1. 引言
人体动作识别是人体运动分析的基础,广泛应用在视频分析、人机交互、自动驾驶、公共安全等领域,有着重要的研究意义和应用价值 [1] 。随着大量视频数据的增长,尽管数据处理能力有较大提高,对人体动作识别的准确性、实时性也提出了更高的要求。由于人体非刚性的运动和视觉特征变化的多样性,以及现实场景复杂性的影响,对人体动作的智能识别仍然存在许多困难。人体动作既有整体运动,又有局部移动,每个动作都是由关节点联系在一起的时空运动。由于类内动作的差异和空间角度的变化,导致运动特征空间具有复杂多变的形式。三维动作识别正在成为研究的方向,基于深度图像的数据集也在增加,但是二维RGB视频依然是数据的主要来源,在现实应用中更加普遍。在二维视角下人体视觉特征会产生旋转、缩放、形变、遮挡等变化,对看似简单的类内动作识别带来影响 [2] [3] 。在现实场景中,人与环境的交互情况对人体动作识别会产生一定影响。
动作特征是典型的空间特征与时间特征的融合,常用的描述有特征轨迹、容积法、光流场等。Qin等提出基于时空特征点轨迹的动作识别方法,采用KLT跟踪时空局部特征,把跟踪得到的轨迹作为特征向量,利用多核学习方法进行分类识别 [4] 。Mekruksavanich借助可穿戴传感器,提出一种多模态训练方法,实现了对运动相关动作识别 [5] 。Sevilla-Lara提出把光流集成于动作识别之中,提高了动作识别的准确度 [6] 。传统的识别方法提取复杂的特征向量,送给训练好的分类器进行识别。特征提取和动作识别是两个分离的过程,由于动作特征的时空性,增加了提取动作特征的复杂程度。对不同目标的同一动作,甚至同一目标的类内动作,都很难确定特征向量的一致性。训练和测试的数据集一般都是手工分割的特定序列,受特征向量和环境的影响,产生模型泛化能力较弱的问题。
深度学习利用多层神经网络来学习复杂的特征,在图像处理、目标识别中表现出了良好的性能。由于数据量的增加,以及计算能力的提高,基于卷积神经网络的方法在动作识别中的运用越来越多 [7] 。Simonyan等人提出一种空间卷积结合时域光流的双流结构模型,取得较好的性能 [8] 。Cao基于训练图提取CNN特征,结合图像RGB数据和注意力算法,利用LSTM训练分类 [9] 。ZHA S直接对视频进行卷积特征提取,利用SVN进行动作分类 [10] 。深层网络AlexNet、VGG模型通过增大网络的深度来获得更好的训练效果 [11] [12] 。GoogLeNet通过引入Inception加宽网络结构,使网络结构稀疏连接,降低了层数增加带来的负作用 [13] 。Huang提出复杂的DsenseNet,将所有网络层两两进行连接,每一层都接受它前面所有层的特征作为输入,使网络模型大量密集的连接 [14] 。Wei提出改进的GooLeNet,对softmax进行缩小和细化,并增加分类输出层,具有较好的泛化能力 [15] 。随着卷积网络深度和宽度的不断增加,目标特征经过层层处理其分布会逐渐产生差异,容易引起梯度消失、过拟合、训练缓慢等问题。特别是在动作识别任务中,受人体非刚性体运动和视角变化的影响更为突出。
为了降低模型复杂程度,提高训练准确率,并以常见的二维视频为处理对象,本文提出了一种基于循环神经网络人体动作在线识别方法,以人体关节点为主要特征进行逐帧处理,利用多层循环神经网络模型进行序列的动作特征识别。在模型中引入注意力机制,对帧间动作特征进行加权处理,增加与识别动作相关特征的权值比重,提高动作识别的准确率,降低过拟合风险。
2. 模型
直接对图像或序列提取运动特征,需要较深的网络层次和大量单元。动作是一种时间序列信号,可以看成特定姿态的集合。在人对动作的理解中,姿态是密切相关。有的动作可用固定的姿态表征,有的动作需要多个姿态严格按时序关系表征。姿态在人体动作识别中起到了关键作用,而且不会产生大量的数据计算。本文的模型以人体关节点作为识别动作的姿态特征,以时间序列的形式送入循环神经网络(Recurrent Neural Network, RNN)进行模型参数学习。
通过对视频均匀采样得到帧画面,采用卷积网络CNN模块初步处理,然后提取姿态信息,把所需的关节点及表观特征送入多层循环神经网络,进行动作识别训练。人体姿态利用关节点信息,在加上肢体表观的特征组成,包括方向、梯度等信息。在多层循环神经网络中引入注意力机制,学习序列中人体动作的帧间运动特征,最后通过Softmax输出识别的动作类型。模型框架见图1所示。
3. 模型
通过CNN模块提取图像特征后,送入Pose模块进行提取姿态信息,简化人体关节模型,进行姿态估计。关节点和人体主要部件表观特征作为进入循环神经网络模块的数据。
3.1. CNN模块
从帧图像中提取动作的空间特征,使用轻量化的卷积网络,采用深度可分离卷积方法,可以减少网络参数的数量,降低训练的计算量。输入网络的维度是224 × 224 × 3,共有12层。第1层是标准的卷积层,有24个卷积核,步长是2。从第2层开始,进行深度可分离卷积,最后一层的输出维度是28 × 28 × 384。见表1所示,Conv dp表示深度可分离卷积,包含3 × 3的深度卷积和1 × 1的逐点卷积。
L1层将输入数据按特征维度24分组,每一组进行3 × 3卷积,获得空间特征。在此基础上做2个1 × 1的逐点卷积,获得每个点的在各个卷积核下的特征。L2层输出为维度是112 × 112 × 48,得到48个相同分辨率的特征向量组。L3层经过2 × 2池化后,再加上L7层和L11层组成CNN网络的输出特征向量。其它各层处理方法相同。此网络的计算量与相同容量的标准卷积网络比较,大约可以降低的80%,虽然牺牲了一定的精度,但适合视频序列中运动特征的提取。
3.2. 姿态提取
CNN模块提取特征后,通过Pose模块进行训练,每个阶段均计算关节响应和损失函数。本文采用双路网络分别检测人体关节特征和肢体表观特征,如方向、梯度。计算过程见图2所示,S分支计算人体关节点的特征值,用于学习对应的置信度;L分支计算人体部件向量,即关节点之间的关联度。循环6个阶段,每个阶段都深度可分离卷积代替标准卷积,而且2~6阶段的卷积尺寸是3 × 3,降低计算量。
对人体关节模型进行简化,共有14个节点,重点分析姿态中的关键节点,如头、躯干、四肢等。f1,f2分别是两个分支的损失函数,处理姿态的估计问题。总的代价函数由两个分支在每个阶段的损失之和组成,见公式(1)。
(1)
其中,
(2)
(3)
公式(2)表示关节点的误差,公式(3)表示肢体特征的误差,用W用来对关节点加权,减小错误检测时对损失函数的影响。将所有阶段的损失函数相加,作为总损失函数。
4. 动作识别
提取人体姿态特征,可以组成时间序列向量。建立多层循环神经网络进行学习,在其中嵌入注意力网络层,提升样本训练的准确率,实现在线动作序列的识别。动作识别模块见图3,序列数据首先通过批再归一化(BReN)处理,使样本分布统一,取得了较好收敛特性。多层循环神经网络处理归一化后的时间序列数据,激活函数采用ReLU函数。输出特征进入随机共享权重的注意力层(Attention Layer),在训练过程中可以自动加强特征学习的权重,从而提高训练的效率。
4.1. 循环神经网络
循环神经网络是一类用于处理时间序列数据的神经网络。常规的RNN网络处理较长序列存在梯度消失和长期依赖问题。动作与姿态关系密切,有的动作只用一帧就可以确定,比如走、跑、跳等。但复杂的动作序列持续较长,要通过上下文的联系才能识别。长短期记忆神经网络(Long Short-Term Memory, LSTM)是一种特殊的RNN,通过加入门控制单元记忆长期信息,解决长序列在训练过程中梯度衰减过快的问题。
使用三层LSTM网络结构叠加,根据序列相邻间隔帧的姿态特征学习识别动作。由于训练时的样本一般是分割好的,现实场景的序列不一定是分割好的视频,多层结构利用上下文可以实现在线识别。LSTM网络层结构见表2,每一层均进行批再归一化操作BReN和Dropout。用BReN进行样本的归一化处理,Dropout随机舍弃部分神经元的权重,实现正则化处理作用。
4.2. 注意力机制
在多层LSTM网络输出后加入注意力层,对重要特征进行加权,提高训练效率和准确率,降低复杂网络结构带来的过拟合风险。注意力机制在训练过程中,先计算特征的权值,然后根据样本输出加权求和,不断加大响应较大的特征权值,相应特征对识别的贡献也就增大。
复杂的网络结构和时序深度的增加,容易导致过拟合问题。注意力机制的产生可以有效缓解这个矛盾。在LSTM网络层之后加入注意力层,而不是直接对关节点特征引入注意力,目的是强化时间序列处理后的特征在动作识别中的作用。经过LSTM网络层得到的特征,经过注意力层的学习受到识别动作更多关注。
注意层的输出:
(4)
其中,yt-1表示上一时刻的注意力输出,ht表示循环神经网络的隐状态,ct表示特征加权,fatt表示注意力层函数。
在特征加权过程中,直接共享注意力权重可进一步降低大量参数的计算,但对于特征的表达能力减弱。本文给出一种随机共享权重的方法对特征加权:
(5)
其中,at,i表示注意力的权值。随机按一定概率给每个维度共享权重。公式(6)中r服从伯努利分布,at,i以概率p共享各维度权值的平均值,见公式(7)。
(6)
(7)
注意力层函数fatt的功能实现见图4所示。Scale进行数据维度调整,Connect是全连接神经单元,Mean进行均值计算,Reduction是在随机概率p下进行权值均值共享,最后对特征进行加权处理。权值随机共享的方法提升了显著性特征的权重,有利用于训练效率的提高,降低过拟合的出现。
5. 实验
本文进行了模型的训练和测试。从UCF视频动作库中选择部分典型场景的动作视频作为样本,进行32类动作的识别。识别的实例见图5所示,图中有人体动作的关节点,以及对动作类型的分类标签。图5给出的3个识别动作,分别是Bowling,GolfSwing,TennisSwing。每一行选取了4帧画面,可以准确检测到人体动作的关节点,正确识别了动作类型。
样本是4000个时间长短不同的视频,均匀采样60帧,分别组成训练集和测试集,进行模型的训练和交叉验证。样本训练和测试的准确率曲线,以及损失函数曲线见图6。训练集的准确率最高可达0.98,损失函数的下降有少量起伏,测试集的准确率也能同步上升到0.97。本文提出的模型具有较好的泛化能力,减少了过拟合的现象。
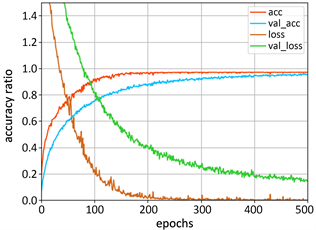
Figure 6. Accuracy and loss curves of training and validation
图6. 样本训练与测试曲线
注意力机制嵌入在循环神经网络中,起到了显著的作用,图7给出了模型在有注意力层和无注意力层时训练集的准确率变化曲线对比。当没有注意力层时,准确率上升缓慢。加入注意力层后,准确率上升较快,提高了模型训练效率和准确率。经过循环神经网络后的特征值与动作识别密切相关,图8给出了128维特征向量在注意力层的权值比重分布,权值比重提升了对动作序列的表达能力。
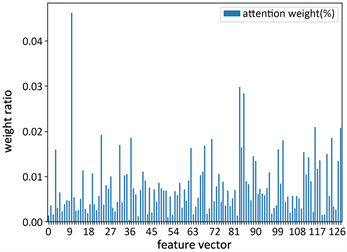
Figure 8. Weight ratio of attention layer
图8. 注意力层权值比重
6. 结论
本文提出一种基于循环神经网络的人体动作在线识别方法,通过逐帧提取关节点特征,用循环神经网络处理时间序列数据,提出随机共享权重的注意力机制,实现了人体动作的在线识别。动作识别在实际中是困难的,不仅由于动作的复杂度不同,人体关节的非刚性等因素,还受到人与环境的交互影响,以及视频分辨率和采样率的差异。动作识别可以借助对环境的理解,人与其他事物的交互关系在动作识别中起到更直接的作用。由于每个视频的长短不同,采样的帧数会影响动作特征描述的信息量差异。从关键帧的姿态入手,结合辅助帧可以更有效的描述动作。在循环神经网络层后加入自定义的注意力层,通过训练自动对提取出的特征进行加权处理。提取特征的含义还不明确,但能在更高维度上对动作序列表征。今后,可以考虑加入对环境信息的学习与识别,把动作识别与背景建模、人与环境的交互结合起来,利用场景理解更好的实现动作在线识别。