1. 引言
卫星定位系统(GPS)、地理信息系统(GIS)和遥感(RS)等理论与技术主要包括在现代空间信息技术中,结合先进的计算机技术,与此同时对空间数据进行采集、处理与应用 [1] [2] ,是推动社会经济发展的重要力量。空间数据因为其有时空相关性的特点,与其他类型的数据相比,对独立性变量假设的经典统计学方法难以使用,这也使得几何空间中的牛顿推测等方法并不适用。1970年,地理学第一定律由Toblert [3] 提出,也被称作空间相关性定律,其具体指的是“All things are related, but nearby things are more related than distant things”。空间相关性,指的是“地物之间的相关性与距离有关,通常来说,任何东西与别的东西之间都是相关的,但近处的东西比远处的东西相关性更强”。空间数据的分析和应用是由地理学第一定律提供理论基础,在地学领域中,最为重要的研究问题之一是空间推测中将离散点的测量数据转化为连续数据。通过几十年的不断研究与发展,空间推测算法趋于完善,并逐渐被应用到地质勘探、土壤环境、海洋水质、空气质量等诸多领域。但随着社会生产力水平的进步与提高,进一步凸显出对地理空间信息的多样性、时效性需求,这也进一步促使空间推测算法对地理空间智能领域提出了更高的要求。总之,进一步发展空间推测模型,对空间制图水平提出了更高的要求,对机器学习领域具有重要的现实意义。
目前,空间推测方法主要包括以下几类:地统计方法 [4] 、回归模型方法 [5] 、机器学习方法。目前空间推测方法中广泛应用的方法是地统计方法。地统计方法的基础是描述空间自相关性的地理学第一定律和描述空间异质性的第二定律。基于地理学第一定律的最近邻插值、反距离加权、径向基函数和局部多项式等确定性推测方法,以及普通克里金(OK)、简单克里金和回归克里金(RK)等都包括在地统计方法中。与确定性推测方法相比,地统计方法能在给出无偏最优推测结果的同时,得到推测结果的不确定性估计,但是难以解决空间异质性问题。例如:2012年,姚旭峰等 [6] 考虑空间中点和点之间的相关性,将空间统计学中的克里金方法引入到机械加工的平面度误差推测中,得出了克里金方法能够显著提高对平面度误差推测的准确程度的结论。
回归模型方法以地理学第三定律为基础,可以分为以下几类:多元线性回归模型、逐步回归模型、广义线性模型、广义加性模型。地理学第三定律认为:地理环境越相似,地理目标特征越相近。多元线性回归模型具有解释性强等优点,遥感、地形、植被、土壤电导率等数据均可作为环境变量与此模型相结合。然而,传统的MLR受限于数据分布:例如,若原始数据不服从正态分布,推测结果误差可能会比较大。逐步回归模型(Stepwise Regression Model, SRM)可在结合环境变量上对模型进行优化,利用AIC信息指标,通过统计指标和异常值测试进行识别和剔除冗余变量,将多重共线性降至最低。回归模型方法可以充分利用自变量数据,改善模型的推测精度。但是偶尔会出现的情况是部分数据难以全部精确获得,为了防止模型过拟合,与此同时,模型会产生残差。因为残差往往具有空间自相关性,所以在考虑属性相似性的基础上,综合利用空间位置关系信息能够在一定程度上提高空间推测精度。比如:2022年,关莹莹等 [7] 利用地理加权回归模型计算了分级人居环境适宜性指数,并探讨了其与人口、GDP密度的空间一致性,验证了适宜性较好的土地的利用效率。
机器学习方法在处理多维协变量数据方面具有极其重要的作用,2001年,Breiman [8] 提出随机森林(RF),并且说明了RF适用于回归问题;2018年,Tomislav等 [9] 提出了随机森林空间推测框架(Random Forest for spatial predictions framework, RFsp),其将预估点到样本点的缓冲距离作为推测因子加入到模型中,通过实验证明其相较于地统计方法推测精度得到提高;2020年,Sekulić等 [10] 提出了随机森林空间插值法(Random Forest Spatial Interpolation, RFSI)。该方法将邻近点的观测值与其到预估点的距离作为推测因子加入到随机森林中,以改进空间插值结果,并验证RFSI的推测结果优于克里金。目前,空间制图领域最前沿的研究方向之一是如何将空间位置关系信息融入到机器学习方法中 [11] ,提高空间推测精度。鉴于此,本文提出了基于多尺度地理环境变量的随机森林的空间推测模型(Spatial Prediction Model for Random Forest Based on Multi-scale Geographical Environment Variables),主要是在随机森林空间推测框架的基础上,将协变量的多尺度特征图层引入到模型中,多尺度策略较单尺度参数更能满足建模的需要,并以荷兰默兹河的土壤锌浓度数据作为案例,与RF、RFsp对比分析,验证了该方法的空间推测效果。
2. 研究区与数据来源
受地区、人为活动等各种复杂因素影响,在空间推测研究方面土壤锌浓度 [12] 广泛应用,因为土壤锌浓度往往呈现出比较复杂的空间分布趋势,本文通过Meuse数据集所对应的研究区以及包含的具体数值加以介绍,来更好地解释多尺度地理环境变量的随机森林空间推测模型 [13] 。
2.1. 研究区概况
本文选取收集在荷兰Stein村附近的默兹河洪泛区作为研究区域,位于北纬51˚42'54''、东经4˚40'4''之间。
2.2. 数据来源
本研究数据集包括了155个站点观测的土壤锌浓度数据、DEM模型数据 [14] 、地表水数据等,具体说明如下:
1) 土壤锌浓度数据。研究采用的是sp软件包中包含的Meuse数据集。该数据集提供了位置以及观察地点的许多土壤和景观变量,其中土壤锌浓度来自面积约为15 m × 15 m的复合样品。该数据集包括了155个站点的土壤锌浓度,单位为mg/kg。具体信息如表1所示。

Table 1. Statistical information of soil zinc concentration data at 155 stations of Meuse
表1. 默兹河155个站点土壤锌浓度数据的统计信息
2) DEM模型数据。数字高程模型(Digital Elevation Model,简称DEM)是DTM中最基本的部分,它是对地球表面地形地貌的一种离散的数学表达。http://ahn.nl/ [15] 是本研究采用的DEM模型数据的获取途径,其空间分辨率为1 km。
3. 研究方法
3.1. 空间推测方法
目前,在空间推测方法的发展过程,可以分为两个阶段:第一个阶段是确定性和地统计等传统科技方法的发展 [16] ,其理论性高,有大量假设条件,并且由于数据集的复杂性,很难满足。第二个阶段是机器学习方法的发展,机器学习作为一种新方法既属于统计学模型范畴,也包含半经验混合模型特性,可基于大数据获取对象特征,也可采取结合多种模型的方法来发挥各自优点,具有耗时短、准确度高、分辨率高和推测时间长等优点。
3.1.1. 随机森林空间推测方法与模型
随机森林(RF)是袋装树木的延伸,是一种基于分类回归的集成学习方法 [17] 。一些基准研究已经证明它是目前可用的最好的机器学习技术之一。
RF本质上是一种非空间的空间推测方法 [18] - [23] ,因为在MLA模型参数的估计过程中忽略了采样位置和一般的采样模式。这可能会导致次优推测和可能的系统性高推测或低推测,特别是在目标变量的空间自相关性高和点模式显示出明显的抽样偏差。为了克服这个问题,我们提出了RFsp (Random Forest for spatial prediction)模型,模型的表达式为:
其中,Z(s)为空间样本点s上的目标变量取值;xR是表面反射率的协变量,即通常是遥感图像的光谱信息;xP是基于过程的协变量,即辅助变量;xG是考虑观测值之间地理邻近性和观测值之间空间关系的协变量(模拟克里格法中使用的空间相关性)。
3.1.2. 多尺度地理环境变量的随机森林空间推测方法与模型
在RFsp中使用观测和未知位置的解释变量数据来研究空间关联性 [24] 。然而,在样本位置外提取不同地理信息的模型仍然有限,而且仍然越来越需要更有效地提取整个空间的地理信息。为了解决上述问题,本研究在RFsp的基础上将协变量的多尺度特征图层引入到模型中,根据模型精度,选择最适宜的建模尺度。其大致可以分为改进协变量和构建模型两部分,核心内容是针对RFsp中的地理环境变量进行改进,根据训练点和预估点的坐标,计算出预估点到训练点的欧式距离:
式中:
为预估点的坐标,
为训练点的坐标,尺度参数的表达式为:
其中,尺度间隔为Δr = 100 m,选取0 m、100 m、200 m作为定量的尺度标准,将预估点到训练点的欧氏距离di与尺度参数rk进行比较,当di ≤ rk时,将范围内所有的点对应的协变量的值取平均值xi,计算其平均值xi作为协变量的新的取值,从而得到一组不同尺度的协变量的值,将其作为建模变量输入,与原有的环境推测变量构建形成多尺度地理环境变量的随机森林空间推测(RFsp-MS)方法与模型。模型的表达式为:
其中,xG是经过计算之后得到的新的地理环境变量,具体展开如下:
多尺度地理环境变量的随机森林空间推测算法流程图可以如下表示:
协变量大致可以分为三类:地表水、到河边的距离、DEM模型数据,数据处理之后,得到了地理环境变量的多尺度特征图层以及参与推测的协变量有土地利用、铅浓度、土壤类型、海拔等,再加入已知训练点的土壤锌浓度建立模型。
建模的步骤可以如下:
步骤1:训练RFsp-MS模型
1) 删除155个样本点中的缺失值,并将剩余站点的观测值与推测变量值组合为Data;
2) Data按7:3的比例,划分为训练集与测试集;
3) 对训练集中的每个点,根据欧式距离公式计算其到预估点的距离Dist,将其与不同的尺度参数进行比较,计算出新的地理环境变量,并将其作为建模变量输入;
4) 训练RFsp-MS模型,推测测试集的土壤锌浓度并计算测试集的RMSE;
5) 比较不同的尺度参数对应的RMSE,选取最小的RMSE,并输出其对应的随机森林的参数。
步骤2:预估点推测
1) 对步骤1输出的最优随机森林参数以及新的地理环境变量构建RFsp-MS模型;
2) 利用构建的RFsp-MS模型推测预估点的土壤锌浓度。
步骤3:交叉验证
1) 运用五折交叉验证法来进行验证;
2) 初始化k = 1;
3) k对应的数据集为测试集,除k之外的4份数据集为训练集,对步骤1输出的随机森林的最优参数以及新的地理环境变量构建RFsp-MS模型,利用RFsp-MS模型推测测试集的土壤锌浓度;
4) 执行k = k + 1,返回第三步,直到k = 5;
5) 根据公式计算模型评价指标MAE、RMSE、CCC、R2。
3.2. 模型评价标准
为验证实验推测结果的有效性及准确性,选取RF、RFsp-MS (k = 0)及不同尺度的随机森林的空间推测模型进行对比,并利用平均绝对误差(Mean Absolute Error, MAE),其指的是模型推测值与真实值的误差绝对值的平均值;均方根误差(Root Mean Square Error, RMSE),反映的是模型的精度,误差越大,表示模型的精度越低;决定系数(Coefficient of Determination, R2),在回归模型中该标准发挥了评价模型好坏的作用。具体而言,回归模型对因变量y变化的解释程度是由其评估的。R2越大,表示模型的拟合度越好,可解释程度越高;反之,该值越小表示模型拟合有问题;一致相关系数(Concordance Correlation Coefficient, CCC)这四个评价标准加以比较,公式如下:
式中:
是交叉验证点sj的预估值;z(sj)是交叉验证点sj的实际观测值;N是交叉验证点的总数;SSE是交叉验证点的误差平方和;SST是总平方和;
与
是预估值与观测值的均值;
与
是预估值与观测值的标准差;ρ为预估值与观测值之间的相关系数。
4. 空间推测实验与结果分析
4.1. 空间推测制图结果分析
基于RF、RFsp-MS (k = 0)以及不同尺度的随机森林的空间推测模型的空间推测结果以及不确定性图(如图1、图2所示),可知土壤锌浓度含量推测结果大体上相似,但局部特征差异比较明显:由图1(d)推测结果可知,从颜色的深浅上来区分,默兹河东部地区土壤锌浓度含量较低,西部地区土壤锌浓度含量较高。由图2(c)的不确定性结果可知,推测标准差保持在较低的水平集中在绝大部分地区,较高的地区分布主要在默兹河的南部区域,由实际地理位置可以得出,默兹河的东南部地区海拔比其他地区高,导致站点数据稀缺,导致空间推测方法难以在这一地区捕捉到有效信息,如需更准确地掌握该地区的土壤锌浓度情况,还需要进一步获取样本点的信息。相比于其他方法,多尺度地理环境变量的随机森林空间推测方法由于使用了辅助数据,从而具有更丰富的细节信息,空间分布变化也更加合理。

Figure 1. RF (a), RFsp-MS (k = 0) (b), RFsp-MS (k = 1) (c), and RFsp-MS (k = 2) (d) soil zinc concentration prediction maps
图1. RF (a)、RFsp-MS (k = 0) (b)、RFsp-MS (k = 1) (c)、RFsp-MS (k = 2) (d)土壤锌浓度推测图
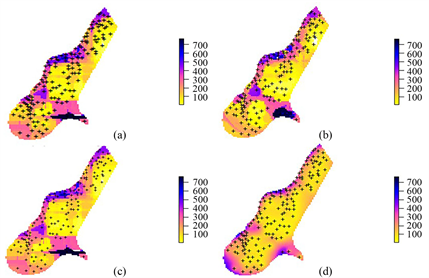
Figure 2. RF (a), RFsp-MS (k = 0) (b), RFsp-MS (k = 1) (c), and RFsp-MS (k = 2) (d) soil zinc concentration prediction uncertainty maps
图2. RF (a)、RFsp-MS (k = 0) (b)、RFsp-MS (k = 1) (c)、RFsp-MS (k = 2) (d)土壤锌浓度推测不确定性图
与RF、RFsp-MS (k = 0)、RFsp-MS (k = 1)三种模型的不确定性图相比,RFsp-MS (k = 1)模型的标准差相对较小,但是其标准差趋势呈现均匀分布,RFsp-MS (k = 0)的不确定性信息包含的信息相对较少,即无法更加标准地度量特殊点(预估点周围的样本点相对较少)的标准差。基于RF的三种不同的空间推测方法,RF、RFsp-MS (k = 0)、RFsp-MS (k = 1)与RFsp-MS (k = 2)在推测标准差方面不同之处主要集中在默兹河偏东南的区域,RF、RFsp-MS (k = 0)、RFsp-MS (k = 1)的标准差基本保持在相对较高的水平,RFsp-MS (k = 2)虽然减少部分地区的标准差,但仍有小部分区域保持在较高水平。结合四种不同的空间推测方法的推测结果与不确定性信息来看,RFsp-MS (k = 2)推测结果保持着较高的精度水平,并且在不确定性方面,RFsp-MS (k = 2)与RF、RFsp-MS (k = 0)相比标准差更小,与RFsp-MS (k = 1)相比,不确定性更加具有时效性与信息性 [25] - [28] 。因此,RFsp-MS (k = 2)模型的空间推测结果的分布更加合理。
4.2. 交叉验证结果分析
本文提出的多尺度的随机森林的空间推测模型 [29] 与RF、RFsp-MS (k = 0)、RFsp-MS (k = 1)交叉验证结果如表2所示。通过表2可以得出,在推测精度方面,RFsp-MS (k = 2)最高,RF最低,从模型的拟合程度来看,RFsp-MS (k = 1)、RFsp-MS (k = 2)都高于0.5,说明模型的拟合度较好。
Table 2. Accuracy of four speculative methods based on fifty fold cross validation
表2. 基于五折交叉验证的四种推测方法的精准度
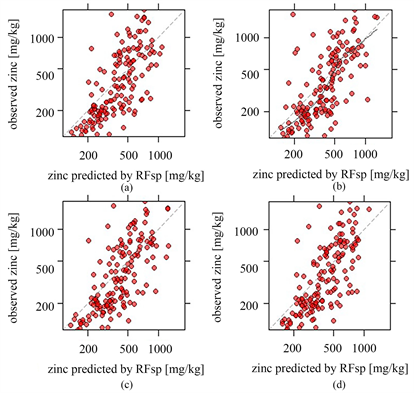
Figure 3. Correlation diagrams of RF (a), RFsp-MS (k = 0) (b), RFsp-MS (k = 1) (c), and RFsp-MS (k = 2) (d) based on observation values and predicted values
图3. RF (a)、RFsp-MS (k = 0) (b)、RFsp-MS (k = 1) (c)、RFsp-MS (k = 2) (d)基于观测值与推测值的相关图
进一步分析,由于RF [30] 是一种基于决策树的集成学习的方法,其没有考虑空间自相关性,可能会导致次优推测,在Meuse数据集的推测结果及图3的观测值与推测之的相关图中,没有表现出很高的推测精度;RFsp-MS (k = 0)将空间位置关系考虑在内,在本次实验中,推测精度处于一个中等的水平,但是模型训练过程中距离的应用可能导致推测结果的偏差;RFsp-MS (k = 2)是随机森林的空间推测与协变量的多尺度特征图层的结合,其在Meuse数据集的推测结果中,表现出了更高的推测精度,因此,相较于RF、RFsp-MS (k = 0),RFsp-MS (k = 2)在空间推测方面不失为一种好的选择。
5. 总结与展望
总览全部内容,本文主要的创新内容体现在基于随机森林空间推测的框架,结合地理环境变量的多尺度特征图层,提出了多尺度地理环境变量的随机森林的空间推测的方法 [31] ,该方法在空间推测中能够有效结合反映土壤锌浓度及影响因素的多维辅助变量信息与空间位置关系信息,可以有效地提高模型的推测精度,得到更为准确的空间推测结果。在RFsp模型中,我们使用了155个训练点来建模,随着数据大小的增加和更多的协变量层的增加,RFsp通常会在验证点导致令人满意的RMSE和MAE,而在交叉验证标准差中没有显示出空间自相关 [13] 。本文所提出的空间推测方法相较于其他方法,推测精度提高了10%以上。同时,其推测结果具有更丰富的细节变化信息和合理的空间变化。本文所提出的方法较适用于具有复杂空间异质性的土壤变量下的空间推测,但是其推测效果还有待于在其他数据集中检验。