1. 引言
结核病是由结核杆菌引起的一种慢性传染病。结核杆菌可以侵害人体的各种器官,以肺结核多见,侵入不同部位表现不一。作为全球结核病高负担国家,目前我国结核病防控形势仍不容乐观。“十四五”国民健康规划中要求全面落实结核病防治策略,加强肺结核患者发现和规范化诊疗,实施耐药高危人群筛查,强化基层医疗卫生机构结核病患者健康管理,加大肺结核患者保障力度 [1] 。
由于我国地域辽阔,各省市自然环境、经济水平、人口组成以及医疗水平差异明显,因此我国结核病发病具有时空分布的特点。尹金风等人利用贝叶斯时空模型分析了时空分布因素对于2008~2018年北京市肺结核报告发病率的影响效果,结果表明2008~2018年北京市肺结核报告发病率呈下降趋势,城市发展新区需要受到更多关注 [2] 。赵明扬等人通过构建普通最小二乘(OLS)模型、地理加权回归(GWR)模型、时空地理加权回归(GTWR)模型描述了2016~2018年全国分地区肺结核发病情况,结果表明气象和空气质量因素对肺结核发病情况具有显著影响,且该影响存在时空特异性 [3] 。Bie等人利用时空分布模型和INLA算法研究了7个影响因素及中国大陆结核病相对危险度(RR)的时空分布的影响。结果表明,从空间上看,相对风险最高的两个省份是新疆和贵州;从时间上看,从2013年到2015年,相对风险逐年下降。每年2-5月较高,3月最为显著。从6月到12月有所下降 [4] 。刘家起等人对2000年至2015年全球结核病患病率的影响因素进行单因素与多因素分析,结果表明全球结核病患病率与人均医疗卫生支出、15~49岁人口艾滋病病毒感染率等相关,应做好结核病的宣传教育工作 [5] 。
本文针对中国各地区社会发展、人口构成等因素,建立相关性分析与多元线性回归模型,探究不同地区的宏观因素对2019年各地区肺结核发病率的影响。
2. 变量指标与数据的选取
本文选取的被解释变量为2019年31个省份、直辖市、自治区的肺结核发病率(1/10万),将其记为y,此数据来源于公共卫生科学数据中心 [6] 。选取的解释变量有各地区人均国内生产总值(元)、文盲人口占15岁以上人口比重(%)、生活垃圾无害化处理率(%)、15~64岁年龄组构成比(%)、0~14岁年龄组构成比(%)、城镇人口构成比(%)、男性性别构成比(%),以及地方一般公共预算支出中的卫生健康支出百分比(%)、节能环保支出百分比(%)、教育支出百分比(%),以上数据来源于国家统计局 [7] 。解释变量选取及符号表示见表1,原始数据见附录表1。

Table 1. Explanatory variable selection and symbolic representation
表1. 解释变量选取及符号表示
3. 模型的建立与研究
将所选取的十个指标变量分别与2019年各地区结核病发病率进行相关性分析,采取Spearman秩相关性检验、Kendall τ相关检验两个非参数检验方法,比较检验结果,判断指标与结核病发病率是否具有相关性 [8] 。之后选取具有相关关系的指标与结核病发病率建立多元线性回归模型,进一步研究各指标对各地区结核病发病率的影响效果。
3.1. 相关性分析
3.1.1. 方法基本原理
1) Spearman秩相关检验
假设有样本量为n的样本为
,将观测值在样本中的位置用秩代替,即用Ri表示Xi在
中的秩,Qi表示Yi在
中的秩。若Xi和Yi具有同步性,则其秩Ri和Qi也应具有同步性,可定义Spearman秩相关系数为:
(1)
并可定义T检验统计量进行两变量的相关性分析。
2) Kendall τ相关检验
对于n对观测值
,若
,有
,则说明
与
之间具有协同性。Kendall τ相关检验即从两变量协同一致的角度出发检验其是否具有相关性。Kendall相关系数统计量定义为:
(2)
其中,Nc表示同向数对的数目,Nd表示反向数对的数目,即对于n对观测值,有
。
3.1.2. 相关性检验结果
由于Spearman秩相关检验和Kendall τ相关检验均为非参数统计方法不受数据分布的影响 [9] ,不需要对数据进行标准化处理,故利用原始数据应用上述两种相关性检验方法进行比较检验,相关性检验结果如表2,其中相关系数值均为绝对值,可表示各个指标与2019年各地区结核病发病率的相关程度。从检验结果可以看出,15~64岁年龄组构成比、0~14岁年龄组构成比、城镇人口构成比、人均国内生产总值与生活垃圾无害化处理率的检验P值均小于0.05,即以上五个指标与2019年各地区肺结核发病率具有一定的相关关系。而男性性别构成比、文盲人口占15岁以上人口比重以及地方一般公共预算支出中的卫生健康支出百分比、节能环保支出百分比、教育支出百分比与2019年各地区肺结核发病率不相关。为进行进一步分析,接下来将对具有相关关系的五个指标与2019年各地区结核病发病率建立回归模型,具体探究各指标对发病率的影响。
3.2. 多元线性回归模型
3.2.1. 普通最小二乘回归
为避免解释变量量纲的影响,对相关指标的原始数据进行标准化处理,标准化后的数据见附录表2,并对所选取的15~64岁年龄组构成比、0~14岁年龄组构成比、城镇人口构成比、人均国内生产总值与生活垃圾无害化处理率五个指标建立如下多元线性回归模型:
(3)
其中ε为随机误差项服从均值为0,方差为σ2的正态分布。若记X为自变量矩阵,则最小二乘估计即寻找参数βi,
的估计值
,使随机误差
(4)
取到最小值。
对多元线性回归方程进行显著性检验,得到F检验统计量值为9.221,P值为
小于0.05,则可知该回归方程显著,解释变量全体可对被解释变量2019年各地区肺结核发病率产生显著线性影响。
接下来对回归模型的基本假定条件进行验证。首先进行正态性检验,采用Shapiro-Wilk检验、Kolmogorov-Smirnov检验以及Anderson-Darling检验 [10] ,并画出回归模型残差的Q-Q图。得到以上三种检验的P值分别为0.5987、0.3656和0.8206,均通过了正态性检验,Q-Q图见图1,表明几乎所有的点都落在了直线附近,综上可说明该回归方程满足正态性的假定条件。
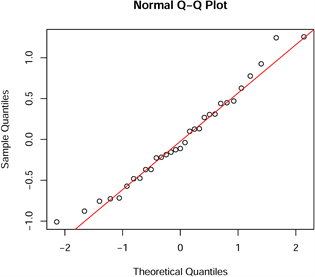
Figure 1. Least squares regression model Q-Q plot
图1. 最小二乘回归模型Q-Q图
检验回归方程随机误差项是否具有同方差性,其残差图如图2所示,从残差图可以看出残差的变化范围较大,则需考虑数据是否存在异常值,是否存在自相关性以及异方差性。
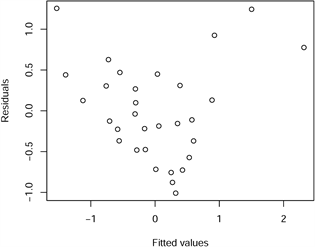
Figure 2. Least squares regression model residual plots
图2. 最小二乘回归模型残差图
首先利用D.W检验判断残差序列是否存在自相关性,得到其P值为0.06262 > 0.05,可以认为残差序列不存在自相关性。之后应用等级相关系数检验法诊断误差项是否具有异方差性,得到检验的P值为0.4044 > 0.05,认为残差序列不存在异方差性。利用学生化残差值判断是否存在异常值点,其观测值的学生化残差值、Cook距离值和杠杆值见附录表3,第6个数据的学生化残差为
,第31个数据的学生化残差为
,因而可以诊断第6个数据和第31个数据为异常值点。由于第6个数据和第31个数据的COOK距离小于0.5,其杠杆值也小于2倍的杠杆值平均值,所以第6个和第31个数据并不是强影响点。通过核实,本文数据不存在登记错误,故为消除异常值对建模的影响,将删除异常值数据,用其余数据拟合回归方程。
最后检验数据是否具有多重共线性,采用方差扩大因子法(VIF) [11] 和条件数法,得到的条件数值为k = 5.968987 < 10,各指标的方差扩大因子值见表3,可以看到五个指标的方差扩大因子均小于10,故认为数据不存在多重共线性,满足自变量之间不相关的假定。
Table 3. Variance expansion factor values
表3. 方差扩大因子值
3.2.2. 回归拟合结果
使用标准化后的数据,将异常值点删除后进行最小二乘估计,得到的描述性统计量见表4。
Table 4. Results of descriptive statistics of weighted least squares regression
表4. 加权最小二乘回归描述性统计结果
由表4可以得到,15~64岁年龄组构成比、0~14岁年龄组构成比、城镇人口构成比、人均国内生产总值与生活垃圾无害化处理率的回归系数检验P值均小于0.05,回归系数显著,则可以得到删除异常值点后最小二乘估计得到的多元线性回归模型为:
(5)
4. 结论
通过以上研究可得出结论,15~64岁年龄组构成比、0~14岁年龄组构成比与2019年各地区肺结核发病率成正相关。说明肺结核的患病率与人口的年龄结构显著相关,而本文仅研究2019年的各地区肺结核发病率,且未细致区分年龄结构,故可以进一步应用更多数据,研究不同年龄组人群肺结核患病率的差异,并针对不同人群给出不同的防治建议。人均国内生产总值也与2019年各地区肺结核发病率成正相关,说明地区经济发展水平有助于肺结核病的检测,提供更好的治疗条件。城镇人口构成比、生活垃圾无害化处理率与2019年各地区肺结核发病率成负相关关系,其原因可能由于城镇的建设更完善,更注重优化卫生环境,故为了降低结核病的发病率,我们应该致力于改善人民的生活条件,推广健康教育和普及结核病预防知识,并应该重视环境保护问题,提高垃圾无害化处理率。
基金项目
国家自然科学基金项目(NSFC11901027),北京建筑大学教学实践类项目(J1703)资助。
附录
Table 2. Post-standardization data
附表2. 标准化后数据
Table 3. Diagnostic analysis of outliers
附表3. 异常值的诊断分析