1. 引言
近年随着互联网社交平台的推广和发展,越来越多人倾向于发布Vlog、Plog等方式记录和分享日常生活、户外运动、旅行等,相应所需电子设备的市场需求也在不断增加。与传统视频录制设备相比,运动相机具有体积小、重量轻、防抖、防震、便于携带等优点,可提供多场景环境下的高清视频拍摄和录制。在此背景下,运动相机市场的竞争日趋白热化,促使运动相机厂商加速产品的优化升级和调整产品的营销策略。为在激烈的市场竞争中胜出,提供更符合消费者及时需求的产品,短时间内把握与预测消费者需求偏好是商家竞争胜出的关键所在。伴随着互联网时代的到来与物流水平的提高,许多消费者倾向于通过在线电子商务平台购买商品。消费者可以通过电商平台购买产品、分享体验。消费者购买产品后,会在电商平台上对购买的产品的不同方面进行在线评论,如价格、性能、用户体验等。
在线评论包含文字、图像、表情和视频等多种内容。近年来,很多学者基于在线评论在很多领域开展了诸多研究,如消费者满意度、情绪分析、购买意向预测等等。Zhou等 [1] 根据词频统计计算指标权重,利用DIPCA算法动态评估客户满意度。Barta等 [2] 针对消费者的负面在线评论使用结构方程模型来研究差评的影响以及评论的感知说服力、有用性和可信度。Sim等 [3] 使用具有空间概率模型和卷积神经网络(CNN)来衡量在线评论对住宿预订意图的影响。Kim等 [4] 使用CONCOR方法聚类分析以及因子分析和线性回归分析进行定量分析,研究在线评论对顾客满意度影响。Zhang和Niu [5] 提出了一种新的基于长短期记忆交互的卷积神经网络(LICNN)模型利用在线评论来预测酒店需求。当前研究基于文本聚类等手段,针对在线评论文本的关键词来探索定性数据,或基于在线评论进行定量化数据处理。Pineda-Jaramillo J和Pineda-Jaramillo D [6] 使用来自在线评论的非结构化数据来预测城市地铁系统的出行满意度。Yadav和Sagar [7] 结合文本分析和社交网络方法,利用LDA模型进行主题分类,然后使用NetworkX进行网络分析。Zhu等 [8] 提出了一种基于论点质量和来源可信度的扩展信息采用模型,以研究与在线评论的感知有用性相关的因素。该模型以读者信任倾向为个体因素、产品类型为调节变量,构建了在线评论感知有用性相关因素的权变模型。
在线评论的情感分析是通过提取在线评论的文本中的情感倾向和情感倾向强度,绝大多数研究针对情绪分析进行分析挖掘。Zhang等 [9] 基于细粒度情感分析与卡诺(Kano)模型,完成了情感分析和需求识别的结合,最终得出消费者对产品属性的需求偏好。Zhang和Guo等 [10] 提出了一种将直观模糊TODIM (IF-TODIM)方法与情感分析相结合的产品选择模型。Wang等 [11] 使用多注意力双向LSTM来识别视频中消费者评论的情感极性,能更好地挖掘消费者在各个主题上的情感之间的关系。Obiedat等 [12] 提出了一种将支持向量机(SVM)算法、粒子群优化(PSO)算法和过采样技术相结合,对在线评论中存在的不平衡数据分布进行情感分析。许多研究对在线评论情感分析后没有对得出结果再进一步分析挖掘。Bhuvaneshwari等 [13] 基于双向长短期记忆自注意力卷积神经网络模型对用户评论进行情感分析。Lucini等 [14] 探索了基于客户满意度维度的航空公司推荐预测,基于贝叶斯分类器的情绪分析后使用逻辑回归模型预测航空公司的推荐。多模态情感分析领域的注意力机制法,能通过提取模态的关键特征提取情感分析的权重信息,进而增加模型准确度。Shi等 [15] 提出一种基于多尺度卷积神经网络和交叉注意融合机制的情感分析模型MSCNN-CPLCAFF,有效分析了抖音平台的视听和文本数据的跨模态特征融合问题。
目前研究在线评论中使用的模型,大多数研究人员倾向于使用机器模型和深度学习模型。沈超等 [16] 首先使用决策树分类模型来识别消费者偏好的关键和非关键属性。然后利用时间序列来分析非关键属性的未来重要性。Yakubu等 [17] 使用Shapley值和Choquet积分进行产品属性重要性识别研究,再使用模糊时间序列进行产品属性的变化趋势预测。挖掘与分析在线评论的机器学习模型,以支持向量机(SVM)、梯度提升、随机森林、逻辑回归和决策树等为主。Nilashi [18] 使用分类回归树(CART)模型进行客户偏好预测。Lee等 [19] 使用了四种机器学习算法对大型餐厅的在线评论进行对比研究和预测。Zibarzani等 [20] 使用学习向量量化(LVQ)算法对在线评论进行聚类分析,并使用分类回归树(CART)算法预测客户满意度和偏好。Hussain等 [21] 基于IOWA算子的自适应神经模糊系统,将预测模型与模糊C均值、减法聚类和网格划分相结合,对在线服务质量执行复杂的预测。Khorsand等 [22] 使用多种机器学习模型根据酒店和乘客的在线评论信息来预测入住率,横向比较了每种算法的结果。深度学习模型可以利用非线性激活函数提取在线评论中的特征向量和其相关联系,从而提高研究精度。研究模型以长短期记忆网络神经网络(LSTM)、递归神经网络(RNN)和卷积神经网络(CNN)等为基础。Wang等 [23] 通过深度神经网络预测消费者评论感知效用,选取BiLSTM模型和传统LSTM神经网络模型进行预测并比较2种模型的精确率。Jain等 [24] 选择四种机器学习模型预测乘客推荐,并用分层K折交叉验证来测试和验证模型,比较四种预测模型结果。Su等 [25] 提出卷积注意力–长短期记忆网络(CA-LSTM)模型,通过注意力机制和卷积运算从在线评论中获得真实的情感特征指标具有更好的分类性能。Chang等 [26] 用长短期记忆网络对在线评论的评分与文本进行情感分析,预测每月酒店入住率。Oh等 [27] 基于RNN处理酒店信息的分类变量,后使用LSTM模型处理在线评论文本信息和卷积神经网络提取酒店图像特征。Olmedilla等 [28] 使用一维卷积神经网络模型对在线评论有用性进行预测,此模型展示了对评论有用性的预测和分类的高性能。
纵观现有研究,在线评论研究多片面集中于消费者满意度、情绪分析、购买意向预测等其中一个方向,或只专注于模型优化,缺少针对在线评论整体深入挖掘研究。针对客户需求偏好的变化,多数研究止步于通过在线评论文本对客户的偏好需求进行满意度评价与总结,较少关注消费者偏好倾向动态发展趋势。偏好预测模型研究多集中于预测模型算法改进与优化方面,缺少对属性偏好维度动态变化的考虑,没有充分考虑消费者对于产品属性的情绪动态走向。研究大多数集中在消费者需求的获取、识别、映射与转化等方面,对于消费者多样化需求偏好的研究相对较少。面对消费者多样化和差异化需求时,厂商和电商在产品的生产和销售无法及时根据消费者需求调整策略方向。缺少以优化与升级产品性能为目的消费者的偏好倾向挖掘研究。在此基础上,本文在深入研究了产品在线评论文本挖掘、情感倾向分析、预测模型相关理论和研究现状后,提出消费者偏好预测模型构建,采用实证分析对用户评论进行了深入挖掘,得出消费者偏好未来趋势。
2. 模型构建
本文构建的模型主要包括三个部分,即偏好特征提取、偏好特征重要性计算和关键偏好特征筛选与预测。具体而言,首先进行情感倾向分析得出消费者情感倾向值,之后利用基于困惑度的LDA模型提取在线评论中包含的偏好特征,然后进一步使用信息增益法结合在线评分与情感倾向得出偏好特征的重要性。最后使用Lasso-SVM模型进行偏好特征的筛选与预测,如图1所示。
2.1. 偏好特征提取与情感分析
在线评论数据通常包含评论文本和客户对产品的打分。根据收集的大规模在线评论,本文首先采用Blei等 [29] 提出的生成式主题模型LDA法提取潜在产品属性词语,然后通过人工剔除其中常见的非属性词语,并对剩余潜在属性词语进行同义词合并,生成产品属性词典。LDA选取主题数量需要同时考虑模型构建的复杂性和数据信息的覆盖范围,本文引入困惑度来选取最佳主题数K,防止数据过拟合现象或信息缺失,具体计算公式如下 [30] 。
(1)
其中分母为数据集中所有单词之和。p(w)为数据集中每个词语出现的概率,其计算公式为:
(2)
其中p(z/d)为每个文档中各个主题出现的概率,p(w/z)为是词库中的各个词语在其中一个主题中出现的概率。
因为消费者的在线评论中有大量词语,一些出现频率低或者偏僻词语对于本研究属于噪声,设定上限可以剔除数据的噪声,之后把文本数据集中的词汇向量化,即将其转化为词频矩阵,再计算各个词频矩阵中每个词汇的TF-IDF权重,转化向量以及提取主题关键词。了解用户的看法需要通过评论文本得知消费者偏好倾向,因此需要进行情感分析。本文使用Python中的Snownlp模块,识别各个特征在每个出现评论中的情感倾向。
2.2. 基于信息增益法的偏好特征重要性计算
在产品设计术语中,信息熵可以表示为在数据集S中,区分一个类别和另一个类别的不确定性。在数据集U中,区分一个类别和另一个类别的不确定性。假设初始数据集U包含n条评论数据
,每条评论数据都有一个对应的类别
,则初始数据集(包含所有特征)的信息熵为:
(3)
其中,p(cr)表示数据集U中的类变量cr的概率,k表示类变量的个数。
本文的类变量包含三个:c1到c3分别表示评分的高、中和低。为了确定最大能力的偏好特征,减少选择集的不确定性,根据偏好特征变量的取值划分为n个子数据集。给定一个特定的偏好特征a,信息熵是该偏好特征的每个唯一值的信息熵的总和为:
(4)
其中Uj表示训练数据U的子集,包含属性的互斥结果值,|∙|表示集合所包含的元素个数。本文的偏好特征有三个互斥结果值(高、中和低),则训练集U将被划分为三个数据子集,U1将包含偏好特征值为高的所有数据实例。根据前文,本文将消费者对商品的评分(高、中、低)作为类变量,视为消费者满意程度,结合偏好特征情感(正面,负面和中性),运用信息增益方法计算每个偏好特征对于客户满意度的影响大小。因此,偏好特征a的信息熵为:
(5)
其中U+、U−和U0分别表示产品属性a为正面、负面以及中性的评论。
之后,计算信息增益值。信息增益越大,说明该词语特征含有的信息量就越大,也就是该偏好特征越重要,即属性a的Entropya(U)越低,其增益IGF越高,这两者的关系可表示为词语特征的信息增益等于初始信息熵减去已知词语特征的信息熵,计算公式如下:
(1)
根据公式(6)可以计算每个产品属性的信息增益。根据信息增益IGF的值,将所有偏好特征的信息增益值按照从大到小排序作为偏好特征重要性排序,以及下一步偏好趋势分析的输入值。
2.3. 基于Lasso-SVM模型的关键偏好特征趋势分析
为了获得更加客观和细致化的用户偏好趋势特征,本文在偏好趋势分析的分析中使用Lasso与SVM模型相结合预测特征趋势。SVM模型进行长时间序列预测上具有较强的精度。增加Lasso算法进行偏好特征的筛选,剔除了对于消费者未来购买行为不产生影响的偏好特征,减少不相干偏好特征对模型精度的干扰,从而改善建模品质。
Lasso算法 [31] 可以将不相关的自变量收缩为零,以此达到优化回归模型中的多重共线性问题。Lasso通过对最小二乘估计加入L1范数作为罚约束,使某些系数估计为0,减少参数数量。使用Lasso回归,剔除相关性较小的因素,对消费者偏好进行筛选,是基于惩罚方法对数据进行变量选择,通过对原本的系数进行压缩,将不显著的变量系数压缩至0,再将此类特征直接舍弃,Lasso回归预测模型目标函数表示为:
(7)
式中:RSS是实际值减去估计值的差的平方和;β是参数向量;λ是调优参数;p为参数个数。根据式(7)可知,由于Lasso回归模型的目标函数包含惩罚项系数λ,故在计算模型回归系数前,需要得到最理想的λ值,λ值的确定可以通过定性的可视化方法和定量的交叉验证方法。在本文中,将偏好特征的信息增益值作为向量X1到Xn,将消费者每条评论类型的信息熵作为Y值输入Lasso模型中,将结果中向量X1到Xn的向量系数为0的偏好特征剔除,将筛选后的特征向量输入SVM时间序列预测模型中。
支持向量机(SVM)是一种监督学习的分类方法。它在解决小样本、非线性和高维模式识别方面具有许多独特的优势,可广泛应用于函数拟合等机器学习问题。其原理和解决过程如下:
给定一个包含两类数据的样本数据集:
(8)
则支持向量机判别函数为:
(9)
其中:
(10)
i为支持向量个数,本文中i作为偏好特征向量个数,
为核函数。将样本数据集V作为训练集输入后,根据实际数据集选取核函数与惩罚因子求解优化问题的最优解向量 。本文将Lasso筛选过的偏好特征向量分别作为特征向量输入SVM中,通过已有的1至N阶段作为时间序列值,对第N + 1阶段进行预测,之后将得到的N + 1阶段作为已知数据,将第2至N + 1阶段再次作为时间序列值,对第N + 2阶段进行预测;以此类推,预测未来3期的趋势走向。因此,本研究所使用的Lasso-SVM方法,首先使用Lasso方法进行变量选择,得到特征变量;然后使用支持向量机作为分类器,利用式(9)对特征变量进行训练。并采用k倍交叉验证方法对预测模型的性能进行检验。
3. 实证分析
3.1. 数据收集及预处理
本文选取运动相机为研究对象,从京东收集了销量排名前20的运动相机的所有评论内容,共计收集到15,301条评论运动相机的在线评论,数据的时间跨度从2020年1月到2022年12月。每条评论主要由评论者名称、评价星级、评论内容、评论时间、商品属性、评论类型等组成。一些例子如表1所示。

Table 1. Examples of online reviews of action cameras
表1. 运动相机在线评论示例
消费者在电商平台上发布的在线评论一般含有很多噪声,比如一些重复评论、无意义符号、外语单词等,这些噪声对于研究过程和最终结果都有干扰,需要除去数据的噪声,再进行后续研究。故在使用LDA模型前需要将所获取的数据进行预处理。本文通过Python的pandas模块,利用drop_duplicates方法进行数据去重,最终得到15,296条评论文本。再将jieba文包导入Python,进行文本清洗以及文本分词。处理后的示例如表2所示。
Table 2. Data preprocessing example
表2. 数据预处理示例
3.2. 在线评论偏好特征识别
3.2.1. 偏好特征提取
本文使用jieba文包以及sklearn工具包通过LDA模型进行偏好维度的提取。
其中主题数目和困惑度折线图如图2所示,由图得,当主题数目为4时,达到折线最低点,因此最佳主题数K = 4。将K = 4代入LDA模型,求出每个主题前20个关键词如表3。
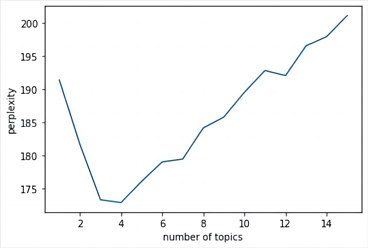
Figure 2. Line chart of topic number and perplexity
图2. 主题数与困惑度折线图
Table 3. Keywords of online reviews
表3. 在线评论关键词
结合表3和图2,主题1主要反映运动相机的使用功能;主题2主要反映平台的服务体验;主题3主要表现消费者对相机的使用体验感;主题4表现运动相机的使用场景。综合来看,4个主题无重叠,拟合较好。
3.2.2. 情感分析
本研究使用snowNLP库自带字典进行分析,并设情感得分大于0.6为正向情感倾向评论,0.6到0.4之间为中性情感倾向评论,小于0.4为负向情感倾向评论。限于篇幅,展示部分文本情感得分如下表4所示。
Table 4. Emotion score of online review text by emotion orientation
表4. 各情感倾向在线评论文本情感得分
经过情感分析算法分类,共得11,307条正面情感评论、3053条中性评论和936条负面情感评论。由于京东商城在线评分采用5星制原则,为了便于对比,本文将5星作为正向倾向,4星与3星作为中性情感倾向,2星与1星作为负向倾向。将得出的情感倾向性估值与在线评分对比,将情感倾向与评分不一致的数据剔除,剔除458条数据,最终留下14,838条有效评论。
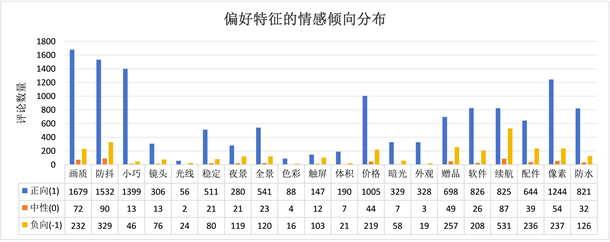
Figure 3. Distribution map of emotional tendency of preference characteristics
图3. 偏好特征情感倾向分布图
基于前文的偏好特征识别以及情感分析法,本案例研究识别出20个消费者偏好特征的情感分布,偏好特征的情感分布情况如图3所示。可以看出消费者对大多数偏好特征持有正向情感倾向,“画质”、“防抖”和“体积”等偏好特征是消费者关注较多的偏好特征。而消费者对于“价格”、“电池”和“配件”的负面情感较多。以“体积”为例,在所有评论中共筛选出包含“体积”的评论1611条,其中正面情感评论数1005条。
3.2.3. 偏好特征筛选与趋势分析
本文采用3年的在线评论数据,共计有效评论16,388条,从2020年1月到2022年12月,分为12个阶段,每个阶段代表1个季度。将处理好的数据集划分为12节时间段,使用信息增益法分别计算每节时间段偏好特征重要性,下面表5展示了部分偏好特征信息增益值。
使用Lasso-SVM模型进行消费者偏好特征的筛选。本文采用sklearn子模块linear-model中的Lasso类中目标函数所包含的惩罚项系数进行计算,采用5重交叉验证的方法得到Lasso的最佳的λ值,Lassoλ = 6.421185709064758e − 07。最后基于最佳的λ值分别得到Lasso模型变量系数,经过Lasso筛选后,相关系数输出结果如表所示,可看出可知中,发现特征X4、X7、X7、X9、X11、X12其变量系数值为零,将这6个偏好特征剔除,最终筛选得到10个关键偏好特征,如表6所示。
Table 5. Information gain value of preference feature
表5. 偏好特征信息增益值
Table 6. Lasso regression output values
表6. Lasso回归输出值
将Lasso筛选过的偏好特征向量分别作为特征向量输入SVM中,通过已有的1至12阶段作为时间序列值,对第13阶段进行预测,之后将得到的13阶段作为已知数据,用2至13阶段预测第14阶段;以此类推,预测未来3期,如下图4所示。

Figure 4. Trends and predictions of the importance of preference features
图4. 偏好特征重要性的趋势与预测
图4展示了“像素”、“夜景”、“体积”、“配件”和“全景”属性在12个阶段的变化趋势以及未来3阶段预测值。可以观察到“夜景”和“像素”整体信息增益值较高;“全景”在4、6阶段信息增益值增长明显;“配件”在第4期达到峰值随后逐渐下降;“体积”的信息增益值较低,但呈现缓慢上升趋势。以未来3阶段预测值为未来消费者偏好走向,则未来消费者对于“配件”方面的偏好在短暂上升之后继续下降趋势,“像素”和“体积”的偏好在上升。针对“配件”,消费者对于运动相机配件的偏好度在4期到8期关注度较高,说明在这几个阶段,电商平台上的运动相机的配件参差不齐,而随着时间的推移,大部分的运动相机配件在逐渐改良,这是厂商对相机配件不断加强重视的结果,在13到15阶段消费者偏好度短暂升高后继续降低,因此未来一阶段厂商不需要将大量的资源集中于相机配件的提升。
4. 讨论
本文将文本聚类、情绪分析与偏好预测结合起来,针对在线评论文本进行消费者偏好预测挖掘。构建的模型适用于电商进行消费者产品偏好趋势分析与预测,从而更好的针对产品属性进行调整优化,使其更符合消费者未来购买倾向。同时以实际在线评论为例验证其有效性,进而帮助商家更加了解用户的不同偏好和变化,了解影响消费者购买行为的影响因素、关系和程度,更加合理精准地制定营销策略,提高营销效果。
本文使用情感分析以及LDA模型挖掘消费者情感倾向与偏好特征,在此基础上使用信息增益法与Lasso算法等改进SVM预测法来进行消费者偏好趋势预测,补充了当前文献中将文本分析、情感分析与偏好特征趋势分析结合起来的空白。本文也扩展了偏好特征提取相关研究,绝大多数研究使用LDA模型倾向于进行客户市场细分、主题提取等方向,本文使用LDA进行偏好特征的提取,增加了LDA模型的使用方向。此外,大部分研究的预测倾向于使用机器模型或者深度学习模型,本文在SVM模型基础上使用Lasso模型进行偏好特征筛选也为未来研究提供了新思路。
消费者的在线评论不仅包括评分和文字,还包括一些表情符号和一些图片和视频。因此,将来在提取消费者偏好特征的过程中需要扩大自变量维度,更全面地分析消费者偏好倾向。同时在进行情感分析时,权重评分分配和分层也比较简单,未来可与情感细粒度分析相结合使偏好维度的情感评分更加真实。此外,本文在研究过程中舍弃了一些偏好维度。这些偏好维度在情感倾向上没有明显的波动,但可能对消费者的偏好倾向产生隐性影响。在未来的研究中,我们可以挖掘和预测这样的偏好维度,以探究它是否对消费者偏好产生影响。