1. 引言
雾是一种视程障碍物,是由大量悬浮在近地面空气中的微小水滴或冰晶组成的气溶胶系统。雾对光有吸收和散射作用,有雾图像可以看作是被雾衰减的反射光与被大气散射光的叠加。雾的存在会导致成像时对比度低、信噪比低、色彩失真,进而对大量依赖计算机视觉处理的自动驾驶、智能农业等视觉应用领域造成很大影响。
目前关于去雾算法的研究中,通常认为不引入深度神经网络的传统去雾算法包括基于图像增强和基于图像复原两种思想进行图像去雾的算法,其中以Rizzi等人 [1] 提出的自动色彩均衡(Automatic Color Enhancement, ACE)去雾算法和He等人 [2] 提出的暗通道先验图像(Single Image Haze Removal Using Dark Channel Prior, DCP)去雾算法分别作为基于图像增强和图像复原思想的去雾算法的代表,这两种思想也为后来的去雾算法研究产生了深远的影响。随着深度学习技术的发展和GPU算力的提升,深度学习算法成为了当前多种视觉任务的主流研究方向,通过引入深度神经网络对图像特征信息进行提取可以端到端地恢复出无雾图像,但同时需要一定量数据集来训练深层网络。根据输入是否为配对数据集可以大致分为无监督学习去雾算法和监督学习去雾算法两大类。其中,在无监督去雾算法分支中,Ren等人 [3] 提出了利用GAN进行去雾的算法(Dehaze-GAN),该算法采用U-Net体系结构的端到端生成式对抗网络训练方案,提取和缩放有雾图像的暗通道图,然后与模型中的特征进行融合。Zhu等人 [4] 提出的用于图像映射和语义转换的循环对抗生成网络(Cycle-GAN),采用同时训练两组生成器和判别器的形式来保持循环一致性,除了循环一致性损失和应用了一个拉普拉斯金字塔网络来处理高分辨率的图像外,还通过增加循环感知一致性损失来增强单幅图像去雾网络的结构稳定性,从而训练得到生成器、全局或局部测试鉴别器等,最终预测出去雾图像。然而,对抗神经网络的结构复杂、生成器训练时约束难度大以及训练周期过长导致出现计算复杂度高、去雾效率低等缺点。在监督去雾算法分支中,基于配对数据集进行训练的监督学习去雾算法是目前使用较为广泛的算法,Cai等人 [5] 提出了端到端单幅图像去雾算法(An End-to-End System for Single Image Haze Removal, DehazeNet),利用CNN网络估计出有雾图像中的大气光照和透射率参数进行去雾图像的预测,能够根据不同图像的特征自适应地调整参数,以获得更准确的去雾结果。Ren等人 [6] 提出了一种多尺度卷积网络来预测从粗到细的传输图将先验信息融入到卷积层中,从而提取出有雾图像的特征。粗尺度卷积神经网络的输出为粗略的透射率图,该透射率图将作为细尺度卷积神经网络的输入。以上算法对大尺度图像的预测能力较低,对图像噪声较为敏感。针对以上问题,Wang等人 [7] 提出一种端到端的透射率和大气光联合估计去雾网络。通过共享特征模块获取透射率和大气光共有的全局特征,通过基于金字塔结构的两个并行的分支分别估计透射率和大气光,将预测值代入大气散射模型从而推导出出无雾图像。然而,此算法在分别估计透射率和大气光时,容易出现累积误差,影响去雾效果。
本文算法引入大气散射模型,用于对输入图像进行真实物理信息量化,采用基于U-Net的网络模型用于输入图像不同尺度下的多特征提取,通过该网络还原场景深处细节,此外,针对深度神经网络训练梯度消失和收敛速度过慢的问题,在网络中加入深度监督模块 [8] 对主干网络进行深度监督。本文算法将物理信息模型、多尺度提取的卷积、深度监督模块相结合,构建出了一个可以快速高效提取空间信息且轻量化的端到端去雾网络。
2. 相关工作
2.1. 多尺度特征融合相关研究
对于传统的CNN网络,需要输入一个固定尺寸的图像,这个固定尺寸的图像可以通过裁剪或变形等方法获取,而如果通过裁剪获得生成图像,图像就会丢失掉未被裁剪到的信息,如果通过变形获得生成图像,图像就会拉伸、变形,所以无论哪种方式都会对原始图像造成不必要的破坏,影响最终模型的精度。基于不破坏原始图像信息的思想,空间金字塔池 [9] (spatial pyramid poolingnetwork, SPP-Net)的结构可以接受不同尺寸的图像,输出固定尺寸的特征向量,并且可以做到在图像变形情况下仍表现稳定。SPP-Net可以将任意尺寸的图像对应的特征图转化为固定维度输出,如此一来,就可以将图像进行缩放等操作变换成不同尺寸的图像,然后输入到带有SPP层的CNN中即可得到多尺度特征。SPP-Net对于处理不同的尺度、尺寸和长宽比是十分灵活的解决思路,同时大大提高了图像特征提取的鲁棒性。此外,多尺度无序池化层 [10] (multi-scale orderless pooling, MOP)算法中将池化层进行了大量的改进和优化,利用将图像分为3个level的架构:其中level 1为原始图像,level 2将图像分成很多小尺寸的patch,level 3将图像分成更小尺寸的patch。level 1直接提取Fc特征得到一个特征向量;level 2将各patch缩放到CNN输入大小,然后按level 1的处理方法提取patch的Fc特征,最后利用加积门局部描述符的矢量算法(vector of locally aggregated descriptors, VLAD)进行特征聚合得到一个特征向量;level 3处理方法同level 2。三个level的特征合并即得到多尺度特征信息。以上算法的提出打破了传统的卷积神经网络要求输入图像尺寸固定的限制,便于从输入图像中读取多维度特征并进行融合。借鉴上述多尺度特征融合思想,Li等人 [11] 提出一种轻量化的一体化去雾网络(An all-in-one network for dehazing and beyond, AOD-Net),该算法引入大气散射模型并重新制定的大气散射模型公式。大气散射模型对去雾算法的研究提供了重要的科学依据,柯斯密德(Koschmieder)定律 [12] 将气象能见度与大气消光系数联系起来,推演证明二者呈反比关系:
 (1)
(1)
AOD-Net算法区别于以前的大多数模型分别估计传输矩阵和大气光架构,而是通过一个轻量级的CNN端到端地生成干净无雾的图像。该算法对大气散射模型进行了进一步的衍生之后得到公式(2):
(2)
并引入了变量
做了进一步整合,将图像的特征量融合进入
中,在给定默认偏差常数b的数值为1,即可通过
复原出无雾图像
:
(3)
的表示公式可以转换为:
(4)
2.2. U-Net网络的引入
Ronneberger等人 [13] 提出的U型全卷积神经网络(U-Net)正是基于上述思想。该体系结构由一个捕获上下文的收缩路径和能够实现精确定位的对称扩展路径组成,U-Net网络架构如图1所示:
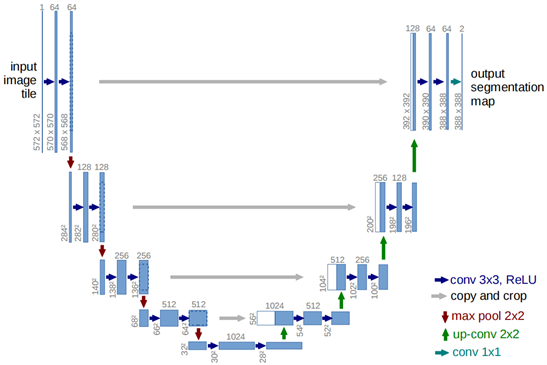
Figure 1. U-Net’s network architecture
图1. “U-Net”网络架构
每个蓝色框对应于一个多通道特征图,通道数在输入张量(tensor)的数量表示在方框的顶部表示,左下角表示特征图的尺寸,白色框表示复制的特征映射,不同颜色的箭头表示不同的操作形式,通过模型示意图可以看出这是一个对称性比较强,深度为四层的U型的结构,U-Net网络包含对称的编码器和解码器结构,通过这些结构可以有效地捕获不同层次的特征信息。之后Zhou等人 [14] 提出了基于U-Net网络的U-Net++网络的算法设计思路引入多尺度融合、密集连接和改进的上采样等策略,U-Net++结构虽不是专门为去雾算法提出的深度学习网络,但其先进性和泛化性在去雾算法研究领域得到了广泛验证和应用。
基于密集特征融合的多尺度增强去雾网络 [15] (Multi-scale boosted dehazing network with dense feature fusion, MSBDN-DFF)的提出了是基于U-Net体系结构的具有密集特征融合的多尺度增强去雾网络,该方法基于增强反馈和误差反馈两种原理进行了设计,并证明了该方法适用于去雾问题。即通过在该模型的解码器中加入增强–操作–减去增强策略,构建了一种简单而有效的增强解码器来逐步恢复无雾图像,并且为了解决在U-Net架构中保留空间信息的问题,设计了一个使用反投影反馈方案的密集特征融合模块。结果表明,密集特征融合模块可以同时弥补高分辨率特征中缺失的空间信息,并利用非相邻特征。
3. 本文算法
3.1. 算法网络框架
本文整体网络架构如图2所示,网络深度为4层,第一层为了尽可能地保留细节信息,首先将原图像进行无损失的4份等尺度裁切操作,随后使用1 × 1的卷积核进行维度的变换,与尺度缩为裁剪后每张图像尺寸一致的图像合并进入卷积操作,第二层是在上层无损失的4份等尺度裁切操作的基础上再做4份等尺度的裁切操作,再通过1 × 1的卷积核进行维度的变换,与尺度缩为裁剪后每张图像尺寸一致的图像合并进入下一步卷积操作,第三层原理同上。加入下采样卷积层和最大池化层,进一步推断图像的空间深度信息。第四层则为典型的全卷积编码–解码结构,用于对输入的带有提取后特征信息的张量和目标图像的特征重构。充分利用图像各个层级的特征,加强特征提取和表达,有效提升网络利用率。

Figure 2. The overall network architecture of the algorithm in this article
图2. 本文算法整体网络架构
在模型的训练阶段,本文算法是从有雾图像集合
中提取图像之后进入第一层网络,进行无损裁剪和等比例缩放操作之后大小、通道数、维度为448 × 448 × 3 × 5,即为集合:
;输入第二层网络中进行卷积和池化操作,然后再次一次进行更小尺度的裁剪之后与分割后对应维度的全高清尺度:大小、通道数、维度为256 × 256 × 3 × 21的集合
进行对比损失计算 [16] 。
本文结合了重新制定的大气散射模型,如公式(5)所示:
(5)
提取出有雾图像的不同尺度和区域内更为准确的参数函数
,最终反推出相对应的真实图像,本文算法单层的网络算法示意图如图3所示:

Figure 3. Schematic diagram of single-layer network algorithm in this article
图3. 本文算法单层网络示意图
输入和输出特征图尺度的不同决定了网络的层数的深浅,整体的解码结构原理在各层类似,此外,对于第二层之后的卷积网络进行了卷积层数的优化,加入了深度监督层(DeepSupervision-Net, DSN),DSN的引入可以提高了隐藏层特征质量的直接性和透明度,改善不同层的收敛率,提高了深度网络的训练效率和梯度消失问题。深度监督的添加在隐藏层位置如图4所示,在网络结构中添加DSN在损失函数的选取上有了更大的有效性和兼容性。
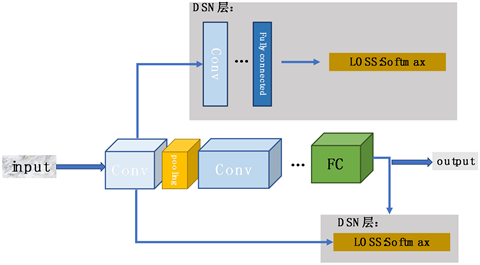
Figure 4. The position where the “DSN” layer is introduced in the hidden layer
图4. “DSN”层在隐藏层引入的位置
加深网络层级和DSN思路之后,在网络的中间层添加额外的损失函数,以便从不同层次和特征表示中获得监督信号。这有助于提供更多的梯度信号,促进网络的训练和优化。在输出层会增加Softmax函数作为神经网络激活函数使用。在神经网络的最后一层,将原始的线性输出通过Softmax函数转化为概率分布,可以使得网络的输出更具有可解释性和可比较性。同时,Softmax函数的导数计算相对简单,有利于梯度传播和参数更新的稳定性。
3.2. 损失函数
在公式(6)中,利用
表示主干网络中第n个神经元权重值,
表示DSN层中第n个神经元权重值,分别算出主干网络和DSN层分支的损失:
(6)
(7)
再由公式(6)和公式(7)分配权重之后,可以得到联合损失函数公式,其中
表示随训练完全迭代t轮(t个epoch)后得到的衰减值:
(8)
(9)
另外,本文算法最终的解决回归问题采用的是基于均方差函数(MSEloss)和结构相似性损失函数(SSIM Loss)来实现控制监督学习中生成的去雾后的图像和GroundTruth之间的像素残差,在公式(10)中,衡量了模型生成的输出与目标值之间的差异。在设计
函数时,首先需要定义模型的输出值和目标值。假设模型的输出像素值
,目标值为
,则
可以定义为:
(10)
在公式(11)中,
和
分别代表预测像素和目标像素的平均值,
和
分别表示预测像素和目标像素的方差,
是预测像素和目标像素的斜方差,
和
是用于避免分母为0带来系统错误的两个常数。
 (11)
(11)
在公式(12)中,
是一个权重系数,用于平衡MSEloss和SSIM Loss的重要性,经过验证,
最终选取0.29时,可以取得更好的效果:
(12)
4. 实验部分
4.1. 实验配置
实验在Ubuntu18.04操作系统下运行,硬件为Intel(R)Core(TM)i7-8750H、16GBRAM、NVIDIA GTX1080GPU,使用的编程语言和用以训练网络的深度学习框架分别是python和pytorch. Adamoptimizer,衰减率
和
分别采用默认值0.9和0.999,网络的初始学习率为0.002,batchsize为4,训练迭代次数为150,000次,学习率从迭代的第50,000次开始每10,000次衰减10%。实验使用真实单图像去雾(REalistic Single Image Dehazing, RESIDE)公开数据集 [17] 和基于3D引擎渲染的自建数据集进行组合训练。训练集在预处理时,将不同尺度的图像输入到不同的网络分层结构当中去,大尺度图像统一成全高清尺寸:1920 × 1080,再对其进行裁剪和缩放,使之作为下一个尺度区间的输入,最小的输入参数为:256 × 256,最终在BN层将像素值归一化到区间[0, 1]。
4.2. 公开数据集对比实验
本节实验选择了RESIDE数据集进行学习,该数据集共包含13,990张合成模糊图像,其测试集由综合目标测试集(SOTS)和混合主观测试集(HSTS)组成,旨在表现出多种评估观点。由于室内合成雾图在实际应用中的价值较低,因此本节主要是为了对比不同算法在户外场景下的去雾效果。对比实验所使用的算法选取了具有较强代表性的传统去雾算法以及基于深度学习的去雾算法,具体包括:DCP算法、Dehaze-Net算法、YOLY算法 [18] 、DCPDN算法 [19] 、GFN算法 [20] 、RefineDNet算法 [21] 、AOD-Net算法、FAMED-Net算法和MSBDN-DFF算法。真实户外场景下不同算法的对比实验如图5所示:

Figure 5. Comparative experiments on different algorithms of “RESIDE Outdoor”
图5. “RESIDE-Outdoor”不同算法的对比实验
通过图5对比图可以直观的发现:DCP算法的对比度明显是最高的,但是在天空和景物的交界处会出现隔离带状的晕影,AOD-Net在预测结果上回出现远处雾气无法去除的现象,FAMED-Net和MSBDN-DFF算法在颜色方面失真减小,但是在细粒度特征较密集的地方涂抹感较重,导致细节丢失,相比之下,本文算法在细节颜色恢复等方面具有明显的优势。
选取RESIDE数据集中的500张室外有雾图像和自建测试集中50张有雾图像评估不同算法对合成有雾图像的去雾性能,定量比较去雾结果时,SSIM和PSNR作为评估指标,二者的值越高,表示去雾图像与Ground-Truth越相似。实验结果如表1所示:

Table 1. Comparison of experimental results between PSNR and SSIM based on the test Dataset RESIDE in real scenarios
表1. 基于真实场景下测试数据集RESIDE的目前典型算法PSNR和SSIM实验结果对比
4.3. 自建数据集对比实验
在图像去雾领域,高质量的数据集对于模型训练、验证模型泛化能力等至关重要,数据集越大,内容越丰富,表示数据集质量越高。受气候、天气等不确定因素的影响,想要捕获到完全一致的场景下的无雾、有雾的配对图像是极其困难的。当前主流的图像去雾开源数据集包括RESIDE、NH-HAZE等。RESIDE数据集中图像尺寸大小不一致,需要在读取数据时对其进行修改,但此操作会造成细节丢失,同时这些图像通常是在真实场景下拍摄,通过使用大气散射物理模型量化调整出的参数人工合成的得到的,不仅在主观感受上,合成雾图与在雾天环境下直接捕获的有雾图像存在很大差异 [22] ,而且在训练网络时,最终的预测结果会遵循合成数据的单一性,从而导致真实场景下学习能力的不足。NH-HAZE数据集的制作方式是在真实场景下使用雾化器模拟有雾环境,制作成本高且效率低。其他开源数据集大多规模太小,不足表达数据的所有特征。因此本文算法在使用RESIDE等公开数据集比较各个方法的同时还自建了一份配对数据集用以增强模型的泛化效果。
相较于目前最常用的通过大气散射模型在实际拍摄的照片上人工增“雾”的手段,通过使用3D游戏引擎自带的天气系统制作配对数据集的方式是行之有效的。“AnvilNext3.5”版本游戏引擎的环境渲染功能十分强大,3D场景规模相对宏达,内容主要为自然景观,显示内容丰富多彩,具有更加细腻的画面表现力和更加复杂的光影效果,对清晰图像的细节恢复帮助很大。利用可调节天气系统的3D引擎对其场景进行手动截图,可以快速高效地制作出两张完全配对的有雾、无雾对比图像,这不仅是对现有数据集数据量的增补,更是提供了一种全新的数据集制作方案。目前自建数据集的训练集和测试集规模分别为1000对和50对全高清尺寸的配对图像,包含城镇、街道、丛林、山峦等不同户外场景。
本节实验使用自建数据集的测试集来比较不同算法的去雾能力,预测结果对比实验如图6所示:
从图6红色矩形虚线标注框位置可以直观地看出,相较于目前较为典型的去雾算法,本文算法在对比度的恢复上更加自然,近景细节恢复和天空与高处的结合处过渡自然清晰,还原出的颜色在真实度上和Ground-Truth更为拟合。DCP算法在还原结果上远近景处的失真的白色轮廓,AOD-Net算法的预测结果出现近处去雾不彻底的现象,导致多出景色细节分辨不清,MSBDN-DFF算法虽然去雾更彻底,在远处细节和颜色恢复与本文算法还有一定差距,本文算法在在泛化性上有更突出的优势。

Figure 6. Comparative experiment on prediction results of different algorithms on self built datasets
图6. 自建数据集下不同算法的预测结果对比实验
此外,本节实验内容是利用自建数据集进行训练的对比实验主要验证:在保证所需要训练的模型大小相近的不同去雾算法的前提下,重新对类比模型进行加入大尺度自建数据集进行训练,加入大气散射模型和负责估计深度和含雾浓度的函数
之后,结合了不同滤波器的多尺度特征比较几类典型算法的去雾效果和在同样配置的服务器上训练的拟合时间。不同模型加入自建数据集进行训练后所需时间对比结果如表2所示:
Table 2. Comparison of time required for training different models with self built datasets
表2. 不同模型加入自建数据集进行训练后所需时间对比
由表2,在保证了整个网络结构轻量化的同时,增加了训练样本大小和深度监督模块之后,训练阶段的收敛时间有明显提升,证明了深度监督模块和U-Net网络的高效性,另外,再增加了训练样本之后,本文算法在大尺度模拟场景下的直观预测效果也有较大优势,直观的类比图如图7所示:

Figure 7. Comparison diagram of self built dataset training experiment
图7. 自建数据集训练实验对比图
由图7可以看出,在红实线标注处的较远的景物,本文算法的无损裁切的优势体现出来,在远景的细节恢复上,本文算法强化了较远处细粒度特征的提取能力。不同模型加入自建数据集进行训练后各自的PSNR和SSIM实验结果对比如表3所示:
Table 3. Comparison of PSNR and SSIM experimental results of different models trained on self built datasets
表3. 不同模型加入自建数据集进行训练后各自的PSNR和SSIM实验结果对比
表3中黑色加粗数字表示效果最好的数值,因此可以得出结论:本文算法的预测结果不仅在主观的颜色复原和对比度复原上更加贴近真实无雾图像,在量化的PSNR和SSIM值上也有明显优势。
4.4. 消融实验
鉴于本文算法在U-Net网络层中加入了深度监督模块用于提升模型梯度传播和训练的稳定性,并且加快网络的收敛速度,为了验证其有效性,本节实验的主要设计方案是对比在隐藏层中加入深度监督模块和屏蔽该模块之后相同迭代次数下收敛情况的对比。训练过程是否加入“DSN”模块的效果对比如图8所示:
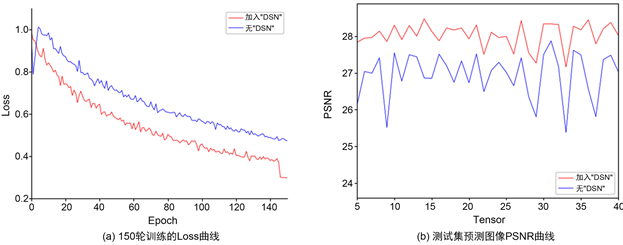
Figure 8. Comparison of the effects of adding the “DSN” module during the training process
图8. 训练过程是否加入“DSN”模块的效果对比
由图8(a)可知,进行150轮训练后,红色曲线表示加入了“DSN”模块的拟合曲线,蓝色曲线表示无“DSN”模块的拟合曲线,而蓝色曲线在训练过程一直处于红色曲线的上方充分表明在加入“DSN”模块后收敛效果和收敛速度都有明显改善;由图8(b)可知,在测试集测试中加入“DSN”模块后预测结果的PSNR值波动更小,效果更佳,并且更稳定。此外,为了防止过拟合,对比试验使用早停策略,在验证集上的loss不再降低时停止训练,以避免模型在训练数据上过度拟合,有无“DSN”模块的收敛时间对比如表4所示:
由表4可以看出,屏蔽“DSN”模块后,模型训练经过约16,000次迭代后停止训练,训练时间持续66分钟,相比之下加入“DSN”模块后,模型训练经过约15,000次迭代后停止训练,训练时间持续仅用时48分钟。由此可以得出:深度监督模块通常可以帮助网络更快地学习有用的特征表示,监督信号在网络的多个层次上都提供了梯度信号。不仅缓解梯度消失的问题还有助于加速网络的收敛,提高训练的稳定性。
Table 4. Comparison of convergence time with and without “DSN” modules
表4. 有无“DSN”模块收敛时间对比
5. 结论
本文将基于多尺度特征融合的U-Net网络应用到去雾研究中,通过引用大气散射模型提取图像的物理量化信息,尽可能多地还原出不同尺度下的真实环境信息,通过对高清图像进行不同维度的特征融合和深度监督策略,在保证不同规模数据集的学习效果的同时,进一步保证了预测结果的稳定性,构建出了兼顾轻量与高效的去雾网络。本文算法可以在去除雾气的同时保留更多的细节信息,尤其远景去雾效果比较明显。
致谢
恭敬在心,不在虚文。