1. 引言
在现代工业生产中,需要对各种零件进行快速的分拣。大多数电器零件种类繁多,体积微小,而一部分零件生产厂家现阶段仍是采用传统的人工分拣方法,使零件分拣效率低、成本高。随着工业生产对机器自动化和智能化需求的不断增长,基于机器视觉的检测 [1] 、测量 [2] 和定位 [3] 等技术被越来越多地应用到实际生产中。然而,生产过程中种类繁多、外形复杂且相似度高的电器零件,其视觉识别和处理工作仍然存在极大的困难和挑战。因此,利用机器视觉技术,对实际生产环境中的电器零件实现自动化的高效准确的分类变得尤为重要。
基于机器视觉的图像分类方法,主要包括特征提取和深度学习两种策略。采用特征提取的图像分类方法,侧重于通过人工设计的规则,将图像映射成一个独特的特征向量。随后,利用机器学习分类器,如支持向量机 [4] 等,对特征向量进行有效的分类。经典的特征提取方法有:局部二值模式 [5] 、尺度不变特征变换 [6] 、方向梯度直方图 [7] 等。尽管在形成最终的特征描述向量过程中,通过特征编码和特征整合等手段,在一定程度上增强了特征描述的鲁棒性,但在应对各种光照变化、细粒度分类等方面仍然存在一些误差。
深度学习作为人工智能领域的一项关键技术,其强大的特征学习能力和模式识别能力为解决电器零件的分类问题提供了全新的途径。目前,针对图像分类的深度学习算法,有两种主流架构:一种是以ResNet [8] ,AlexNet [9] 等为代表性的卷积神经网络的特征提取算法,具有较强的局部感知能力,且网络结构相对轻量化,对资源有限的端侧设备较友好。然而,对于图像全局特征的识别有一定局限性。另一种是以Transformer [10] 为代表性的主干网络的提取算法,具备较强的全局关联能力,能更好地捕捉到图像中的全局特征。然而一般参数量较大,不易部署与推理。比如Swin Transformer [11] 、Vision Transformer [12] 等。而在工业检测中,我们期望模型能够达到较强的实时检测能力,并且保证获得较准确的检测结果。因此,本文通过结合CNN [13] 与Transformer两种算法的优势,提出了一种针对复杂电器零件的轻量化、高精度分类算法,以实现对电器零件的实时检测。
2. 数据集与预处理
如图1所示,本文基于实际生产工业生产环境下,采集并制作了6种代表性的电器零件图像数据集。并采用了多种的数据增强方式,获得了3000多张高分辨率的零件数据集。数据集由多种复杂零件图像构成,涵盖实际作业场景下的多种拍摄问题(光照不均、零件表面存在阴影、反光、摆放角度多变等)。将采集到的零件数据集,首先按照6:2:2比例划分为训练集、验证集、测试集,之后单独对训练集进行多种线下数据增强(随机旋转、色域变换、均衡化等),从而获得最终的复杂电器零件的工业数据集。

Figure 1. Sample diagram of electrical parts
图1. 电器零件样本图
3. 轻量化模型
模型结构如图2所示。输入图像被统一压缩成224*224*3 (高*宽*通道数)大小,而后进行特征提取。模型结构共六层,在前五层中,每一层都对特征图进行2倍的下采样,以提高网络感受野,捕获更多的全局特征。最后一层,通过将特征图展平为1维向量,从而得到最后的分类得分。模型前两层采用提出的轻量化卷积残差块结构,第三、四层采用提出的多尺度的金字塔特征提取结构,并结合MobileVit [14] 中的多头注意力结构(TransEn-block),进行多尺度的全局特征提取。在模型第五层,结合提出的SkipAT-block结构,实现复用第四层的注意力计算结果,实现轻量化的注意力块计算。
在面对实际工业应用场景,本文重点考虑模型的轻量化和实时推理速度。具体地说,本文在MobileVit基础上,做了以下三种改进:
1) 引入了Skip-Attention [15] 对原模型的TransEn-block结构进行改进,即SkipAT-block。通过利用前面层的自注意力计算来近似一个或多个后续层的注意力,在维持模型整体性能的同时,减少了计算和存储开销。这一改进不仅有利于模型在有限硬件资源下的高效部署,还加速了推理速度,使其更适用于实时应用场景。
2) 为了进一步降低模型的复杂度,引入深度卷积代替原网络中的常规卷积,并利用通道打乱以及残差连接的结构,增加多个通道特征信息的有效交互,从而构建了L-ConvRes模块。
3) 针对本文零件特征,我们设计了多尺度的金字塔特征提取模块(MPCF),该模块通过引入多尺度的卷积核,能够灵活捕捉零件在不同尺度上的特征信息,从而更全面地理解零件的结构和形态。
3.1. SkipAT-block
为了实现模型的轻量化,我们借鉴了先前研究中提出的Skip-Attention概念。在视觉Transformer的网络结构中,不同层之间存在着显著的特征图相关性。基于这一观察,通过采用Skip-Attention (SKIPAT),在前面层的多头注意力(MSA)计算的输出上引入简单的函数控制,实现了重用自注意力块的目的。这一设计旨在保持模型基准性能的同时,提高计算速度,使模型更适应轻量化需求。详细实现如下:
(1)
(2)
(3)
SKIPAT参数函数,如公式(1)所示。将第L-1层的MSA块(
)通过两个线性层(
)和中间的深度卷积 [16] (DwC),因此将特征映射到第L层,作为L层的注意力计算结果,从而省略中间层的注意力计算,以实现层注意力复用。引入参数函数的目的在于确保直接特征重用不会影响这些注意力块中的平移不变性和等价性。此外,该参数函数还充当了一个强大的正则化器,有助于提升模型的泛化性能。SkipAT-block的实现框架,如公式(2)、(3)所示。它将L-1级的整体输出(
)与L-1的多头注意力经参数函数后的输出(
),同时作为第L级的输入,而后第L级只通过多层感知机(MLP),而后与原输入进行残差连接,从而得到L级最终的输出。相比于原先的多头注意力结构(TransEn-block),L级省略了过多的注意力计算,节省了模型整体的耗时。
3.2. 轻量化残差卷积块(L-ConvRes)和多尺度的金字塔特征提取模块(MPCF)
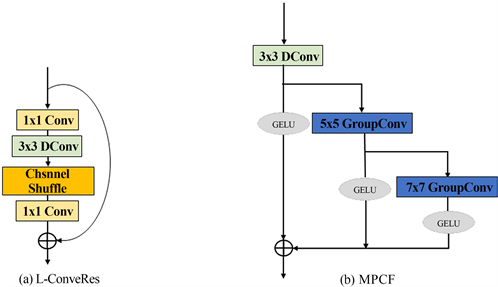
Figure 3. Lightweight residual convolution block ((L-ConvRes) and multi-scale pyramid feature extraction module (MPCF)
图3. 轻量化残差卷积块和多尺度的金字塔特征提取模块
轻量化卷积残差模块如图3(a)所示。该结构采用两个1*1的常规卷积,分别进行通道的降维和升维,一方面,能够有效地降低模型的复杂度。另一方面,允许模型学习不同通道之间的非线性关系。采用3*3的深度卷积在增加网络感受野的同时,保证了模型的轻量化。并且,为了保持不同组之间特征的信息交互,以及更好的捕捉多尺度特征,进行了通道打乱,在不引入额外参数的同时,有效地提高了模型的鲁棒性。
多尺度的金字塔特征提取模块如图3(b)所示。模块采用了大核卷积,金字塔式的特征提取和融合结构。首先将输入特征图先通过一个3*3的标准卷积进行通道压缩,以减少计算量。此时,输出特征信息将分成两条分支,一支进行非线性激活作为该层的单独输出特征,另一支是将该层特征继续通过一个5*5的组卷积(分8组),尽一步地进行多尺度特征提取。同理,此时输出继续作为单独的一支进行输出,而另一支继续通过一个7*7的组卷积(分16组)来提取有效特征。最后,将提取到的特征图相加,实现进一步地多尺度特征的融合。经上一个卷积输出的特征每次通过下一个卷积,都会进一步扩大感受野,提取到更多的特征信息。且每个卷积的输出特征信息又被单独保存输出,不同尺度的特征得到高效地利用。
4. 实验及结构分析
4.1. 实验环境与相关参数
训练过程中,训练集被压缩成224*224大小,之后进行随机旋转、裁剪等方法进行线上增强。同时,验证集也压缩到224*224进行效果评估。考虑到零件数据集与公开数据集的差异性,我们未使用任何预训练权重,从头开始训练。我们的网络训练和测试在基于Pytorch1.10.0+cuda11.5+Nvidia GeForce RTX3090平台上进行。实验相关参数的具体设置如表1所示。

Table 1. Experimental related parameter settings
表1. 实验相关参数设置
4.2. 评价指标
面对真实的工业应用场景,本文主要从检测速度和检测精度两个方面来评估针对复杂电器零件的检测算法的性能。因此,本文从检测准确率、参数量、实时推理速度三个指标,进行模型整体性能的评估。
1) 准确率(Accuracy)
(4)
表示正确分类的样本个数占总样本个数的比率,其中N表示样本总数,TP表示该零件准确分类时的样本数,TN表示将非该类零件判断为非该类的样本数。准确率越高,表明模型的检测精度越高。
2) 参数量(Params)
是指网络模型中需要训练的参数总数。模型参数量较多会增加在推理过程中的计算资源需求,包括CPU、GPU或其他专用硬件。在工业场景中,部署硬件通常是受限的,因此较大的模型可能导致计算资源短缺,降低推理速度。越小的参数,对部署设备更加友好,推理速度一般更快。
3) 实时推理速度(FPS)
FPS (Frame Per Second)即每秒可以处理图片的数量。不同的检测平台其性能各不相同,因此评估FPS参数时须在同一设备上进行测试。本文在单位时间内处理图片数据,通过1秒内处理图片的数量,数量越多,表示实时检测速度越快。
4.3. 实验细节
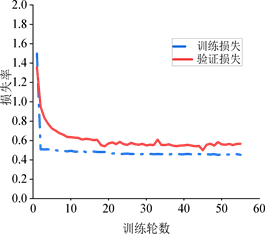
Figure 4. Accuracy curves (left panel) and loss curves (right panel) on training and validation sets
图4. 训练集和验证集上的精度曲线(左图)和损失曲线(右图)
本文模型训练过程中,训练集以及验证集上的精度和损失如图4所示。从左图可以看到,在模型训练50轮左右时,模型逐渐收敛,训练集与验证集上的精度曲线变化平缓,训练集上精度接近99%,验证集上的准确度可达97.8%。同时,从右图可以看到,两s数据集上的损失在45轮左右也趋于平稳,训练集上的损失可稳定在0.5,验证集上的损失可稳定在0.6。由此看出,本文模型在达到较高检测准确性的同时,具备良好的鲁棒性。
5. 实验结果与分析
Table 2. Test results of each model on the electrical parts dataset
表2. 各模型在电器零件数据集上的测试结果
多个轻量化模型在本文电器零件测试集上的实验结果,如表2所示。可以看出,本文模型针对零件数据集有较高的检测正确率,且参数量较低,实时推理速度较快,可达到每秒125张图像的检测速度。其中,MobileVit也是将CNN与Transformer相联合的混合模型,本文模型在原有的MobileVit上,准确度提升了1.2%,实时推理速度是其2倍。并且,与纯卷积结构的Mobilenetv3、Mobilenetv2、Espnetv2相比,本文模型实时检测精度各有3%、3.3%、1.6%的提升。其中,Mobilenetv2在实时推理速度上有显著优势,但模型参数量较大。同时,本文模型与检测准确度相近的Mobilenext相比,本模型的参数量约是其1/3,而提升了将近1%的检测准确度。总体上,本文模型在兼顾检测准确度和模型轻量化的同时,保证了较优的实时推理速度。
通过比较各模型的实时推理速度,可明显看出,纯卷积模型普遍具有较高的实时检测速度。将参数量相近的纯卷积结构的Espnetv2与注意力块较多的MobileVit相比,前者比后者的实时推理速度快了将近一倍。由此也证明,本文采用卷积块结合Skip-Attention方法构建较轻量化的模型,进行零件特征提取的合理性。一方面,利用少量注意力块有效解决CNN中无法捕获长距离依赖信息的局限性,另一方面,利用卷积结构在端侧检测中的推理优势,实现较高的实时检测效率。
6. 结论
本文创建了多种复杂电器零件图像数据集,采取多种数据增强方法处理,并构建了针对零件的轻量化分类模型,实现了对多种零件的有效分类。实验结果表明,本文模型相比其他较成熟的轻量化模型,具有较高的检测速度和较低的延迟,同时保持了较高的准确率,能够满足工业检测的实际需求。
NOTES
*通讯作者。