1. 引言
出血性脑卒中是一种严重的脑血管疾病,其发病率约占脑卒中的10%~15%。它是由于非外伤性脑实质内血管破裂而引起的脑出血。出血性脑卒中的病因十分复杂,常见的原因包括脑动脉瘤破裂、脑动脉异常等。这些原因导致血液进入脑组织并引发机械性损伤。出血性脑卒中的起病非常急,进展迅速,预后相对较差 [1] 。据统计,其病死率高达45%~50%。即使幸存下来,约80%的患者也会遗留严重的神经功能障碍,对患者及其家庭来说都带来了沉重的负担。因此,预防和早期诊断对于出血性脑卒中非常重要。控制高血压、减少饮酒、戒烟、保持健康的生活方式等措施可以有效降低患者患上出血性脑卒中的风险。对于已经患有出血性脑卒中的患者来说,血肿范围的扩大是预后重要危险因素之一。血肿范围的扩大会导致颅内压迅速增加,进一步损害脑组织,加重神经功能障碍,甚至危及患者的生命。因此,监测和控制血肿的扩张成为临床关注的重点。此外,血肿周围的水肿也是脑出血后继发性损伤的标志之一 [2] 。血肿周围的水肿会导致脑组织受压,进一步影响神经元的功能,加重脑组织的损伤,进而加重患者的神经功能障碍。
近年来,医学影像技术的飞速发展为无创动态监测出血性脑卒中后脑组织损伤和演变提供了有力的手段。同时,人工智能技术的广泛应用为海量影像数据的深度学习和智能分析带来了新的机遇。通过利用影像信息、患者个人信息、治疗方案和预后等数据,构建智能诊疗模型,可以更准确地预测患者的康复阶段,并根据预测结果进行个性化的治疗。这对于加速患者的康复具有重要的临床意义。因此,针对出血性脑卒中后的关键事件,即血肿扩张的发生和发展,进行早期识别和预测是至关重要的 [3] 。通过结合患者的个人史、疾病史、发病及治疗相关特征等因素,可以有效预测出血性脑卒中的发病风险。
总之,出血性脑卒中是一种严重的脑血管疾病,预防和早期诊断至关重要。通过医学影像技术和人工智能的应用,可以实现对出血性脑卒中后脑组织损伤和演变的监测和预测,为临床决策提供科学依据,改善患者的预后。这将为出血性脑卒中患者带来希望,并为未来的研究和临床实践提供更多的机遇和挑战 [4] 。本文通过真实临床数据,首先研究出血性脑卒中患者血肿扩张风险以及血肿周围水肿随时间发生的演进规律,最终结合临床和影像相关信息,运用有自注意力机制的一维卷积 [5] 预测出血性脑卒中患者的手术后48小时内的血肿发生概率。
2. 方法
2.1. 血肿认定
血肿扩张是指患者术后48小时内后续的检查比首次检查其血肿的绝对体积增加量多于6 mL或相对体积增加33%以上,即认定为血肿扩张事件 [6] [7] 。需要根据表1中入院首次影像检查流水号索引,明确发病到首次影像检查时间间隔,以及表2中各时间点流水号及对应的血肿体积(HM_volume)等数据,判断前100名患者(sub001至sub100)是否存在血肿扩张事件。同时记录从发病到影像显示开始发生血肿扩张事件的时间。提取表中入院首次影像检查流水号、发病到首次影像检查时间间隔以及表2中各时间点流水号及对应的血肿体积(HM_volume)等数据。提取首次影像检查时的血肿体积与之后每一次影像检查的血肿体积做比较,同时记录下每次影像检查的时间点,用以确认血肿的发生。

Table 1. Patient’s age and background information
表1. 患者年龄及其背景信息
Table 2. Imaging information from the patient’s medical examination
表2. 患者检查影像结果
2.2. 基于自注意力卷积神经网络的血肿扩张预测模型
自注意力卷积神经网络(Self-Attention Convolutional Neural Network)是一种结合了自注意力机制和卷积神经网络的网络结构 [8] 。卷积具有局部感知、权值共享等特征,可以自动提取目标数据中的关键信息,即提取关键少数的局部特征,常用于自然语言处理中提取关键词的过程。然后总结出全局特征,窥一斑而知全豹。自注意力模型可以一步到位的获取全局特征与局部特征的的联系,从而提高预测精度。由于在本文中,所提出模型输入需进行了数据预处理,每个一维数据代表的含义是固定的。非时间序列,不存在时间上的关系。故卷积和自注意力网络采用并行计算,弥补单个模型在单线程的预测精度不足的问题。两个模型的输出展平后输入全连接层,每个元素都会与序列中的其他元素进行相关性计算,然后根据相关性计算的结果来加权求和,进行归一化,最后得到所要求的概率。
卷积层包含许多具有加权参数的卷积核(也称为滤波器)。这些卷积核与上一层输入图进行运算,并创建新的特征图。每个内核提取输入局部区域的局部特征使用相同的内核大小,共享相同的加权参数,从而有效减少超参数数量,降低模型复杂度 [9] 。给定第
个卷积层的输入数据
和一组核
,其中M、N为输入图片的尺寸,h,w为卷积核的尺寸,那么第l层的结果如下:
(1)
其中,
为激活函数,*为卷积运算,b是偏置系数,
是第l个卷积层的第i个特征值;
是第l层卷积尺寸为
的第i个卷积核,它与上一层输入的
特征图进行卷积运算,后加上偏置矩阵值就得到了当前层的特征值输出。激活函数是为了避免在训练卷积核和偏置矩阵参数的更新过程中出现梯度消失和梯度爆炸的问题。经过实验得知sigmoid激活函数会导致梯度消失问题。因此,本文CNN激活函数选择整流线性单元(ReLU)激活函数,其定义如下:
(2)
卷积结束之后,序列特征信息被剥离出来。一般卷积完成之后进行池化操作,池化运算不仅可以对卷积产生的结果进行特征提取,而且可以缩小卷积导致的数据量激增问题。卷积分为最大池化和平均池化,试过实验分析,最大池化的结果更佳,最大池化后的结果如下:
(3)
为池化层的输出,
为池化层的输入,D为池化尺寸。
在经过卷积层和最大池化层之后,输入的数据转变成了一个矩阵,需要对结果进行展平操作后,才能进行全连接运算,第l层展平后的结果如下:
(4)
为激活函数,
为全连接层的系数矩阵,
为偏置参数,u,v代表池化层输出特征的大小。
在一维的卷积中,卷积核不在选用是
的矩阵,而是选用
的序列作为卷积核。示意图如图1。在训练开始前卷积核随机初始化。
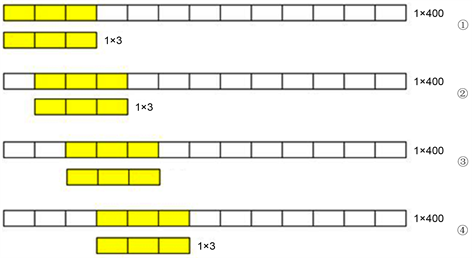
Figure 1. Schematic diagram of one-dimensional convolution process
图1. 一维卷积过程示意图
自注意力机制包括缩放点积注意力(SDA)机制和多头注意力(MHA)机制两部分 [10] 。SDA是对输入序列X做线性映射,过程如式(5)、(6)、(7)所示,得到矩阵Q、K和V:
(5)
(6)
(7)
通过Q和K矩阵的点积除以
进行相似度计算,以防止计算所得值过大,再通过softmax函数进行归一化处理,最后通过加权求和法得到最终数据,如式(8)所示:
(8)
式中:Q,K,V为同一输入矩阵做线性映射所得到的矩阵;
为稳定训练梯度的矩阵;softmax为具有归一化功能的激活函数。
3. 实验与结果分析
3.1. 数据预处理
数据处理首先需要将医院数据库中的数据进行预处理,排除缺失值、异常值。其次根据影像检查的流水号将表格中数据进行汇总。通过表1的序号和表2中的流水号将其他数据表格中的数据归类整理到一张表中方便后续工作的展开。总表表头按顺序为患者编号、流水号、年龄、性别、首次mRS评分、患者病史、血压、治疗方法、患者影像信息血肿及水肿的体积及位置、患者影像信息血肿及水肿的形状及灰度分布 [11] 等依次排序。
由于数据不集中,分布在两个表格中。首先通过Matlab读取表1、表2、并利用单元格编号将其划分到一张表中。这里需要注意,患者流水号是乱序的,为了确保流水号与患者编号之间的连续性以及关联性,应该将同一患者的每次检查的流水号放在同一组以便观察。同时将每次检查的时间与首次发病之间的时间点。
为了数据存取方便,将表1中的“男”、“女”字符分别换成1和2,再统计患者检查的次数以及其影像数据,如果部分患者没有检查即数据缺失,则不记录在内。为了确保数据的连续性,对于缺失数据,考虑采用前三个同类型数据的平均值将其代替。处理完数据的完整表格的大小为592 × 100,由于数据过多,不方便展示,其整理后表格如表3所示。
Table 3. Individual treatment and imaging information of patients
表3. 患者个人治疗及影像检查信息
通过简单逻辑以及数据整理,提取首次影像检查时的血肿体积与之后每一次影像检查的血肿体积做比较,同时记录下每次比较时两次影像检查的时间点,然后给定患者是否发生血肿扩张事件。流程图如图2所示。输出为两个值,是否发生血肿扩张和发生的时间。结果预览见下表4。

Figure 2. Flow chart of pre-processing of hematoma expansion data
图2. 血肿扩张数据预处理流程图
Table 4. Postoperative results of patients and the time of occurrence of hematoma
表4. 术后患者是否发生血肿及其血肿发生的时间
3.2. 参数确定
在数据清洗之后,根据血肿发生需要考虑的数据,即个人史,疾病史,发病及治疗相关特征信息,以及其关于血肿影像检查的形状和位置大小,把模型所用数据提取出来,构建成一个75 × 100数据矩阵。其中输入参数72维,输出结果为0或1,即发生血肿和不发生血肿。
CNN模型需要对卷积核的大小、激活函数,层数及其具体参数进行选择。本文采用基于自注意力的卷积神经网络包含两层CNN神经网络、以及两层全连接层,其具体结构构成如图3所示。训练轮数为1000或者损失小于0.001。损失函数采用交叉熵损失函数(CrossEntropy Loss),优化算法采用Adam算法,初始学习率为0.001。CNN的初始权重参数和偏置全为零。在所有的数据样本中,把60%的样本作为训练集,其余的用作测试集。
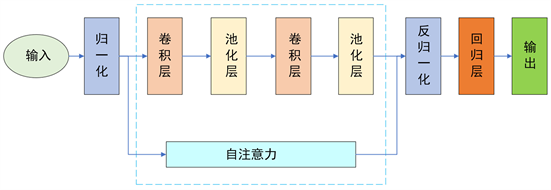
Figure 3. Flow of self-attention convolutional neural network
图3. 自注意力卷积神经网络流程
3.3. 实验环境以及参数设置
实验在配置了Python3.8的Pytorch1.10的移动工作站上进行,工作站配备了英特尔i5-10300HCPU、16 GB内存,显卡1650Ti,显存4G的移动工作站上进行的。
3.4. 结果分析
需要根据前100名患者的个人史,疾病史,发病及治疗相关特征以及其影像检查结果和其影像检查结果,预测所有患者发生血肿体积扩大的概率。即已知输入为这前100名患者的个人史、疾病史等医学特征,输出为患者发生血肿体积扩大的概率。将处理后的数据作为输入,是否发生血肿作为目标,训练自注意力卷积神经网络模型,即可得到关于预测全体患者的血肿体积扩大的神经网络模型。该模型可以有效预测出所需要的结果。训练过程中的损失如图4所示,在前期的快速下降阶段,训练损失呈指数下降,然后是波动下降阶段,约600轮时,下降至0.3;最后是缓慢下降阶段,训练结束,损失下降至0.15。
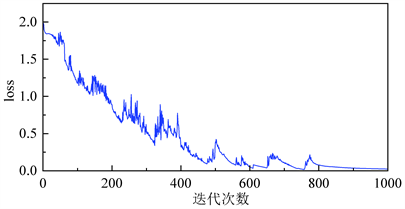
Figure 4. Plot of training loss for the proposed prediction model
图4. 所提出预测模型训练损失图
经过1000次的训练,所提出模型的内部参数已经基本处于最优状态,此时用来预测病人术后的血肿是否发生,准确率达到97.5%。预测结果如表5所示。
Table 5. Comparison table between predicted results and real results
表5. 预测结果与真实结果对照表
4. 结语
本文所建立的血肿扩张事件概率模型,自注意力机制可以捕捉输入序列中的长距离依赖关系。相比于传统的卷积神经网络,它不受局部感受野的限制,能够在整个输入序列上进行全局的关联建模。基于患者个人史,疾病史,发病及治疗相关特征以及其影像检查结果可以有效预测患者出现血肿扩张事件的概率。在本文中,取用100位患者的治疗信息作为机器学习的对象。经过训练,所提出模型根据患者术后的首次影像检查结果和相关信息预测其血肿是否发生的准确率达到97.5%。在实际应用中可以辅助医生对患者进行治疗,从而加速患者康复过程。