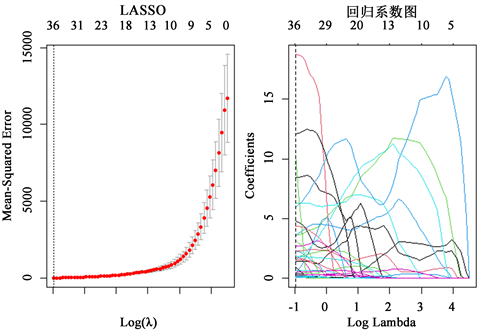
Figure 6.
selection plot and regression coefficient plot
图6.
选择图以及回归系数图
从图6中可知,当
时,保留36个变量。其中
变量系数被压缩为0,从而未被选入,相当于选择了36个变量。
(10)
在
模型下对应的拟合残差图、预测残差图、上证50指数预测图、上证50指数跟踪图7如下。
对图7进行分析:从拟合残差图可知,该拟合残差在0上下波动,无明显趋势效应;从预测残差图显示,不是该残差白噪声序列;上证50指数预测图可以看出随着时间的增加,预测误差越大,预测值显著低于实际值,可以看出预测效果不好。
6. 岭回归指数追踪模型
岭回归(ridge regression, Tikhonov regularization)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法。通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
岭迹是指将
从0增加到正无穷的过程得到的中每个分量的变化曲线。岭迹法选择
值的一般原则是:1) 各回归系数的岭估计基本稳定;2) 用最小二乘估计时符号不合理的回归系数,其岭估计的符号变得合理;3) 回归系数没有不合乎经济意义的绝对值;4) 残差平方和增大不多。
与LASSO相比,岭回归得到的模型一直都是50个变量,因此岭回归没有变量筛选的功能。运用LASSO进行变量选择,然后再通过最小二乘回归、岭回归、刘回归等对筛选出来的变量进行回归分析,从而对指数进行跟踪得到模型。
基于不同方法的指数追踪效果来看,似乎无法辨别某种方法下的上证50指数的追踪效果最佳,某种方法下的上证50指数的追踪效果最差,这个时候就需要用数据、用评价标准来判别基于不同方法下指数追踪效果的优劣了。在下表3中,我们展示了基于不同准则下(Cp准则,CV准则)的方法的追踪效果,以及在同一准则下不同方法的追踪效果。
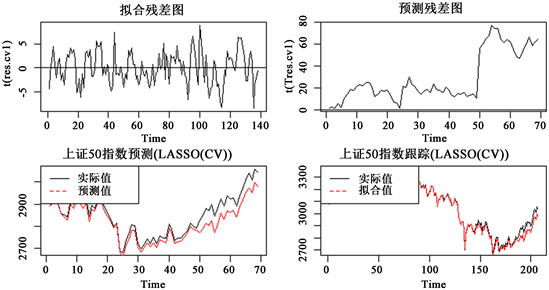
Figure 7.
model of fitting residual graph, forecast residual graph, SSE 50 index forecast graph, SSE 50 index tracking graph
图7.
模型的拟合残差图、预测残差图、上证50指数预测图、上证50指数跟踪图

Table 3. Cp comparison of index tracking effects of different methods under the criterion
表3. Cp准则下不同方法的指数追踪效果对比
从表3中可知:在Cp准则下,LASSO保留了49个变量(成分股),且在测试集上的残差平方和、平均残差平方和(RMS)和残差标准差(SD)三种指标都优于逐步回归和岭回归;在LASSO变量选择方法下,进一步运用刘估计进行回归,得到较好的外预测效果。为此,我们绘制出Lasso + LIU (olse)方法下的指数跟踪图,如图8所示。
LASSO + LIU (olse)的回归方程如下:
(11)

Figure 8. SSE 50 index tracking graph
图8. 上证50指数跟踪图
Table 4. CV comparison of index tracking effects of different methods under the criterion
表4. CV准则下不同方法的指数追踪效果对比
从表4可以看出:相比于
准则,CV准则下的LASSO只保留了36个变量,外预测效果明显都次于
准则;在CV准则下,LASSO测试集上的残差平方和、平均残差平方和(RMS)和残差标准差(SD)三种指标都优于逐步回归和岭回归;两步估计中,岭估计外预测效果也是较好的。为此,我们绘制出LASSO + 岭回归方法下的指数跟踪图,如图9所示。
LASSO + 岭回归的回归方程:
(12)
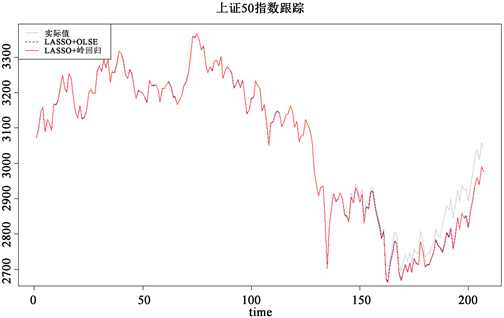
Figure 9. SSE 50 index tracking graph
图9. 上证50指数跟踪图
7. 分位数回归指数追踪模型
在线性回归模型中,需要假设X和Y服从二元正态分布为前提,但是如果X和Y不服从二元正态分布,那么我们用来描述
的分布就不仅仅只是条件期望和条件方差了。最方便的一个方法就是用分位数来描述
的分布。
首先我们先给出在给定X下的Y的条件分位数的表达式,当然,此时的X和Y是服从任意联合分布的。假设X和Y仍然是通过简单线性模型相关.而误差项
的分量
是独立同分布的。但是此时需引入一个特定的误差分布函数,记作
。现在考虑条件分位数的线性回归模型,同时,仍假设
的期望为0,但是它的分位数不为0。因此,当我们用分位数回归来代替线性回归模型时,误差项不会消失。
令
,并用
代表q分位点的误差。同时因变量的条件q分位点通过
得到
,那么条件q分位点的线性回归模型为:
(13)
而该公式就是一个分位数回归模型。
在分位数回归中还是通过一个散点图来画分位数回归线,分位数回归与普通线性回归的区别在于线性回归线穿过“平均或重心”的点,而分位数回归线则通过分位点。
由于作为基金公司,需要用最少的变量达到对指数的跟踪,从而实现股票与股指期货的对冲,达到保值目的,对比两个表格,发现基于方法(CV准则)选择LASSO (36个变量)与基于方法(Cp准则)选择LASSO (49个变量)的平均残差平方和(RMS)和残差标准差(SD)相差并不是很大,但是选择的变量个数相差了13个之多。为此,下面我将采用基于方法(CV准则)选择LASSO (36个变量)进行。
当分位数为
时获得经验回归方程如下:
(14)
当分位数为
时获得经验回归方程如下:
(15)
当分位数为
时获得经验回归方程如下:
(16)
当分位数为
时获得经验回归方程如下:
(17)
当分位数为
时获得经验回归方程如下:
(18)
并绘制了在不同分位数下的上证50指数跟踪图,如下图10所示。
通过上图10似乎无法判别基于哪个分位数的上证50指数跟踪效果更好,为此,我们通过计算在不同分位数下的指数跟踪的残差平方和、平均残差平方和、残差标准差来进行评价。
Table 5. Comparison of index tracking effect under different quantiles
表5. 不同分位数下的指数追踪效果对比
从表5中可看出,在CV准则下,LASSO测试集上的残差平方和、平均残差平方和(RMS)和残差标准差(SD)三种指标都优于逐步回归和岭回归;两步估计中,0.5分位数回归外预测效果也是最好的,0.05分位数回归的效果最差。此外,我们还将基于上述所有方法所得模型的评价标准总结于表6中。
Table 6. Summary table of index tracking effect comparison under different models
表6. 不同模型下的指数追踪效果对比汇总表
从表6中可以看出,1) 在Cp准则下,LASSO保留了49个变量(成分股),且在测试集上的残差平方和、平均残差平方和(RMS)和残差标准差(SD)三种指标都优于逐步回归和岭回归;在LASSO变量选择方法下,进一步运用刘估计进行回归,得到较好的外预测效果。2) 在CV准则,LASSO只保留了36个变量,外预测效果明显都次于Cp准则;在CV准则下,LASSO测试集上的残差平方和、平均残差平方和(RMS)和残差标准差(SD)三种指标都优于逐步回归和岭回归;两步估计中,岭估计外预测效果也是较好的。3) 在CV准则下,LASSO测试集上的残差平方和、平均残差平方和(RMS)和残差标准差(SD)三种指标都优于逐步回归和岭回归;两步估计中,0.5分位数回归外预测效果也是最好的,0.05分位数回归的效果最差。4) 在不同的选股法下值的改变对模型的影响不同。
8. 总结
随着国内外证券市场的成熟化,追踪标的国际化,投资者的指数化投资理念更加成熟,越来越多的指数型基金管理公司开始通过构建指数追踪组合对市场指数进行追踪。因此,本文通过Cp准则、CV准则选股法来选出构建追踪组合的样本股,并且分别构建了指数追踪的逐步回归模型、岭回归、两步回归模型和分位数回归模型等。通过研究指数追踪方法对国内外资本市场都具有十分重要的理论意义和实际意义,也为投资者提供更多的方法。
参考文献