1. 引言
城市中的各种功能建筑通常沿街道两侧线性分布,呈现一种城市资源集约高效的现象,可以代表性地展示城市街区功能结构分布。西班牙工程师索里亚·玛塔于1882年首次提出了基于线型城市的城市区域规划概念。在识别城市功能区时选择针对线性街道进行研究,对街区功能分布的划分,有利于改善兴趣点推荐、设施选址以及路线推荐等应用。
随着数据采集能力的增强,特别是在信息化背景下,诸多学者在如何充分挖掘大数据所隐含的城市功能区信息展开了一系列探索与尝试。例如,邬群勇等借助出租车轨迹数据分析每个地块交通起止点数量的时空分布特征将厦门岛划分为工作区、居住区和休闲娱乐区 [1] ;赵莹等基于手机漫游用户数将张家界划分为日常居住区、重点旅游区和其他波动区 [2] ;王俊珏等基于核密度与兴趣点大数据开展了城市功能分区研究 [3] 。
兴趣点(point of interest, POI)数据包含名称、类型、经度和纬度四方面信息,具有体量大、精确度高和时效性强等特点。POI数据记录社会经济各行业部门的空间位置信息,能够为精细识别城市功能区类型提供可能,从而为更好地认识城市空间结构、指导区域空间优化调控提供科学支撑。目前,一些学者基于POI数据进行了城市功能区识别研究,例如:Jiang等根据计算每个单元内POI出现频率,配对算法识别城市功能区 [4] ;Wang等通过核密度聚类实现功能区识别 [5] ;康雨豪等使用密度分数进行武汉市功能区识别 [6] 。上述研究中功能单元划分粒度较大,通常以区域为研究对象进行功能划分。而街道单元本身是认知城市的基本单元,因此本文选择包含街道、建筑和兴趣点数据的街区单元作为基本空间单元进行城市功能区识别研究,可以更准确地识别人们的活动,把握城市的功能结构分布。
观察发现,城市街区功能分布常常存在多种功能的混合,即混合功能区。现有的功能识别算法无法直接发现这些混合功能区,聚类算法结果簇标签通常为单一类型。识别混合功能区存在的挑战为当街区内出现两种及以上功能时,如何判断该区域功能混合,如何提取该街区功能区。基于以上观察,本文定义了城市街区混合功能区,提出了一种基于语义的街道功能有序聚类划分算法。以开放街道地图的路网数据和POI数据为主要数据源,基于层次聚类思想提出了针对线性街区的语义聚类算法。在判断该区域功能是否混合时,提出了利用度量街区的功能分布的纯度,并结合语义强度共同定义混合功能区,在提取该街区功能区时,对语义化层次树通过层次遍历进行提取。
本文的主要贡献如下:
(1) 提出了针对城市街区的单一功能区和混合功能区定义,对城巿功能区的划分更加精确合理。
(2) 提出了支持城市功能街区划分的有序语义聚类算法,可以实现对单一功能区和混合功能的识别。
(3) 利用真实数据进行实验,验证了算法的有效性。
2. 相关工作
本文相关工作涉及城市功能区划分以及聚类算法两个方面。
2.1. 城市功能区划分
根据采用的数据不同,城市功能区划分方法可分为基于静态数据的功能区划分、基于动态数据的功能区划分。
早期的基于静态数据的功能区划分主要是基于遥感影像、土地利用、面板数据等,根据土地的自然属性对城巿功能进行分类。另一类静态数据为POI数据,通过POI数据反映各种设施的多样性和混合程度。Zhai等通过构建Place2vec模型来获取POI地理信息,改进了功能区识别框架 [7] ;Ran等基于POI数据对长沙巿生活服务业的空间格局进行了深入分析 [8] 。随着数据获取途径的增加以及GPS的普及,利用用户轨迹数据进行功能区识别与划分突破了传统的功能分区思路,Song等根据公园地理位置的照片数量和视觉内容(来自Instagram和Flickr平台)探索了公园的使用情况 [9] 。然而,这些方法受到用户数量和用户足迹定位精度的限制,所以分类结果的准确性较差。
将POI数据与动态轨迹数据结合的现有研究中,都选择采取矢量栅格化划分城市地块,将城市不同等级的路网分割为互不相同的空间单元。冯慧芳等利用出租车GPS轨迹和POI数据,利用城市栅格方法构建栅格关联规则矩阵,识别兰州市城市功能区 [10] 。陈泽东等利用出租车GPS数据提取地块的居民出行时序特征,采用期望最大化算法,进行北京城市区识别与空间交互研究 [11] ;由于路网数据本身原因,对城市内部功能区范围界定尺度较大,且对于功能区划分研究以定性为主,缺乏对功能区混合现象的研究。
现有城市功能区划分以区域为单位,而本文研究对象为线性分布的街区,采用的划分方法应考虑对象的顺序关系。另外,现有研究中大多仅将城市划分为单一功能区,如商业功能区、居住功能区、工业功能区等,缺乏对城市功能区混合现象(如商业与居住功能区混合)的研究。对此问题,本文研究单一功能区与混合功能区发现方法。
2.2. 聚类算法
聚类是按照特定标准把数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不同簇中的数据对象高度相异。
本文数据为有序的数据,针对有序数据的聚类算法,Fisher最优分割法采用的最优二分割法只能求得局部最优,不适合由于样本长度较大时的情况。高苏等通过K-modes聚类方法构建的有序聚类方法得到海员职业幸福感指数的等级划分及其相应的语义描述 [12] 。姚尧等通过时序出租车出行数据和POI数据描述居民出行模式,结合动态时间规整和K-MEDOIDS聚类算法识别城市的功能属性和空间结构 [13] 。苏月同等通过对站点有序客流数据聚类,提出了一种基于有序样本聚类的站点级差异化高峰时段识别方法,识别出城市轨道交通站点高峰时段 [14] 。本文数据为自然顺序下的街道单元POI数据,现有的有序数据聚类,无法直接用于本文。
基于本文数据特点,提出构建一种支持城市功能街区划分的有序语义聚类算法,在不改变数据自然顺序前提下,对其进行聚类分析,完成城市街道单元功能区的划分,功能区包含单一功能区、混合功能区。
3. 问题定义
3.1. 定义1 (城市街区)
城市街区S为城市中一段道路及其两侧所属的空间对象集,空间对象集P由有序的对象组成表示为(p1, p2, p3, …, pn),其中pi的序号为i。每个对象pi表示为(ID, loc, c, info),其中ID为对象的序号,loc为街区S上的相对位置,c为对象类别,info为对象描述信息。
本文将对象类别定义为6个,分别为居住、商业、行政、公共服务、医疗和教育。为了对象简化表示,将道路两侧的对象pi投影到街道上,利用映射后街道内包含的对象pi作为研究对象。为了方便表示,将居住、商业、行政、公共服务、医疗和教育分别用字母abcdef代替。例如某街区POI经过简化后可表示为cecea,表示POI点分别是行政–医疗–行政–医疗–居住等。
3.2. 定义2 (城市街区单位区段)
给定城市街区S以及街区内有序对象集P,按单元长度对街区划分生成多个单位区段,表示为(s1, s2, s3, ..., sm)。对于区段si根据区段中的对象分布可以得到区段特征向量fi,fi的每一个维vj对应一个区域功能,其值可由相应空间对象数目获得。
例如某条街区的POI表示为ceaceabbcc ccccccccbb aeacaaabac,生成3个分段s1、s2、s3分别为|ceaceabbcc|、|ccccccccbb|、|aeacaaabac|,区段特征向量s则会产生3个向量f1 (0.2, 0.2, 0.4, 0, 0.2, 0), f2 (0, 0.2, 0.8, 0, 0, 0), f3 (0.6, 0.1, 0.2, 0, 0.1, 0),向量的各维数值为相应功能对象的所占比例。
给定城市划分区段的特征向量,通过特征向量的各维数值可以确定街区功能,选择维数值大的功能作为街区功能。本文定义了两种功能区,一种为单一功能区,另一种为混合功能区。
3.3. 定义3 (单一功能区)
给定城市划分区段S的特征向量f,当f的最大取值维
时,则称该区域为单一功能区,功能区标签为该维的功能类型,其中
为功能确定阈值。
本文提出了混合功能区的概念,混合功能指街区的功能表现为两个以上功能特征,并且这些功能分布均匀。为了评价一个线性城市街区S的功能分布均匀性,本文提出了线性层次基尼指数度量Gini(S),如定义4所示。
3.4. 定义4 (线性层次基尼指数)
给定城市划分区段S及其单位区段,设单位区段组为最细粒度层表示为S0,将S0相邻区段两个合并生成S1层,依次合并直到合成为一个区段,为顶层表示为Sq,则区段S的线性层次基尼指数为各层基尼
指数之和,表示为
,其中
。
线性层次基尼指数是为了衡量区段S内功能类型分布的不纯度,基尼指数越大,不纯度越高,功能的混合程度越高。设计线性层次基尼指数为了度量街区的总体的功能分布,采用某一划分粒度的基尼指数无法度量。例如区段S共包含6个单位区段分别为|aa|aa|bb|bb|aa|bb|,线性层次基尼指数
,区段
共包含6个单位区段分别为|ab|ab|ab|ab|ab|ab|,线性层次基尼指数
。
3.5. 定义5 (混合功能区)
给定城市划分区段S的特征向量f,存在一个f的维的子集V,满足
且任意两个维度
与
满足
,则S为候选混合功能区。当S的单位区段功能分布均匀性满足
则称S为混合功能区,标签为V相应功能。其中Gini(S)为S的线性层次基尼指数,
为功能分布均匀性阈值。
混合功能区由语义强度以及混合分布性确定。语义强度需满足特征向量内任意两个及以上的各维数值相加大于等于阈值
时,任意两维数值差小于等于
。例如特征向量f (0.1, 0.2, 0.4, 0, 0.3, 0)、
、
时,
,
,则此街区为候选混合功能区,其功能特征为子集V (0.4, 0.3)。
混合分布性由V内线性层次基尼指数Gini(V)确定,当
时说明子集V内的混合分布性越高,子集
由两段(3, 2) (2, 2)组成,
时,
,则称区段为由公共服务和教育混合的混合功能区。
将相邻区段进行合并时,簇间相似度采用余弦相似度计算,当两个簇Ri、Ri+1合并时,需要生成一个新簇,新簇的特征向量采用加权平均来计算。具体的计算方法为式1:
(1)
例如,给定两个簇长度l1、l2分别为2、4,向量分为别(0, 0.6, 0.4, 0, 0, 0)、(0, 0.2, 0.6, 0, 0.2, 0),则新簇的特征向量为(0, 0.333, 0.534, 0, 0.133, 0)。
4. 基于语义的有序聚类算法
本节介绍基于语义的有序聚类算法,用于将城市街区按功能特征划分,并生成功能区。算法包括数据序处理、语义化层次树生成和功能区提取3个阶段。首先,在数据序处理阶段将城市街区进行单位划分,根据单位区段内的对象分布得到特征向量线性序列。在语义化层次树生成阶段采用凝聚层次聚类的方法将相邻的相似分段合并,得到层次树,并将层次树结点进行语义化,得到语义化层次树。在功能区提取阶段,进行单一功能区与混合功能区识别,获取给定街区的线性功能区。
4.1. 数据预处理
给定待处理的街区S,需要将街区周围的一定距离POI对象投影到S,生成线性功能类别有序序列。然后,将线性有序序列划分为街区单元区段,提取出街区单元区段的特征向量,生成特征向量线性序列。
本文采用2种方法划分街区单位区段,第1种是将POI点按距离均等划分,给定一组POI功能数据,将其按照等长进行划分;第2种是将功能相同的类别合并后,再采用近似等距离划分。
例如:str{aaabbccccaaaccc},当采用第1种将POI点按距离均等划分时按每5个POI划分,划分结果为{aaabb},{cccca},{aaccc}。采用第二种划分,相同字符合并处理后可划分位置数组
。第一次位置划分位置数值取5,
,则
,第二次位置划分位置数值取10,
,向后平移取12,则
,
,则
,输出划分结果为{aaabb},{ccccaaa},{ccc}。
在提取出线性有序序列后,根据本文研究的六个功能类型进行类别重新分类,形成包含功能标注的线性类别序列,对线性类别序列按照划分位置数组X进行划分,得到单位区段s1、s2、s3,...,sm,根据定义2生成每段街区分段的特征向量(f1, f2, …, fm)。
4.2. 语义化层次树生成
在聚类生成语义化层次树阶段,将提取的街区分段的特征向量作为结点,通过余弦相似度计算相邻结点的相似度,选择相似度最高的两个结点进行合并,并根据公式1生成新的特征向量,以此反复生成层次树。将层次树结点进行语义化,结点的语义化分析指根据结点区段的特征向量将该结点定义为单一功能区或混合功能区,最终得到语义化层次树。
算法1给出了层次树生成过程,初始化层次树T为空(第1行)。当区段集中多于1个区段时,进行结点合并生成层次树(第3~12行)。首先将最大相似度simMax初始化为0,最大相似度的相邻区段标号初始化为0 (第3~4行),计算相邻区段特征向量的余弦相似度,查找一对相似度最大的相邻区段fi,fi+1,将相似度赋值给simMax (第5~7行)。i赋值给m,将找出的相邻结点及合并后的结点插入T中,并将区段集S中删除sm,sm+1,插入合并区段sm, m+1 (第8~12行)。最后返回层次树T (第13行)。
算法1由两层循环构成,区段集中区段个数为n,特征向量个数为n,则算法的时间复杂度为O(n2)。
算法2给出了结点语义化过程。层次树T中每一个结点进行语义化分析(第1~5行),当某一结点的特征向量fm中某一维大于定义3定义的阈值
时,则确定该区段为单一功能区,功能区标签为该维的功能类型(第2~3行)。当某一结点的特征向量fm中任意两个及以上的各维数值相加大于等于定义3定义的阈值
,且任意两个维度差满足定义5定义的阈值
,该结点的线性层次基尼指数大于等于定义5定义的阈值
,则确定区段Sm为混合功能区,功能区标签为i,j代表的功能类型(第4~5行),返回节点语义化的层次树T' (第6行)。
算法2中时将整个层次树T结点访问并语义化,所以其时间复杂度为O(n)。
4.3. 功能区提取
功能区的提取需要对语义化层次树提取结点。提取层次树结点是指根据功能区个数k从上往下提取层次树的结点,提取过程中若该结点为单一功能区,则可以分解该结点的左右孩子结点,若该结点为混合功能区,则将该结点及其包括的所有孩子结点视为整体,提取时不再进行分解,提取至结点个数等于k。
算法3给出了层次树结点提取过程。算法采用层次遍历的方法进行结点提取,初始化一个队列Q,先将根节点加入队列(第1~2行)。当队列不为空时进入循环,如果队列中的结点语义化为单一功能区,将其左右孩子结点加入队列并删除该结点(第3~6行)。如果队列中的结点语义化为混合功能区,则访问该结点,将其加入最终遍历序列中(第7~8行)。当队列中元素个数等于所提取聚类个数时,停止循环,输出队列中结点(第9~10行)。
5. 实验分析
对于本节采用真实数据集对所提出的算法模型进行实验验证,对比分析各方法的性能。
5.1. 实验数据集与实验参数
本文选取的线性街道范围为复兴路至建国路,全长20千米。POI数据来自百度地图,北京市的路网数据来自开放地理数据平台(http://www.locaspace.cn/)。本文将POI数据与路网数据进行匹配后,只选取街道两侧各300米内的POI数据投影到街道上,形成的沿街道路两侧的线性有序序列,生成共1102个POI点,并根据《城市用地分类与规划建设用地标准》结合北京市实际情况,将POI 数据分成居住、商业、行政、公共服务、医疗和教育6大类,其中各类POI数为居住54个,商业694个,行政298个,公共服务32个,医疗10个,教育14个。
本文采用轮廓系数(Improved Silhouette Coefficient, ISC)来度量所提出来的聚类方法的效果。由于所聚类数据对象为有序POI,将轮廓系数进行了修改。具体计算公式如式2所示。
(2)
其中,a(i)为i向量到所有它属于的簇中其它点的平均距离。由于所聚类数据对象为有序POI,所以簇间距离只包括相邻簇之间的距离,则b(i)为i向量到相邻簇内的所有点的平均距离。n为簇内向量个数。
轮廓系数取值范围为[−1, 1],越趋近于1代表内聚度和分离度都相对较优,聚类效果越好。
在判断功能区类型时,通过设置参数的不同的取值,对比评价不同聚类方法的性能,参数取值如表1所示。
5.2. 实验评价
利用现有的聚类方法与本文提出的聚类方法进行比较,具体方法表示如下,其中方法(1)~(4)为比较方法,(5),(6)为本文提出来的聚类方法。
(1) 等分划分层次聚类法(Equidistant Method, EM):等分城市街区,层次聚类生成层次树后,取k簇。
(2) 等分去孤立点法(Equidistant remove isolated points method, ER):等分城市街区,层次聚类生成层次树,去除孤立点后,取k簇。
(3) 合并等分法(Merge divide method, MD):将功能相同类别合并后,再近似等分街区,层次聚类生成层次树,取k簇。
(4) 合并等分去孤立点法(Merge divide remove isolated points method, MDR):将功能相同类别合并后,再近似等分街区,层次聚类生成层次树,去除孤立点,取k簇。
(5) 等分语义法(Equal division semantic method, ES):等分城市街区,对层次聚类生成的层次树,进行结点语义分析生成混合功能区后取k簇。
(6) 等分语义去孤立点法(Equidistant semantic remove isolated points method, ESR):等分城市街区,对层次聚类生成的层次树,进行结点语义分析生成混合功能区,并且去除孤立点后取k簇。
本文通过设置不同的参数,对比分析六种方法聚类效果。第1个实验是当k变化时,各算法的效果。实验结果如图1(a)~(d)所示。其中
,
,
时,g分别取200 m,300 m,400 m,500 m。
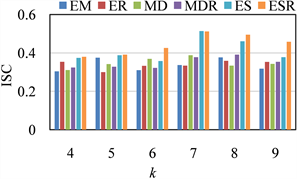
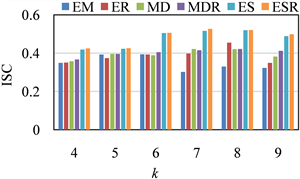 (a) g = 200 m (b) g = 300 m
(a) g = 200 m (b) g = 300 m
 (c) g = 400 m (d) g = 500 m
(c) g = 400 m (d) g = 500 m
Figure 1. Improved silhouette coefficient map for dividing distances
图1. 划分距离的轮廓系数图
由实验1结果可知,ESR优于其他方法,且g = 300 m,k = 7时,6种方法的聚类效果均为最优。
第2个实验是改变b的取值,评估6种聚类方法的效果,实验结果如图2所示,其中g = 300 m,k = 7,
,
。由实验2结果可知,ESR优于其他方法,且当
时,6种方法的聚类效果均为最优。
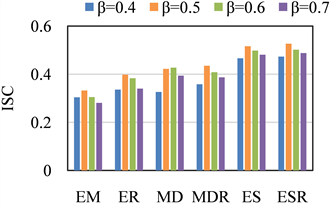
Figure 2. Improved silhouette coefficient plots with different
value
图2. 不同
取值的轮廓系数图
功能区的提取需要对语义化层次树提取结点。提取层次树结点是指根据功能区个数k从上往下提取层次树的结点,第3个实验是改变
的取值,评估6种聚类方法的效果,实验结果如图3所示。其中,g = 300 m,k = 7,
,
。由实验3结果可知,ESR优于其他方法,且当
时,6种方法的聚类效果均为最优。
功能区的提取需要对语义化层次树提取结点。提取层次树结点是指根据功能区个数k从上往下提取层次树的结点,由以上实验结果观察可知,6种方法中同样操作方法时去除孤立点方法优于未去除孤立点方法。方法ES和ESR优于其他4种方法,原因是对于混合功能区的度量,使得更精确的计算区段内各类POI分布纯度,以及整个区段的功能语义强度。对于街道的划分距离g,当g = 200 m时六种方法均为最优,当划分距离过近或过远,单位区段内POI个数较少或较多,都无法精确表示该区段的功能特征。对于功能确定阈值
,即为单一功能区确定阈值,当该值越小,单一功能区的纯度越低。功能分布均匀性阈值
的取值参考基尼指数,当该值越大,不纯度越高,功能的混合程度越高。
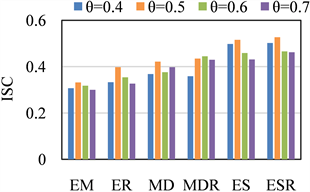
Figure 3. Improved silhouette coefficient plots with different
value
图3. 不同
取值的轮廓系数图
6. 结论
本文研究了城市功能街区划分问题,提出了一种支持城市功能街区划分的有序语义聚类算法。该算法重新定义了混合功能区的度量,根据其语义强度以及混合分布性确定混合程度,并根据语义分析结点,进行簇的提取。为了评估所提出算法的性能,将其与基本方法进行比较,并利用真实数据集进行了实验验证。
NOTES
*通讯作者。