1. 引言
近年来,随着社交软件的普及,人们开始在微博、Twitter和Instagram等社交媒体上用日记记录事件 [1] ,同时由于传感技术和位置感知技术的进步,使得人们对事件的记录更加方便准确,记录的信息也更加丰富 [2] 。因而对于生活日志的分析已经成为一个重要的研究方向。目前,Lifelog已经被应用于许多领域的研究中。在医疗方面,Lifelog已被用于查看肥胖患者的行为变化,以进行体重管理 [3] ;使用抑郁症患者的Lifelog数据来预测他们抑郁症复发的风险 [1] ;通过Lifelog查看患者健康状态 [4] 。在社会生活方面,利用Lifelog中记录的位置信息对个人的移动情况进行分析 [5] [6] ;使用地理标记照片数据集识别用户的重要位置和日常行为 [7] ;使用个人信息型生活日志数据自动生成故事模型 [8] 。Lifelog数据内容丰富多样,为了提高管理效率,对其进行合理分类显得尤为必要。Lifelog中包含大量对日常行为的描述,根据这些行为对其分类是一个很好的分类方式。通过分类,我们能更有条理地整理个体的日常活动。
目前,常用的文本分类机器学习算法主要有朴素贝叶斯(NB) [9] ,K最近邻(KNN) [10] 和支持向量机(SVM) [11] 。但这些方法忽略了文本数据中的上下文信息,导致语义信息无法准确表达,同时存在时间成本较高等问题,影响分类效率。近年来基于深度学习的文本分类方法引起了人们的广泛关注,Kim等人提出了TextCNN的分类模型 [12] ,该模型采用卷积操作对文本局部特征进行提取,取得了不错的效果;王佳慧等 [13] 将CNN与Bi-LSTM混合模型,有效提升了中文文本分类准确性;杨阳等采用融合词向量的方法来提高文本分类精度 [14] ;AK Sharma等人通过融合Word2Vec技术,同时对CNN模型进行微调来提高分类的准确性 [15] 。由于生活日志是人们随手对生活的记录,因此存在词汇不规范、以及语义模糊的问题,现有的文本分类模型大多基于文本内容本身,通过提高挖掘文本语义能力来提高文本的分类效果,但这对于语义表达不规范的生活日志来说分类效果的提升是有限的。因此本文提出了融合地理位置特征和主题特征的生活日志文本分类模型DTC-TextCNN,通过利用用户发送动态的地理位置这一空间信息,从而更为准确的表示出句子的语义,在一定程度上弥补了语言表达模糊以及不规范的问题,同时引入主题模型,弥补了CNN模型对于全局文本语义缺失的问题。
文章的组织结构如下:第一节介绍了Lifelog的发展以及常用的分类方法,第二节介绍了我们的Lifelog项目及使用的数据集,第三节介绍了DTC-TextCNN模型的构建方式,第四节对模型结果进行评价,最后进行了总结和评论。
2. Lifelog项目和数据集
2.1. Lifelog项目
我们团队从2011年开始有计划地收集个人Lifelog数据。目前已经有22位志愿者参与到这个项目中,在过去的11年,几乎每一天都会记录一次数据,收集到的有效Lifelog数据超过4万条。志愿者可以登录我们团队开发的App,随时随地记录个人生活,存留下每一个精彩瞬间。图1是我们的开发的APP界面。
APP会根据用户当前位置通过百度API自动记录用户的地里位置信息。每一条Lifelog数据记录了基本的位置信息(经度、纬度)、个人活动信息(行为描述)和显示信息(图像或视频)。为了更好将文本数据用于科研,当用户上传行为描述文本时,系统会自动将中文转换为英文。
用户不会在特定的时间发布动态,因此Lifelog数据集是典型的非连续的,包含标注等丰富信息的数据集。现在任何人都可以在我们的网站(www.lifelog.vip)上免费的获取已经公开的Lifelog数据,也可以免费下载这个App,从而参加到我们的项目中。图2展示了我们Web页面端收集的数据集。
2.2. 数据集
本文选取Lifelog数据集中用户Liu在2011年至2022年间发表的9000余条Lifelog数据作为数据源,在后文中我们称其为Liu Lifelog数据。表1展示了Liu Lifelog中的部分数据。其中Num为每一条数据的序号,Lon和Lat分别为用户发送动态时所处地理位置的经度和纬度信息,Description为用户所发动态的文本描述,Behavior为动态的所属类别,Time表示发送动态的时间。
收集到的Liu Lifelog数据中可能包含噪音,或是存在不一致、不完整等问题,直接进行训练可能对建模效果产生不良影响。因此,必须对数据进行预处理从而提高数据的准确性,以确保在模型训练过程中更好地捕捉和理解文本信息。
l 删除空值:用户在某些时刻选择只上传图片、像音频类的文件,而未进行任何文本描述,这些记录的Description文本字段为空,因此我们选择剔除掉这些文本数据为空的记录。
l 删除标点符号以及特殊字符:在文本中,标点符号以及包含的一些特殊字符,如HTML标签,表情符号等,这些符号对于文本分类来说没有实际意义,需要将它们从文本中删去。
l 大小写转换:确保文本数据中的字母大小写是一致的,有助于消除由于大小写不一致而可能导致的混淆和误解。在文本数据中,同一个词可能以不同的大小写形式出现,例如“Rest”和“rest”。如果不进行大小写转换,模型可能会将它们视为不同的特征。因此,我们将Liu Lifelog中所有文本数据转换为小写形式,从而消除由于大小写不一致而可能导致的混淆和误解。
l 去除停用词:在文本中经常出现没有实际意义,但是出现频率较高的词语,例如“a”、“the”等。这些词语不仅会增大计算量,还可能会影响模型的效果,因此,需要将他们从数据中剔除。
经过上述对数据的预处理后,我们过滤掉了Liu Lifelog中缺失或不完整的数据。同时由于other类型的数据表意不明,我们选择将这些具有干扰性的数据去除。最终,我们得到了8个种类的Lifelog数据,即ork in school、work outside、chores、rest、on road、meal outside、entertainment、tourism。
3. DTC-TextCNN模型
3.1. DTC-TextCNN模型框架
为了解决Lifelog领域中数据分类问题,我们提出了DTC-TextCNN文本分类模型。模型对用户发布的文本描述进行主题特征提取,对经度和纬度信息进行聚类,将不同的地理位置分配到不同的簇中进而得到地理位置簇特征。最后,将用户发布的文本描述、文本的主题特征和地理位置特征拼接,输入到TextCNN中进行分类。图3为DTC-TextCNN模型的流程图。
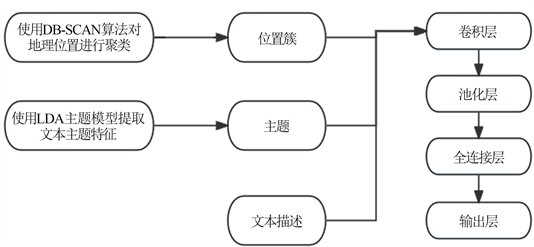
Figure 3. DTC-TextCNN model flowchart
图3. DTC-TextCNN模型流程图
3.2. DTC-TextCNN模型特征提取
用户在相同地点发布的动态内容可能呈现较高的相似性,因此考虑将地理位置作为一个重要特征纳入模型,以增强对动态内容的分类能力。同时由于用户在同一个地点所发出的动态包含的经度纬度信息可能具有一定的偏差,因此我们使用DB-SCAN算法 [16] 对其进行聚类,以便识别相同的地理位置。
LDA主题模型 [17] 是一种可以挖掘文档数据集合中潜在主题信息的概率模型。首先,使用LDA模型对Liu Lifelog进行训练,以发现其中的潜在主题。每一条Lifelog数据都被表示为一个主题分布,其中每个主题与一组词相关联。利用LDA生成的主题分布,将文本转换为一个主题向量。这个向量可以被视为文本在主题空间中的表示,它捕捉了文本中潜在的语义信息。
人类语言具有高度模糊性,一句话可能有多重的意思或隐喻,而计算机当前还无法真正理解语言或文字的意义。因此,现阶段的主要做法是将文本数据转换为模型可以理解的数值表示,这通常包括词嵌入 [18] 的应用,将每个词语映射到一个实数向量。Word2Vec [19] 是一种用于将词语表示为向量的技术,能够捕捉词语之间的语义关系 [20] 。通过Word2Vec,每个单词都被映射为一个固定维度的向量,这些向量保留了单词之间的语义关系,使得它们可以被用作神经网络等深度学习模型的输入。
使用LDA模型训练的主题向量和Word2Vec方法训练的词向量作为文本分类器的输入。Word2Vec侧重于词语上下文信息,但在表达词语的全局语义时存在不足。相比之下,LDA模型训练的主题特征向量反映了词语在整个文档集中的全局主题特征,更好地概括了词语的全局语义。因此,我们在文本分类时引入了LDA模型中词语的主题特征作为额外的语义补充信息,以提升分类效果。
3.3. DTC-TextCNN模型搭建
由于在Liu Lifelog中,所记录的数据通常都是短文本数据,即这些记录包含相对较短的文本片段,可能是几个句子、一个段落,或者是简短的描述。因此采用短文本分类的方法能更好地对Liu Lifelog 数据进行分类。CNN相比于其他的深度学习模型以及经典的分类方法,对于文本的局部信息比较敏感;计算开销低。同时,在对短文本进行分类中,TextCNN是比较好的处理模型,在进行实验验证时具有较好的分类效果 [21] 。
通过DB-SCAN聚类算法进行地理位置的特征提取,在本文中,使用球面距离来衡量两者之间的距离并作为聚合的半径参数。选取1公里作为密度聚合的半径参数,MinPts的个数为5。聚类后部分结果如表2所示,其中Cluster字段为聚类后的位置簇id号。

Table 2. Geographical location clustering results
表2. 地理位置聚类结果
文本主题是由3.2节中提到的LDA主题模型训练得到的,使用LDA主题模型,生成文档–主题分布以及主题–词语分布。在本文中,由于需要进行分类的数据共有8种,因此我们将模型的主题参数k值设置为8。经过训练后生成的“主题–词语”分布可以得到每个词语关于主题的概率值,它表示每个词在主题下的概率分布,这可以更加丰富地表示文章中每一个词的潜在语义,以获得更加准确的效果。一个词在主题中的概率越大,说明这个词在这一主题中的重要程度越高,也就越能够表征该主题的主题信息,也就应赋予该词更高的权重。我们选取每个主题下概率前十的词语,计算在其主题下所占的归一化权重,公式如(1)所示。其中
表示在第t个主题下词语i出现的概率。将通过(1)式计算得到的每个词在相应主题下的归一化权重与通过Word2Vec方法训练获得的词向量通过加权求和得到相应的主题向量,公式如(2)所示。其中
为通过Word2Vec方法训练获得的词向量,
为每一段生活日志文本对应的主题向量。主题向量的获取如流程如图4所示。
(1)
(2)

Figure 4. Topic Vector Generation Process
图4. 主题向量生成过程
将向量化后的文本信息,位置信息同主题向量拼接,使用两个不同卷积核大小的卷积层,然后通过全局最大池化层提取最显著的特征,最后通过全连接层进行分类。表3详细描述了DTC-TextCNN模型的整体结构,其中包括各层的参数数量和输出形状。
Table 3. DTC-TextCNN model structure
表3. DTC-TextCNN 模型结构
4. 实验结果
本节使用2.2节介绍过的Liu Lifelog数据进行实验。将Liu Lifelog数据集按照8:2的比例随机划分成互不相交的两部分作为训练集和测试集。使用Dropout正则化技术 [22] ,以防止模型在训练集上的过拟合,提高其在未见过的数据上的性能。使用批归一化加速神经网络训练过程,缓解梯度消失问题,使得训练更加稳定 [23] 。表4展示了DTC-TextCNN模型的实验环境。
Table 4. DTC-TextCNN model experimental environment
表4. DTC-TextCNN 模型实验环境
使用DTC-TextCNN对Liu Lifelog数据集分类的总体准确率为60.9%。此外,我们还建立了只包含地理位置信息和动态文本信息的DC-TextCNN模型,以及只包含动态文本信息的D-TextCNN模型,这两个模型对于数据集分类的准确率分别为57.9%和50.1%。上述模型的验结果如表5所示。可以看到,融合了主题特征和地理位置特征的DTC-TextCNN能够有效提高生活数据的分类效果。
Table 5. Experimental results of DTC-TextCNN model
表5. DTC-TextCNN模型实验结果
5. 结论
对Lifelog数据的分类不同于传统的文本分类,因为它是专门记录日常生活的经历,与个体用户的生活和经验相关联,涉及用户的兴趣、活动、位置等信息,这些个性化的特点要求用于分类的模型需要更好地适应用户的特殊行为和偏好。在本文中,我们提出了DTC-TextCNN模型用于解决Lifelog领域中数据分类问题。该模型融合了地理位置信息和文本主题信息。相比于基本模型,该模型能够提高Lifelog数据分类的准确性。
对Lifelog数据的收集是一件有意义的事情,人们可以通过对以往数据的查看,来回忆发生在自己身上的那些值得纪念的事情,同时,对Lifelog进行分类,使得人们更加方便地搜索相关动态。现在我们的项目已经公开在www.lifelog.vip,同时提供相关数据集供公众研究使用。希望有更多的志愿者能参与到项目之中,和我们一起共同留存生活中的美好时刻。