1. 引言
图像修复任务旨在通过特定方法对图像中损坏的区域进行重建,使修复后的图像尽可能接近现实图像。由于其广泛的应用价值,图像修复技术已在日常生活中得到普遍应用。例如,街景现实图像的重建 [1] [2] ,人脸的遮挡图像修复 [3] [4] ,还为文物保护 [5] 提供了一种新的修复方法。作为一种重要的图像预处理方法,图像修复在计算机视觉任务中具有重要的意义。
复杂内容图像是指具有多种结构、纹理和形状的图像。随着卷积神经网络(Convolutional Neural Network, CNN)的发展,基于深度学习的方法在图像修复领域取得了显著的进展。这些方法将图像修复视为一个基于条件的图像生成问题,利用CNN的编解码器结构作为生成模型,通过在大规模的数据集上进行训练,将学习到的知识填充到目标区域 [6] [7] 。这样,图像修复不仅能够恢复损坏的部分,还能够保持原始图像部分的一致性。通过生成对抗网络 [8] (Generative Adversarial Network, GAN),两个编码器相互作用,在共享的兼容性空间中学习潜在代码,图像修复得到了显著的发展。Rares [9] 通过大规模数据集学习图像的特征分布,Qin [10] 使用CNN在修复网络的解码器中,应用多尺度注意力增强合成图像的质量。随着Unet [11] 的出现,UNet采用了编码器–解码器结构,通过上下采样操作可以有效地保留了图像的空间信息,并利用跳跃连接将低级特征信息与高级特征信息进行融合。UNet类方法最初由Yan [12] 等人提出在UNet结构中引入移位连接(Shift connection, SC)层的图像修复方法,它使用SC层替换全连接层以转移图像背景区域特征信息,这一设计可以在更短的时间内得到更加精细的纹理和视觉上合理的修复结果。Liu [13] 在UNet结构中使用带有自动掩码更新的部分卷积,利用只在存在有效信息的位置进行卷积运算的特点,帮助网络更好地去除干扰并准确捕捉到关键的特征。Yu [14] 使用门控卷积来控制修复区域内有效和无效像素传递的技术,以更好地保留图像上下文信息。
随着深度学习的发展,自然语言处理领域流行的自注意力机制Transformer被应用到了视觉任务中。与CNN不同,注意力操作符的权重会根据输入动态调整,能够通过显式地与全局特征交互,更好地捕捉长距离的依赖关系。Dosovitskiy [15] 等人提出了ViT (Vision Transformer),通过长程依赖的建模,可以较好地捕获输入特征之间的全局关系,从而更好地实现图像修复。但是ViT的计算复杂度是输入长度的二次型,从而阻碍了常规高分辨率图像处理的应用。Dong [16] 等人设计了一个增量Transformer结构修复网络,它分别使用掩蔽位置编码提高模型对于不同掩码的泛化能力,但对于复杂图像无法很好地还原其纹理细节。Wan [17] 用Transformer进行外观重构,用CNN进行纹理补充,将CNN与Transformer的优势进行结合,同时引入了UNet通过跳跃融合操作填补底层信息以增强特征,对图像保真度有较大的性能提高。Li [18] 在此基础上,引入了风格感知网络,输入的噪声向量将传递到所有子网络中,这些风格向量会在后续的网络中被合并和传递。Transformer和CNN在图像处理领域各有优势,CNN在局部特征提取和空间上下文捕捉方面具有优势,而Transformer在全局建模和处理长程依赖关系方面具有优势,当前方法仍不能完全发挥两者的优势。
目前的图像修复网络可以大致分为三类:单生成器网络、多生成器网络和渐进式网络。单生成器网络 [19] [20] 是指通过一个生成器网络将输入的损坏图像直接映射到修复后的图像,它直接学习图像的映射关系,但是单个生成器网络具有局限性,无法保证图像修复的完整性。多生成器网络采用多个生成器网络 [21] [22] [23] 进行联合工作,每个生成器负责修复图像的不同部分。通过分而治之的策略,该方法可以更好地处理大型或复杂的图像修复任务。渐进式网络 [24] [25] 是一种层次化的修复方法,它将图像修复任务分解为多个阶段。每个阶段都会逐步恢复图像的细节和内容,从粗糙模糊到逐渐清晰,最终生成修复后的图像。在当前阶段,面对高分辨率和复杂内容等问题,渐进式网络在图像修复领域具有显著优势,本文将结合多生成器和渐进式网络的优势对网络进行设计优化。
针对上述问题,本文通过采用多生成器和渐进式网络的思想,通过多个网络分别提取不同属性的特征,提出了一种基于多源特征增益编码的图像修复网络。本文的主要贡献如下:
• 以视觉捕捉原理为出发点,构建了一个网络框架,依次对结构和纹理信息进行编码,并运用通道注意力(Efficient Channel Attention, ECA)的UNet网络对结构、纹理、感知等多源特征进行融合。
• 设计了通道和稀疏双自注意力ViT (Channel Sparse Dual Attention Vision Transformer, CSDA),通过双重注意力机制遮蔽无效信息,使网络能够自适应地学习复杂图像重建的全局依赖关系,从而获得更准确的结构信息。
• 在Unet网络中,通过在不同深度层加入ECA通道注意力,实现对不同特征的渐进融合,使网络能够更有针对性地关注需要修复的区域,从而增强特征的表达。
2. 本文方法
本文提出的网络框架如图1所示,由两个核心模块组成:基于通道稀疏双注意力机制的ViT模块,它能够自适应地学习复杂图像重建的全局依赖关系;基于ECA [26] -UNet的多源特征融合模块,能够有效地融合全局和局部信息。还引入了感知风格编码模块增强图像修复的多样性。
图1描述了网络的总体结构以及核心的网络模块。在这个网络中,输入图像IM带有掩码,并通过一个经过视觉捕获设计的修复网络进行处理,经过多源特征的融合后,最终得到修复图像。具体来说,输入一个带有掩码的图像IM (IM∈R,H × W × 3),其中H × W表示特征图的空间分辨率,利用3 × 3卷积将特征图进行下采样的同时把其扩展到一个更高维的特征空间。然后,特征图将通过“浅–深–浅”设计的ViT Block,其中每个Block中由多个CSDA组成,各级编码器网络都具有不同的通道数和分辨率。为了增加模型训练的稳定性,增加了跳跃连接来跨越连续的中间特征。为了将不同编码器得到的特征进行增益融合,本文采用多尺度逐级特征融合,由一组对称的“5 + 5”Unet编码器–解码器组成,随着编码器像素信息逐级缩小,特征信息逐级加深,在编码器中引入ECA进行特征逐级融合,这种的方式可以学习图像不同尺度的特征信息,进而重建出合理的图像纹理和结构。
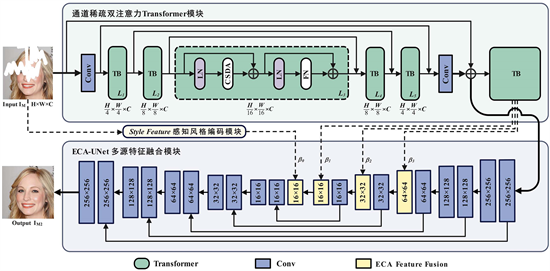
Figure 1. The framework of multi-source features encoding network
图1. 多源特征增益编码网络框架
2.1. 通道稀疏双注意力Transformer模块
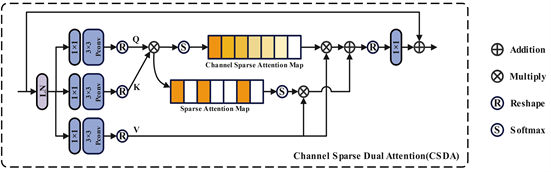
Figure 2. Channel sparse dual attention vision Transformer module attention
图2. 通道稀疏双注意力Transformer模块的注意力部分
旨在提升图像全局结构修复的编码能力,因此设计了一种通道稀疏的双自注意力机制,以替换ViT中常用的多头自注意力机制。如图2所示,该过程首先采用1 × 1卷积对通道级上下文进行编码,随后通过3 × 3深度卷积生成查询(Q)、键(K)和值(V)。这一步骤能够计算出Q与K之间所有像素对的注意力值P,从而有效地增强了图像修复编码的精确性和效率。
(1)
其中,
为头部尺寸,k为头部编号。在稀疏自注意方面,对P进行了一个简单而有效的掩蔽函数M来选择top-k,对每一行的相似度矩阵进行分析。对于小于阈值的其他元素,用0替换它们。这一步可以进一步过滤掉嘈杂的信息,并加训练过程:
(2)
其中,阈值是行的第k个最大值。最后,将Channel Attention和Sparse Attention的加权和矩阵乘以
得到CSDA的最终输出:
(3)
在每个CSDA中,给定在第(k − 1)块Xk−1处的输入特征,CSDA的编码过程可以如公式(4) (5)所示:
(4)
(5)
其中,
和
表示CSDA和前馈网络(Feed forward Network, FN)的输出,LN是指图层的归一化。在完成CSDA全局特征编码后,将全局特征、感知风格通过多源特征融合模块进行分层融合后得到修复结果。
2.2. ECA-UNet多源特征融合模块
为了对特征进行增益编码,在编码器中加入了特征融合模块,把通过CSDA特征编码模块和感知风格编码得到的
,
,
,
(见图1)逐级融合进特征网络。其中特征融合模块中引入了ECA,如图3所示,将输入特征图通过平均池化(Average Pooling)获得聚合特征
,之后通过执行卷积核大小为k的一维卷积来生成通道权重,最终将权重作用于原特征图。其中k通过通道维度C的映射自适应确定,公式(6)所示:
(6)
k表示卷积核大小,C表示通道数,odd表示k只能取奇数。在融合过程中引入注意力机制可以在保持较高的计算效率同时帮助修复网络区分输入特征中的重要信息和噪声或缺失部分。通过学习到的注意力权重分布,网络能够更加集中地关注需要修复的区域,提高修复结果的准确性和质量。
2.3. 感知风格编码模块
感知风格编码模块由10层网络构成,如图4所示,该模块由3层下采样、3层卷积、2个AdaIN [27] 模块、2个FC层4种类型构成。其中在FC层中的Instance Norm当中包含了2个可学习参数,Shift和Scale。而AdaIN就是让这两个可学习参数从W向量经过全连接层直接计算出来的,因为Shift,Scale会影响生成的图片,从而实现拓展特征信息的网络空间。因为W是随机生成的,所以同原图的特征相结合能够实现修复效果的多样性。
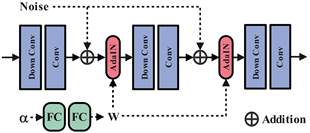
Figure 4. Perceptual style encoding module
图4. 感知风格编码模块
如上图4所示,首先在特征空间中对图像IM和感知风格特征W进行编码,将两个特征送入AdaIN层,AdaIN层将图片特征映射的均值和方差与感知风格特征映射的平均和方差对齐,产生目标特征映射t,公式表示为:
(7)
特征t在网络空间中向后传递,最终得到感知风格特征
,其中AdaIN的公式表示为:
(8)
接收内容输入x和样式输入y,并简单地对齐x的通道均值和方差以匹配y的均值和方差。AdaIN通过传递特征统计量,特别是信道均值和方差,在特征空间中进行风格传递。
2.4. 损失函数
本文的损失函数由三部分组成:1) 对抗损失;2) 重构损失 [28] ;3) 感知损失 [29] ,整体的目标函数可以表示为:
(9)
本文引入了感知损失是基于生成图像和目标图像之间的CNN特征差分定义,与传统的均方误差损失函数相比,感知损失更注重图像的感知质量,更符合人眼对图像质量的感受。令
来表示损失网络,
表示网络的第j层,
表示第j层的特征图的大小,定义为:
(10)
经过实验对比,其中损失项的平衡参数
,
时,模型收敛效果最佳。
3. 实验
本文使用两个常用图像修复公共数据集:Places-365 [30] 为复杂图像数据集,其中有来自365个场景类别的180万张图像,本文划分训练集有177万张,测试集有3万张;CelebA-HQ [31] 为人脸数据集,划分训练集有2.7万张图,测试集有3000张。
本文提出的网络基于pytorch 1.9框架实现,训练和测试系统均采用Nvidia GeForce GTX 3090Ti 24G GPU。该网络使用256 × 256图像进行训练,使用Adam优化器 [32] 对模型进行优化。两阶段生成器以学习率为10−4进行训练,当损失趋向平稳时将学习率降到10−5,直至生成器收敛,最后学习测试时,只需要加载训练的模型对图像进行测试。

Figure 5. Comparison of irregular mask inpainting in Places-365 dataset
图5. Places-365数据集不规则掩码修复比较

Figure 6. Comparison of irregular mask inpainting in CelebaA-HQ dataset
图6. CelebaA-HQ数据集不规则掩码修复比较

Figure 7. Comparison of mask inpainting details for Places-365 dataset
图7. Places-365数据集规则掩码修复细节比较

Table 1. Comparison of irregular mask inpainting on the Places-365 dataset
表1. 在Places-365数据集上不规则掩码修复对比
Table 2. Comparison of irregular mask inpainting on the CelebA-HQ dataset
表2. 在CelebA-HQ数据集上不规则掩码修复对比
3.1. 定性试验
为了客观展现修复结果,本文在对比方法时使用相同的输入数据。图5展示了通过EC [25] 、DeepFill [14] 、CTSDG [22] 、ZITS [23] 、MAT [18] 以及本文提出的方法在Places365数据集上进行的不规则掩码修复结果,图6展示了上述除专注于结构修复的ZITS以外的方法在CelebA-HQ数据集上的修复结果,图7展现了部分方法的局部修复放大图。
如图5所示,EC是通过预测边缘信息来指导修复过程,对具有稀疏损坏的图像生成的修复结果往往具有合理的语义结构,但是不能对损坏图像进行合理的像素级别的修复。Deepfill利用可以更新Mask的门控卷积进行特征提取修复,但由于缺乏全局结构信息导致图中修复产生了杂乱无章的修复结果。CTSDG利用结构和纹理相互指导的修复方法,可以看到图中已经拥有了丰富的纹理信息,但结构信息未能合理编码,结构修复的方面产生了一些错误。ZITS、MAT的修复结果相对传统方法的结构更加完整,但在多个尺度的特征融合时仍存在不足,导致产生一些明显的不合理图像和伪影。本文方法在Places-365数据集上较好的完成了结构和纹理的修复,在视觉上未产生明显的不合理部分。此外,本文在人脸数据集CelebA-HQ的修复中也取得了良好的表现,得益于CSDA网络的无效信息自适应遮蔽,即使在不规则的修复区域,也能较完整地捕捉图像的语义信息进行修复。与其他修复方法相比,本文展现出更好的细节修复效果。
本文从前文的方法中选择了CTSDG、ZITS、MAT (年份最新的3种方法)进行比较,并展示了修复细节。从图7中的表现可以看出,本文提出的修复方法能够有效地补充纹理信息和结构信息,由于图7第二排图的电梯结构有效信息已经完全被遮挡,所以修复的结果无法同原图完全相同,但本文修复后的图像未产生伪影和错误结构,且该图在视觉上看起来更加合理,在复杂图像的修复上展现出了优异的性能。
3.2. 定量评价
本文在测试集中为每张图像设计了不同尺寸的损坏区域,即不同比例的掩码面积,并应用了六种不同的图像修复方法以获得修复效果。为了量化评估图像的失真或噪声水平,本研究采用了PSNR (峰值信噪比)作为标准;而为了衡量原始图像与修复结果之间的结构相似度,采用了SSIM (结构相似性指数)。此外,鉴于感知损失与风格损失在网络中的重要性,本文采用FID [33] (弗雷歇距离)来评估图像高级特征之间的相似度。通过这三种评价标准,本研究不仅在像素层面上评估了模型的修复效果,也从特征层面进行了综合评价。PSNR和SSIM的高值表明更佳的图像修复效果;而FID的低值则表示图像在高层特征上的相似性更高。如表1和表2所展示的,综合这些评价指标,本文提出的网络模型在Place365复杂图像数据集上的三个度量指标均优于其他方法,并且在CelebaA-HQ数据集上也表现出色。这一结果证明了本研究方法在复杂图像修复领域相比于当前主流编解码网络的优越性。
3.3. 消融实验
Table 3. Comparison of multiple attention evaluations of self-attention in Transformer
表3. Transformer内部多种自注意力的评价指标对比
Table 4. Comparison of evaluations for different modules
表4. 不同模块下的评价指标对比
为了证明本文CSDA模块对修复结果的影响,本节对CSDA模型进行了消融实验,对比本文方法的以下变体 [34] :1) MTA (Muti-Head Attention),FN;2) MDTA (Multi-Dconv Head Transposed Attention),GDFN (Gated-Dconv Feed-Forward Network,控制特征转换,抑制小信息量的特征);3) CSDA,GDFN。在Places-365数据集上选取了60万张作为训练集,3万张作为测试集训练,表3列出了的定量评价。本文的模型比其他的配置表现得更好,这显著地揭示了每个单独的组件对性能改进都有积极的影响。
为了深入探讨多源特征编码的有效性,本文设计了以下实验:首先移除了编码全局结构的CSDA;接着剔了UNet特征融合过程中的ECA模块;最后比较了去除提升多样性感知风格模块后的效果。通过

Figure 8. Ablation experiment of perceptual style module
图8. 感知风格编码模块消融实验对比效果
这些实验设置,表4中的数据清晰地揭示了模型性能的显著降低,从而验证了本文方法中结合多源特征的重要性。这一点在ViT和UNet的串联机制中表现尤为明显。此外,移除感知风格编码后,测试结果在所有评价指标上均显示性能下降,尤其是在FID和PSNR指标上。这一现象表明图像在保真度方面有所损失,说明感知风格编码在图像重建中提供了关键的潜在空间。图8展示了几个可视化示例,其中A、B示例未应用感知风格编码模块,而C、D则展示了本研究方法的输出效果。相比之下,本文方法不仅在视觉效果上更为出色,还展现了更高的多样性。
4. 结论
实验研究结果展现了本文提出的多源特征增益编码的图像修复网络在复杂图像修复领域的优秀性能。复杂图像通常包含丰富的纹理、结构和空间关系特征,本文通过串联结构–纹理特征编码策略,有效融合了全局和局部信息,从而增强了修复能力。本文在Place365和CelebA-HQ两个数据集上进行了实验,将稀疏注意力和通道注意力机制引入Transformer能够更加有效地关注结构信息,在定量和定性的实验评估中均表现出显著提升。此外,感知风格编码的引入使得图像修复结果更加多样化,在多尺度下融合多种特征可以实现特征间的有效适配。与传统图像修复方法相比,本文方法不仅能生成更高精度和清晰度的图像,还在处理各种范围和形状的掩码修复任务中展现了适应性。综上所述,本文提出的图像修复网络模型在实际应用场景中具有广泛的应用潜力和前景。