1. 研究背景
脑中风又称脑卒中,是一种急性脑血管疾病。脑中风是由脑部血管破裂或是血管堵塞导致血液无法流入大脑而引起的一种脑组织损伤疾病,其包括两种:缺血性以及出血性卒中。其中,缺血性卒中的发病比例略高于出血性卒中的发病比例,大概占总发病比例的60%~70%。常见的缺血性卒中多发生在年龄40周岁以上的老年人,颈内动脉和椎动脉闭塞常常是引发老年人缺血性卒中的主要原因。相较于缺血性卒中而言,出血性卒中的危害更加明显,死亡率远高于缺血性卒中。
目前,脑中风已经一跃成为我国致死原因第一位,也是我国成年人残疾的首要原因。对于脑中风的治疗,目前而言预防是最为主要的措施,而高血压是导致脑中风的重要因素之一,因此对于血压的观测应是脑中风患者的重中之重。
关于脑中风的研究,目前国内已有许多学者发表了许多文献研究。刘艳娇 [1] 通过临床流行病学方法研究了肥胖人痰湿体质与脑中风的相关性并证明了肥胖人痰湿体质是引发脑中风的相关因素之一。赵孔华与张沁园 [2] 通过对缺血性脑中风的研究分析出其发病机理以及治疗原则。杜恩 [3] 通过老年脑中风患者观察组与对照组的比较说明了早期康复治疗对于老年脑中风偏瘫患者的重要性。甘勇、杨婷婷以及刘建新等人 [4] 通过对脑中风的研究,分析出了影响脑中风的主要因素。本文选取了该篇文献内的相关指标来使用Logistic回归模型得到几个重要影响因素。
2. 广义线性模型
2.1. 模型介绍
在数据分析的过程中,很多分析方法和模型往往要求目标变量(数据)服从某些假设如正态分布、方差齐次等。一般来说,如果数据不能服从这些假设,那么采用对应的方法或模型获得的结果往往不可信。例如,我们经常使用的经典模型,即形如y = kx + b的一般线性模型就要求数据(目标变量)必须满足正态分布和残差的方差齐次。然而,在实际科研工作中,很多数据往往不能满足以上条件。这种情况就要求我们寻找一种没有以上假设的方法来替代存在假设的模型如:一般线性模型。此时就产生了广义线性模型(GLM)。
在统计学中,广义线性模型(GLM)是普通线性回归的灵活概括,它允许响应变量具有除正态分布以外的误差分布模型。GLM通过允许线性模型通过链接函数与响应变量相关,并允许每种度量的方差大小成为其预测值的函数,从而推广线性回归。广义线性模型由John Nelder和Robert Wedderburn制定,作为统一各种其他统计模型的一种方式,包括线性回归,逻辑回归和泊松回归。他们提出了一种迭代重加权的最小二乘方法,用于模型参数的最大似然估计。最大似然估计仍然很流行,并且是许多统计计算包上的缺省方法。其他方法,包括贝叶斯方法和最小二乘拟合方差稳定响应,已经开发出来。
线性回归模型主要适用于因变量为连续性(特别是服从正态分布)的随机变量的情况,GLM通过一个已知的连接函数将因变量的数学期望与自变量的线性函数连接起来,并将因变量的分布由正态分布推广到广义指数分布族,GLM可以处理因变量为一些离散型、连续性随机变量的回归问题。
在线性回归模型中,设因变量Y与自变量 的n组观测值:
,其有两个基本要素:
相互独立,服从同方差的正态分布
;
,通常取
。
的n组观测值:
,其有两个基本要素:
相互独立,服从同方差的正态分布
;
,通常取
。
在广义线性模型中,将
的分布由正态分布推广到指数族分布;将
推广到它的一个单调、可微函数(称为连接函数)
,使得
。
称随机变量
满足广义线性模型,如果:
相互独立且服从指数族分布;对于某单调、可微的连接函数
,有
,其中
。指数族分布包含诸如二项分布、Poisson分布、正态分布、Γ分布等常见的离散型和连续性分布。对指数族分布的定义为,若Y (一元)概率分布(离散)或概率密度(连续)有如下形式:
,其中
为已知连续函数,
称为自然参数(表示位置),
称为散度参数(表示尺度),则称Y服从指数族分布。通常,
与
有关,是我们所感兴趣的参数,
与
有关,通常作为多余参数。
一般连接函数是,连接函数
是将自变量第i组观测值的线性组合
与
联系起来的函数,即
。常见的连接函数有:对数函数,
;Logit或Logistic函数:
;Probit函数或Gauss函数:
;重对数函数:
;互补重对数函数:
。
典型连接函数是随机变量Y服从指数族分布,典型连接函数
满足
。此时,
,
。
当
:
,典型连接:
;
:
,典型连接:
;
:
,典型连接:
,即Logit (或Logistic)函数;
:
,典型连接:
。
设
为因变量Y和自变量
的观测值,若:
相互独立,且对每个i,
服从指数族分布:
;
其中
,则称Y与
服从广义线性模型(GLM)。
广义线性模型有十分广泛的应用背景,例如:研究人类某种疾病的发病率与人的性别、年龄、家庭经济情况、职业、自然环境情况等的关系,我们可以用典型连接函数创建Logistic模型,通过检验
是否显著为0,了解哪些因素是影响该疾病发病率的主要因素,各因素影响发病率的强度等等。还可以研究某地区在某时段内矿难发生次数与矿山类型、企业类型、企业管理水平、企业规模、安全资金投入等等因素的关系,我们可以建立Poisson模型或者对数线性模型来分析。
2.2. GLM的极大似然估计
设有数据:
,
服从参数为
和
的指数族分布,其概率分布或密度:
。设
,选定连接函数
,考虑广义线性模型:
。
求参数
的最大似然估计,
的对数似然函数为:
由于
通过
与
相联系,而
与
无关,所以
的最大似然估计即是下列方程组的解:
,
,
,
。
利用链式求导法则得:
代入似然方程得
,其中
。对很多有重要应用背景的指数族分布,有
,
已知。这时似然方程为
。
讨论一般情形下的似然方程的迭代最小二乘解。
。在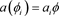 的情况下,似然方程为
。令
,则
,由于
,因此
的情况下,似然方程为
。令
,则
,由于
,因此
。
从而有:
从而似然方程变为
,
。
若
已知,则
的加权最小二乘估计为
,其中,
,
,
。
实际上,Z是未知的,可用迭代加权LS法:
1) 给定
的一组初值
,比如
2) 计算
的初值
3) 由
,计算
,
的初值:
,
,
,
。
计算
的第一次估计:
4) 令
,这里
,
。由
,根据3)计算得
,
,由此求得
的第二次迭代估计:
5) 重复上述步骤得
的迭代估计式:
,直到
收敛。
3. Logistic模型
3.1. 模型
Logistic模型最早在20世纪四五十年代由Berkson,Dyke和Patterson等人使用过。当因变量Y是0~1变量(二值变量)时,即Y表示分两类的类别,用取值1和0表示,将取值1称为成功,我们关心的时成功的概率
。这是一个[0, 1]区间内的值。如果把Y当作一般因变量做线性回归,会给出不合理的结果,比如负值,另外线性回归假定误差项为正态分布在这里也不适用。
如果Y是m次试验中成功的次数,这时可以设Y服从二项分布B(m,p),关心的是成功概率p,也可以归入相同的模型。
为此考虑对应于二项分布的广义线性回归模型:
,
其中m为试验次数,Y为m次试验中成功次数,p为给定
条件下的成功概率。一般取联系函数
为Logit函数
。此模型称为Logistic模型,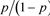 是成功概率与失败概率的比值,称为发生比。
称为对数发生比。
是成功概率与失败概率的比值,称为发生比。
称为对数发生比。
Logistic模型有如下的模型假定:因变量表示成败型结果,为零一变量或者已知试验次数中成功次数;各个观测独立;如果某个观测的试验次数为m,成功概率为p,则因变量方差为mp(1-p),方差不等于常数值,与期望值mp有关系;对数发生比
与自变量之间为线性关系。
3.2. 最大似然估计
考虑观测的因变量是二值因变量情形。数据为
,一个观测对似然函数的贡献为:
,其中
,对数似然函数为:
需要用数值迭代算法求最大似然估计。若样本为满足模型的随机样本,最大似然估计是相合估计,渐近有效估计,具有渐近正态分布。得到最大似然估计
后,一般用信息阵的逆矩阵估计其协方差阵,信息阵为:
在用数值迭代算法计算最大似然估计时,一般会得到最大值点处的对数似然函数的海色阵,加上负号并求逆矩阵,就可以作为参数协方差阵估计。有了参数估计的协方差阵估计,就得到了参数估计的标准误差。设参数估计为 ,估计的方差开平方根作为其抽样分布标准差估计,称为标准误差,记为
。令
,可以用Z统计量检验
,在
成立,大样本且满足适当正则性条件时近似服从标准正态分布。也可用
近似服从
分布进行检验。这样对回归系数进行的检验称为Wald类型的检验。此检验对中小样本有一定缺陷,参数的实际数值绝对值较大时,容易错判成不显著。另一种可用的方法是利用偏差统计量的方法。
,估计的方差开平方根作为其抽样分布标准差估计,称为标准误差,记为
。令
,可以用Z统计量检验
,在
成立,大样本且满足适当正则性条件时近似服从标准正态分布。也可用
近似服从
分布进行检验。这样对回归系数进行的检验称为Wald类型的检验。此检验对中小样本有一定缺陷,参数的实际数值绝对值较大时,容易错判成不显著。另一种可用的方法是利用偏差统计量的方法。
4. 数据选取、预处理与描述
根据世界卫生组织(WHO)的数据,中风是全球第二大死亡原因,约占总死亡人数的11%。从kaggle上选取脑中风数据集,共有5110条数据,包含id、性别等共12个指标。脑中风数据集包含指标如表1所示。
首先BMI中存在的缺失值删除。将性别指标中的男性改为1,女性改为0,由于只存在一例其他性别,并且女性有2994人,男性有2115人,因此将其设为人数较多女性,这样不至于使误差过大。婚姻状况上,未婚改为0,曾今结过婚改为1。工作类型上,孩子、政府工作、从不工作、私人、自由职业分别对应设置为1~5。居住类型上,城市改为1,农村改为0。在吸烟状况上,曾经吸烟、从不吸烟、吸烟、不明分别对应设置为0~3。
查看处理后数据中的脑中风情况,如图1所示。
在4909条数据中,脑中风的人数有209人,占比为4.26%。没有脑中风的有4700人,占比为95,74%。在分性别查看患脑中风的情况,如图2所示。
对于选取的2898名女性中,患脑中风的人数为120人,占比为4.14%。选取的男性人数为2011人,患脑中风的人数为89人,占比为4.43%。可以看出,男性、女性患脑中风的比例相差并不是很大,男性要稍微高一点。
再按年龄来看脑中风情况,如图3所示。
我们可以看出,脑中风现象大约是从30岁开始少量出现,并且随着年龄段的增加,脑中风的人数也逐渐增加,50~80岁之间为脑中风的高发年龄段,同时,脑中风率也有增高的趋势。
再按高血压分类来看脑中风情况。如图4所示。
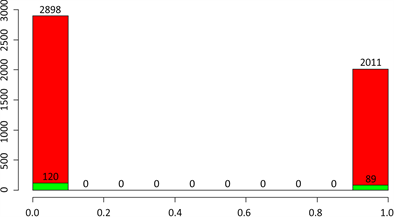
Figure 2. Number of cerebral strokes by sex
图2. 按性别分类脑中风的人数
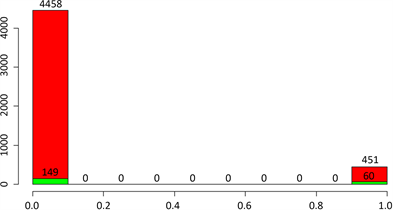
Figure 4. Cerebral stroke classified by hypertension
图4. 按高血压分类的脑中风情况
不患有高血压的4458人中,有149人患了脑中风,比例为3.34%,患有高血压的451人中,有60人患了脑中风,比例为13.3%。可以看出,患有高血压的人群得脑中风的比例比不患高血压的人得脑中风的比例高很多,高了约有10%。
再按心脏病分类来看脑中风情况。如图5所示。
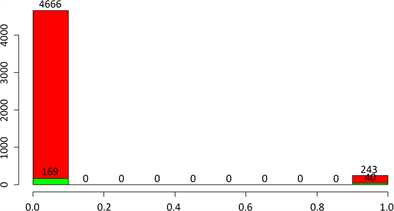
Figure 5. Cerebral stroke classified by heart disease
图5. 按心脏病分类的脑中风情况
不患心脏病的4666人中,有169人患了脑中风,比例为3.62%,患心脏病的243人中,有40人患了脑中风,比例为16.46%。可以看出,患有心脏病的人群得脑中风得比例比不患心脏病的人得脑中风的比例高很多,高了约有13%。
再按结婚状况分类来看脑中风情况。如图6所示。
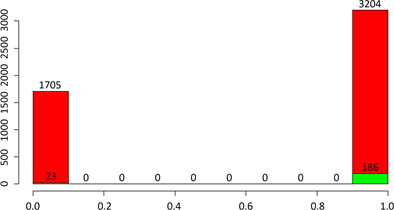
Figure 6. Cerebral stroke classified by marital status
图6. 按结婚情况分类的脑中风情况
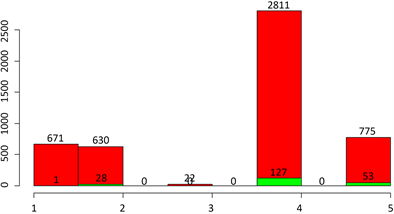
Figure 7. Cerebral stroke classified by type of work
图7. 按工作类型分类的脑中风情况
在未婚的1705人中,只有23人患了闹中风,比例为1.35%,曾经结过婚的3204人中,有186人患了脑中风,比例为5.8%。可以看出,结过婚的人患脑中风的比例要比未婚的人高,这可能主要是和年龄有关,曾经结过婚的人一般年龄较大,而未婚的人年龄较小。
再按工作类型分类来看脑中风情况。如图7所示。
可以看到,各个工作类型的人数分别为671,630,22,2811,775,他们的脑中风情况分别为1,28,0,127,53,比例分别为0.15%,4.44%,0,4.51%,6.84%。可以看到,小孩与从不工作患脑中风的比例最低,几乎为0;自由职业者患脑中风的概率最高,约有7%;政府工作与私人工作的患脑中风的比例相差不大,都约为4.5%。
再按居住地类型分类来看脑中风情况。如图8所示。
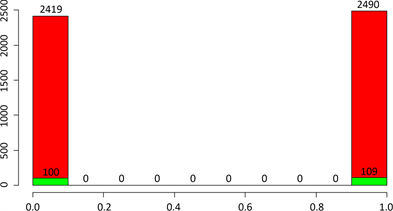
Figure 8. Cerebral stroke classified by type of residence
图8. 按居住地类型分类的脑中风情况
可以看到,居住在城市和农村的人都差不多,得脑中风得人数与比例也都差不多。
再按血糖水平来看脑中风情况。如图9所示。
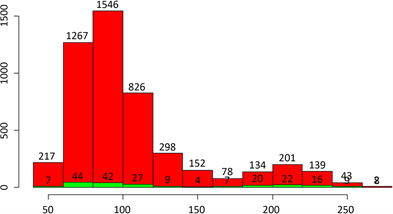
Figure 9. Cerebral stroke classified by blood sugar level
图9. 按血糖水平分类的脑中风情况
可以看到,血糖水平基本都集中在50~150之间,约有4306人,患脑中风的有133人,占比为3.08%,血糖水平150以上约有603人,患脑中风的有74人,占比为12.27%。可以看出,血糖在170~250之间脑中风率较高。
最后是BMI与吸烟情况,对于BMI,各区间患脑中风的比例都约为3%~5%,相差不大。各吸烟情况得脑中风的比例也都相差不大,在6%左右。
5. 模型建立与结果
首先我们通过相关系数查看各自变量之间的线性关系。如图10所示。
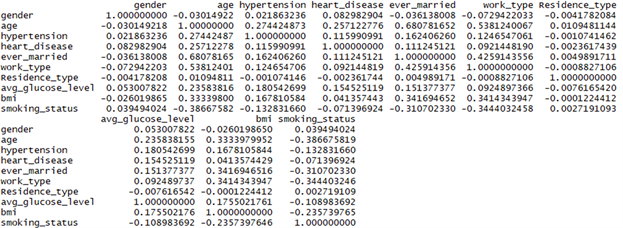
Figure 10. Correlation coefficient of each variable
图10. 各变量相关系数
可以看出,曾经结婚与年龄的相关系数最大,为0.68,还没有达到0.8,不是很强。对于连续型变量来说,年龄越大,血糖的水平较高的人数越多,但总体仍是血糖水平较低的人数多,相关系数为0.23。年龄和BMI之间存在弱相关关系,BMI和血糖水平之间关系不大。再根据之前的描述性统计,工作类型为1、3的为一个水平,2、4的分为一个水平,5为一个水平,所以将它们分为3类。
对其建立广义线性模型中的Logistic回归,结果如图11所示。
年龄、高血压、心脏病、工作类型和平均血糖水平都通过了显著性检验,与之前的描述性统计相符。在未通过显著性检验的变量中,只有曾经结婚与我们的描述性统计量不符。
由此我们可以得到初步的经验回归方程为:
继续进行逐步回归。逐步回归的结果建议我们选取年龄、高血压、心脏病、工作类型和平均血糖水平。对这五个变量和脑中风进行Logistic回归。结果如图12所示。

Figure 12. Regression result of Logistic after selecting the variable
图12. 选择变量后的Logistic回归结果
所有回归系数在0.1的显著性水平下都通过了检验,并且AIC值较之前有所降低。但是心脏病得系数还是不够好,这可能是由于样本中患有心脏病得人比例太少了,仅有243人,而且是两点分布,总人数却有4909人,相较于其他指标,人数是比较少的。我们可以得到经验回归方程:
我们可以看出,随着年龄的增加、平均血糖水平的升高,患脑中风的概率也增加,患高血压与心脏病也会增加患脑中风的概率,对于三个水平的工作类型,即孩子、从不工作;私人、政府工作;自由职业,患脑中风的概率也随之降低。
以一个50岁,不患高血压,职业为政府工作,血糖水平为120的人比较其是否患心脏病得脑中风得概率。如果其没有心脏病,则患脑中风得概率为3.5%,反之,患中风得概率为2.4%,有了显著得降低。
6. 结论
年龄、高血压、心脏病、工作类型、平均血糖水平对于判断患脑中风的概率有着显著的影响,年龄是我们不可改变的,工作类型由于生活需要也是不能随意改变的,但是高血压、心脏病、平均血糖水平却可以靠我们自己来改变。在日常生活中多锻炼,多吃一些清淡食物,养成良好的生活习惯,可以有效降低患脑中风的概率。