1. 引言
近年来生产安全事故态势来看,我国房屋市政工程安全形势不容乐观,建筑行业安全生产监督管理工作需进一步加强 [1] 。每年因未正确佩戴安全帽而导致的安全事故数不胜数,给人们的生命财产安全带来了严重的损害。为此,工人在施工期间必须佩戴安全帽,检查工人是否按要求佩戴安全帽工作成为生产安全管理工作中的一项重要环节 [2] 。但传统人工监管随监控时长增加,监控范围扩大,容易产生视觉疲劳,继而导致误判,既耗费大量人力、物力资源,也无法满足目前安全管理要求 [3] 。因此,采用高效的目标检测方法进行自动化安全帽检测十分必要。
国内外广大学者对安全帽检测技术展开了广泛的研究。冯国臣等人 [4] 使用机器视觉方法进行安全自动识别研究;Le Vanbang [5] 等人通过HOG特征提取来检测人体,接着采用颜色直方图识别安全帽;胡恬 [6] 在研究小波变换和BP神经网络的基础上,进行了人脸识别的研究;刘晓慧等人 [7] 利用安全帽与人头发颜色的色差进而判断工人是否佩戴安全帽。然而,以上传统目标检测方法通过人工设计特征实现检测任务,效率较为低下,并且存在模型复杂、检测精度不高等问题。
随着卷积神经网络(Convolutional Neural Network, CNN)的发展,基于传统机器学习的目标检测算法正在慢慢被基于深度学习的卷积神经网络算法替代。Redmon J等提出的YOLO系列算法 [8] [9] [10] [11] 使深度卷积网络在目标识别精度和速度上都有了较大提升。在此基础上,徐印赟等 [12] 在传统YOLO算法的基础上通过设计特征融合模块,强化不同尺度间的信息融合从而降低误检率。李振华等 [13] 在YOLOv3中引入自注意力,并对聚类算法进行优化,提升了锚框质量。孙备等 [14] 在SSD算法上通过对浅层网络进行多尺度卷积融合,提高对小目标的检测性能。丁田等 [15] 在YOLOX网络基础上引入跨通道交互的注意力机制,并优化损失函数,提高安全帽检测精度的同时保持较好的检测速度。
但以上现有的安全帽检测方法仍然容易受到复杂多变的环境影响,导致检测准确率较低,此外模型参数量普遍较大。本文提出改进YOLOv7-Tiny的安全帽检测方法,针对复杂场景下小目标检测效果不佳、模型参数量大等问题,对特征融合网络进行改进,并引入了注意力机制,引导模型关注小目标信息,并对锚框重新聚类,使其适应安全帽检测任务尺寸。实验结果表明:改进的模型具有环境适应性好、检测准确率高、模型参数量小等特点,满足实际复杂场景下的安全帽检测任务。
2. YOLOv7-Tiny算法简介
YOLOv7 [16] 是Alexey Bochkovskiy团队于2022年提出的目标检测模型。作为当今YOLO系列中的基本模型,其检测速度和精度也十分优秀。为保证模型大小与检测精度之间的平衡,选择使用YOLOv7-Tiny作为基础网络进行改进。其网络架构如图1所示。
YOLOv7-Tiny网络主要由Backbone、Neck、Head三部分组成。Backbone部分主要由CBL、ELAN模块以及MP下采样模块构建而成。其中Backbone部分通过多个CBL模块对输入图像进行卷积下采样,再经过若干ELAN和MP下采样模块进行特征提取。Neck部分通过SPPCSPC模块对不同尺度的特征进行融合,同时该网络采用了YOLOv5中使用的PAN结构,加强特征提取网络中的特征融合。Head通过CBL卷积检测大、中、小目标。
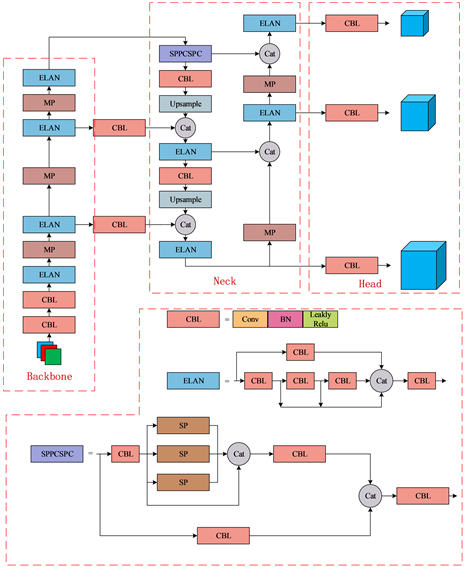
Figure 1. YOLOv7-Tiny network structure diagram
图1. YOLOv7-Tiny网络结构图
3. YOLOv7-Tiny算法的改进
3.1. 引入全局注意力机制
在安全帽检测任务中,安全帽和人头部在图像中像素占比较小,同时物体间普遍存在遮挡等问题。此外随着网络加深,细节信息丢失严重,网络中识别小目标等的能力较弱从而造成漏检、误检等问题。为改善网络对小目标的识别能力,在骨干网络的最后方和检测头前引入坐标注意力 [17] 模块,在几乎不带来计算开销的前提下,让网络更加关注空间上的坐标信息,从而更精准的识别被检测的目标,提升网络性能。
坐标注意力通过将横向和纵向的坐标信息通过编码融合进通道注意力中,使其能更加关注到物体的坐标信息,从而提升网络的检测性能。其具体操作主要分为两个步骤:坐标信息编码和坐标注意力生成,结构如图2所示。
首先,对全局位置信息进行编码。对任意给定输入X,使用尺寸为(H,1)和(1,W)的池化核来编码水平方向和垂直方向特征,其第c维特征在垂直方向高度为h时和水平方向宽度为w时的输出分别如公式(1)、(2)所示:
(1)
(2)
上述公式沿水平和垂直两方向集成特征,输出一对方向确定的特征图,使得网络能关注到某一方向上的长距离关系,从而建立坐标关系,使网络能重点关注空间位置信息。再对上述变换后的坐标信息进行注意力生成,将公式(1)、(2)的输出进行Concatenate操作,再对其使用卷积函数
进行变换,最后再经过非线性激活函数
得到包含水平方向和垂直方向的特征图输出记为f,其表达式如公式(3)所示:
(3)
随后将f分解为两个独立的特征
和
,再分别通过1 × 1卷积和Sigmoid激活函数进行特征转换,使输出维度与给定输入X一致,其输出表达式如公式(4)、(5)所示:
(4)
(5)
将两个独立方向的输出
和
合并为权重矩阵,最终CA注意力模块的输出可以写成如公式(6)所示:
(6)
3.2. 特征提取网络的改进
YOLOv7-Tiny原网络在输入图像尺寸在(640,640)的情况下,进行连续多次2倍下采样得到(80,80)、(40,40)、(20,20)三种尺度的特征图。然而,原网络在训练的过程中,随着不断进行卷积和下采样,抽象的语义信息不断增强,而对小目标而言,细节和纹理信息也在不断减弱。为缓解网络加深导致的细节纹理信息丢失,提升网络对小目标的检测性能,在特征提取网络中,增加针对小目标的特征提取层,其结构如图3所示。
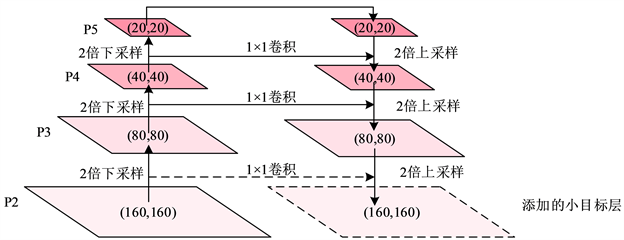
Figure 3. Adding the feature extraction network of the small target feature extraction layer
图3. 添加小目标特征提取层的特征提取网络图
图中虚线部分为增加的针对小目标的特征提取层,通过对浅层特征层中的特征进行特征融合,加强网络对小目标的识别能力。同时,为减少参数量,删除用于预测大目标的预测层和预测头,由于在安全帽检测任务中,检测对象基本为中小目标,大目标在其中占比较少,因此删减用于预测大目标的检测层和检测头对于安全帽检测性能影响较小。其改进的网络结构如下图4所示。
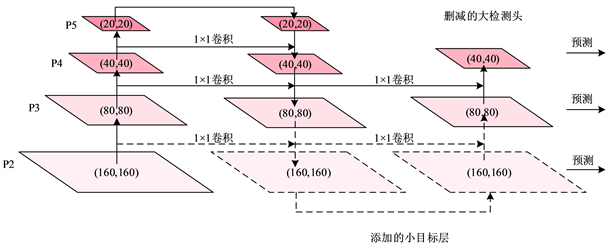
Figure 4. Feature extraction network of deleted large target prediction head
图4. 删减大目标预测头的特征提取网络图
3.3. 引入CARAFE上采样算子
YOLOv7-Tiny采用最邻近上采样方式进行上采样,该采样方式仅通过空间位置决定上采样核,并没有充分利用特征图中的抽象语义信息,且通常感知域都较小。针对最邻近上采样方式的不足,引入轻量的上采样算子 [18] Content-Aware Re Assembly of Features,简称CARAFE算子。
CARAFE主要由上采样核预测模块和特征重组模块组成,其网络结构简图如图5所示:

Figure 5. CARAFE up-sampled network structure diagram
图5. CARAFE上采样网络结构图
尺寸为H × W × C的输入特征图,若上采样倍数为σ,输出得到尺寸为σH × σW × C的输出特征图。其主要过程为:首先用一个1 × 1卷积将通道进行降维到Cm,接着对输入特征图内容进行编码,假设上采样核的尺寸为K × K,利用一个卷积层来预测上述采样核,输入通道数为Cm,输出通道数为σ²K²,然后再将通道维度展开到空间维度,得到形状为σH × σW × K²的上采样核。再将上述上采样核的各项权重利用Softmax进行归一化。最后,将上述输出特征图中的每个像素点的位置映射回输入特征图中,找出以该映射点为中心点的K × K区域,与该点上采样核的通道维度展开成K×K的空间区域作点积,最后得到尺寸为σH × σW × C的输出特征图。
在原网络中利用CARAFE算子替换传统的最邻近上采样算子,让网络在特征融合过程中拥有更大感受野,同时根据输入特征图自适应预测采样核,根据输入特征图进行高质量上采样,保证特征信息的完整性。
改进的YOLOv7-Tiny网络如下图6所示:
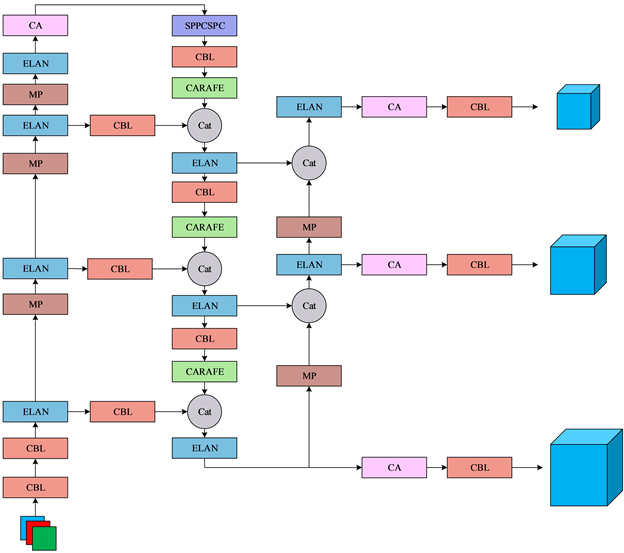
Figure 6. Structural diagram of the improved YOLOv7-Tiny network
图6. 改进的YOLOv7-Tiny网络结构图
3.4. K-Means++聚类锚框
YOLOv7-Tiny默认设置了针对COCO数据集的9个anchor框,按照大小顺序依次为[10,13],[16,30],[33,23],[30,61],[62,45],[59,119],[116,90],[156,198],[373,326]分别用来检测小、中、大目标。然而不同数据集的目标尺寸分布不一样,在安全帽检测任务中,针对COCO数据集预设的9个锚框并不符合安全帽检测场景。因此,需要针对SHWD数据集对锚框进行重新聚类分析。为了使网络更好的学习安全帽的大小尺寸信息,本文采用K-Means++算法对锚框进行重新聚类。最终得到9个针对安全帽尺寸的锚框[9,10],[11,13],[16,19],[26,28],[40,44],[60,67],[97,110],[174,198],[396,332],最后选定用这9个锚框替换预设锚框进行安全帽检测训练。
4. 实验及结果分析
4.1. 实验环境与参数
本文实验的操作系统为Windows10,GPU型号为NVIDIA GeForce RTX 3090 (24G显存),编程语言选择Python,采用Pytorch框架,CUDA版本为11.4,实验超参数的设置如表1所示。

Table 1. Experimental hyperparameter settings
表1. 实验超参数设置
4.2. 实验数据集
本文采用公开数据集SHWD (Safety Helmet Wearing Dataset)进行安全帽佩戴检测研究,该数据集中共有9044个人佩戴安全帽的目标和111,514个未佩戴安全帽的头部目标。数据集中一共包含7581张图片,其中将5457张图片作为训练集,607张图片作为验证集,1517张图片作为测试集。
4.3. 评价指标
本文使用准确率(Precision, P)、召回率(Recall, R)、平均精确度(Average Precision, AP)、平均精确度均值(mean Average Precision, mAP)等指标评价模型的检测精度,使用参数量(Parameter, Params)指标评价模型的大小。
其中准确率P和召回率R计算公式如下(7)、(8)所示:
(7)
(8)
式中TP为预测正确的正样本数,FP为预测错误的正样本数,FN为预测错误的负样本数。
平均精确度AP和平均精确度均值mAP计算公式如下所示:
(9)
(10)
式中N为总类别数,AP用于衡量模型对于某一类别的平均精确度,mAP为所有类别的AP的平均值。模型在实验结束后会根据预测结果得出准确率P和召回率R,将此两种指标作为横纵坐标可以绘制出P-R曲线,其曲线下面积就是模型对某一类的预测平均精确度AP,所有类别AP的均值就是mAP,mAP越大,模型的检测性能越好。
模型的参数量计算公式如下(11)所示:
(11)
Params表示一个卷积层不考虑偏重的情况下的参数量,其中K为卷积核的尺寸,Ci和Co为输入输出通道数。
4.4. 实验结果
4.4.1. 消融实验
为分析每一部分模块的改进对于模型整体系统的性能影响,同时为了保证实验的科学性,进行消融实验,将实验一共分为6组。编号1表示使用原网络进行检测;编号2表示引入坐标注意力模块;编号3表示改进特征提取网络;编号4表示利用K-Means++算法对锚框进行重新聚类;编号5表示引入CARAFE上采样算子;编号6表示将上述改进均添加得到的最终模型,实验结果如表2所示。
从表中数据可以看出,引入注意力机制,模型检测精度上升0.2%,改进特征提取网络后,模型的检测精度相比原网络上升了0.7%,由此证明提出的针对小目标的特征提取网络具有较好的检测性能,重新聚类锚框后,算法精度上升0.9%,改进上采样算子后,算法精度提升0.5%。实验证明各个模块对模型整体性能起良好的改进作用,通过改进后的算法拥有高达94.9%的检测精度,其优良的检测性能满足安全帽检测任务中的检测需求。
4.4.2. 对比实验
为了进一步验证改进后算法的有效性和实用性,将改进后的算法与目前主流的目标检测算法SSD、YOLOv4-Tiny、YOLOX-Tiny、YOLOv5s、及原网络YOLOv7-Tiny进行对比实验。其结果如表3所示。
Table 3. Results of comparison to others methods
表3. 对比实验结果
由上表3可知,本文提出的改进YOLOv7-Tiny算法在检测性能和模型参数量上相比当前一众主流算法有着较为明显的优势。在保证高检测精度的同时有着较小的参数量,满足实际应用场景中对安全帽检测的需求。为了更直观地验证改进后算法的优越性,将原YOLOv7-Tiny算法(左)与改进的算法(右)检测效果分别进行可视化分析,检测效果如图7~9所示。通过对比检测结果可以看出,本文提出的改进的YOLOv7-Tiny算法在远距离的小目标上以及遮挡等不利条件下,检测性能均优于原算法,减少了漏检情况,提升了算法的精度。

Figure 7. Target detection of the occlusion
图7. 遮挡目标检测

Figure 8. Small target detection at long distances
图8. 远距离小目标检测
5. 结束语
在建筑施工地等高危环境下,由于人员密集、物体遮挡目标、像素点较小等一系列因素的影响,进行安全帽检测任务较为困难,普遍存在小目标检测困难或检测模型参数量较大等问题。本文针对以上问题,提出了基于YOLOv7-Tiny的改进模型,通过改善特征提取网络,加强对小目标的特征提取能力,并引入了坐标注意力机制,让网络更加关注坐标信息,此外,引入CARAFE上采样算子,优化了网络上采样的质量。实验结果表明,改进的YOLOv7-tiny算法相比原网络,在参数量下降31.7%的同时,检测精度高达94.9%,相比原网络提升了1.5%,满足复杂场景下对安全帽检测的需求。