1. 引言
随着机器学习和稀疏表示的重大进步,图像处理已成为一个重要的研究课题,由于受到成像设备或外界环境变化等因素的影响,图像中难免会存在不同程度的噪声。人们为了从图像中提取更多的有用信息,运用图像去噪技术来去除噪声。
字典学习是实现图像去噪的一种有效技术,但在传统的字典学习(K-SVD)中,字典训练是一个耗时的过程,稀疏表示大多通过设置固定的硬阈值来停止,导致图像中的有效内容丢失 [1] 。基于上述问题,一些研究对传统的字典学习算法进行改进,文献 [2] 提出了一种改进的K-SVD算法,用于稀疏表示去噪,该算法具有更快的执行速度。Song等人 [3] 提供了一种参数化的模糊自适应字典改编方法,嵌入了模糊集的新机制,将字典列的更新与稀疏表示的更新相结合。然而,基于K-SVD的去噪算法仅利用图像块的内部信息进行独立的稀疏编码,而不考虑与其他块相关的信息。
数据不同的组成部分可能具有不同的结构,它们位于不同的子空间中可以单独表示 [4] ,因此可以根据工作的特性构造特定的字典,这样可以有效地保留原始数据之间的局部几何结构 [5] 。基于此类想法,Chen等人 [6] 将RPCA的稀疏项替换为预学习的语音字典和系数矩阵的乘积,将背景噪声建模为低秩部分和残差之和,从而实现语音增强。Xu等人 [7] 基于预学习字典和自适应参数设置方法,选择平均重构质量最好的字典作为预学习字典来降低计算的复杂性,实验表明该算法的性能优于其他去噪算法。Wright等人 [8] 指出人脸的干净数据可以很好地用子空间来表征,且同一类的干净数据位于同一低维子空间中。此外,结构化噪声通常对应于人脸图像 [9] 中的面具、眼镜等,可以用字典和对应系数的乘积来表示。
综上所述,本文提出了一种基于预学习字典的低秩算法用于人脸去噪,在算法中,干净数据和结构化噪声分别被建模为它们对应的字典和系数矩阵的乘积,并进一步描述重构误差与干净数据的联系,然后利用对称ADMM对所提的算法进行求解,最后,在AR数据集上验证所提算法的有效性。
2. 相关理论与方法
2.1. RPCA
RPCA [10] 旨在从损坏的观测矩阵X中恢复低秩矩阵L,其数学模型为:
(2.1)
其中,
为矩阵的秩,
表示矩阵S中非零元素的个数。问题(2.1)是一个NP-难问题,在实际应用中通常转化为问题(2.2)
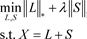 (2.2)
(2.2)
其中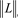 是矩阵L的奇异值的总和。
是矩阵中每个列向量的绝对值之和的最大值。
是矩阵L的奇异值的总和。
是矩阵中每个列向量的绝对值之和的最大值。
2.2. 聚类评价指标
评判聚类结果的好坏,除了凭直观感受评价可视化的结果外,还可以借助数值化的聚类有效性指标,本文使用的评价值指标有ACC,PUR [11] 、NMI [12] 。
2.2.1. PUR
纯度(Purity)为正确聚类的样本个数占总样本数的比例,可表示为
 (2.3)
(2.3)
其中,N表示总的样本个数,
表示正确的聚类结果,
表示真实的聚类结果。
,越接近1表示聚类的结果越好。
2.2.2. NMI
假定X是一个由n个样本点组成的样本集
,
是正确的聚类结果,
是待和P比较的聚类结果。P和Q之间NMI指标(normalized mutual information)可表示为
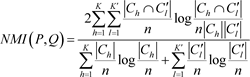 (2.4)
(2.4)
NMI指标的最大值为1,最小值为0,值越大表示聚类结果越接近真实结果。
2.2.3. ACC
准确度(Accuracy)使用正确的聚类结果与真实的聚类结果进行匹配,可表示为
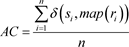 (2.5)
(2.5)
其中,
,
分别表示
所对应的正确聚类结果和真实聚类结果,n表示总样本数,
表示指示函数,定义如下:
ACC的取值范围为0到1,值越大表示聚类结果越好。
3. 模型的构建与求解
3.1. PLID模型的构建
本文将原始数据X分为干净数据、结构化噪声和残差部分,分别用
,
和E表示。其中
和
分别为干净数据的字典和系数矩阵,
和
分别为结构噪声的字典和系数矩阵,剩余残差
。A是将观测矩阵X转化为干净数据的映射矩阵,为此我们提出如下模型:
 (3.1)
(3.1)
上式对于任意固定的字典
,有
,所以系数矩阵可以直接控制稀疏性 [13] 。因此
和
的稀疏性和低秩性分别由系数矩阵
和
控制。为此将(3.1)式进一步调整后如下:
 (3.2)
(3.2)
3.2. PLID模型的优化求解
对于模型(3.2)中的变量,本文利用对称交替方向乘子法(ADMM)解决该最小化问题 [14] 。首先,引入辅助变量Q,P,M,N得到如下的优化问题:
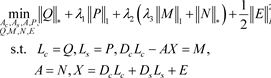 (3.3)
(3.3)
问题(3.3)对应的增广拉格朗日函数为
(3.4)
其中
,
,
,
,
是拉格朗日乘子,
是罚参数。
1) 求解Q的子问题,保持其他变量不变,更新Q:
(3.5)
其中,
表示奇异值阈值算子 [15] ,
是收缩算子,
是H的奇异值分解。
2) 求解P的子问题,保持其他变量不变,更新P:
(3.6)
其中,
。
3) 求解M的子问题,保持其他变量不变,更新M:
(3.7)
其中,
。
4) 求解N的子问题,保持其他变量不变,更新N:
(3.8)
其中,
是奇异值阈值算子。
5) 求解
的子问题,保持其他变量不变,更新
:
(3.9)
该子问题的最优解为:
(3.10)
其中,
。
6) 求解
的子问题,保持其他变量不变,更新
:
(3.11)
该子问题的最优解为:
(3.12)
其中,
。
7) 求解A的子问题,保持其他变量不变,更新A:
(3.13)
该子问题的最优解为:
(3.14)
其中,
。
8) 求解E的子问题,保持其他变量不变,更新E:
(3.15)
该子问题的最优解为:
(3.16)
算法1给出了求解优化问题(3.3)的PLID迭代过程
算法1. PLID迭代过程
3.3. 算法的复杂度分析
算法1中,Q和N涉及了对矩阵进行奇异值分解,所以求解
和A的步骤是最耗时的。对于一个矩阵
,精确SVD的计算复杂度为
。因此,更新
的计算复杂度为
,类似的更新
的计算复杂度为
。
4. 实验结果与讨论
在本节中,首先在ORL1和Yale2数据集上进行消融实验,验证PLID算法各个成分的有效性。其次对PLID算法的收敛性进行分析。最后在AR数据集 [16] 上与RPCA [10] ,PSSV [17] ,DRPCA [18] ,ARPCA [19] 等算法进行比较。表1总结了实验所用的数据集的特征。

Table 1. Description of the experimental dataset
表1. 实验数据集的描述
4.1. 预学习字典
在算法1的框架之外,需要提前学习字典
和
。首先采用RPCA方法将原始数据分解为干净部分和结构化噪声,然后利用KSVD学习这两部分的字典
和
,两个字典分别为干净数据字典和结构化噪声字典。本文对ORL,AR和Yale数据集干净部分和结构化噪声的两个字典的原子数分别设置为2和3。
4.2. 收敛性分析
当涉及到具有三个以上变量块的凸问题时,ADMM可能是发散的 [20] ,因此本文采用实验证明算法的收敛性,其中
从图1可以看出,PLID在所有数据集中大约会在迭代80次收敛。
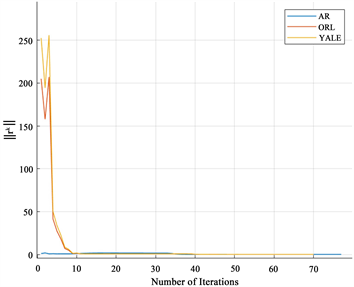
Figure 1. Convergence curves of PLID on three datasets
图1. PLID在三个数据集的收敛曲线
4.3. 消融实验
上述所提出的模型是由几个模块组成,为验证各个模块的相关性和有效性,我们对其进行消融实验,具体方式如下:
1) 为了评估预学习字典的作用,将PLID的完整版本与没有预学习字典的方法进行比较,即干净数据和结构化噪声不分解为字典和系数矩阵的乘积。
2) 理论上,对不同的数据分别进行预学习字典可以提高算法的恢复性能。为了证实这种潜在的优势,将完整版本的算法和它的简化版本进行比较,即字典用单位矩阵表示。
3) 为了验证正则项的作用,对PLID在参数
为零和非零时的性能进行比较。
最后,用准确度(Accuracy, ACC),归一化互信息(normalized mutual information, NMI)和纯度(Purity, PUR)做为评价指标,对ORL和Yale数据集进行聚类实验,检验各个组件的聚类效果,所得结果汇总于表2。表中结果表明,PLID的每个模块在提高算法的性能方面发挥着积极和显著的作用。
4.4. 人脸去噪实验
首先随机在AR数据集上 [16] 选择5个类,然后进一步选择每类中14张无遮挡的干净图像和3张带眼镜的图像作为训练数据,剩下3张带眼镜图像作为每类的测试数据。将每张图片的大小重新调整为55 × 40,参数设置
,
,
。此外,我们将同时对每张图像添加如下的两种噪声:
Table 2. Cluster index analysis of different components of PLID
表2. PLID不同组成成分的聚类指标分析
1) 添加信噪比为15 dB的高斯噪声
2) 添加3个大小为5 × 5黑色遮挡块

Figure 2. Example of AR image corruption
图2. AR图像损坏示例
上图2是添加两种噪声后的图像示例。下面将提出的算法与其他方法进行比较,并使用k-means方法对获得的干净数据进行聚类分析,聚类结果如表3所示。
Table 3. Clustering results of corrupted AR images
表3. 损坏的AR图像聚类结果
从表3可以看出,PLID相比其它四种算法对损坏图像的聚类效果更好,体现了更好的性能。同时,图3展示了不同算法的恢复图像,很容易发现 RPCA,PSSV,DRPCA和ARPCA算法可以很好的处理一部分高斯噪声和黑色遮挡块,但是不能很好地处理人脸的眼镜遮挡。相比之下,本文所提的算法不仅去除了眼镜干扰,还很清晰地去掉了三个黑色块,说明PLID更适合处理复杂的噪声情况。

Figure 3. Example of recovery. (a) is the image damaged, (b)~(f) is the image reconstructed by RPCA, PSSV, DWRPCA, ARPCA, and PLID, respectively
图3. 算法恢复AR图像的可视化示例。(a) 是被噪声损坏的图像,(b)~(f) 分别是被RPCA,PSSV,DWRPCA,ARPCA和PLID重建的图像
此外,为了验证映射矩阵A对新样本(即测试数据)的有效性,先使用PLID通过训练数据求得A,然后对测试数据中5个类的10张带有太阳眼镜图像直接处理,恢复结果如图4所示。可以看出,添加噪声的测试样本在通过映射矩阵的线性变换后,也可以恢复出一张清晰的人脸。

Figure 4. Example of recovery of the test sample. The first row is the test sample with added noise, and the second row is the data AX reconstructed with mapping matrix A
图4. 测试样本的恢复示例。第一行是添加噪声的测试样本,第二行是利用映射矩阵A重构的数据AX
5. 结论
本文提出了一种基于预学习字典的低秩算法,该算法将干净数据和结构化噪声分别表示为字典矩阵和系数矩阵的乘积,同时在重构误差和低秩结构之间建立联系。预学习的字典可以表示小数据集中的子空间,可以提高图像的去噪性能。此外,基于训练数据得到的映射矩阵可以用于处理未参与训练的新样本。采用对称ADMM将优化模型的目标函数分解为若干个子问题进行求解,大大减少了数据集中恢复出干净数据的计算量并加快了算法的迭代速度。最后在AR数据集上的实验表明,该方法从噪声数据中恢复具有低秩结构的干净数据方面优于其他方法。