1. 引言
由于建筑工地存在施工环境复杂、人员流动大和不同机械同时作业等特点,工人们在作业中经常面临潜在的安全风险,如果没有采取有效的安全防护措施,甚至会导致各种安全事故的发生,造成人员伤亡和财产损失。
传统的施工现场安全管理方式,是通过人工巡检或视频监控来发现潜在的安全问题,并及时管控。这种方式虽然可以发现部分问题,但效率较低且准确性不高,尤其对于大型施工现场,视频监控难以覆盖所有区域,容易出现视线盲区,从而形成安全隐患。
随着卷积神经网络(CNN, Convolutional Neural Network)在深度学习领域的快速发展,许多研究人员提出了基于深度学习的目标检测方法,利用摄像头和目标检测算法实现对施工现场的实时监控与智能预警。2020年,赵永强等 [1] 从改进和结合的角度对单阶段、两阶段目标检测算法进行了综述,并详细介绍了通用数据集。2023年,朱豪等 [2] 针对单阶段目标检测的结构原理和优缺点进行综述,认为此方法对小目标检测准确度可能有所下降,需要不断改进。杨锋等 [3] 从改进目标检测算法应用研究方面进行了综述,并从注意力机制、轻量型网络和多尺度检测等方面对目标检测算法的最新改进思路进行总结梳理。Li等 [4] 提出了一种涉及多种风险因素强度的工人风险水平评估方法,并开发了实时跟踪系统,以客观记录安全帽的使用情况。
依据住房和城乡建设部办公厅目前公开发布的“关于2020年房屋市政工程生产安全事故情况的通报”,2020年全年共发生安全事故689起,其中高空坠落共发生400多起,占到总数的一半以上,物体打击事故83起 [5] 。在高空坠落和物体打击等类似建筑施工安全事故中,正确佩戴安全帽可以大幅度降低事故伤害。近年来,随着对工地安全的重视程度越来越高,针对安全帽佩戴检测方法的研究已经有了长足的进步,本综述就基于深度学习的安全帽佩戴检测算法研究进展,从以下四部分进行阐述:(1) 数据集与评价指标,分析总结了近年来研究人员常用的目标检测数据集和评价指标;(2) 两阶段目标检测算法,主要针对改进Faster R-CNN安全帽佩戴检测进行算法与局限性分析;(3) 单阶段目标检测算法,分析改进的YOLO和SSD系列算法的优势和局限性;(4) 对全文归纳总结,提出当前存在的问题及未来展望。
2. 数据集与评价指标
2.1. 数据集
在训练深度学习网络时,目标检测算法的数据集,要求拥有足够的数据量和丰富的数据类别。数据集的不同表现在图像数量、采集设备的选择和视角等方面,研究人员根据算法的要求选择合适的数据集进行实验,一般会使用公开的图像数据作为参考,以此客观地评判算法的精度。
目前深受研究人员欢迎的数据集主要有PASCALVOC [6] 、MS-COCO [7] 和Image Net [8] ,这些数据集的出现使目标检测领域得到了快速地发展,然而当前在安全帽佩戴检测领域还缺乏优秀的公共数据集,大多研究人员都是根据实际场景采集图像数据,再标注构建数据,比如建筑施工现场、油气作业领域等严格佩戴安全帽的场景,大多都是通过收集网上数据、提取作业现场监控视频和现场拍摄等途径获取数据集。
如表1所示,在目前的目标检测领域中,现有的数据集大都是简单场景范围,缺乏复杂场景中的小目标检测数据集,并且在安全帽检测方面也仍缺乏公共数据集,仅仅依靠研究人员采集实际场景的图像再进行标注。主要原因是小目标数据不易标注、标全难度大,且对于标注误差更为敏感,现有大规模的通用小目标数据集处于缺乏状态,因此后续研究人员可以把重点放在收集、标注小目标图像数据集上。

Table 1. Commonly used target detection datasets
表1. 常用的目标检测数据集
2.2. 评价指标
除了数据集之外,评价指标也同样重要,目标检测算法的性能常用检测速度、交并比、准确率、召回率、平均精确率和平均精确率均值等评价指标进行分析以此比较不同的算法模型。
1) 检测速度(Frames per second, FPS):表示每秒可以处理的图片数量,用于评估模型检测的速度,FPS越高实时性越好。
2) 交并比(Intersection over Union, IOU):预测边框与实际边框的交集和并集的比值。
(1)
式中Ax是预测边框,By是实际边框,IOU处于0~1之间。
3) 精确率(Precision, P):表示正样本数据被分类器准确判别为正样本的概率。
(2)
式中TP是预测正确的正样本数量,FP是负样本预测成正样本的数量。
4) 召回率(Recall, R):表示分类器把所有正样本数据都找出来的能力。
(3)
式中FN是正样本预测成负样本的数量。
5) 平均精确率(Average precision, AP):不同召回下的平均检测精度,通常以特定类别的方式进行评估。表示的是PR曲线所围成的面积,而PR曲线是以检测模型的召回率为横坐标轴,准确率为纵坐标轴所形成的。
(4)
式中t是在不同IOU下的曲线召回率,假设当t = 0.7时,只有IOU ≥ 0.7才会被认为是正样本。
6) 平均准确率均值(mean Average Precision, mAP):表示多个类别的平均AP值,是衡量分类器对所有类别的检测效果。
(5)
式中N为种类的数量。
3. 两阶段目标检测
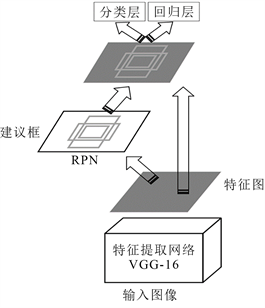
Figure 1. Faster R-CNN algorithm network structure diagram
图1. Faster R-CNN算法网络结构图
目标检测算法的目的是将场景中需要识别的目标进行定位、分类和标记,在对目标进行识别的过程中,最重要的两个过程是识别和分类 [12] 。两阶段目标检测(Two-Stage)也称为基于分类的目标检测算法,需要先预设一个区域,即一个可能包含待检测物体的预选框,再通过卷积神经网络进行样本分类计算。首先特征提取,其次区域生成(RP,Region Proposal),最后再分类/定位回归。常见的算法有R-CNN系列,如Fast R-CNN [13] 、Faster R-CNN [14] 以及R-FCN [15] 等。
3.1. R-CNN
R-CNN作为一种基于区域的CNN探测器,它的主要特点是可以将物体识别任务转化为基于区域的分类问题,通过在输入图像中获取和计算物体的类别,并使用目标检测算法来确定物体的位置 [16] 。该方法包括四个部分:第一个模块产生候选区域;第二个模块则是对每个候选区域使用深度网络提取特征;第三个模块将特征送入每一类的SVM分类器,判断是否属于该类,再使用边界框回归器,以准确地预测边界框。通过候选区域的选择,利用卷积神经网络从各区域抽取出4096个特征矢量,考虑到各区域提取所需的输入矢量是固定的,则要求各区域提取特征尺寸一致。若CNN的输入尺寸固定为227 × 227像素,那么从一帧到另一帧物体的尺寸或长宽比,将被改变为第一个模块中建议的提取区域的尺寸,而候选区域周围边界框中的所有像素,无论区域尺寸或长宽比如何,都将变形为所需的227 × 227像素 [17] [18] 。
3.2. 改进Faster R-CNN的安全帽佩戴检测算法
Faster R-CNN算法的网络结构主要由三部分组成:特征提取网络、RPN网络和分类回归网络,如图1所示。Simonyan等 [19] 提出使用特征提取网络VGG-16提取图像对应的特征图,利用一种具有极小(3 × 3)卷积滤波器的架构,对深度不断增加的网络进行了全面评估。目前基于两阶段目标检测算法改进最多的是Faster R-CNN算法,具体可以分为四个方面:特征融合模块、ROI池化模块(Pooling, ROI)、区域提取网络(Region Proposal Network, RPN)和非极大值抑制模块(Non-Maximum Suppression, NMS),本节针对安全帽佩戴检测算法的模块改进进行综述研究,见表2。
Table 2. Improved Faster R-CNN algorithm
表2. 改进Faster R-CNN算法
4. 单阶段目标检测
单阶段目标检测(One-Stage)也称为基于回归的目标检测算法,不需要得到建议框,直接产生物体的类别概率和位置坐标值,通过单次检测即可直接得到最终的检测结果 [25] ,典型的算法为YOLO (You Only Look Once)系列算法和SSD (Single Shot Multi Box Detector)算法,其任务流程是先特征提取,再进行分类/定位回归。
4.1. YOLO系列算法
YOLO [26] 是在Faster R-CNN之后提出的单阶段目标检测,主要通过摄像头和全图像进行实时检测。YOLO检测是一个回归问题,将统一的架构直接从输入图像中提取特征,因此它可以预测边界框和类别概率。
YOLOv1算法是通过将图像划分为网格图来实现目标检测,每一个网格预测物体的边界框及概率,当目标物体的中心点在网格内时,该网格就可以预测物体的位置和类别 [27] 。虽然YOLOv1的检测速度很快,但是精度较低。
Redmon等 [28] 引入YOLOv2算法,其网络结构参照SSD和YOLO算法。它将VGG-16替换为了DarkNet19作为特征提取网络,并采用了多目标分类和检测的训练技巧,从而将可检测的物体种类扩充到了数千种。方明等 [29] 在安全帽佩戴检测研究中以YOLOv2目标检测方法为基础,对网络结构进行了改进,利用MobileNet中的轻量化网络结构对网络进行压缩,使模型的大小缩减为原来的十分之一,增加了模型的可用性。
YOLOv3 [30] 由于速度快、精确度高成为了当前工业检测领域常用的算法。它将特征提取网络替换成了DarkNet53,激活函数使用了Logistic取代了Softmax,并且采用了三条分支检测不同尺度的对象。
由于上述改进,虽然YOLOv3算法的检测精度与Faster R-CNN算法基本持平,但检测速度是SSD算法和Faster R-CNN算法的两倍多 [31] 。
YOLOv4 [32] 算法在YOLOv3算法的基础上引入了许多创新技术,如Mosaic增强、cmBN和SAT自我对抗训练、CSPDarknet53网络结构、Mish激活函数和Dropblock等 [33] 。此外,YOLOv4还引入了SPP模块和FPN + PAN结构,并采用CIOU作为边界框预测方法,以进一步提高检测精度和速度。综上,YOLOv4算法比YOLOv3算法,在实际应用中更具优势。
YOLOv5是基于Pytorch框架的轻量级目标检测算法,使用深度学习和卷积神经网络实时检测物体,识别是否有效采取安全防护措施,如安全帽、安全带和防护服 [34] 。YOLOv5算法在各种平台的模型部署方面非常灵活,在当前工业软件、操作系统和机器人设备国产化的背景下有着很大的优势。
4.2. 改进YOLO系列的安全帽佩戴检测算法
安全帽佩戴检测对小目标检测的要求较高,并需要具有时效性,为了追求更快的检测速度和更精准的小目标检测能力,能够更好地应用于安全帽佩戴检测任务中,许多研究人员对YOLO系列算法进行了改进,见表3。
Table 3. Improvement of YOLO series algorithm
表3. 改进YOLO系列算法
4.3. 改进SSD算法
YOLO算法在检测实时性中速度较快,但在检测精度上仍有不足,由此SSD [39] 算法孕育而生。SSD算法引入了Multi-reference和Multi-resolution技术,不同于以前的检测算法只在网络的最深层分支进行检测,SSD算法设置了多个分支,来检测不同尺度的目标 [40] 。通过这些技术的改进,SSD算法的多尺度目标检测效果,特别是小目标检测方面,比YOLOv1的表现更优异。
SSD算法第一阶段将图像特征提取得到特征图,再输入VGG16网络后会分别在第4、7、8、9、10、11个卷积层生成相应的特征图,通过上采样进行拼接,得到多尺度特征图;第二阶段在不同的预测网格中对多尺度特征图进行预测,包括边界框位置的回归参数和分类参数;第三阶段,按照目标的置信度得分进行排序,采用非极大值抑制算法筛选 [41] 。SSD深度学习目标检测算法结构如图2所示。
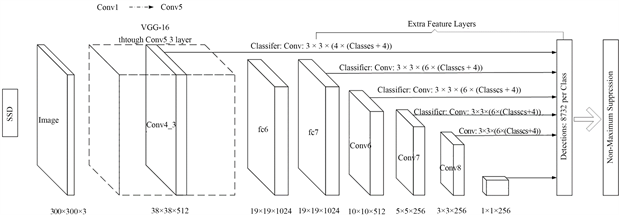
Figure 2. SSD algorithm network structure diagram
图2. SSD算法网络结构图
5. 总结与展望
在深度学习的推动下,目标检测技术已经有了较为成熟的研究成果并运用到实际工程中,并在智慧安防领域取得了很大的进展,其中安全帽佩戴检测的识别速度和精确度都有一定的提升。以下给出几点目前存在的问题及未来具有研究意义的发展方向,供研究人员参考。
5.1. 目前存在的问题
1) 目标检测算法在处理小目标或者目标密集的情况下,定位精度较低,这可能导致目标被错误地定位或者漏检,并且检测速度和精确度之间,难以同时满足最优条件。
2) 目前还存在着泛化问题,目标检测算法在处理目标被遮挡或者存在复杂背景的情况下,处理遮挡和复杂背景的能力有限,容易受到干扰,导致检测结果不准确。
3) 在某些场景中,数据集的目标类别分布不平衡,类别的样本数量较少,对于少数类别的检测效果较差。
4) 深度学习在训练过程中能够学习到复杂的特征,但对于姿态变化和尺度变化的鲁棒性不足,目标检测算法对于目标的姿态变化和尺度变化较为敏感,容易导致检测结果不稳定。
不足之处是目标检测技术发展的挑战,研究人员需要不断改进和优化算法,以提高目标检测的精确度、鲁棒性和速度。
5.2. 展望
1) 为了同时满足检测速度与精确度的安全帽佩戴识别,研究者可以尝试通过强化学习与环境的交互,将深度学习和在线学习融合。目前的安全帽佩戴检测都是通过实例标注数据来训练,未来的目标检测技术可以引入强化学习方法,使算法能够自适应地调整参数和策略,提高安全帽检测的性能。
2) 为了实现更准确的安全帽检测识别,未来的目标检测技术可以结合多种传感器或信息源,如图像、红外和深度等,以提高安全帽检测的准确性和鲁棒性。通过融合多模态信息,可以更好地应对复杂场景、遮挡和光照变化等问题。
3) 对目前数据集的情况而言,研究者可以尝试多样化的数据集,以覆盖各种场景、光照条件和姿态变化等情况,提高模型的泛化能力和鲁棒性,使其在实际应用中更加可靠。
4) 在实际应用中,安全帽检测需要具备实时性和低功耗的特点,未来的目标检测技术需要在保持高准确性的同时,进一步优化算法和硬件,以满足实时应用和低功耗的需求。
基金项目
重庆科技学院硕士研究生创新计划项目(YKJCX2220707)。
参考文献