1. 引言
水是生命之源,每个人时时刻刻都离不开水,城市区域的可持续发展也与水密不可分,随着社会经济的不断发展,用水量也在逐渐增长,为高效配置区域水资源,增强用水效率,防止因水资源供需不平衡影响社会经济以及生态环境的发展,对用水量进行合理预测是至关重要的。
目前对用水量进行预测常用的方法有用水定额法、时间序列法、BP神经网络法以及灰色系统理论等 [1] 。用水定额法中对用水定额的选取容易受不同时期社会经济发展的影响,时间序列法突出时间序列而不考虑外界因素影响,这两种方法预测偏差都较大;BP神经网络对模型收敛速度要求高且构建过程复杂。相比于这些方法,灰色系统理论具有时间序列短、统计数据少、信息不确定的系统建模分析特点,适合于对用水量进行预测。谢锦彪等 [2] 基于最小二乘法原理改进模型初始值参数;闫海霞等 [3] 利用飞蛾火焰算法建立MFO GM(1,1)优化模型;江艺羡等 [4] 利用黎曼积分,以不规则梯形面积取代传统梯形面积优化背景值。虽然众多学者均提出了改进模型,但未针对具体类型数据进行研究。
本文通过分析陕西省各部门用水量变化趋势,针对不同部门的具体数据提出相应改进措施,提高模型预测精度,具有良好的实践意义,可为相关单位优化分配水资源提供科学的数据参考资料,以保障城市的健康高质量发展。
2. 灰色系统原理
灰色系统理论由我国华中理工大学邓聚龙教授 [5] 于1982年提出,经历四十年的发展,已基本形成了一套完整的结构体系,包括以灰色代数系统、灰色方程、灰色矩阵等为基础的理论体系,以灰色序列生成为基础的方法体系,以灰色关联空间为依托的分析体系,以灰色模型(GM)为核心的模型体系,以系统分析、评估、建模、预测、决策、控制、优化为主体的技术体系,是进行建模、预测和评估的重要研究方法之一。灰色系统理论是一种用于解决信息不完备、结构体系不明确的系统的数学方法,通过对部分已知信息的生成、开发,提取有价值的信息,建立数学模型,进而实现预测未知信息的目的。其优良特性在于能够根据各因素之间的关联性和测度寻找隐藏于系统内部的变化规律,在建模过程中经过科学的处理方法,弱化原始数据的随机波动性,生成有规律的序列数据,构造相应的模型。
灰色预测是灰色系统理论的主要组成部分之一,相较于传统统计学预测而言,灰色预测能够充分挖掘少量数据中的内涵信息,以从较少的数据中得到较为合理的预测。其中最重要、使用最广泛的灰色预测模型是一阶微分GM(1,1)模型,其具有建模原理简单、可靠性和预测精度高等优点 [6] 。GM(1,1)模型将原始序列进行累加得到新的呈现一定规律的生成序列,随即建立灰色预测微分方程,用一阶线性微分方程的解对生成序列进行模拟,并对未来进行预测。目前,GM(1,1)模型在工业、农业、水利、经济、社会、科技、军事、医疗等多个领域的预测与评估方面都得到了广泛应用 [7] ,但是,这并不意味着GM(1,1)模型可以随意使用,其具有一定的适用范围。刘思峰等 [8] 应用模拟研究、实验分析等方法确定了GM(1,1)模型的有效区、使用区、不宜区和禁用区;徐宁等 [9] 提出背景值构造需同时满足的无偏性和最小误差性等条件;李峥 [10] 认为GM(1,1)的模型背景值序列存在取法固定、缺乏灵活性以及易受原始数据影响造成误差增大、结果失真等问题。
用水系统是多因素、多层次的复杂系统,其特点符合灰色系统理论的应用领域,又因GM(1,1)模型所需信息少、建模简单、易于检验,本文采用灰色GM(1,1)模型进行用水量预测是合适的。
3. 灰色预测模型的建立
3.1. 传统GM(1,1)灰色预测模型
构造灰色GM(1,1)模型具体步骤如下:
第1步:设GM(1,1)模型的非负原始数据序列为
:
(1)
其中,n为观测数据个数;
为了弱化原始数据的随机性和波动性,增强数据的规律性,为灰色模型提供更加有效的信息,在建立灰色预测模型前,对原始数据做一次累加生成,即1-AGO (Accumulating Generation Operator),记一次累加生成序列为
:
(2)
其中,
;
第2步:准光滑检验:
(3)
当
;
,
时,
为准光滑序列;
第3步:准指数检验:
,
(4)
令
,当
时,
具有准指数规律;
第4步:由
构造模型背景值序列
:
(5)
其中,
;
第5步:建立GM(1,1)模型的灰微分方程为
(6)
相应的白化方程为:
;
其中,a为发展灰数,b为内生控制灰数;
第6步:采用最小二乘法确定参数:
(7)
其中
,
;
第7步:确定GM(1,1)模型的时间响应序列:
(8)
第8步:对式(8)做一阶累减还原得
的还原值为:
(9)
当
时,所得数值为原始数据的拟合值;当
时,所得数据为预测值。
3.2. 改进的GM(1,1)灰色预测模型
传统的GM(1,1)模型在建模时存在固有缺陷,有两处(参数、背景值)缺乏严格数学理论支撑,使模型不具备白指数率预测无偏性。为了弥补这些缺陷,求得最佳拟合函数,各领域学者进行不断探索,从不同角度改进模型,涌现出各种各样的改进算法。
大多学者针对参数或者背景值进行优化,考虑模型对高指数增长和低指数增长数据是否都适用,但对于用水量的趋势,一般都是平缓的增长,适用传统GM(1,1)模型。当精度不符合要求时,适用残差序列修正模型,先前的研究大多用于沉降量、灾害、故障率等的预测,很少将其用于需水量方面 [11] 。
设
,其中,
。
对残差序列进行一次累加生成,建立微分方程,求出相应的残差修正时间响应式:
。
4. GM(1,1)模型的精度检验
为判断GM(1,1)灰色模型预测的准确性和可靠度,必须对模型的精度进行检验,当检验达到标准后,方可进行预测。本文采用残差检验和后验差检验来评价拟合预测效果。
4.1. 残差检验
残差序列
为:
(10)
相对误差序列
:
(11)
平均相对误差
为:
(12)
e表示预测值与真实值的接近程度,其值越小越好,
表示预测残差占原始数据的比例,其值越小越好。
4.2. 后验差检验
后验差检验时,GM(1,1)灰色模型的预测精度取决于均方差比值C和小误差概率p。均方差比值与小误差概率成反比关系,当均方差比值增大时,小误差概率将会降低,模型的预测精度也会较低。
4.2.1. 均方差比值
均方差比值C表示残差序列均方差与原始序列均方差之比,其值越小,误差越小,预测精度就越好,若
时,模型检验不合格。
原始序列均方差
为:
(13)
残差序列均方差
为:
(14)
均方差比值C为:
(15)
式中,
,
。
4.2.2. 小误差概率
小误差概率p指残差与残差均值的差值的绝对值小于0.6745倍原始数据均方差的概率,其值越大,说明误差较小的概率越大,模型精度越高,若
时,模型检验不合格,精度不达标。
小误差概率p为:
(16)
式中,
为残差序列平均值。
4.3. 模型精度等级划分
GM(1,1)灰色预测模型精度检验等级划分标准见表1所示。

Table 1. Classification criteria for accuracy test of gray prediction models
表1. 灰色预测模型精度检验等级划分标准
5. 应用案例
陕西省位于我国西北地区,水资源相对比较匮乏,且分布不均,陕北、关中、陕南3个地区的水资源总量分别占全省水资源总量的9.8%、19.5%和70.7%,全省人均水资源占有量仅为1086 m3,约为全国平均水平的一半,是我国水资源最紧缺的省份之一 [12] 。水资源对于经济规模的增长至关重要,本文分析陕西省2010~2021年历年用水总量、农业用水量、工业用水量、生活用水量以及生态用水量数据,并对未来5年用水总量及各部门用水量进行预测。数据来源于陕西省水利局、《中国水资源公报》以及《陕西省统计年鉴》,见表2所示。
Table 2. Water consumption data of Shaanxi Province from 2010 to 2021
表2. 陕西省2010~2021年历年用水量数据
5.1. 灰色GM(1,1)预测模型的构建
(1) 建立原始数据序列并做一次累加生成
原始数据序列用水总量
,农业用水量
,工业用水量
,生活用水量
,生态用水量
:
,
,
,
,
,
一次累加生成序列用水总量
,农业用水量
,工业用水量
,生活用水量
,生态用水量
:
,
,
,
,
,
经验证,原始数据通过光滑性检验,一次累加生成序列通过准指数检验。
(2) 构造背景值序列
用水总量
,农业用水量
,工业用水量
,生活用水量
,生态用水量
:
,
,
,
,
;
(3) 建立GM(1,1)模型的灰微分方程
用水总量:
,
农业用水量:
,
工业用水量:
,
生活用水量:
,
生态用水量:
,
(4) 最小二乘法确定参数:
利用MATLAB软件编程求得a和b。
,
;
,
;
,
;
,
;
,
;
(5) 确定GM(1,1)模型的时间响应式
,
,
,
,
;
(6) 一阶累减还原
,
,
,
,
。
由此可得2010~2021年历年用水总量、农业用水量、工业用水量、生活用水量、生态用水量预测值见表3所示。
Table 3. Water consumption forecast data of Shaanxi Province from 2010 to 2021
表3. 陕西省2010~2021年历年用水量预测数据
5.2. 模型检验结果
对各部门用水序列进行残差检验和后验差检验,结果见表4所示。
由表可知,生活用水量和生态用水量模型的精度等级为“好”,用水总量模型的精度等级为“合格”,但农业和工业用水量模型检验结果为“不合格”,模型精度不够,需要对其进行修正。
5.3. GM(1,1)模型修正
陕西省2010~2021年各类用水量变化如图1和图2所示。
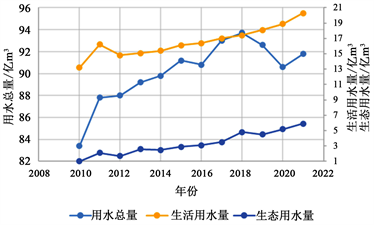
Figure 1. Changes in total water consumption, domestic water consumption, and ecological water consumption
图1. 用水总量、生活用水量、生态用水量变化
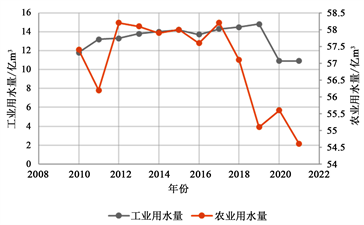
Figure 2. Changes in industrial water consumption and agricultural water consumption
图2. 工业用水量、农业用水量变化
由图1可以看出,用水总量、生活用水量和生态用水量呈平稳增长趋势,传统的GM(1,1)模型适用于分析这种稳定增长的数据,因此预测精度高。针对农业用水量和工业用水量数据,使用多种方法改进,包括参数优化和背景值优化:以
作为初始条件确定参数C;以使
与
离差平方和最小确定C;将原始背景值构造
代入微分方程求解等。这些改进方法求得模型精度等级低,由此可知,大多学者优化初始值和背景值改进的模型不适用于用水量方面的预测。
5.3.1. 农业用水量模型修正
农业用水量受降水影响比较大,在丰水年用水量小,枯水年用水量大,此外,随着城市经济的高速发展,农业的灌溉模式也在发生改变,由图2可以看出,近十年农业用水量呈现逐年减少的趋势。因此本文采用的修正方式是建立残差GM(1,1)模型。
利用2017~2021年数据建立可建模残差尾端序列:
;
1-AGO序列:
;
经验证,原始数据通过光滑性检验,一次累加生成序列通过准指数检验;
模型背景值序列
;
灰微分方程为
;
最小二乘法求得
;
时间响应式为
;
一阶累减还原
;
残差序列预测值
;
原始数据预测值
;
则原始数据预测值
;
模型检验结果:平均相对误差
,模型精度等级“好”。
5.3.2. 工业用水量模型修正
原始数据序列
;
一次累加生成序列
;
经验证,原始数据通过光滑性检验,一次累加生成序列通过准指数检验;
模型背景值序列
;
灰微分方程为
;
最小二乘法求得
;
则时间响应式为
;
一阶累减还原
;
模型检验结果:平均相对误差
,模型精度等级“好”。
5.4. 用水量预测
采用用水总量、生活用水量、生态用水量灰色GM(1,1)预测模型,以及农业用水量、工业用水量修正GM(1,1)预测模型预测陕西省2022~2026年未来五年的用水总量、农业用水量、工业用水量、生活用水量以及生态用水量,预测结果见表5所示。
Table 5. Water consumption projections for 2022~2026
表5. 2022~2026年用水量预测
为进一步检验该模型的合理性和准确性,与传统GM(1,1)模型以及文献 [13] 中灰色组合模型进行预测误差分析。选用近5年即2017~2021数据作为测试数据,计算相对误差见表6所示。
Table 6. Comparison of prediction error results of different models
表6. 不同模型预测误差结果比较
由表6可以看出,本文提出的改进灰色模型预测误差最小,结果更合理,说明该模型对陕西省用水量进行预测具有很好的适用性。
6. 结论
(1) 在前人研究的基础上,本文采用改进GM(1,1)模型,用水总量和各部门用水量预测模型精度都有很大提高。从结果来看,陕西省用水总量呈波动增长趋势,随着人民生活水平的提高,居民生活用水不断增加;城市化进程的加快促进工业发展,工业用水量也逐年增长,随之也加大生态环境保护用水量;由于农业节水灌溉技术的不断优化,农业用水量逐年下降。
(2) 本文针对陕西省2010~2021年历年用水量所建立的预测模型精度等级高,对未来5年用水量预测结果真实有效,可为供水规划决策提供可靠的数据支撑;此外,本研究重点是通过实践验证对于用水量此类呈平稳增长趋势的数据适用传统模型和残差修正模型,弥补了前人在实践上的不足。
(3) 灰色GM(1,1)预测模型是存在缺陷的,其预测数据是单调递增或单调递减,但实际被预测因素数据可能呈波动性变化,因此在实际应用中需进一步改进。
基金项目
陕西省自然科学基础研究计划项目(2021JLM-52)。