1. 网络结构
由于Transformer将整张图片作为序列作为网络输入时,会在所有阶段内只专注于全局上下文信息的建模,因此会导致缺乏详细的低分辨率特征。若直接上采样到原分辨率会无法有效地恢复该信息,从而
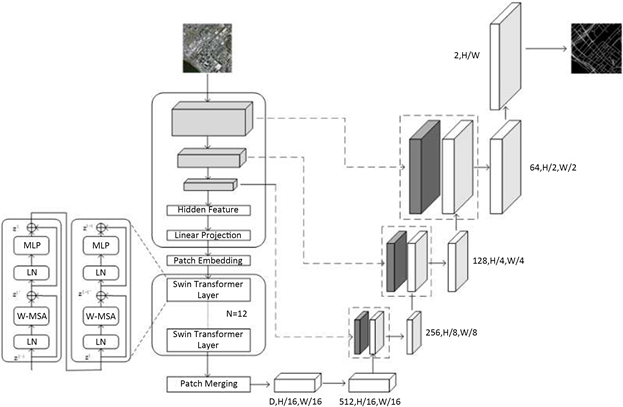
Figure 1. The structure schematic diagram of STransUNet
图1. STransUNet的结构示意图
导致分割结果不够精确。因此,本文采用一种融合CNN-SwinTransformer的网络结构STransUNet,该网络基于经典的U型编码–解码结构实现,如图1所示。
在编码器阶段,不同于常规的对称编码–解码结构,STransUNet在编码部分中首先将图像输入到3个CNN卷积块当中,每个卷积块由2个卷积层、BN层、ReLU激活函数和最大池化层组成,并在首个卷积块将常规卷积层替换为蛇形动态卷积模块 [1] ,目的是为了更加有效地提取有管状特征的道路。
输入图像经过CNN部分后会输出一张特征图,在经过Patch Embedding层后将特征图序列化并且加上位置编码,输入到堆叠的Swin-Transformer块进行深层编码,本文中在这一层中设置了数量为12的Swin-Transformer块。
在解码器阶段,首先将对特征图输出进行Patch Merging,再经过卷积核大小为1的卷积层进行降维得到深层特征图。之后进行级联上采样,同时与编码器的CNN部分进行跳跃连接,将经过上采样之后的特征图与编码器部分对应大小的特征图进行拼接操作,最后逐层恢复到原图的输入大小,输出最终预测结果。
1.1. 蛇形动态卷积模块
对于道路这种管状类结构的特征精确提取目前仍然具有挑战性:
细长且脆弱的局部结构。如图2所示,细长的结构仅占整个图像的一小部分,像素的组成有限。此外,这些结构容易受到复杂背景的干扰,因此模型很难精确分辨目标的细微变化,从而导致分割出现破碎与断裂。
复杂且多变的全局形态。图2显示了细长管状结构复杂多变的形态,即使在同一张图像中也是如此。位于不同区域的目标的形态变化取决于分支的数量、分叉的位置,路径长度以及其在图像中的位置。因此当数据表现出未曾见过的形态特征时,模型倾向于过拟合到已见过的特征,无法识别未见过的特征形态,从而导致泛化性较弱。
为了获得更好的性能,在计算机视觉领域里已经提出了各种方法,根据管状结构的形态设计特定的网络体系结构和模块。(以著名的膨胀卷积 [2] 和可变形卷积 [3] 为代表,提出了基于卷积核设计的方法来处理CNN中固有的有限几何变换,在复杂的检测和分割任务中表现出了优异的性能。这些方法 [4] [5] [6] [7] 也被设计成动态地感知对象的几何特征,以适应具有可改变形态的结构。例如,文献 [6] 中提出的Dunet算法将可变形卷积算法集成到U形结构中,并根据血管的大小和形状自适应地调整接收野。因此提出了基于网络结构设计的方法来学习管状结构的特殊几何拓扑特征。PointScatter [8] 提出了用点集来表示管状结构,替代了管状结构提取任务中的分段模型。文献 [9] 提出了一种树形结构的卷积门控复发单元来显式模拟冠状动脉的拓扑结构。与上述允许模型完全自由学习几何变化的思想不同,考虑到过度随机性带来的收敛困难的局限性以及模型可能会聚焦于目标的意外区域。蛇形动态卷积模块结合了管状结构形态的领域知识,在特征提取过程中稳定地提高了管状结构的百分率。
首先本文的目标是在遥感影像中提取竖直的管状道路,蛇形动态卷积模块从可变形卷积的概念中获得灵感,使模型能够在学习特征的同时动态适应其卷积核的形状。这种方法使模型能够集中于管状地层的基本结构属性。然而,在最初的实验中,由于管状结构的比例相对较小,模型往往会失去对这些特定结构的感知。因此,卷积核显著偏离其预期焦点。为了解决这个问题,蛇形动态卷积模块提出了一种专门针对管状结构特点的网络结构的设计。这种专门的结构作为一个指导框架,确保该模型有效地确定关键功能的优先顺序。
蛇形动态卷积的目标是允许卷积核自由地适应结构以进行有效的特征学习,同时确保它在定义的约束内不会偏离目标结构太远。这一观察使蛇形动态卷积将其与动物的特征进行了类比:蛇。其设想了卷积核像蛇一样动态地扭曲和扭曲以符合目标结构,从而能够更精确地提取特征。

Figure 3. Snake dynamic convolution diagram
图3. 蛇形动态卷积示意图
结果完全自由的成型有时会导致精细结构细节的丢失,这在分割微妙的管状结构的背景下构成了一个巨大的挑战。如图3所示,动态蛇形卷积从蛇的运动中获得灵感,蛇的头部一节接一节地引导身体不断前进,创造了波浪式的运动。
为了解决这个问题,蛇形动态卷积在卷积核的设计中引入了连续性约束。在每个卷积位置,前一位置用作自由选择卷积的移动方向的参考点。这种方法既保证了自适应结构的自由度,又保证了特征感知的连续性。
为了使卷积核更灵活地聚焦于目标的复杂几何特征,动态蛇形卷积引入了变形偏移∆。然而,如果让模型自由学习变形偏移量,感知场往往会偏离目标,特别是在薄管结构的情况下。因此,动态蛇形卷积使用了ITER-ative策略,为每个要处理的目标依次选择要观察的以下位置,从而确保注意力的连续性,并且不会因为大的变形偏移量而将感觉领域扩展得太远。
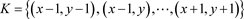 (1-1)
(1-1)
在DSConv中,其将标准卷积算子在x轴和y轴方向上都拉直。DSConv考虑大小为9的卷积核,并以x轴方向为例,每个网格在K中的具体位置表示为:
,其中
表示到中心网格的水平距离。卷积核K中每个网格位置
的选择是一个累加过程。从中心位置Ki开始,远离中心网格的位置取决于前一网格的位置:与Ki相比,用偏移量
来增加
。因此,偏移量需要为Σ,从而确保卷积核符合线性形态结构。公式1-1在x轴方向变为:
(1-2)
并且y轴方向上的公式1-2变成:
(1-3)
其中K表示公式1-2和公式1-3的分数位置,K'枚举所有整数空间位置,B是双线性内插核,它被分成两个一维核,如下公式1-4所示:
(1-4)
如图3所示,由于二维(x轴、y轴)的变化DSConv在变形过程中覆盖了9 × 9的范围。DSConv的设计是为了更好地适应细长筒体结构的动态结构,从而更好地感知关键特征。

Figure 4. The working principle of snake dynamic convolution
图4. 蛇形动态卷积的工作原理
1.2. Swin Transformer模块
传统的Transformer模型在自然语言处理领域表现出色,但在计算机视觉任务中,特别是在处理高分辨率图像时,存在着一些挑战。原始Transformer架构不适合处理大规模图像,因为它需要在全局上计算自注意力,这导致了高昂的计算成本和内存需求。Swin-Transformer [10] 的提出正是为了应对这一问题,使得Transformer可以更好地处理大尺寸图像数据。Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
在Swin Transformer中使用了Windows Multi-Head Self-Attention (W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域0,并且Multi-Head Self-Attention只在每个窗口内进行。相对于Vision Transformer中直接对整个特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者提出了Shifted Windows Multi-Head Self-Attention (SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。
通过图5可以看出整个框架的基本流程如下:
首先将图片输入到Patch Partition模块中进行分块,即每4 × 4相邻的像素为一个Patch,然后在channel方向展平。假设输入的是RGB三通道图片,那么每个patch就有4 × 4 = 16个像素,然后每个像素有R、
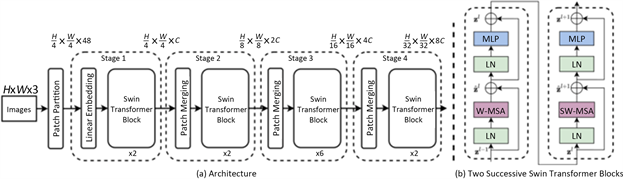
Figure 5. Swin transformer structure diagram
图5. Swin Transformer结构示意图
G、B三个值所以展平后是16 × 3 = 48,所以通过Patch Partition后图像shape由[H, W, 3]变成了[H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由[H/4, W/4, 48]变成了[H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中的Embedding层结构一模一样。
然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样。然后都是重复堆叠Swin Transformer Block注意这里的Block其实有两种结构,如图6中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。
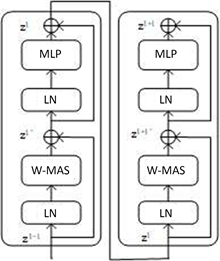
Figure 6. Paired Swin Transformer modules
图6. 成对的Swin Transformer模块
2. 实验设置
实验的硬件配置为NVIDIA GeForceGTX3060 (12GB)GPU、操作系统是win10,并使用Pytorch作为本文的深度学习框架。在训练网络时,为合理利用计算资源,将batchsize设置为16,学习率设置为1e-4,并在每20轮训练轮次结束后将其调整为原学习率的20%。此外,训练时采用Adam算法对模型进行优化。
在本文中,使用的数据集为美国马萨诸塞州地区的遥感影像数据集和高分二号遥感影像数据集作为实验数据,图像尺寸为1500 × 1500,由于该数据集中包含背景内容丰富,包括乡村、城市和山地等不同的地理环境,且面积大、范围广,能够满足实验需求。首先1500 × 1500像素的数据集裁剪成模型输入需要的256 × 256 × 3大小的数据集,并按照6:2:2的比例分割成训练集、测试集和验证集,所有数据集内的图像大小均为256 × 256 × 3。接下来我们对准备完毕的道路数据集进行预处理,其目的是为了通过对数据集进行翻转、裁剪等操作,可以生成额外的训练样本,从而增加训练数据的多样性。这有助于提高模型的泛化能力,使其更好地适应不同场景和变化。
3. 道路提取结果分析
3.1. 消融实验
本文为了展示出U型结构下融合蛇形动态卷积和Swin Transformer模块带来的道路提取任务精度提升,在Massachusetts道路数据集上进行了消融实验。首先使用未使用Swin Transformer与蛇形动态卷积模块的网络结构,使用纯ViT模块的U型网络结构作为基准,设计添加Swin Transformer与蛇形动态卷积模块的网络模型,并且在此基础上使用12个Swin Transformer模块作为对比实验,测试并且对比这几组模型之间的道路提取性能。本文所使用的模型使用了12个Swin Transformer模块。
选取其中一张道路提取结果进行评估分析,道路提取结果如图7所示,提取精度如表1所示。
在图7中可以看出,未进行改进的纯ViT模型的提取结果c有诸多误提取结果,且道路提取结果不连贯,也受到遮挡物的干扰,导致其精度不高。图7d中是将模型前两层替换成DSConv进行提取的结果,可以看出误提取的道路像素减少,并增加了其结果的连贯性。图7e为在Baseline的基础上将ViT模块替换成了Swin Transformer模块,道路提取精度明显提高,且断裂减少,也明显规避了许多误提取的道路像素。图7g为本文使用的模型,在添加了DSConv模块与12个Swin Transformer模块后,道路提取精度为四个模型中最高,道路连续性有很大提升,且受到干扰减少,误提取的道路像素在图7e的基础上也有所下降。

Table 1. Various compared results in the Massachusetts Road dataset Figure 7
表1. 在Massachusetts数据集图7下多模型对比实验
表1为消融实验在图7a数据集上的评估结果,可以看到未添加DSConv与Swin Transformer模块的Baseline模型OA最低,为94.85%,IoU也在四个模型中最低,为95.03%。在添加了DSConv模块后,OA有所提升,提升了0.31个百分点,达到了95.16%,IoU也提升了0.51个百分点,达到了95.03%,可以得出添加了DSConv模块的网络模型在道路提取任务中是有效的,但是与替换ViT为Swin Transformer的模块相比,提升有限。替换Swin Transformer模块的网络模型的OA相较于原模型,提升了1.94个百分点,IoU相较于原模型,提升了2.14个百分点,精度提升显著,其原因可能是由于ViT模型在对遥感影像进行推演处理时的效果相较于Swin Transformer缺少了滑动窗口的处理,在推演过程中对遥感影像的全局特征提取未有Swin Transformer有效。在表1的最后一行为本文提出的STransUNet模型,OA达到了最高的97.07%,IoU也为最高值,达到了96.97%,相较于只替换Swin Transformer的Baseline提升为0.3个百分点左右,说明DSConv模块在道路提取任务中也起到了一个正面的作用,帮助模型进行更好的管状特征提取。
3.2. Massachusetts道路数据集
图8为各个模型在Massachusetts道路测试集上的对比实验,表可以看到图8c和图8d中CNN架构的网络模型在对于尺度较大的道路提取上有断裂的问题存在,同时对于细微的道路像素也有着不错的提取精度。图8e为纯Transformer架构的Swin-UNet提取结果,由于其对于全局特征的提取优势,在对于大视野下的道路提取结果有着非常高的提取精度。图8f为本文的Baseline模型,图8g为本文提出的网络模型STransUNet,可以看到图8g在图8f的基础上,提取精度大大提高,同时路网的断裂、误提取像素也大大减少,可以说明该模型在Massachusetts道路数据集上有着不错的性能,同时在Baseline的性能基础上有进一步的提高。




(a) 原图 (b) 标签图 (c) UNet(d) Deeplabv3+



(e) Swin-UNet (f) TransUNet(g) StransUNet
Table 2. Quantitative evaluation results in Figure 8
表2. 图8的精度评价指标
表2为图8中五种方法在Massachusetts道路数据集上的精度评估,其中本文提出的STransUNet在两张图片中都取得了较好的表现。其中两张图片的平均OA达到了97.06%,为五种模型中的最高值,平均IoU也有较好的表现,而且与Baseline模型TransUNet的性能进行对比,道路提取的精度都有明显提高。相较于传统的CNN网络UNet和DeepLabv3+两个模型,OA平均提升了1个百分比以上,IoU也平均提升了1.5个百分比以上。
Table 3. Various compared results in the Massachusetts Road test dataset
表3. 在Massachusetts数据集下多模型的对比实验
表3为各个模型在Massachusetts道路验证集上的对比实验,CNN架构的U-Net与DeepLabv3+模型在道路提取任务上的平均OA在90.25%左右,平均IoU在61.2%左右,为对比实验里所有模型的最低值。
作为Baseline的TransUNet在Massachusetts数据集下的OA与IoU与传统CNN架构的网络相比,略微存在一些优势。本文提出的STransUNet在TransUNet的基础上OA提高了1.6个百分点,IoU提高了1个百分点,与Swin-UNet网络的性能相差无几,IoU相较于Swin-UNet略微高出0.3个百分点。
3.3. GF-2道路数据集
高分二号数据集中的路段多为城市、乡镇路段,道路特征相对明显,但由于城市与乡镇中车辆、建筑物数量多,导致阴影遮挡的区域相对于Massachusetts数据集更大,因此对于道路提取结果连通性的测试有较的高研究意义。




(a) 原图 (b) 标签图 (c) UNet (d) Deeplabv3+



(e) Swin-UNet (f) TransUNet (g) StransUNet
从图9中可以看到,CNN架构下的预测图像c和d表现出较多的道路误提取,而Transformer架构下的e、f和g预测结果,并未有过多的误提取表现,且道路主干提取结果较为完整,但是g作为Baseline的TransUNet偶尔有道路断裂的表现,对于这种现象的出现,是由于建筑物导致的阴影过多。g预测图像对于f中出现的断裂现象有很大改进,道路连通性也较为良好。
Table 4. Various compared results in the GF-2 Road test dataset
表4. 在GF-2数据集下多模型的对比实验
表4显示了在GF-2验证集下五种网络模型的性能对比,可以看到STransUNet在六种模型中的IoU为最优值,达到了72.84%,相较于传统的CNN架构网络U-Net与DeepLabv3+平均提高了15个百分点,OA与Swin-UNet相差无几,分别达到了93.87%与93.79%。相比于经典的卷积神经网络U-Net和DeepLabv3+有明显的提升,同时与同是Transformer架构的TransUNet相比,也有性能上的提升,OA和IoU平均提升了1.7%和5%,F1为五个模型中的最高值68.76%。
Table 5. Quantitative evaluation results in Figure 9
表5. 图9的精度评价指标
表5中的数据为五个模型在图9中GF-2数据集中两个提取结果的精度评价指标,其中STransUNet的性能与Swin-UNet相当,OA与IoU分别在两张图中达到了最高值,平均OA分别为97.67%与97.51%,平均IoU分别为97.36%与97.28%,道路完整性与道路连通性均为五个提取结果中的最优,且道路误提取像素少。相比于TransUNet模型,STransUNet在两张提取结果中的平均OA提升了1.1个百分点,平均IoU提升了1个百分点,道路连通性有明显提高。且在表5与图9可以明显看出,融合了Transformer架构的网络模型在道路提取任务中有较大优势。
4. 结论
本文提出了一种融合Transformer和CNN的U型神经网络遥感影像道路提取算法,其中主要提出了一种融合了蛇形动态卷积和Swin Transformer作为网络的编码器端,采用上采样与跳跃连接的方式来对特征提取结果进行还原的网络结构。通过消融实验和多个模型在Massachusetts道路数据集和高分二号数据集上的对比实验证明,蛇形动态卷积在对道路这类管状结构的提取起到积极的作用,以及Swin Transformer在对大尺度的长距上下文关系的提取相对于ViT模块更加有效,同时也能够得出STransUNet在对山地、农村等道路进行提取时有较好的性能表现,提取精度明显优于传统的CNN网络和纯Transformer网络。