1. 引言
进入21世纪以来,在计算机的高速发展下,人类已经从工业革命进入信息时代。现实生活中各行各业每天都会产生大量的数据,而这些数据中隐藏的大量信息可以为日常生活带来巨大的便利,如何有效地存储并利用这些数据成为重中之重。数据库技术的发展可以很好地解决这一问题,它将数据按照一定的规则进行存储,同时也会提供对于数据的查、改、删、增等一系列操作,而实现这些操作,往往都会用到结构化查询语言(Structure Query Language, SQL)。为了帮助非专业的用户从数据库中查询到所需要的信息,提出了基于深度学习的自然语言–数据库接口(Natural Language Interface to Database, NLIDB),极大地降低了用户与数据库之间的交互门槛 [1] 。
NLIDB的核心任务是根据已有数据库信息,将自然语言问句映射到特定功能的SQL语句(Text-to-SQL)。Text-to-SQL是自然语言处理领域里语义解析的一个子任务。语义解析旨在将自然语言表达转换为结构化的语义表示,便于计算机能够理解和处理,其涉及语言学、计算语言学以及认知语言等多个学科,近几年获得了广泛的关注 [2] [3] [4] 。Text-to-SQL的深度学习模型需结合自然语言问句和数据库本身的信息,提取出关联的数据库表名、列名以及问句的意图模式。然而数据库本身复杂的内部结构以及中文自然语言问句表达方式多变等因素会给深度学习模型带来巨大的挑战,主要挑战有:1) 数据库中每张表存在表名、列名以及列名所对应的值,除此之外,还有主键、外键等关联信息,如何学习从这些复杂信息到结构化语句的映射是非常困难的;2) 相比较于英文的自然语言问句,中文问句的语法结构较为灵活,动词和宾语的位置可以交换,给模型的学习带来了极大的挑战 [5] 。图神经网络因其能够捕捉节点之间的局部结构信息和全局拓扑特征,近年来,被越来越多的深度学习网络引入。图神经网络(Graph Neural Network, GNN) [6] 通过将原始数据转为关系图谱作为输入,采用聚合节点的邻居信息,在图结构上进行线性变换、卷积等操作,能够准确表示各元素之间的关联信息。
本文的主要贡献如下:
(1) 本文借助图神经网络,引入自然语言问句中的语义依存信息,丰富了问句中每个单词的表示,从而提升识别关键词的准确率。
(2) 基于中文Text-to-SQL任务数据集Chase上进行验证,实验表明,本文所提出的方法可以有效提升SQL的匹配准确率。
2. 相关工作
目前,基于深度神经网络的Text-to-SQL模型通常由编码和解码模块构成,编码模块主要目的是提取问句与数据库模式的特征信息,便于解码模块准确生成SQL语句;解码模块利用编码模块所提取的特征信息进行SQL语句生成。
SQLNet [7] 通过列名注意力机制来增强模型捕捉问题与数据库模式之间的联系,然后在预先定义的SQL模板上使用指针网络来补全SQL信息。随着图神经网络的发展,结构化的数据库信息逐渐使用图神经网络进行编码。GNN-SQL [8] 使用图神经网络对数据库中表的结构形成全局表示,以此让模型在未见过的数据库模式上具有更好的泛化能力。Global-GNN [9] 通过引入全局节点,强化了问句和模式的全局化特征。然而上述方法仅仅考虑数据库层面的关联信息,没有考虑到问句中单词和单词之间的关联。
Zhong等首次在大规模SQL生成数据集WikiSQL上使用序列生成的方法,提出了Seq2SQL [10] 模型。Seq2SQL模型的主要创新是在Seq2Seq模型的基础上添加了输出模板,并将完整的SQL序列拆解成3个子任务进行学习,即agg的生成、where子句的生成和select的生成,在此基础上引入了强化学习方式。SQLNet [7] 在Seq2SQL基础上对子任务设计上做了进一步的细化,将where子句拆解为4个子任务,并且模型还引入了列注意力机制以强调自然语言问句中涉及列名的信息。基于树形结构的Seq2Tree [11] 采用了层级式树解码方法,可以很好地捕捉SQL语句的组成结构。SyntaxSQLNet [12] 利用堆栈来控制解码的进程,便于实现嵌套查询这类复杂句式的生成。
3. 问题描述与模型框架
3.1. 问题描述
Text-to-SQL任务的输入是一个查询语句以及其相应的数据库模式,输出是SQL语句。具体而言,模型需要根据所给定的长度为L个字符的问句
和相应的数据库模式S生成结构化查询语句Y。数据库模式指表名、列名、列类型和主外键等数据表逻辑结构信息,这里的数据库模式
,其中
指的是表名,
指的是列名,n为数据库包含表的数量,k为数据库中第n个表所包含的列名数。
3.2. 模型框架
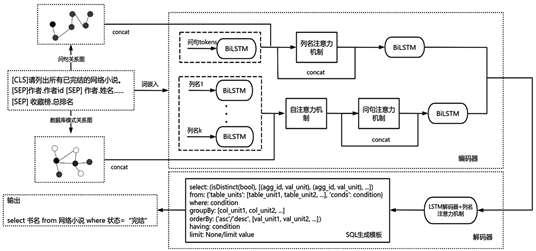
Figure 1. The overall framework of the model in this article
图1. 本文模型的整体框架
本文提出的基于问句语义图神经网络的Text-to-SQL模型采用序列到序列的框架,如图1所示,主要由3个模块组成:1) 图神经网络部分,包含数据库中各个表之间的关系、各个表中列名之间的关系及自然语言问句中语义依存关系;2) 编码器部分,通过图神经网络将这些关系融入词嵌入向量中,再使用注意力机制将问句、数据库模式联合编码为隐藏向量表示;3) 解码器部分,使用带有注意力机制( [13] , pp. 199-205)的长短期记忆网络(Long Short-Term Memory, LSTM) ( [13] , pp. 145-149)生成SQL语句。
4. 模型设计
4.1. 图网络构建
现有Text-to-SQL模型根据数据库信息构建图网络,仅仅包含表名–表名、表名–列名以及列名–列名3种关系类型 [8] [9] 。本文在此基础上,还添加了自然语言问句中各个词之间的语义依存关系,有施事关系、当事关系、受事关系等55种关系类型 [14] ,进一步让模型从现有的数据中学习到有用的信息。
本文根据数据库和问句分别构建了各自对应的图网络,其中,数据库图网络的节点为表名和列名,问句图网络的节点为哈工大LTP分词 [14] 的结果。构建的图网络所包含的关系类型具体有:
(1) 表名→列名:表的主键是列名;表中存在列名;表中不存在列名。
(2) 表名→表名:两个表通过外键连接;两个表互为外键连接;两个表不存在直接连接。
(3) 列名→表名:列名是表的主键;列名属于表的其中一列;列名不属于表的一列。
(4) 列名→列名:两个列名属于同一张表;两个列名不属于同一张表;一个列名是另一个列名的外键。
(5) 问句词→问句词:55种语义依存关系中任意一种。
4.2. 编码器
为解决未登录词问题,本文首先使用RoBERTa预训练语言模型 [15] 获得每个字符的向量,在此基础上根据分词结果,对词汇中包含字符的向量加和取平均获得词嵌入表示
,
,其中
是自然语言问句的词向量表示,
是数据库中列名的词向量表示,然后对问句和数据库模式构建图网络
和
,这里以问句图网络为例,获得最终词向量的具体过程如下:
(1) 问句图网络的节点是LTP的分词结果,根据LTP的语义依存分析结果,构建邻接矩阵
,矩阵中元素
表示第
行,第
列所对应的关系。
(2) 将问句的词向量
通过全连接层和激活函数得到新的词向量
:
(1)
(3) 对
做步骤(2)的变换,得到矩阵
,再将其与
的转置矩阵
相乘得到
:
(2)
(3)
(4) 根据关系矩阵
中元素是否为0得到矩阵
,基于
中元素值,生成新的
。
(5)
经激活函数与
相乘得
,再将
做步骤(2)的变换与
相加得最终编码向量
:
(4)
(5)
4.3. 解码器
解码器使用IGSQL模型中基于注意力机制的LSTM网络解码SQL语句。首先将问句词向量和模式词向量与LSTM的隐藏层向量做注意力操作,然后根据这一结果计算SQL关键词和数据库模式项这两类的重要系数,最后在重要系数基础上,选择对应的解码器,生成SQL语句中的字符。
重要系数的计算方式如下:
(6)
其中,
是LSTM解码器的隐藏向量,
是问句和模式词向量与LSTM隐藏层做注意力操作的拼接向量,
是sigmoid函数。
5. 实验与结果分析
5.1. 实验环境及数据集
本文的实验是在操作系统Ubuntu20.04下进行的,GPU为NVIDIA RTX A4000 16GB,开发编程语言为Python3.9,深度学习模型框架为PyTorch [16] 。
CHASE是由微软亚洲研究院和北航、西安交大联合提出的首个大规模中文跨领域上下文依赖的Text2SQL数据集,其由CHASE-C和CHASE-T两部分组成,分别来自DuSQL数据集、SParC数据集 [17] 。它包含了5459个对话以及相应的SQL查询语句,这些对话覆盖了280个数据库。为方便研究人员进行研究,CHASE每个问题都有丰富的语义注释,并且划分出训练集、测试集以及验证集部分。但考虑到本文研究的是上下文无关的查询问句生成SQL,因此,选取每轮对话中的第一个问题以及对应的SQL语句构成本文的数据集。
5.2. 评价指标
本文使用两个指标评价模型在CHASE数据集上的效果,分别为部分匹配率 (Partial Matching Accuracy, PM)和完全匹配率(Exact Matching Accuracy, EM),前者是将SQL拆解为“SELECT”,“WHERE”等几个部分,然后计算每个部分真实值与预测值的F1值;后者是在无顺序要求的情况下,衡量SQL语句预测值与真实值之间的匹配程度 [18] 。
5.3. 实验设置
本文使用中文RoBERTa作为预训练模型,在学习率为1e-5下进行微调,其可以处理的最大长度为512,但本文的训练样本最大长度不超过300,因此将300作为RoBERTa的输入长度。训练时迭代次数epoch为10,批量大小batch size为32,采用的优化器是Adam,使用warmup机制训练,Dropout层损失信息比例设置为0.5,模型学习率为0.003。
5.4. 对比实验分析
本文使用EditSQL [19] 和IGSQL [20] 模型作为基线模型进行对比,为了下文叙述的方便,本文提出的模型记为Ours。表1是不同模型在Chase测试集上的实验结果。

Table 1. Experimental results of different models
表1. 不同模型的实验结果
从表1的实验结果可以知道,模型引入问句中语义依存关系的信息可以提高模型的匹配率。相比较原有模型,Ours在完全匹配率上提升了6.3%,具有显著效果。
Table 2. Analysis of experimental results of IGSQL and Ours model
表2. IGSQL与Ours模型的实验结果分析
表2是EditSQL和IGSQL与Ours模型的实验结果例子分析,其中EditSQL、IGSQL生成的是错误的SQL,Ours生成的是正确的SQL语句。表2中的解释是对EditSQL和IGSQL生成错误SQL的原因分析,可见Ours可以更好的将问句中关键信息与数据库模式对齐。
为了更细致地分析本文提出的模型在不同SQL子句上的性能表现,表3给出了模型在各个子句上的F1值。从表3可以看出模型随着难度的增加,各子句的F1值并没有一直下降,其中select子句在困难程度下,F1值达80.3%,where子句中,F1值最高的是特别困难程度下。总的来说,对于生成复杂SQL语句来说,模型具有良好效果。
Table 3. F1 values of SQL clauses under different levels of difficulty
表3. 不同难度下SQL各子句F1值
5.5. 消融实验分析
为了分析不同模块对Ours模型带来的效果增益,本节对Ours模型进行消融来验证中文RoBERTa词向量模块和问句的语义依存关系图模块对模型性能的影响。消融实验结果如表4所示。
Table 4. Ablation experiment results of the Ours
表4. Ours消融实验结果
从表4的实验结果可以看出,完整模型相比不同的消融模型取得的效果最佳。对比移除RoBERTa词向量模块,移除语义依存关系图对模型的影响较大。因此,本文引入问句的语义依存关系图对于模型性能的提升起到一定作用。
6. 结束语
针对语义解析领域的Text-to-SQL任务,本文提出一种基于问句语义图神经网络的模型。根据自然语言问句与数据库模式信息分别构建关系图谱,通过图邻接矩阵的方式,将关系信息编码到词向量中。在Chase数据集上的实验结果表明,相比于EditSQL模型和IGSQL模型,本文所提出的模型能够利用语义依存信息更好捕捉问句中语义的信息,有效提升了模型在多表查询中的匹配准确率。然而,在现实的应用中,因自然语言交互的随意性,SQL生成任务仍存在诸多困难,比如零次学习(zero-shot)等。针对上述挑战,未来的研究可以通过改述自然语言问句来增强样本容量,或者引入外部知识(比如知识图谱等)来增强模型的表示能力。