1. 引言
合作行为广泛存在于自然系统和人类社会中,并且对种群进化和社会繁荣起到重要促进作用。但由于自私个体总是追求自身利益最大化,这与牺牲自身利益提高集体收益相矛盾,故而形成了社会困境。因此,研究自私个体之间合作行为的出现和维持成为一个有趣且具有挑战性的问题,引起了学者们的极大关注 [1] [2] [3] [4] [5] 。囚徒困境博弈作为解释合作行为的一般隐喻,已经得到了很好的研究 [6] 。在这个基本模型中,两个参与者应该同时选择合作(C)或背叛(D)策略。他们的收益确定如下:如果双方合作,每个玩家将获得奖励R,如果双方背叛,则获得惩罚P。如果合作者遇到背叛者,背叛者获得诱惑收益T,合作者获得收益S。并且需满足
和
,以确保博弈的性质 [7] ,这意味着无论对手的选择如何,背叛都是最好的策略。其结果是背叛行为在所有参与者中蔓延,称为社会困境。
解决这一困境的方法有很多种,主要可以分为两类。第一类是引入空间结构,让合作者可以形成紧凑的集群,以防止背叛者的入侵 [8] 。第二类是引入一些促进合作的机制 [9] [10] [11] ,如针锋相对(TFT,记忆),奖惩 [12] [13] [14] ,自愿参与 [15] [16] ,声誉 [17] ,愿望 [18] 和环境 [19] 。不仅如此,通常假设所有智能体在每一轮交互后都会同时更新他们的策略,然而,现实中博弈交互时间尺度与策略选择时间尺度并不总是相同的,研究表明,如果考虑时间尺度多样性,合作的演变可能会发生变化 [19] [20] [21] ,此研究尽管取得了一些进展,但这些研究通常是在费米策略更新规则的框架下进行的。也就是说,每个玩家选择一个邻居后以相同的概率或偏好学习其策略,这可能会忽略环境的影响。最近,强化学习(即Q学习算法)得到了很好的研究,并被纳入演化博弈中,以了解合作行为的出现。与直觉相反,强化学习未能促进囚徒困境博弈中的合作。这是因为这些研究主要是在混合良好的人群中进行的,没有考虑任何其他机制。
受到所有这些创新的启发,一个有趣的问题浮出水面:如果我们在方格网络上同时结合时间尺度多样性和强化学习,合作水平是否会得到提升?在这项工作中,我们考虑了囚徒困境博弈中每一轮交互结束后受时间尺度影响更新概率公式决定要不要更新策略,策略更新规则是自关注Q学习。数值模拟结果表明,时间度多样性可以促进合作。因此,关于时间尺度多样性与强化学习的影响的研究对于进一步理解人类合作变得有意义。
2. 预备知识
博弈论是研究人与人互动的数学框架 [22] [23] 。在两人两策略博弈中,两个智能体应该同时选择合作(C)或背叛(D)策略。他们的收益确定如下:如果双方合作,每个智能体将获得奖励R,如果双方背叛,则获得惩罚P。如果合作者遇到背叛者,背叛者获得诱惑收益T,合作者获得收益S。两人两策略博弈可以由矩阵给出,如下所示:
其中第一个元素表示行智能体的收益,第二个元素表示列智能体的收益。这四个参数的大小决定了博弈的类型和纳什均衡的位置。纳什均衡是指一套策略,没有人可以通过单方面改变自己的策略来获得更高的回报。如果参数满足
,博弈类型为囚徒困境博弈,纳什均衡为
;如果参数满足
,博弈类型为雪堆博弈,纳什均衡为
和
;如果参数满足
,博弈类型为猎鹿博弈,其纳什均衡为
和
;如果参数满足
和
,博弈类型为协调博弈且纳什均衡为
。
Q-learning是强化学习的基本算法之一 [24] [25] ,用于表征多智能体系统中由联合行动触发的决策过程。S为状态集,
表示具有n个代理的系统中的动作集。学习过程
意味着状态信息由所有智能体共享,并受联合行动的影响。Q-learning定义了一个Q表,其中每个元素(状态–动作对)代表在状态S中执行行动a的累计奖励。给定一个代理i,它在第t轮的状态S下执行动作
。设F表示i通过与环境交互获得的收益。Q-learning是一种自适应值迭代方法,每个智能体在基于当前时间步的Q值
和采取动作
后的状态
下的Q值
估计其下一步的状态–动作值
其中
代表学习率,
表示折扣因子。
为下一状态
行下
表的最大值,这是对状态
下最佳未来值的估计。该函数表示在状态s下采取行动
有多好。
3. 基于自关注Q-learning的演化博弈模型
考虑一个空间囚徒困境博弈(PDG),玩家占据一个
具有周期性边界的方形格子。在不失一般性的情况下,研究了弱PDG [7] ,其中收益矩阵
(1)
其中b表示背叛诱惑。
每一步中,每个玩家只能与他们的四个邻居(冯诺依曼邻居)互动以获得累积的收益。累积收益
(2)
其中
和
为玩家i和对手j选择的策略,M为收益矩阵,
为玩家i的邻居。
博弈交互结束后,根据更新概率公式 [19] 决定要不要更新
(3)
其中用
来刻画时间尺度,当
时,
,即每次博弈交互后一定会更新策略,代表没有时间尺度多样性的常规情形;当
,时间尺度多样性随着的增加而增加。
至于策略更新过程,玩家采用自适应Q学习算法,这与
涉及与环境交互的传统Q学习方法不同。在这样一个新颖的框架下,玩家i根据他们的经验用最大的Q值更新策略,而不考虑邻居的策略(这在以前的Q学习方法中是必需的)。Q值由Q表定义,用于记录不同动作在不同状态下的相对效用。在下文中,状态集S和动作集A是相同的,即
带有状态(行)和操作(列)的Q表提供如下:
(4)
其中
表示状态为s且动作a在时间步长t处玩家的Q值。为简单起见,但不失通用性,s表示玩家当前的状态,a表示可能采取的行动。当玩家与邻居交互完后,Q表会根据以下等式 [26] 进行更新:
(5)
其中
为学习率,
为当前时刻收益,并且
表示决定更新策略的未来奖励比例的折扣系数,
为下一状态
行下Q表的最大值。为了避免Q值收敛到局部最优值,在每一轮更新过程中使用
-贪婪探索法则。玩家以
的概率随机行动或者以
概率选取Q表中的最大值行动。这样高收益的行动将得到加强。
总的来说,整个算法流程如下:一、最初,所有玩家被分配到一个大小为
网络的格子上,随机分配一个初始状态,即玩家以相同的概率选择合作或者背叛。二、由于玩家最初不知道博弈或者环境,因此Q表初始化为零。三、每个回合中,随机选择一个状态s和动作a的玩家i,玩家i与周围四个邻居交互并根据公式(2)获得收益,根据公式(5)更新Q值。四、获得收益后,根据公式(3)决定要不要更新策略,若要,根据所选动作a,将玩家i的状态从当前s更新为
;否则这一轮交互后依旧保留当前状态s。五、重复程序三和程序四直至T步停止。
本文借助MATLAB进行仿真,演化博弈根据蒙特卡洛模拟过程向前迭代,方形格子大小为200 × 200。在实验过程中观察到,经过3500次迭代即可达到稳定状态,合作水平是从稳定状态的平均值得到的,因此,取5000次迭代最后500步稳态值的平均值。同时,为了保证较高的精度,进行了20次独立实验。
4. 结果和分析
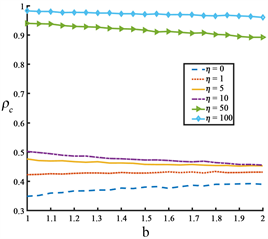
Figure 1. The effect of betrayal temptation
on the proportion of cooperators
at different
values. The remaining parameters
图1. 不同
值时背叛诱惑
对合作者比例
的影响。其余参数
我们先讨论强化学习解决传统PDG (
)的情形。从图1中我们可以看到,在没有时间尺度多样性时,自适应Q学习可以让合作者比例维持在一个可观的数量上,而不像在传统的费米更新规则中消失。因此,Q学习可以保持部分自私个体选择合作,但依然无法动摇背叛者的统治。接着我们讨论时间尺度多样性在Q学习下对合作者比例的影响。当考虑时间尺度机制时,与传统情形相比,合作者的占比随着
的增加而提高。当
时,完全由合作者主导。简言之,当同时考虑时间尺度机制与Q学习,尽管背叛诱惑大,依然能极大的促进玩家选择合作行为。
接下来从宏观角度观察当
取不同情况下,合作率是如何随时间演变的。如图2所示,大概到4000步时所有情况都能达到稳态,并且没有时间尺度多样性时(
)合作水平是最低的,背叛者数量更多,随着
逐渐增高,合作水平逐渐增强,当
之后合作者优势愈发明显,甚至能统治全局。由此可见,当时间尺度参数达到一定阈值时,合作行为能主导全局。

Figure 2. The evolution diagram of cooperation ratio
with time
when
takes different values. The remaining parameters
图2.
取不同值时合作比例
随时间
演变图。其余参数
为了从微观角度理解促进合作的机制,图3描绘了动态平衡下方形网络的演化快照图。我们将背叛诱惑收益值固定
。当时间尺度多样性较小时(
,上图),随着演化步骤的增加,这些玩家逐渐分散开,但背叛者占上风;当
时(中图),每个玩家都可以根据适应度适度调整自己更新策略的概率。最终,合作者和背叛者几乎持平。当
时,合作者逐渐主导背叛者,最终合作者几乎占据了整个网络,只有少数分散的背叛者。每个玩家能在一次交互后将高收益的行为保持住,不更新自己的策略。这样的结果表明,若中心玩家为合作者时,合作者就能维持更长的时间,背叛者的数量就会减少;而若中心玩家是背叛者时,会从它的周围合作邻居那获得高额回报,故而与背叛者相邻的合作者倾向于在随后几轮采用背叛策略,反过来又减少了背叛者的收益,Q学习可以引入目前人群中不存在的新策略,所以在这种周围都是背叛者状态中合作者仍然可以出现,从而导致背叛策略的短期存在。
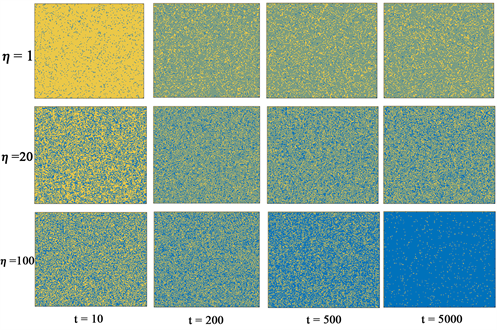
Figure 3. Evolutionary snapshots of cooperators (blue) and defectors (yellow) at different time scales and different iteration steps. From left to right, there are 10, 200, 500 and 5000 MCs, and the upper, middle and lower represent the cases of
respectively. The remaining parameters
图3. 不同时间尺度和不同迭代步下合作者(蓝色)和背叛者(黄色)的演化快照图。从左至右依次为10、200、500、5000个MC的情形,上、中、下分别代表
的情形。其余参数
上述我们已经证明了时间尺度机制结合强化学习如何有效的促进合作。接下来我们来探讨一下Q学习的自身参数(
)在结合时间尺度机制下又会如何影响合作的演变。如图4所示,左右两图分别代表传统情形和有时间尺度多样性的情形。从图中可以看出来,随着学习率
升高,合作者比例也会随着升高,说明较快的遗弃旧值可以加强合作。
代表玩家远见水平的折扣系数(小
意味着玩家更关注当前的收益),左图中可以看出
过大过小都是不利于合作的实现的,但当考虑时间尺度多样性后(右图)
最优取值范围更广一些,都反应了适度的关注未来的奖励才是明智的。
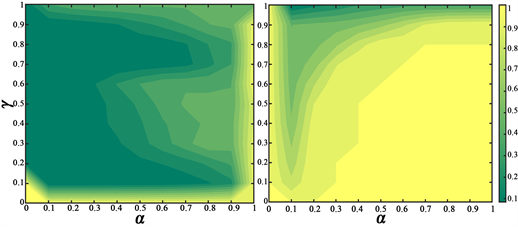
Figure 4. The two-dimensional parameters of
jointly affect the contour map of the proportion of collaborators. Left Figure:
; Right Figure:
, The remaining parameters
图4.
二维参数共同影响合作者比例的等高线图。左图:
,右图:
,其余参数
最后,我们研究一下初始设置是否会影响合作的稳定性(即方法的鲁棒性)。为此,我们固定演化早期合作者的占比分别为总人口的10%、30%、50%、70%、90%,如图5,图6所示,图5为传统情形(
),图6为有时间尺度多样性(
)。由于玩家喜欢学习最大收益策略以避免被他人利用,合作水平几乎不受初始分布的限制,并且初始分布对于有无时间尺度机制都是鲁棒的。从这个角度来看,如果玩家只学习最大收益的动作,合作可以达到相同合作水平的稳定状态。

Figure 5. The evolution of cooperation rate with time under different initial proportion of collaborators (
). The remaining parameters
图5. 不同合作者初始占比下合作率随时间的演化情况(
)。其余参数

Figure 6. The evolution of cooperation rate with time under different initial proportion of collaborators (
)
图6. 不同合作者初始占比下合作率随时间的演化情况(
)
5. 结论
本文未考虑随机性因素,同时企业之间隐瞒信息导致在信息不对称下做决策是常有的事情,将是以后需要继续挖掘的课题。本文表明,将时间尺度机制与强化学习策略更新规则相结合能够极大的促进合作水平的提升。数值结果表明,即使诱惑很大,时间尺度机制依然能够促进合作的生存。这是因为当博弈交互时间尺度大于策略更新时间尺度时,对于高收益的策略能够维持更长的时间,若中心玩家为合作者时,合作者就能维持更长的时间,背叛者的数量就会减少;而若中心玩家是背叛者时,会从它的周围合作邻居那获得高额回报,故而与背叛者相邻的合作者倾向于在随后几轮采用背叛策略,反过来又减少了背叛者的收益,Q学习是一种创新规则,可以引入目前人群中不存在的新策略,所以在这种四周都是背叛者状态时合作者仍然可以出现,从而导致背叛策略的短期存在。不仅如此,我们研究了影响Q学习的参数,一般来说,高学习率和适度的折扣系数更有利于合作。最后,还验证了无论初始状态如何,合作将始终收敛到稳定水平。
我们的工作不同于参考文献 [27] 在混合良好的人群中进行,我们关注的是结构化人群,这更接近经验观察。也不同于参考文献 [19] [20] [21] [28] 将费米函数用作策略更新规则,揭示了自关注Q学习算法对于解决社会困境的特定积极作用。因此,我们相信,我们的工作能够为未来提高合作率的研究带来更多启示,从而推动社会困境解决机制的发展。