1. 引言
眼底视网膜血管的形态结构能够反应出人体的健康状况,医生通过观察分析眼底视网膜血管图像来诊断黄斑水肿、糖尿病性视网膜病和青光眼等眼部疾病 [1] 。因此,对视网膜血管图像进行精确分割,进而分析血管形态对于计算机辅助诊断眼部疾病有很高的实际应用价值 [2] 。目前,视网膜血管图像分割依旧通过专业医生人工分割,由于眼底视网膜血管结构极其复杂,曲率高,形态多样导致人工分割的过程十分繁琐耗时且容易出错 [3] ,所以研究利用人工智能技术完成视网膜血管自动分割的方法非常有必要。
视网膜血管的自动分割方法主要有两类:无监督方法和有监督方法。使用无监督方法的传统医学图像分割算法包括基于匹配滤波 [4] 、基于区域生长的分割算法等 [5] 。有监督分割方法是依靠人工标注出来的数据信息来训练模型,并进行迭代学习得出效果最好的结果模型。有监督分割方法主要有浅层模型方法和深度神经网络方法,前者有K最邻近(KNN)算法 [6] 、支持向量机(SVM) [7] 等。近几年在图像分割邻域深度学习技术有了广泛而深入的应用。2014年Long等提出了全卷积FCN模型 [8] ,首次将深度学习技术应用于图像分割;Ronnebergero等在2015年提出的UNet模型在医学图像分割邻域上受到了广泛关注 [9] ,该模型提出了编码解码的网络结构,并且在同层特征图用级联操作实现补充上下文信息的功能;Oktay等人在2018年在处理CT腹部数据集的UNet网络中研究加入了一种注意力机制 [10] ,该机制通过增强相关区域权重来提高模型的敏感性和准确性;Zhou等人在2019年提出一种新的UNet++网络 [11] ,在UNet网络的编码器与解码器之间加入了密集跳跃连接,获取了不同层次尺度的特征并通过特征叠加的方式整合,同时获取图像浅层和深层特征,缩短了编码器与解码器之间的语义差别鸿沟 [12] 。尽管现有的算法已逐渐提高了血管分割的准确性,但仍存在诸如血管断裂、血管末端的遗漏分割以及对空间信息关注不足等问题。
针对视网膜血管图像中血管管径细小、形状不规则和连接处复杂等特点,本文在UNet++的基础上改进设计了一种新的网络模型结构,该模型可以充分提取多尺度的血管特征,同时避免分割结果中血管图像细节的丢失。本文主要的工作内容包括:1) 使用空洞卷积级联模块替代传统卷积模块作为编码–解码结构的特征提取部分,来增大模型特征提取时的感受野,使模型能够多尺度的提取血管图像特征,从而更精确的处理血管的细节。2) 在特征提取的步骤后采用了通道注意力与空间注意力级联模块来提高与分割任务相关的通道特征权重和空间特征权重,使网络达到更好的分割性能。3) 在特征提取的下采样部分改进使用普通卷积来代替常规的最大池化,避免了血管图像有效特征在下采样传递时的丢失。本文提出的Dil-UNet++模型整体框架如图1所示。

Figure 1. The overall framework of the Dil-UNet++ model
图1. Dil-UNet++模型整体框架
2. 主要研究内容
2.1. 空洞卷积
视网膜血管分割网络模型需具有可提取细小血管特征的卷积核,即针对小尺寸特征的感受野应较小;还需有感受野较大的卷积核提取主干血管,精确定位较大尺寸特征,所以提取特征的模块对于感受野大小要非常敏感,使模块可以根据血管的尺寸特征进行多尺度的提取分割最后进行融合,从而能够对血管的细节和主干区域同时进行检测,最终提取出全部完整的血管结构 [13] 。空洞卷积又称为扩张卷积,在标准卷积核中相邻的数字行列间插入0值做填充,从而扩大卷积核整体感受野。由于空洞卷积具有感受野可调的特点,有利于提取不同尺寸特征,在不增加计算参数的同时可以保留网络细节结构,所以利用空洞卷积进行网络优化适用于视网膜血管分割任务。
空洞卷积和普通卷积感受野大小计算可以使用空洞率r来转换,转换公式如式1所示。
(1)
在式子中,RFi表示第i层的感受野,ksize表示卷积核大小,stridei表示第i层的步长。
在本文提出的网络中,在网络编码部分不同层具有可变感受野大小的特征提取模块。该模块可以有效地同时定位分割血管的整体结构和边缘端点部分。由于卷积核中插入了0值的行列,所以空洞卷积核在运算时可能会受插入空洞的影响,从而造成一些特征像素点没有被覆盖,这些像素点没有参与卷积运算而造成图像信息丢失,为了解决该问题,本文在经过实验比较后设置了空洞率大小分别为2、5、7的三层空洞卷积组合为一个模块,并且在三个空洞卷积之后加入数据归一化方法(Batch Normalization),该结构在不破坏原有网络结构的前提下,可加快训练收敛的速度,使模型训练更加稳定。在特征图经过批量标准归一化之后使用Relu激活函数 [14] ,可以促进网络的稀疏性,减少网络进行前向传播时的计算量,从而缓解梯度消失的问题。将特征图经过三层的空洞卷积处理之后进行融合,最后使用
卷积输出对应大小的特征图实现网络的特征提取功能。空洞卷积模块结构设计如图2所示。
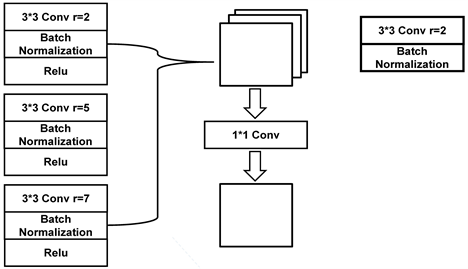
Figure 2. Structure of the dilated convolution module
图2. 空洞卷积模块结构
2.2. 卷积注意力模块
本文在UNet++网络密集跳跃连接中嵌入卷积注意力模块,使网络既能精确提取特征图中的血管细节部分的同时,又能增强对于血管主干结构的识别能力,同时还可以抑制其他无关噪声,减少由病理区域和阴影区域引起的干扰。卷积注意力模块由通道注意力与空间注意力级联组成。其中,通道注意力模块可以通过增加特征关键通道的权重,捕捉血管图像中的目标特征通道;空间注意力模块是通过获取特征的空间位置信息,将不同权重赋予各特征的空间位置,以有效提升模型分割效果。卷积注意力模块结构如图3所示,主要通过通道注意力机制与空间注意力机制协同处理,实现特征的多尺度提取融合。
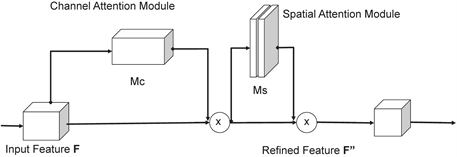
Figure 3. Structure of convolutional attention module
图3. 卷积注意力模块结构
2.2.1. 通道注意力机制
通道注意力主要功能是保留不同特征通道之间的结构信息。首先将大小为H × W × C的血管特征图F输入分别进行全局最大池化和全局平均池化来聚合特征的空间信息,将空间维度压缩为1,保留通道信息,从而得到两个不同的1 × 1 × C特征信息通道图,再将这两个特征信息通道图的每个通道都进行特征聚合,并送入共享的多层感知机(MLP, Multilayer Perceptron) [15] 进行通道权重信息分配,将重新分配好权重信息的通道特征图再经过Sigmoid激活函数得到最终的特征图。该机制细化语义特征能力更强,能够精确的提取血管边缘特征通道信息。计算公示如式2所示,通道注意力机制如图4所示。
(2)
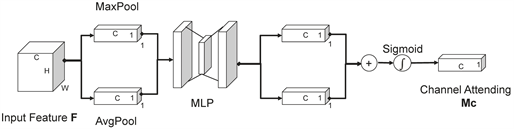
Figure 4. Channel attention mechanism module
图4. 通道注意力机制模块
2.2.2. 空间注意力机制
空间注意力可以注意到关键信息的位置,并增强提取有用特征的能力。首先将输入大小为H × W × C的血管图像依次进行最大值池化和平均池化,将特征图像的通道维度压缩为1,保留空间特征信息,得到两个不同的H × W × 1特征信息空间图,然后将这两个特征信息空间图进行拼接,再经过卷积核大小为
的卷积层重新分配空间特征权重,最后将重新分配好权重的空间特征图经过Sigmoid激活函数处理得到最终的特征图 [16] 。该机制有助于血管复杂连接处特征信息的提取。计算公式如式3所示,空间注意力机制如图5所示。
(3)
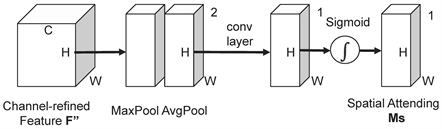
Figure 5. Spatial attention mechanism module
图5. 空间注意力机制模块
2.3. 卷积下采样
在传统的视网膜血管分割网络中,编码器部分下采样通常使用池化操作来传递特征信息,尽管池化操作可以减少特征图参与运算的参数个数和网络的计算量,但是无论是最大池化还是平均池化都会在信息传递时不可避免的丢失一些血管细节信息。本文提出模型采用了卷积模块代替池化模块来实现特征传输的下采样操作。经过实验证实,该模块虽然会稍微增加计算量和网络参数数量,但是下采样之后血管特征信息的保留效果更好。
最大池化操作的表达式如式3所示:
(4)
式中输入特征图为X,输出特征图为Y,
表示滑动框的尺寸,max表示对滑动窗内的特征值取最大值。
平均池化操作的表达式如式5所示:
(5)
式中
表示滑动框的尺寸,average表示对滑动窗内的特征值取平均值。
将一个尺寸为4 × 4大小的特征图,分别输入到尺寸大小为2 × 2、步长为2的最大池化块和平均池化块中计算得到输出特征图,如图6所示。
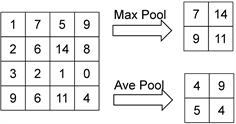
Figure 6. Example diagram of maximum pooling and average pooling
图6. 最大池化与平均池化例图
卷积操作的公式如式6所示:
(6)
式中定义输入特征图X与卷积核W的二维卷积操作为
,h和w表示卷积核的大小,wu,v表示卷积核,
表示输入特征图。
将一个尺寸为
大小的特征图,与一个尺寸大小为
,步长为2的卷积核卷积计算后得到输出特征图,如图7所示:

Figure 7. Convolutional down-sampling example
图7. 卷积下采样例图
由图6、图7输出特征图结果可知,最大池化操作选择每个池化窗口中的最大值作为输出,这可能会忽略掉较小但有意义的特征而导致输出特征图的失真;平均池化对每个池化窗口中的特征取平均值,这可能会丢失某些空间位置的细节信息导致输出特征图不完整;卷积操作通过卷积核在输入特征图上进行窗口滑动,遍历特征图中的所有信息来计算特征值,得到最后输出的特征图,该操作可以最大程度的使所有特征信息参与运算从而避免信息丢失。因此,在网络下采样的过程中使用卷积代替池化,可以尽可能实现特征信息的完整传递。同时卷积作为一个可学习的操作,可以通过反向传播来更新参数,从而更好地适应分割任务。
3. 实验结果与分析
3.1. 实验环境配置
实验平台的操作系统基于64位Windows,python版本为3.8,编程软件为PyCharm,模型训练和测试基于深度学习框架PyTorch 1.13.0,实验代码中使用Adam优化器,损失函数使用CrossEntropyLoss2d,初始学习率设置为0.005。
3.2. 数据集选择
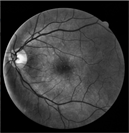
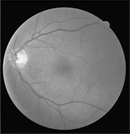
本文使用DRIVE眼底视网膜血管图像数据集来验证模型分割的效果 [17] ,目前视网膜血管分割研究大多数都是通过处理此数据集进行对比和验证。DRIVE数据集一共包括了40张彩色眼底血管图像,每一张图像尺寸为565 × 584,其中7张存在早期糖尿病视网膜病变现象,33张不存在糖尿病视网膜病变现象 [18] 。在这数据集中官方设定前20张图像作为训练集,后20张图像作为验证集使用 [19] 。每张图像都有其对应的人工分割的血管真值图像和其对应的掩膜 [20] 。数据集图像如图8所示。


 (a) 数据集原图 (b) 数据集标签图(c) 数据集自带掩膜
(a) 数据集原图 (b) 数据集标签图(c) 数据集自带掩膜
Figure 8. DRIVE dataset image
图8. DRIVE数据集图像
3.3. 数据集预处理
DRIVE数据集中的彩色血管图像都是RGB模式图像 [20] ,为了减少背景噪声、光照不均等因素对图像分割的影响,在模型训练前采用了预处理方法将图像中的血管部分突出显示以提高分割精度。首先将彩色图像灰度化处理 [21] ,得到血管与背景对比度较高的灰度化图像;再通过自适应直方图均衡化操作限制图像对比度 [22] ,凸显血管部分,同时抑制图像中的不相干噪声;最后使用自适应Gamma矫正操作 [23] ,自适应调整图像的曝光度,解决图像光照不均匀的问题,进一步突出血管特征部分。数据集预处理的各阶段图像如图9所示。

 (a) 原图像 (b) 灰度化图像(c) 直方图均衡化图像 (d) Gamma矫正图像
(a) 原图像 (b) 灰度化图像(c) 直方图均衡化图像 (d) Gamma矫正图像
Figure 9. Images at various stages of pre-processing
图9. 预处理各阶段图像
3.4. 数据量扩增
由于DRIVE数据集图像数量较少,模型训练时容易出现过拟合的问题 [24] ,本文对数据集图像采用随机裁剪的操作来扩充数据集数量,从每张血管图像的原始和标记图像中随机选择了大小为48 × 48的2,000个局部样本块,用于模型的训练,加强了模型的泛化性能。图10为随机裁剪后的血管图像样本块和相对应的标签图像样本块。
 (a) 视网膜血管图像样本块
(a) 视网膜血管图像样本块 (b) 视网膜血管标签图像样本块
(b) 视网膜血管标签图像样本块
Figure 10. Retinal vessel image after cropping
图10. 裁剪后视网膜血管图像
3.5. 评价指标参数
视网膜血管图像分割的结果分为两个部分:血管部分和非血管部分,血管部分表示为正值,非血管部分表示为负值 [25] 。在分割结果验证评价中,对于血管部分的像素点,预测结果与专家手工分割结果相同的像素点数称为真正值(True Positive, TP),不同的像素点数则称为假正值(False Positive, FP) [26] ;对于非血管部分的像素点,预测结果与专家手工分割结果相同的像素点数称为真反值(True Negative, TN),不同的像素点数则称为假反值(False Negative, FN) [27] 。为了验证分析本文模型的有效性,选用评估医学影像分割效果常用的评价指标:相似系数(Dice) [28] 、均并交比(MIOU)、准确率(Accuracy)、精确度(Precision)、F1 Score [29] 。公式分别如下。
同时,也引入PR与ROC的曲线面积评价指标,PR曲线综合考虑了召回率和精确度,ROC曲线综合考虑了敏感度和精确度 [30] ,PR与ROC的曲线下方面积越大,表明模型具有更好的分割性能 [31] 。
3.6. 实验结果与分析
经过实验验证本文提出的模型对视网膜血管分割有更好的效果,在DRIVE数据集上分割结果如图11所示,从整体图像分析,可以看出模型分割的结果与专家手工分割的结果十分接近,在血管主干网络的连接处以及血管末端细节部分都实现了精确分割,从分割结果来看,Dil-UNet++能够更清晰地区分血管和背景,并降低了血管的误分类率。同时,在低对比度和噪声干扰的条件下,Dil-UNet++能够确保血管的连通性和完整性,模型表现出了良好的抗干扰性。因此,本文提出的模型能够实现对复杂视网膜血管的精确分割。
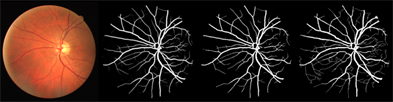
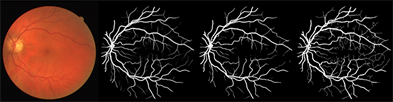

Figure 11. Example of segmentation results for the DRIVE dataset (original, probabilistic prediction, binary prediction, and labeled graphs in that order)
图11. DRIVE数据集分割结果示例(依次为原图、概率预测图、二值预测图和标签图)
交叉处血管和亮斑处血管的局部放大图如图12所示。由图可知,本文所提模型对交叉处和亮斑处的血管有着精确的分割,细小血管保留也比较完整,血管平滑度和连通性更是优于手工分割标签图,局部放大视图证明了Dil-UNet++在分割视网膜血管细节方面的优越性和稳定性。
本文实验选取了常用于二维图像分割任务的交叉熵损失函数(CrossEntropyLoss2d)来训练验证模型 [32] ,

(a) 原图
该函数可以根据数据标签来计算预测值与标签值的差异,从而在模型反向传播时优化模型中的参数 [33] ,使模型能更好地适应图像分割任务,提高图像分割性能。实验设置网络训练和验证迭代次数为50次,损失函数值越小,说明模型拟合程度越高,分割效果越好。训练和验证过程的损失函数值变化情况如图13所示,网络模型在迭代学习次数达到37次左右,损失函数值变化趋势逐渐变得平稳,由此可见,在训练过程中,模型的性能是逐渐得到优化的,训练和验证过程的损失函数值分别下降到0.07和0.075,均达到最小值,表明此时网络分割效果最优。

Figure 13. Loss function value variation during the training and validation process
图13. 训练和验证过程中损失函数值变化图
验证过程中准确度与F1值变化如图14所示,从变化趋势可以看出随着迭代次数的增加,准确度与F1值都随之增加,并且在损失函数值下降到最小值时准确度与F1的值都达到最高,分别为0.9699和0.8472。
为了更直观的体现出本文算法的分割性能,给出了PR和ROC曲线如图15所示,从图中可以看出,在DRIVE数据集上的PR曲线下方面积大小为0.8890,说明模型有较高的召回率和精确度,能够精确的分割出血管部分;ROC曲线下方面积大小为0.9690,假正值较低,真正值较高,表示模型在血管分割任务中的整体性能较好,能够准确地识别血管部分。此外,PR和ROC曲线的变化表明,Dil-UNet++可以正确地区分视网膜血管和背景,具有较低的误分割风险。
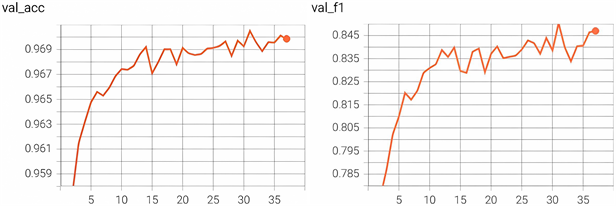
Figure 14. Image of verification process accuracy and F1 value variation
图14. 验证过程准确度与F1值变化图
为了进一步验证本文模型对眼底视网膜血管分割的有效性,将本文提出的模型与一些目前常用效果较好的分割模型进行比较,在同样条件下对DRIVE数据集进行分割处理,在五个常用指标上进行性能对比。实验结果显示,Dil-UNet++网络模型的Dice系数、MIoU、准确度、精确度、F1值分别为87.65%、85.52%、96.99%、92.82%、84.72%,其中UNet++虽然在MIou指标上比本文模型高1.63%,但是其他评价指标与本文方法差别较大,可见本文方法提取血管信息方面更具优势。同时本文提出的方法相较于UNet,UNet++ [34] ,Attention UNet [35] Res UNet [36] 等模型在准确度等评价指标都有不同程度的提升,实验数据表明本文提出的方法能有效精确地对眼底视网膜血管进行提取分割,在保证高准确率的同时也有较高的抗干扰能力和泛化能力。不同模型在DRIVE数据集验证结果比较如表1所示。

Table 1. Comparison of validation results of different models in the DRIVE dataset (%)
表1. 不同模型在DRIVE数据集验证结果比较(%)
4. 结论
针对视网膜血管图像中血管细节复杂、形态多变、血管连接处以及血管末端模糊等问题,本文提出了Dil-UNet++的网络模型,首先使用级联空洞卷积模块代替普通卷积,使模型在特征提取阶段自适应调整感受野的大小,这样可以同时捕捉血管细节和主干特征,实现血管的多尺度信息提取融合;其次在网络跳跃连接的部分设置了卷积注意力模块,从空间与通道两个维度来关注有用的血管特征,抑制不重要特征的影响,使整个网络更有效精确的提取分割血管末端边缘与连接处特征;最后,为了避免血管特征信息在传递过程丢失,在下采样中使用改进的卷积操作代替了传统的池化操作。实验结果表明,改进的Dil-UNet++网络模型相较于传统的UNet、UNet++等网络,在DRIVE视网膜血管图像数据集上有着更好的分割效果,多个评价指标均具有显著的提升,证明了改进后模型的可行性和有效性。
本文改进之后模型具有大量的参数,导致在训练和验证过程中的处理速度较慢。未来的研究可以集中在消除血管图像中的噪声,以及在不影响网络分割准确性的同时简化网络模块结构和优化模型的运行速度。
基金项目
辽宁省教育厅科学研究经费项目(L202004)。