1. 引言
随着全球能源安全问题日益突出,以及气候转变等环境问题的加剧,风力发电技术逐渐受到了全球各国的关注 [1] 。中国能源局的资料表明,2022年上半年全国风能新增1294万千瓦。其中陆上风能新增装机1206万千瓦,海上风能新增装机27万千瓦。截止2022年6月底,风电装机3.42亿千瓦 [2] 。自然风力会随天气变化呈现不规律波动,导致发电功率不稳定。同时,风电在全国电网中的占比也具有非平稳性,这些不稳定因素都对电网的安全可靠运行带来挑战。因此,能否精确地预测风力发电的功率对电网的规划和安全运行具有重要意义。
目前,风电功率预测的典型方法有时间序列模型 [3] 、机器学习模型 [4] 、深度学习 [5] 和组合预测模型 [6] 等。文献 [7] 通过构建ARIMA模型计算历史风电序列特征以预测短期风电功率。但由于风电功率序列的非平稳性,其MAPE值仅为4.9%,效果并不理想;文献 [8] 采用改进的ARIMA模型,通过人工神经网络模型修正风电功率序列特征,减少了风电功率中的不平稳性特征的影响,提高了预测精确度;文献 [9] 采用极限学习机-LSTM组合模型训练,并通过加权灰色关联算法提取特征近似的历史数据,缩小了风电功率预测误差分布范围;文献 [10] 采用CNN-LSTM神经网络组合模型进行训练,利用主成分分析法(PCA)对原始气象特征降维,以实现风电功率的精确预测;文献 [11] 采用变分模态分解(VMD)、卷积长短记忆网络(ConvLSTM)和误差分析构建的组合模型用于短期风电功率预测。结果表明,该模型相比单一模型,能更有效挖掘出风电功率序列特征,具备更好的预测性能。文献 [12] 通过引入基于注意力的门控循环单元(AGRU),提高了模型的预测精确度。该模型通过嵌入了GRU块的隐藏激活函数来关联不同预测步骤的任务,并设计一种注意力机制作为特征选择方法以识别关键输入变量。通过组合不同模型,合理运用各个模型的特点和优势,组合模型相比单一模型具备更好的稳定性,但其适用范围也存在一定限制 [13] 。
综上所述,目前常见的风电功率预测模型结构简单且易于应用,能够基本满足预测需求。但缺乏对数据波动性的考虑,相对于组合模型存在泛化性弱、抗干扰能力差、特征提取能力不足、预测精确度不佳等问题 [14] 。为此本文提出一种基于注意力机制的VMD-CNN-LSTM短期风电功率预测模型。首先利用变分模态分解(VMD)算法将风电功率序列分解成若干个分量,再采用注意力机制对历史气象特征和轴承变量分配不同权重,实现特征融合。之后,通过卷积神经网络(CNN)对带有权重特征的新数据进行其特征的深度挖掘。最后,将挖掘出的局部特征数据以时间序列格式输入长短期记忆网络(LSTM)训练。其中,LSTM对每个分量结合气象特征和轴承变量的关联性进行训练,对输出结果重构并获得最终风电功率预测值。另外,为了提升模型的整体性能,使用hyperopt贝叶斯算法对整体模型的超参数迭代寻优 [15] 并输出最终模型。本文相对于传统风电功率组合模型有两点创新:一是在数据预处理过程采用VMD算法,对风电功率序列数据分解成若干个子分量,对每个分量结合风电功率特征变量训练,再对各个分量的预测结果重构,解决了风电功率序列波动性大,噪声强的问题。二是在CNN-LSTM组合模型中引入注意力机制,对关键的特征分配强权重,将复杂的特征简单化,增强了LSTM的记忆能力。在Elia比利时电网公司提供的开源风电功率数据集上的实验结果表明,本文提出的基于注意力机制的VMD-CNN-LSTM预测模型,相比于其他模型,具备更好的风电功率预测精确度和泛化性。
2. 模型构建原理
2.1. VMD简介
风电功率序列信号具有非平稳性,将其分解成多个子序列以降低功率序列的复杂程度。在一般情况下对于长序列的信号分解,EMD算法的使用较为广泛。但该算法的本征模态函数分量数目不能人为控制,且分解模态分量较大时,易出现模态混叠情况导致预测精确度不高 [16] 。VMD算法 [17] 作为一种新型信号分解技术,弥补了EMD技术缺陷。因此本文使用VMD对风电功率数据进行分解。
假设原始信号f可分解为k个分量,分解序列为具有不同中心频率的本征模态函数(Intrinsic Mode Function, IMF),则约束的变分表达式如式(1)所示:
(1)
式中:
为模态信号,
为狄拉克函数,f为时间序列,k为模态数,
为第k个模态的中心频率。
利用Lagrange乘子λ将变分问题转换为非约束性问题,得到变分约束模型的最优解。其中,增广Lagrange表达式如式(2)所示:
(2)
式中:α为二次惩罚因数,λ为拉格朗日乘子。使用交替乘子法,计算得到
和
。
通过迭代更新后得到迭代分量
、迭代中心频率
、迭代Lagrange乘子
的表达式如下:
(3)
(4)
(5)
(6)
式中:ε为迭代收敛阈值,N为最大迭代次数。
2.2. 基于中心频率确定分量个数
在对功率序列使用VMD算法进行分解时,k的取值合适与否至关重要。当取值较小时,易造成欠分解;当k值较大时,会出现模态混叠或噪声增加的情况。这两种情况都会影响到模型对风电功率序列预测的精确度。本文分别取k值为3,4,5,6,7,并标记对应分量的中心频率。最终当第k次出现中心频率相近的k值时,即确定k − 1为分解模态的数目,以此参数分解风电功率序列。
2.3. 加入注意力机制的预测模型
CNN-LSTM模型本身已具备强大的性能,但当输入的特征信息比较多时,模型的复杂度会增加,导致LSTM网络对于长序列输入特征信息的记忆能力不高。虽然CNN局部连接、权值共享等优化操作能够一定程度上降低模型的复杂度,但仍有进一步提升的空间。综合考虑以上问题,引入了注意力机制,以进一步提升CNN-LSTM模型的预测精确度。首先对每个IMF分量和收集的相关气象特征以及轴承变量使用MinMaxScaler算法归一化 [18] ,并分别在CNN-LSTM网络建模,再对输入特征变量分配自适应权重系数,从而改变输入特征变量对输出结果的贡献率,以缓解模型复杂度和表达能力之间的矛盾,最终获得风电功率序列与特征之间的相关性信息,进一步提高CNN-LSTM组合模型的预测精确度。
3. 基于注意力机制的VMD-CNN-LSTM风电功率预测
3.1. 预测模型结构
本文研究的目标为设计一种基于注意力机制的组合预测模型,用以实现对风电功率序列高精确度预测。首先通过VMD算法对风电功率序列进行分解,得到若干个本征模态函数分量。之后凭借CNN网络深入挖掘输入特征变量和风电功率序列分量之间的相关性。引入注意力机制对不同特征划分权重系数,以减少模型的复杂度。利用LSTM模块解决功率序列与特征之间的长依赖问题,得到风电功率序列的变化规律,输出各分量的预测结果。最后对输出数据进行重构,得到最终预测结果。
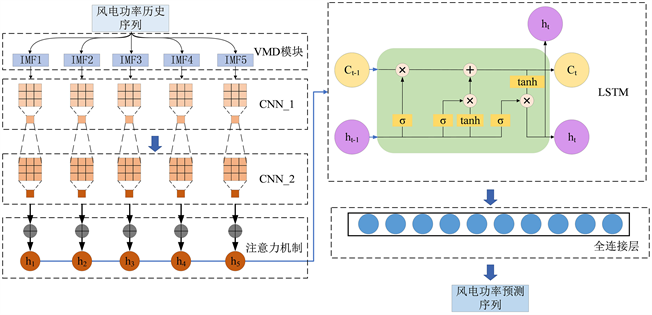
Figure 1. The structure of VMD-CNN-LSTM model based on attention mechanism
图1. 基于注意力机制的VMD-CNN-LSTM模型结构
模型整体结构如图1所示,包括变分模态分解模块、卷积神经网络模块、注意力机制模块和长短期记忆模块。变分模态分解模块中IMF分量的数量k取值为5,alpha设置为7000,tol精确度设置为0.0000007,init初始化W值为1,以避免风电功率序列在迭代过程中端到端效应以及虚假分量问题,减缓模态混叠现象。卷积神经网络模块包括两个不同卷积核大小的卷积层和一个最大池化层。这样设置可以让不同宽度的卷积核结合下采样操作,利于挖掘风电功率序列的潜在特征,并抑制序列的高频噪声。注意力机制模块采用单通道注意力模块,结合softmax归一化激活函数计算风电功率特征权重,对关键特征重新赋予较大权重。长短期记忆模块设置为两层,隐藏节点数分别为100,200。为了避免过拟合,在LSTM模块的最后一层设置了dropout层,让某部分神经元停止工作,减少神经元之间复杂的共适应关系,缓解过拟合现象,提高组合模型的泛化性。
3.2. 评价指标
采用均方误差MSE,均方根误差RMSE,平均绝对误差MAE和平均绝对百分比误差MAPE [19] 作为预测模型的评价指标,各个误差函数的表达式分别如下:
(7)
式中:m为样本的数量;yi为样本i风电功率的实际值;
为样本i风电功率的预测值。在风电功率预测中,如果上述四种指标的数值越小,表示预测值与实际风电功率值的差异越小,预测精确度越高,反之,则越低。
4. 算例分析
4.1. 数据集
本文使用比利时电力公司(Elia Wind grid)观测站站点提供的公开数据集。原始数据集中的特征数据包括了风电功率、风速、风向和环境温度等14个维度数据。实验数据集取自波罗的海(Baltic Sea)的海上风电场。
总计23,520个小时的数据样本。将训练集、验证集和测试集的样本数量按照6:1:3的比例进行划分。其中,训练集有14,112个样本,验证集有2352个样本,测试集有7056个样本。
4.2. 数据处理
Baltic站点风电功率的数据集样本足够多。因此,将有缺失的数据直接整行删除,对剩余数据进行归一化处理,对非数值数据进行one-hot编码。最后通过因素相关性分析以及VMD算法将功率序列分解为若干个分量。
4.2.1. 因素相关性分析
本文利用斯皮尔曼相关系数 [20] (Spearman Correlation Coefficient, SCC)对特征向量和目标向量进行相关程度分析。和皮尔逊相关系数(Spearman Correlation Coefficient, PCC)相比,SCC无需对数据进行正态性检验,可以更好地显示二者的关联程度。
SCC算法所使用的数据是“秩”,即根据向量数的大小排列等级而不是数值本身,其具体表达式为:
(8)
式中:N为样本数;
为特征因素等级数;
和
分别为某气象和轴承因素与风电功率的平均等级数。
取值范围在−1到1之间。如果
,则表明二者呈正相关关系,否则呈现负相关。
的绝对值越接近1,则说明二者相互关联的程度就越高,反之越低。比利时电力公司风电场的实测数据的特征包括环境温度、轴承轴温度、叶片3桨距角、齿轮箱轴承温度、齿轮箱油温、发电机转速、发电机绕组2温度、轮毂温度、主箱温度、无功功率、涡轮机状态、风向和风速。这些特征与风电功率之间的SCC如表1所示。
从表1可知,发电机转速、风速、无功功率与风电功率的SCC分别为0.984、0.983和0.981,存在较强关联性;齿轮箱轴承温度、发电机绕组2温度、齿轮箱油温和轴承轴温度与风电功率呈现弱相关关系,而环境温度、叶片3浆距角、轮毂温度、逐项温度、涡轮机状态和风向的SCC值很低,表明上述特征几乎与风电功率没有关联,所以将发电机转速、风速、无功功率、齿轮箱轴承温度、发电机绕组2温度、齿轮箱油温和轴承轴温度等7个相关性强的特征因素作为输入特征。

Table 1. Correlation coefficient between wind power and characteristic factors
表1. 风电功率与特征因素之间的相关系数
4.2.2. 变分模态分解分析
为获取更加可信的数据集,并充分发掘风电功率序列和特征因素之间的潜在规律。采用VMD算法把风电功率序列划分成了若干个分量。该算法通过中心频率法来确定模态数量k。一般情况下,k取值范围为3~7。据表2可得,k从5到6的值相似,可得,k选5。并结合模态混叠情况,模块参数:alpha为7000,tol精确度为1e−7,init初始化W值为1,使之均匀分布产生随机数。k值为5,将风电功率序列分解为5个模态分量。
Table 2. Center frequency for different number of modes k
表2. k个模态分量的中心频率
从图2中各个分量的频谱图和图3的中心模态分布图可知,IMF1原始频谱呈现很强的不稳定性,当进行一级分解时,不稳定性开始趋于稳定,当进行IMF4到IMF5分解时,频谱呈现稳定状态,说明此时风电功率序列分解比较理想。
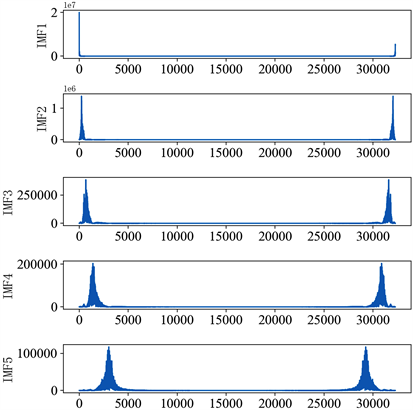
Figure 3. IMF Central Mode Distribution Diagram
图3. IMF中心模态分布图
4.3. 预测结果分析
各个模型主要超参数见表3。
Table 3. The main hyperparameters of the model
表3. 模型主要超参数
为检验本文所给出预测模型的有效性和可行性,对本文模型与ARIMA模型、SVR模型、LSTM模型、CNN模型、VMD-LSTM模型、VMD-CNN模型、VMD-AM-LSTM模型、CNN-LSTM模型、CNN-AM-LSTM模型、VMD-CNN-LSTM模型的预测效果进行比较。由表4可以看出,本文所提组合模型相较于ARIMA、SVR、LSTM、CNN单一预测模型,RMSE分别降低了80.1%、72.07%、56%、59.78%;MAE分别降低了84.82%、38.71%、59.85%、66.56%;MAPE分别降低了30.99%、32.11%、31.49%、18.3%。相较于VMD-CNN、VMD-LSTM、VMD-AM-LSTM、CNN-LSTM、CNN-AM-LSTM、VMD-CNN-LSTM组合模型,RMSE分别降低了35.31%、27.17%、0.76%、63.06%、71.47%、41.02%;MAE分别降低了44.82%、38.90%、2.23%、68.92%、76.01%、49.62%;MAPE分别降低了2.94%、2.82%、44.22%、22.1%、15.1%、6.32%。其中,与文献 [21] 中CNN-LSTM-lightGBM组合算法模型横向量化比较,RMSE、MAE和MAPE指标分别将降低了15.8%、35.2%、13.4%。与文献 [22] 中TPE-LSTM智能优化算法横向量化比较,RMSE指标降低了43.2%,MAPE指标略有差距,但本文所提出的组合模型在其他关键性能指标具有显著优势。
Table 4. Comparison of wind power prediction results of various models
表4. 不同模型风电功率预测结果对比
从图4可以明显看出,在风电功率变化较大的极点处,基于注意力机制的VMD-CNN-LSTM网络模型预测值更接近实际值,说明本文提出的网络模型具有在极端情况下更好地预测风电功率的能力。
多组实验结果分析发现,同一模型对同源不同规模的采样点具有更优的预测效果,通过使用本文提出的基于注意力机制的VMD-CNN-LSTM模型对1000个采样点间隔100个单位进行预测,对得到的10个不同的平均绝对百分比误差值进行分析。从图5误差的结果可以很明显的看出,在本文提出的模型中,同一模型对同源的不同规模的采样点的MAPE值在0.22%~0.31%之间,比同时预测9685个采样点MAPE值降低了42%~18.4%。
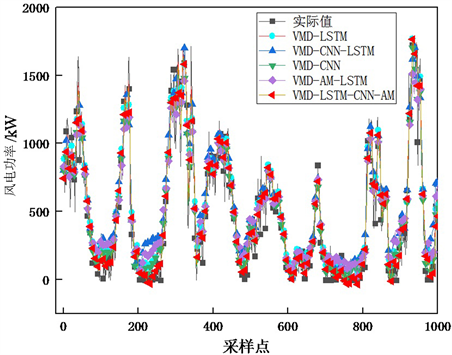
Figure 4. Predictions from different model
图4. 不同组合模型的预测结果

Figure 5. MAPE values of the same model homology at different scales
图5. 同一模型同源不同规模的MAPE值
为检验文中所给出模型的泛化性,分别选取夏季和冬季作为实验对象,如图6和图7所示。从图中可以看出,在夏季,风电功率变化较小,其MAPE值是0.2942。在冬季,风电功率变化较大,其MAPE值是0.2909。由预测结果可得,在夏季和冬季两种极端条件下,本文给出的模型的误差均小于传统神经网络预测方法。说明本文组合模型具备更强的泛化性能。
5. 结论
本文旨在解决当前传统物理机理驱动预测风电功率的方法中精确度不高和泛化能力弱的问题,提出了一种基于注意力机制的VMD-CNN-LSTM短期风电功率预测方法。
首先通过VMD变分模态分解实现对风电功率时间序列的固有模态分量的有效分解,克服了复杂且非线性强的时间序列问题。其次,引入CNN-LSTM组合网络模型提高了特征提取能力,解决了长依赖问题,并在组合模型中加入注意力机制模块进一步提高了预测精确度。通过斯皮尔曼相关系数特征分析法对气象和轴承数据的深入分析,对原始轴承数据进行了等级划分,降低了网络模型复杂度,提高了预测精确度。技术创新点在于综合运用VMD、CNN、LSTM和注意力机制,从而构建了一种在风电功率预测中具有显著优势的综合模型。研究结果表明,本文方法在提高预测精确度和泛化性能方面较传统方法更为优越,与组合算法CNN-LSTM-lightGBM以及TPE-LSTM模型横向相比,关键性能较为突出,说明了本文组合模型的先进性。然而,本文仍存在不足之处,包括缺少多个数据集进行多工况分析,未来研究方向可集中在优化模型参数的基础上,增加数据集多工况的对比,进一步提高并验证模型预测精确度和泛化能力。
实验数据
该文所有实验代码与结果可在 https://github.com/chyaou/VMD-CNN-LSTM-AM-wind-power-forecast.git获取。
基金项目
国家自然科学基金(62076215);教育部新一代信息技术创新项目(2020ITA02057);盐城工学院研究生科研与实践创新计划项目(SJCX22_XZ035、SJCX22_XY061)。
NOTES
*通讯作者。