1. 引言
中耳炎(OM)是鼓膜后方中耳腔和颞骨的气腔与咽鼓管覆盖的黏膜发生感染而导致的一种炎症 [1] 。其症状包括耳剧痛、耳溢液、鼓膜穿孔、耳道化脓感染等,常见的中耳炎类型有急性中耳炎(AOM)和慢性化脓性中耳炎(CSOM)。急性中耳炎(AOM) [2] 是与上呼吸道感染密切相关的炎症,临床表现为耳膜鼓包、耳道红肿、分泌物增多、耳胀。慢性化脓性中耳炎(CSOM) [3] 是一种持续性、隐匿性的中耳炎症状表现,会持续2周以上向外耳道排出分泌物,并常伴有鼓膜穿孔症状。阻塞性耳垢(EarWax)通常积聚在外耳道。一般来说,耳垢可以防止鼓膜被灰尘和其他微小粒子引发感染,但外耳道阻塞性耳垢长时间堆积后未脱落会引起耳道发炎感染,伴随疼痛、耳鸣和听力下降症状,严重时会造成继发性急性中耳炎 [4] 。
耳镜成像、声反射术、超声评估、鼓室测量等方式对中耳炎疾病的检测起了很大的作用 [5] 。临床上通常使用电子耳镜检查耳膜的状态,该设备包含小型照相机、卤素光源、低功率放大镜,以及连接到计算机实现存储图像 [6] 。医生通过获得的鼓膜图像进一步对患者进行评估诊断,后续诊断准确率完全依靠于医生的诊治经验,相关研究表明,在临床检测中,188名耳鼻喉科医生诊断中耳炎的准确率仅为73% [7] ,且不同医生对相同患者的诊断结果相差较大。若不及时治疗,严重时会造成面部神经麻痹、听力损失、颅内感染和认知障碍等并发症 [8] ;而过度诊断则会导致抗生素滥用现象,并造成患者用药不当的医疗事故 [9] 。因此,中耳炎的准确诊断在耳道疾病治疗过程中至关重要。
目前,随着人工智能和计算机视觉技术的不断革新,机器学习方法开始广泛应用于医学图像分析 [10] 。鉴于人工诊断过程中,其准确性受限于医生的个体医疗技能水平,越来越多的研究者开始使用机器学习技术来实现中耳炎诊断。Mironica等人 [11] 采用包括K-最近邻(KNN)、多层感知机(MLP)以及支持向量机(SVM)等在内的六种不同算法,在所采集的耳镜图像上进行实践。实验结果表明,支持向量机(SVM)表现出最佳的分类效果,其准确率达到了72.04%。Myburgh等人 [12] 提出了一种利用图像处理技术和决策树(DTs)的中耳炎诊断模型,用于区分五个不同类别,包括外耳道阻塞性耳垢、正常鼓膜、化脓性中耳炎(AOM)、中耳炎溢液和慢性化脓性中耳炎,其采用特定的特征提取算法来分析鼓膜图像,并将相关特征输入到决策树中。实验结果显示,该模型达到了80.60%的准确率。Shie等人 [13] 设计了一种用于中耳炎的计算机辅助诊断系统。其使用了不同类型的滤波器来提取特征,针对四类中耳炎(正常、化脓性中耳炎(AOM)、粘液性中耳炎(OME)和慢性化脓性中耳炎(COM)),准确率为88.06%。Kruvilla等人 [14] 提出了一种基于词汇表和语法集的自动化算法,这些词汇表和语法集分别对应于鼓膜的数值测量和决策规则,来用于确定中耳炎的诊断类别。该算法在正常、化脓性中耳炎(AOM)和粘液性中耳炎(OME)类别的分类中取得了89.9%的准确率。Barasan等人 [15] 提出了一种基于Faster R-CNN和预训练的卷积神经网络结合的分类模型,用于区分正常和异常的鼓膜。使用Faster R-CNN自动确定鼓膜图像中鼓膜的位置。该过程生成一个覆盖鼓膜的补丁,而不是完整的鼓膜图像。得到图像补丁在VGG-16上训练,最终得到90.48%的分类准确率。
上述研究工作中,传统机器学习方法通常依赖于冗长的人工特征提取的过程,这个过程繁琐且耗时,由于耳内镜下鼓膜图像的特征较复杂,人为特征提取极大程度受到主观因素影响。而基于深度学习的经典卷积神经网络的参数量和计算复杂度较高 [16] ,模型过大时难以部署在移动设备上运行。因此,能否针对耳镜下中耳炎数字图像的复杂特征,利用轻量化卷积神经网络克服现有方法的不足,同时提高中耳炎诊断的准确率,是本文研究的重点。
针对上述问题,本文提出了一种基于轻量级卷积神经网络MobileNetV2的中耳炎诊断模型CIH-MobileNetV2。首先,对于现有耳内镜下鼓膜数字影像数据集规模有限与深度学习网络所需训练数据量大的矛盾,采用图像增强技术扩充数据集样本。其次,融入轻量化坐标注意力机制CA (Coordinate Attention),既能获得图像通道信息,又保留了特征的方向信息,增强了网络模型对数字耳镜影像特征的分析能力;同时利用改进注意力特征融合模IAFF (Iterative Attentional Feature Fusion)来替换网络结构中简单的特征层相加功能,获取跨通道下不同大小尺度的特征;其次,使用HardSwish激活函数替换原始ReLU6函数,提升了模型的鲁棒性;最后,对模型通道数进行缩减,减少了模型参数量,降低模型复杂度。实验结果表明,本文所提出的方法有效提高了对中耳炎不同类别诊断的准确率,同时减轻了对移动设备的性能要求,为轻量型中耳炎识别模型部署在移动设备上的研究提供了相应参考。
2. 模型方法
2.1. MobileNetV2模型
MobileNet网络 [17] 是专门针对移动端设备和资源受限环境下而设计的轻量化神经网络架构。其采用了深度可分离卷积结构,将传统3 × 3卷积结构分离成3 × 3逐通道卷积和1 × 1逐点卷积,在不降低网络精度的前提下,大幅度减少了模型参数量,训练时间更短。
MobileNetV2 [18] 的模型结构如下表1所示,其在提出的V1版本上进行了改进,除了保留深度可分离卷积结构以外,主要特点表现为瓶颈层中的倒置残差结构(Inverted Residual, IR),倒残差结构在3 × 3逐通道卷积模块前引入1 × 1逐点卷积,以提升逐通道卷积模块的特征表达能力,同时采用残差连接实现特征复用,有效提升训练效率。为了避免ReLU激活函数所导致的低维特征丢失问题,瓶颈层中最后一个卷积层采用线性激活函数替代ReLU激活函数。倒置残差模块如图1所示。

Table 1. Structure of MobileNetV2 network
表1. MobileNetV2网络结构
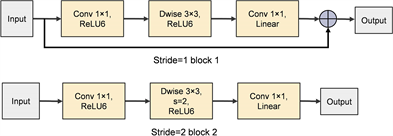
Figure 1. Structure diagram of the inverted residuals module
图1. 倒置残差结构模块图
2.2. CIH-MobileNetV2模型
针对耳镜下中耳炎影像诊断任务,本文设计了CIH-MobileNetV2模型,由于本文实验所用中耳炎影像数据集背景复杂,存在病变区域分布不均、病变区域面积大小各异等特点,且原始MobileNetV2网络在数据集上表现效果较次,为提高模型在分类任务上的性能表现,本文实验对初始模型进行一系列改进,改进后模型内部构造如图2所示。
与原始MobileNetV2相比,本研究首先在倒置残差模块中1 × 1降维卷积 Linear 层后引入坐标注意力机制,增强网络在图像训练过程中对目标区域的特征提取能力;其次采用迭代注意力特征融合模块替换原始瓶颈层中特征相加机制,以此融合跨层级不同尺度的特征,避免遗失小区域特征信息;然后将深度可分离卷积模块中ReLU6激活函数替换成HardSwish函数,保留训练样本中正负特征信息,以提升模型的鲁棒性;最后,缩减模型通道数,降低模型参数量,以便模型更利于部署在移动设备中。
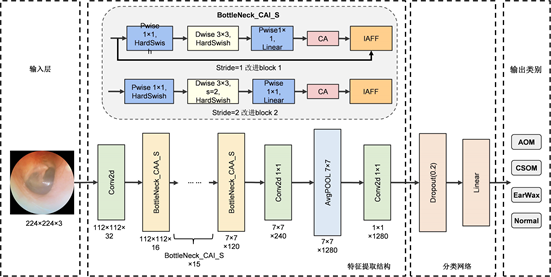
Figure 2. Structural diagram of the CIH-MobileNetV2 model
图2. CIH-MobileNetV2模型结构图
2.2.1. CA注意力机制
在神经网络中,卷积核仅关注输入图像的局部特征,而忽略全局表征对局部的影响。在网络中引入注意力机制不仅能提高对图片特征的提取能力,同时使网络更加关注到目标区域,提升任务效能。
CA (Coordinate attention)注意力是Hou [19] 等人针对移动网络设计提出的坐标注意力机制,旨在将位置信息嵌入通道注意力中,从而增强网络模型特征学习的表达能力,获取目标更详细的特征信息,同时也避免了产生重大的计算开销。如图3所示,CA注意力机制作用到网络模型分为两个步骤,第一步为坐标信息嵌入,第二步为坐标注意力生成。
在坐标信息嵌入过程中,为了避免二维全局集合造成的位置信息损失,坐标注意力机制将通道注意分解为两个并行的一维特征编码过程,使用尺寸为(H, 1)或(1, W)的平均池化核对每个通道的水平方向和垂直方向进行编码,得到沿X方向和Y方向的感知特征图,如公式(1)、(2)所示。其中
和
分别表示经过一维全局平均池化后第c通道在高度h处以及在宽度为w处特征输出张量。
(1)
(2)
通过上述两种变换可分别获得沿两个空间方向的聚合特征,生成一对方向感知特征图。在坐标注意力生成阶段,将获取的宽度方向和高度方向的特征图进行Concat拼接操作,通过1 × 1卷积变换函数F1,送入Sigmoid 非线性激活函数生成大小为
的融合特征图
,如公式(3)所示。
(3)
按照空间维度将得到的特征f分解成两个不同方向张量
和
,再使用 1×1 卷积的线性变换和分别将通道数量恢复至原始规模C,经过Sigmoid激活函数后分别得到水平方向注意力权重
与垂直方向的注意力权重
,如公式(4) (5)所示。
(4)
(5)
最终将水平方向输出权重
和垂直方向注意力权重
,与输入特征X在相应的坐标位置进行加权融合,得到最终的坐标注意力输出特征图
,如公式(6)所示。
(6)
2.2.2. IAFF特征融合模块
简单的特征融合通常采用求和(summation)或连接(concatenation)的线性计算对来自不同层级或分支的特征进行组合,这种融合方式会造成跨层后特征权值质量下降,导致模型表现受限。为了更好地融合跨层级架构中语义和尺度不一致的特征,以及避免丢失小目标上下文信息,本研究引入可迭代注意特征融合模块IAFF (Iterative Attentional Feature Fusion) [20] ,以进一步提高神经网络的表征能力。
为了缓解尺度变化和小目标所带来的问题,在多尺度通道注意模块(MS-CAM)中,如图4(a)所示,其中r为通道缩减比。其关键思想是通过改变空间池化的大小,在多个尺度上实现通道注意融合。MS-CAM结构在获得全局上下文特征同时引入局部特征分支,通过逐点卷积(PWConv)模块作为局部上下文聚合器,同时较普通1 × 1卷积而言,大幅度减少了参数量,最终得到的注意权重通过加权平衡全局特征与局部细微特征信息。在通道注意力模块中结合局部和全局的上下文特征。初始输入特征X经过瓶颈结构运算得到的全局特征通道注意力
和局部特征通道注意力
,得到的细化特征
,相应公式如下:
(7)
(8)
其中
表示通过MS-CAM模块产生的注意权重,
表示批标准化(Batch Normalization),
表示为ReLU激活函数。
如图4(b)所示,普通AFF模块在MS-CAM模块的基础上,将基于注意力的特征融合从同层场景推广到跨层场景,包括短跳连接和长跳连接,以及涵盖多个特征内部的初始整合。在AFF模块中,对于两个特征图
,默认情况下Y是具有更大感受野的特征图。计算公式为式(9),其中Z为融合后的特征,
为融合权重,结构图中虚线表示为
。初始对输入的两个特征 X,Y 进行元素级简单相加特征融合,经过sigmoid激活函数后,融合特征权值范围在0~1之间,同时经过减1计算,使得网络在后续训练过程中在X和Y之间进行软选择或加权平均,来确定不同特征的权重。
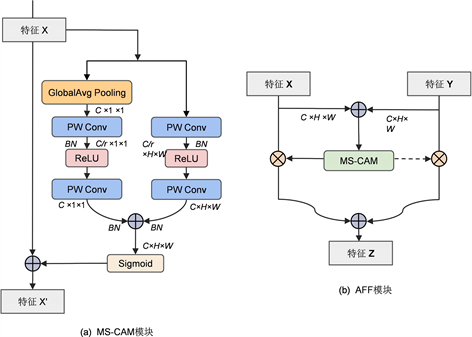
Figure 4. The structural of MS-CAM module
图4. MS-CAM模块及AFF模块结构图
(9)
在实际场景应用中,初始特征融合仅关注到对应输入特征简单相加,而如何集成初始特征特性,保证特征融合质量对最终输出权重产生的影响,本研究最终采用可迭代注意特征融合模块替换瓶颈层特征简单concat模式,即在普通AFF基础上,使用额外AFF融合模式来生成更细粒度的初始特征输入,具体公式如下所示,IAFF结构如图5所示。
(10)

Figure 5. The structural of IAFF module
图5. IAFF模型结构图
2.2.3. HardSwish激活函数
ReLU激活函数是网络训练中最常用的激活函数 [21] ,在加速网络收敛的同时解决了梯度消失的问题,缓解了过拟合现象的发生。公式表现如式(10)。ReLU6函数是ReLU函数的一种改进,公式如式(11),原始正值输出范围被抑制为6,这使得在移动端设备低精度计算中具有较好的数值分辨率。但在具体任务训练中,随着网络学习的不断深入,Float16所表示的数值范围受限,当激活函数输出值超过其数值时,精确度则大幅度下降,导致信息丢失;同时函数的输入值为负时,其输出梯度始终为0,会造成神经元无法更新参数、直接失活的现象,从而影响模型的学习能力。
(11)
(12)
为了克服上述ReLU函数与ReLU6函数存在的缺点,本文使用HardSwish激活函数 [22] 替换模型中原有ReLU及ReLU6函数,函数图像如图6。HardSwish是Swish函数的近似体,计算模式简洁,是无上限的轻量级非线性激活函数,能够提高推理性能,降低损失能耗;且在零值附近的梯度表现更佳平滑,在训练中能够避免梯度爆炸,增强模型训练的稳定性和可靠性。具体计算公式如下。
(13)

Figure 6. Comparison the images of ReLU and ReLU6 with HardSwish activation functions
图6. ReLU及ReLU6与HardSwish激活函数的对比图
2.2.4. 模型通道数调整
上述所提出的改进策略能有效提升模型的表达能力,但在一定程度上增大了参数量,实际医用中会造成相应系统开销。在MobileNetV3模型中,研究者将初始卷积通道数减少为原来的一半,为了防止减少过多通道数导致模型精度大幅度降低,因此,本研究将瓶颈层中超过64的通道数缩减少1/4,其他通道数不变,得到的新瓶颈结构记为Bottleneck_CAI_S,改进后模型CIH_MobileNetV2的结构表如下表2所示。
Table 2. Structure of CIH_MobileNetV2 network
表2. CIH_MobileNetV2网络结构
3. 实验及结果分析
3.1. 数据集
本文所使用数据集建立在CTG ANALYSIS研究小组公布的开源鼓膜影像数据集Tympanic_Membrane的基础上 [23] ,该数据集共包含956幅耳镜影像,获取于2018年10月至2019年06月期间在Özel Van Akdamar医院接受治疗的中耳炎患者处,该数据集中共包括9类耳镜下鼓膜图像,但由于数据集中某些类别样本数量过少(10张以内),且存在黑暗、模糊等非有效视觉特征,故本文只关注急性中耳炎(AOM)、慢性化脓性中耳炎(CSOM)、耳内道阻塞性耳垢(EarWax)以及正常鼓膜(Normal)的分类。
针对原数据集图像数据不足以及部分类别分类有误的情况,本研究在耳科临床专家的进一步分类筛选下,整合了Viscanio等人与智利大学临床医院耳鼻喉科合作创建并公开的鼓膜影像数据集Datos [24] ,构建出全新的中耳炎影像数据集。该数据集中共包括1517张图片,其中急性中耳炎(AOM)图像共119张,慢性化脓性中耳炎(CSOM)图像共283张,外耳道阻塞性耳垢(EarWax)图像共360张,正常鼓膜(Normal)图像共755张。数据集详细情况如表3所示,数据集样本图像展示为图7所示。
Table 3. The category distribution of dataset
表3. 数据集类别分布
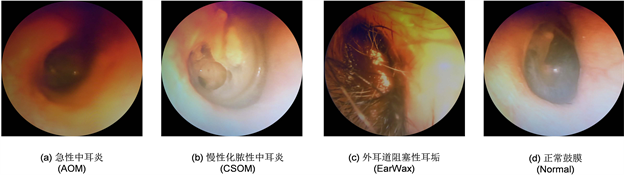
Figure 7. Images of tympanic membrane samples and category labels. (a) Acute otitis media (AOM); (b) Chronic purulent otitis media (CSOM); (c) Obstructive earwax of the external auditory canal (EarWax); (d) Normal tympanic membrane (Normal)
图7. 部分鼓膜样本图像及类别标签。(a) 急性中耳炎(AOM);(b) 慢性化脓性中耳炎(CSOM);(c) 耳内道阻塞性耳垢(EarWax);(d) 正常鼓膜(Normal)
3.2. 数据预处理
本文将实验数据集按照8:2的比例随机划分为训练集与测试集,并且在训练集中随机抽取20%作为模型的验证集,用于评估模型的泛化能力。为了防止由于数据集规模较小且样本间不平衡造成模型训练过程中出现过拟合现象,以及提高模型分类的准确性。本研究对训练集中不同类别图像进行相应数据增强操作,由于耳镜影像具有一定的特征表达性,为避免对数据集中鼓膜形态结构造成干扰,本研究仅针对训练集影像进行水平、垂直翻转,旋转90度,旋转180度,旋转270度,水平方向平移,中心裁剪以及随机光照、随机对比度、随机饱和度等多种增强方式,样本增强部分示例表现如图8所示。
Figure 8. Image examples of data augmentation (a) Rotate 90 degrees; (b) Rotate 180 degrees; (c) Rotate 270 degrees; (d) Horizontal flip; (e) Vertical flip; (f) Horizontal translate; (g) Random brightness; (h) Random contrast; (i) Random saturation; (j) Center clipping
图8. 数据增强示例。(a) 旋转90度;(b) 旋转180度;(c) 旋转270度;(d) 水平翻转;(e) 垂直翻转;(f) 水平平移;(g) 随机光照;(h) 随机对比度;(i) 随机饱和度;(j) 中心裁剪
3.3. 实验环境及参数设置
本文实验环境基于Ubuntu18.04操作系统,使用Pytorch1.10深度学习框架、Python3.9编译环境、Anaconda操作软件、CUDA架构以及PyCharm编译器。硬件平台配置CPU为Intel(R) Core(TM) i5-8200@1.30 GHz,内存为64GB,GPU为2张NVIDIA RTX 2080Ti 12GB。
在实验过程中,所有样本图片统一设置成224 × 224像素大小输入网络进行训练,使用Adam优化器来更新模型权重以及偏差参数,初始学习率设置为0.0001,动量参数为0.9,批处理大小batch size设为16,训练周期为100轮。相应超参数如下表4所示。
Table 4. The hyperparameters of experiments
表4. 实验超参数设置
3.4. 评价指标
本文实验为中耳炎多分类任务,考虑到实验数据集存在样本数据量不平衡的问题,为了更加客观地评估各模型在该数据集上的性能表现,本实验选择混淆矩阵、准确率Accuracy、精确率Precision、召回率Recall以及F1 Score作为模型的综合评价指标 [25] ,计算公式如下。
(14)
(15)
(16)
(17)
其中,
表示样本被正确预测为第i类,实际真实类别也为第i类的样本量;
表示除去第i类的其他类别样本被正确预测为对应类别的样本量;
表示非第i类的样本被预测为第i类的样本量;
表示真实类别为第i类但被错误预测为其他类别的样本量。
3.5. 消融实验及结果
为了验证在MobileNetV2模型上相应改进方法对提高模型表现能力的有效性,在同一数据集下对不同改进方法的模型进行消融实验。其中,当仅使用坐标注意力机制时,将CA注意力模块嵌入到MobileNetV2瓶颈层的倒残差结构中;当仅使用IAFF特征融合结构时,将原倒残差结构中简单特征相加部分进行替换;使用HardSwish激活函数替换原有ReLU6函数;以及缩减模型通道数的情况。实验中,使用测试准确率(Accuracy)、F1 Score以及模型参数量作为评价指标,具体结果如表5所示。
Table 5. Results of ablation experiments
表5. 消融实验结果
注:“-”表示在原始MobileNetV2网络中未引入该方法,“√”表示在原始MobileNetV2中使用该改进方法。
上述结果表明,在初始MobileNetV2模型倒置残差结构中嵌入CA注意力机制,训练所得模型在测试数据上的准确率以及F1 Score分别提升了1.98和3.05个百分点;使用IAFF迭代注意特征融合结构替换原始特征简单相加方式,所得模型相应准确率提高了0.99个百分点,F1 Score提高了1.82个百分点;通过将ReLU6函数调整为HardSwish激活函数,所得准确率以及F1 Score分别提升了0.66和1.39个百分点。最终,通过嵌入坐标注意力机制、优化模型特征融合方式替换激活函数以及的模型改进策略,改进后模型在中耳炎数据集上的准确率与F1 Score表现较未改进MobileNetV2模型而言,分别提升了2.31和3.57个百分点。为了更直观地展示本研究提出的CIH-MobileNetV2在中耳炎分类任务上的有效性,测试数据集在初始MobileNetV2和改进后CIH-MobileNetV2模型上混淆矩阵详细情况如下图9所示。
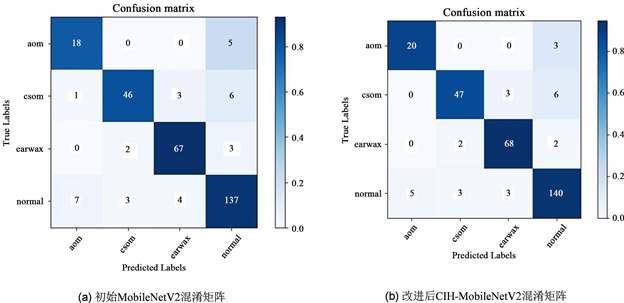
Figure 9. The confusion matrix of the model on the test set. (a) Initial MobileNetV2 confusion matrix; (b) Improved CIH-MobileNetV2 confusion matrix
图9. 模型分别在测试集上所得混淆矩阵。(a) 初始MobileNetV2混淆矩阵;(b) 改进后CIH-MobileNetV2混淆矩阵
3.6. 不同模型对比实验及结果
为了更好的验证CIH-MobileNetV2模型在本文任务上的有效性,将改进后的CIH-MobileNetV2模型与目前深度学习领域图像分类任务中经典网络AlexNet、GoogleNet、VGG16、ResNet18、ResNet50、ShuffleNetV2进行对比实验。在相同中耳炎数据集以及运行环境下,以测试集准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1 Score、模型参数量、FLOPs作为评估指标。训练过程中,各分类模型在训练集上的损失值及在验证集上的准确值变化如图10所示,相应指标数值如下表6所示。
Table 6. System resulting data of standard experiment
表6. 标准试验系统结果数据
由上表数据可得,改进后模型同轻量化模型ShuffleNetV2相比,在测试集中准确率和F1 Score分别高出3.64%和4.78%,同经典分类模型AlexNet、GoogleNet、VGG16、ResNet50相比在准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1 Score有明显的提升,且参数量大幅度下降,在确保模型性能表现的同时,更好地符合模型轻量化的要求。训练过程中,各模型在训练集上的损失值及在验证集上的准确值如图10所示,训练得到的模型在测试集上得到的相关混淆矩阵如下图11所示。
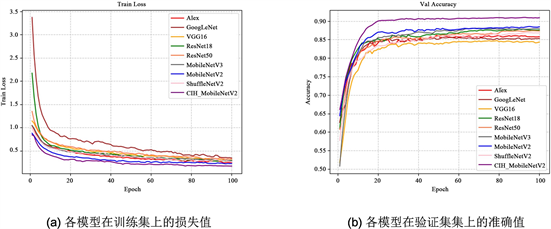
Figure 10. Improved model iteration curve. (a) The loss of each model on the training set; (b) The exact values of each model on the validation set
图10. 改进模型迭代曲线。(a) 各模型在训练集上的损失值;(b) 各模型在验证集上的准确值
为了更好的体现本研究提出的中耳炎诊断模型在实际分类中的准确性,将所训练完成的模型权重对测试集内图像进行测试,具体表现如下图12,可以得出,本研究所设计模型能够得到较好的诊断结果,能为中耳炎诊断提供有效帮助。
4. 结论
本文研究以中耳炎病变类别为对象,提出了一种融合CA注意力机制以及IAFF特征融合模块的中耳炎诊断模型CIH-MobileNetV2,并引入HardSwish激活函数替换原有瓶颈层中ReLU6激活函数,最后缩小卷积结构内部通道数,以此减少模型参数量,降低模型大小,节约了计算成本。
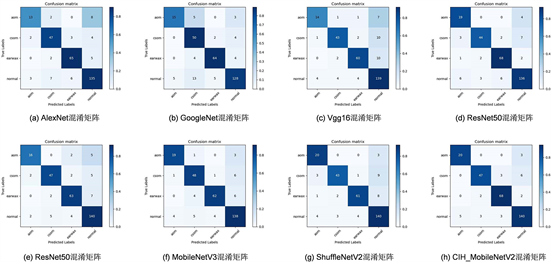
Figure 11. The confusion matrix representation of each model on the test set
图11. 各模型在测试集上的混淆矩阵表现

Figure 12. The predict results of CIH-MobileNetV2 on the test set
图12. 改进CIH-MobileNetV2模型在测试集上预测结果
实验结果表明,本文提出改进方法能兼顾高精度以及轻量化两大要求,在对比经典分类网络AlexNet、GoogleNet、VGG16、ResNet18、ResNet50中,改进的CIH-MobileNetV2网络在性能表现上效果更佳,分类准确率达到了91.05%,F1 Score为89.18%,从而验证了本文方法的有效性。
后续工作中,将着眼于扩大数据规模,从而提升中耳炎识别模型的泛化能力。并且在实际临床场景中,识别准确率会受到耳镜下数字影像背景环境的影响,因此,在复杂背景中,在模型轻量化的前提下,进一步提高模型准确率是未来研究的目标。
基金项目
本研究得到了国家重点研发计划(2021YFB2802300)的工作支持。