1. 引言
精确的径流预报模型对于水资源规划及综合开发利用,水利枢纽运行管理等重大决策问题提供基本决策依据,对国民经济健康发展具有十分重要的意义。由于影响流域河川径流变化因素很多,如蒸发、降水、气候和地下河流等,它们之间的变化机制和相互影响的因素十分复杂,其过程表现出强烈的非线性特征 [1] [2],要完整而准确地描述这样一种复杂非线性性过程,传统的欧式几何和动力系统模型预测极为困难,因此流域内径流建模是一项具有挑战性的任务 [3] [4] [5]。目前国内外对中长期径流预测研究主要的方法有成因分析法、统计分析法、灰色系统分析法、小波分析法等 [6]。应用较为广泛统计建模方法主要有三种:自回归(Auto Regressive Mode1, AR)模型、移动平均(Moving Average Mode1, MA)模型和自回归移动平均混合(Auto Regressive Moving Average Mode1, ARMA)模型,这三种模型均可根据历史资料制作多步预测,但预测得到的结果都接近序列的平均值,对未来预测精度不高。而近年来随着计算机硬件和智能计算方法的发展,基于数据驱动的机器学习方法获得迅速发展,其本质上就是从观测样本数据中学习数据输入模式空间与输出空间的广义函数映射关系,建立数据输入和输出之间的知识和规律,并利用这些知识和规律对未来数据或无法观测的数据进行推断、决策和预测 [7] [8] [9]。如经典有监督机器学习方法神经网络模型,在建立模型时不需要考虑的径流物理过程,将预测系统构造的神经网络学习矩阵看作是输入与输出之间的一种非线性映射,而实现这种非线性映射关系,并不需要事先知道所研究的预报系统内部结构,而是通过对有限的样本作学习训练,以模拟预报系统输入与输出的内部结构关系 [10] [11] [12]。由于神经网络方法具有很强的处理非线性问题的能力,比一般的方法具有更好的预测能力,它为径流建模分析和预测提供了新技术、新方法 [13] [14] [15]。然而随着径流数据的收集越来越多和存储数据能力的不断增长以及计算机运算能力的飞速发展,对复杂数据建模的精度要求越来越高和预测时间区间尺度要求越来精确,而神经网路方法需要有经验的工程技术人员通过反复训练和测试,网络才能在实际应用中获得一个稳定的解决方案,加之复杂数据的多源和异构,使得神经网络模型在使用中会出现过拟合或者欠学习的问题 [16] [17],这极大限制神经网络在实际径流预测建模中的应用,从而使得研究新的机器学习方法越来越重要 [18] [19]。
近年来在循环神经网络(Recurrent Neural Networks, RNN)基础上发展的长短期记忆神经网络(Long Short-Term Memory Neural Networks, LSTM),在处理时间序列数据时具有记忆过去和对过去信息采用非线性动力系统控制的优势 [20] [21],通过误差反向传播和梯度下降算法求解网络参数达到目标误差最小,在时间序列建模问题上不但可以记忆相邻序列重要信息,而且能够记忆模型长期依赖的关键信息,忽略不必要的信息 [22] [23] [24],已经成为深度机器学习重要模型之一。LSTM是在循环神经网络基础上提出的,循环神经网路最早的模型是1982年和1984年美国加州工学院物理学家John Hopfield提出的可用作联想存储器的互联网络Hopfield神经网络模型,他先后发表了两篇论文介绍了离散时间反馈神经网络网络(Discrete Hopfield Neural Network, DHNN)和连续时间反馈型神经网络网络(Continuous Hopfield Neural Network, CHNN) [25]。随后,在1986年Rumelhart等人,Werbos等人和Elman等人改进Hopfield 神经网络模型提出循环神经网络(Recurrent Neural Network, RNN),其主要是以时间序列数据建模和预测为目的,网络的结构与标准多层感知器的结构类似,在按照时间序列的推进方向进行递归且所有节点或者循环单元按链式法则连接的前向神经网络系统 [26] [27] [28],不同之处在允许与时间延迟相关的隐藏单元之间进行连接,通过这些连接模型可以保留有关过去的信息,使它能够发现数据中彼此事件之间的时间相关性。
循环神经网络具有高维的隐藏状态和非线性动力学,使它们能够记忆和处理过去的信息,并且参数共享并且图灵完备,因此在对序列的非线性特征进行学习时具有一定优势 [29],先后被成功应用在自然语言处理、语音识别、语言建模、机器翻译等领域有应用,也被用于各类时间序列预测建模 [30]。但是,循环神经网络实际应用也存在很多缺陷,其中最大缺陷就是训练网络参数时,误差梯度在经过多个时间步的反向传播后容易导致参数与隐藏状态的动力学之间的关系非常不稳定,包括梯度消失和梯度爆炸 [31]。在1997年由Hochreiter & Schmid Huber在循环神经网络的隐层引入了存储单元状态(Cell State)和门结构调节网络中信息流的门控机制取代传统的感知器架构扩展了RNN架构 [32],初步形成LSTM的架构,梯度消失问题得以解决,并在近期被Alex Graves进行了改良和推广 [33]。目前LSTM已变得越来越流行,机器学习范式并被成功应用到经济、交通量、语言识别和手写体识别等多个领域 [34] [35] [36]。
在使用机器学习方法建立径流模型时,有两个重要因素需要考虑:一是选择数据的特征,二是选择恰当的机器学习模型。在径流序列建模研究时如何选取与径流相关性的建模因子,并且排除多重变量相关因素之间的影响是径流建模首要考虑的因素。为此本文依据径流时间序列的系统状态具有不同时期前后依赖的特征,利用魏凤英、曹鸿兴提出的均生函数模型思想构建一组周期函数 [37] [38],通过分析原序列与这组周期函数间的统计关系,提取系统不同振荡周期特征形成建模因子,并结合长短期记忆神经网络对在非线性时间序列记忆特征和非线性时序动力系统控制的优势,建立柳江径流机器学习模型。
2. 基于均生函数的长短期记忆神经网络模型
2.1. 均生函数建模的原理和方法
均生函数(Mean Generating Function, MGF)建模主要是基于动态时间序列系统状态前后具有依赖的记忆思想,把原始序列以及它的一阶差分、二阶差分按照不同时间间隔计算均值,构建周期函数及其延拓序列。通过分析原序列与这组周期函数间及其延拓序列的统计关系,建立回归预测方程,其目的就是将动态的时间序列分析转化为静态数据分析,将单一的要素通过不同的因子生成方式,转化为包含不同预报信息的多个预报因子序列 [39] [40]。原理为:
设某一时间序列为
(1)
式中n为样本长度,则序列的平均值为
, 则均值生成函数为:
(2)
式中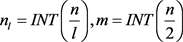 ,INT表示取整,对均生函数
按照式(3)做周期延拓计算由此构造均
,INT表示取整,对均生函数
按照式(3)做周期延拓计算由此构造均
生函数延拓序列矩阵
(3)
(4)
同时为对原始序列
再分别计算一阶差分和二阶差分后再次计算均生函数并延拓获得一阶差分和二阶差分矩阵,对3个延拓的均生函数序列矩阵的信息熵计算采用由此可以获得:
(5)
其中I为对分类预测的信息熵评分,
为i类事件与j类估计事件的列联表中的个数,挑选出预报信息熵(Information Entropy, IE)相对高的延拓均生函数序列作为建模因子。
2.2. 长短期记忆神经网路建模方法
假设给定一个时间序列
,传统时间序列模型是建立自回归模型进行预测,具体表达式如下:
(6)
其中p为延迟阶数,
为回归系数,
为白噪声,LSTM针对时间序列问题,后续每一时刻有外部输入时,则模型演变成有外部输入的非线性自回归模型时间序列模型:
(7)
其中
为利用神经网络模拟估计逼近函数。原始RNN的隐藏层只有一个h状态,它对于短期的输入非常敏感,很难实现自身反馈和记忆状态。LSTM通过增加一个存储单元状态c来实现,让网络保存长期的状态。在t时刻,LSTM单元模块有三个输入:(1) 当前时刻网络的输入值
;(2) 上一时刻LSTM的网络隐层输出值
;(3) 上一时刻网络单元状态的输出
;LSTM的网络输出有两个:当前时刻LSTM网络隐层输出值
,和当前时刻网络单元状态的输出
,具体LSTM网络模块结构如图1所示。
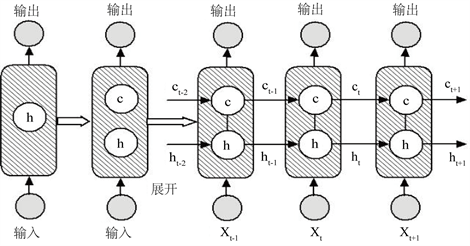
Figure 1. LSTM neural network model structure and fold diagram
图1. LSTM神经网络模型结构和展开图
LSTM隐层记忆单元具有的遗忘门、输入门和输出门使得网络具有记忆单元长短时记忆机制,该机制一致地确定要保留的信息,要保留的时间以及何时从存储单元读取信息。在存储单元状态中配备三个门结构门,即:遗忘门、输入门和输出门。通过门控单元可以对存储单元添加和删除信息,有选择地决定信息是否通过,采用sigmoid神经网络层和一个成对乘法操作组成,该层的输出是一个介于0到1的数,表示允许信息通过的多少,0表示完全不允许通过,1表示允许完全通过 [41] [42] [43]。LSTM的建模过程隐层单元的结构图如图2所示。

Figure 2. Structure diagram of the hidden layer unit of LSTM
图2. LSTM的隐层单元的结构图
遗忘门决定上一时刻的单元状态有多少“记忆”可以保留到当前时刻,其计算模型如下:
(6)
而输入门根据上一次的输出
和本次输入
来计算当前输入的单元状态,避免当前无关紧要的内容进入记忆,决定当前时刻网络输入
有多少保存在单元状态
中,其计算模型如下:
(8)
用于描述当前输入状态
的计算模型如下:
(9)
这是一个tanh激活函数生成新的候选值
,它作为当前层产生的候选值会添加到单元状态中,当前时刻输入的单元状态
计算模型如下:
(10)
则模型的输出
的计算,首先是先通过
层来得到一个初始输出,然后使用tanh将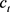 缩放到−1到1间,再与
得到的输出逐对相乘,从而得到模型的输出,具体计算如下:
缩放到−1到1间,再与
得到的输出逐对相乘,从而得到模型的输出,具体计算如下:
 (11)
(11)
(12)
以上公式中
是权重矩阵,
是偏置项,
表示把两个向量连接成一个更长的向量,
是门的激活函数,表达式如下:
(13)
LSTM主要是求解以上8个参数,损失函数是交叉熵损失函数,表示为:
(14)
采用梯度下降的误差反向传播算法(Back-Propagation Through Time, BPTT)求解模型的参数,首先确定参数的初始化值,然后向前计算每个神经元的输出值;反向计算每个神经元的误差项值,LSTM误差项的反向传播包括两个层面:空间层面上将误差项向网络的上一层传播,时间层面上沿时间反向传播,即从当前t时刻开始,计算每个时刻的误差。每个权重(即参数)具体推导和计算过程见文献 [44] [45]。
2.3. 柳江径流建模过程
本文利用柳江原始径流和一阶差分序列的均生函数生成径流序列延拓矩阵,并利用信息熵筛选建模因子作为神经网络输入训练集,建立非线性自回归外生输入神经网络(Nonlinear Auto Regressive with External Input by Neural Network, NARX-NN)和长短期记忆神经网络(Information Entropy and Long Short-Term Memory Neural Network, IE-LSTMNN)的径流模型,具体计算过程如图3和图4所示。
3. 应用实例及其结果分析
3.1. 建模数据
本文建模的数据选取广西柳州市老桥口柳江径流2001年1月1日~2010年12月31日期间10年每天12时的径流(m3/s)数据进行应用实例分析,全部的数据3652个,图5为3652个柳江径流数据实况。

Figure 3. Flow chart of NARX-NN runoff modeling
图3. NARX-NN径流建模流程图
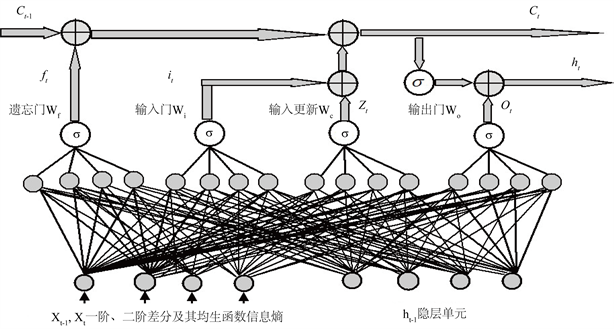
Figure 4. Flow chart of IE-LSTM runoff modeling
图4. IE-LSTM径流建模流程图
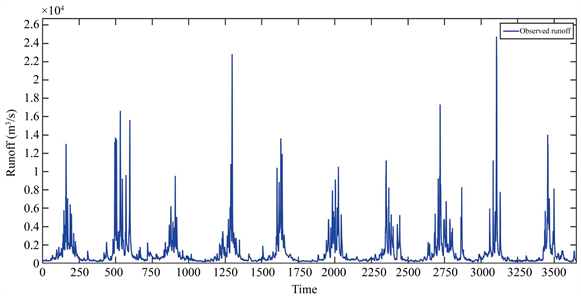
Figure 5. Liujiang River runoff of 3652 actual observed from January 1, 2001 to December 31, 2010
图5. 从2001年1月1日~2010年12月31日3652个柳江径流实际观测值
在机器学习方法中,利用有监督学习方法建立模型时,通常会设置一定比例的验证数据集(Validation Set),使用训练数据集去训练模型,使用验证集去评估模型的泛化能力,其目的防止对训练数据集(Training set)过度训练而导致最小化过度拟合。为此把数据分为训练数据集合训练模型参数、验证数据集合调整优化模型参数和测试数据集合检验模型实际预测效果,其中2001年1月1日到2007年12月31日共计2556个数据作为训练数据集合建立径流拟合模型,2008年1月1日至2009年12月31日共计731个数据作为验证数据集合优化校验模型,2010年1月1日到2010年12月31日共计365个数据为测试数据集合检验预测模型效果。柳江每年5月份进入汛期,10月份汛期结束,为了较为准确预测灾害性洪水,本文把径流大于5000 (m2/s)作为洪水峰值来预测,表1是训练数据、验证数据和测试数据样本和洪水峰值样本总数情况,图6是不同数据集中径流峰值分布示意图。

Table 1. Training, validation and test data samples and statistics table of the total number of flood peaks
表1. 训练、验证和测试数据样本和洪水峰值总数统计表
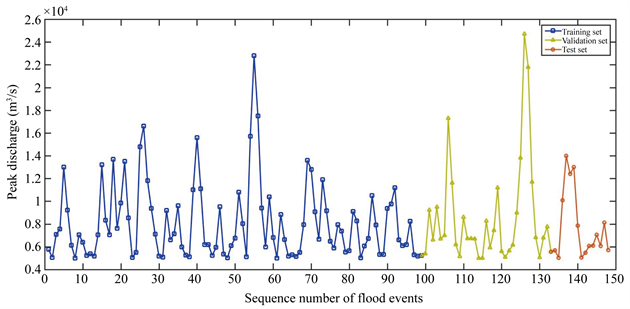
Figure 6. Distribution of peak runoff in training, verification and test data sets
图6. 训练、验证和测试数据集中径流峰值分布情况
3.2. 模型性能评价
本文引入以下4种统计指标:
(1) 均方根误差(Root Mean Square Error, RMSE):
(15)
(2) 平均绝对百分比误差(Mean Absolute Percentage Error, MAPE):
(16)
(3) Pearson相关系数(Pearson correlation coefficient, PCC)
(17)
(4) 纳什效率系数(Nash-Sutcliffe Efficiency coefficient, NSE):
(18)
式(15)~(18)中、
分别代表径流实际值和模型的输出值,
分别表示径流实际值平均值和模型的输出值平均值,n为样本个数,在纳什效率系数的基础上,提出洪水峰值模型预测性能评价指标:
(5) 峰值纳什效率系数
(19)
式(19)中、
分别表示洪水峰值实际值和预测洪水峰值输出值,
表示洪水峰值的平均值,p为洪水峰值期间样本个数。性能评价指标(1)和(2)是衡量实际径流值和模型计算值的偏离程度,其值越小说明模型的预测性能越好;性能指标(3)主要是看模型能否对径流的趋势做出正确的判断,其值越大就说明模型能够较为准确把握径流未来趋势;性能指标(4)和(5)是验证径流模型结果的好坏,NSE取值为负无穷至1,越接近1表示模型的效果越好,模型可信度高;NSE接近0表示模型结果接近观测值的平均值水平,即模型总体结果可信,如果NSE远远小于0则模型是不可信的。
3.3. 结果分析
表2是两种模型对柳江径流训练数据集的拟合结果性能统计表,图7是两种模型对训练数据集中径流峰值拟合效果,从表2的结果可以看出IE-LSTM模型对训练数据集中的RMSE和MAPE性能指标均小于NARX-NN模型,说明IE-LSTM模型拟合值和真实值之间的偏离程度最小,拟合精度高于NARX-NN模型;同时可以看出IE-LSTM模型对训练数据集的Pearson相关系数为0.9978,而NARX-NN模型为0.8807,二者比较接近,说明这两种模型均可以对径流趋势做出较为准确的拟合,IE-LSTM模型拟合精度高于NARX-NN模型。
Table 2. Performance indicators of NARX-NN and IE-LSTM models for training samples
表2. NARX-NN和IE-LSTM模型对训练样本计算结果性能指标统计表
从纳什效率系数指标考察这两种模型,NARX-NN模型置信度只有17.84%,置信度很低;而IE-LSTM模型对径流峰值置信度很高,可以达到98.50%。说明IE-LSTM模型相对NARX-NN模型具有很好的学习能力、对径流峰值跟踪能力。本文涉及两种神经网络方法均是通过训练数据集来调整网络的权重,通过验证数据集校验网络性能,在训练过程中训练数据集性能误差减小,而验证数据集的性能误差保持不变或升高,则停止网络训练过程,以此找出效果最佳的模型所对应的参数,用来对测试数据集(Test set)预测。

Figure 7. The fitting result of two different models on the peak discharge in the training data sets
图7. 两种不同模型对训练数据集中径流峰值拟合效果
表3是两种模型对柳江径流验证数据集的预测结果性能统计表,图8是两种模型对验证数据集中径流峰值预测效果,从表3的结果可以看出,IE-LSTM模型的性能指标RMSE和MAPE均小于NARX-NN模型,性能指标PCC和NSE均大于NARX-NN模型,在对验证数据集中径流峰值预测中,IE-LSTM模型置信度高达0.9917,而NARX-NN模型置信度只有0.2130,这些结果进一步说明IE-LSTM模型对验证数据集的预测误差精度小、趋势预测和实际观测值高度一致,对径流峰值预测置信度很高;对比表2和表3,结果显示IE-LSTM模型对训练数据集的RMSE为126.2828,对验证数据集的RMSE为129.1887,二者非常接近,说明IE-LSTM模型没有过拟合,可以用训练好的模型对未来进行预测。
Table 3. Forecasting performance indicators of two models for validation samples
表3. NARX-NN和IE-LSTM模型对验证样本预测结果性能指标统计表
有监督机器学习的主要任务就是利用建立的模型并实现对未来的精准预测,训练数据集和验证数据集训练得到的模型能否适用于待测试数据集的新数据,即模型具有泛化能力。因此,当在评估模型的性能时需要重点考察训练好的机器学习模型在新数据上准确率如何,这样才有把握用它对未来做出高质量的预测结果。表4是两种模型对柳江径流测试数据集的预测结果性能统计表,图9是NARX-NN模型对365个测试数据集径流预测效果,图10是IE-LSTM模型对365个测试数据集径流预测效果。图11是两种模型期望输出和目标输出之间相关性以及回归效果。
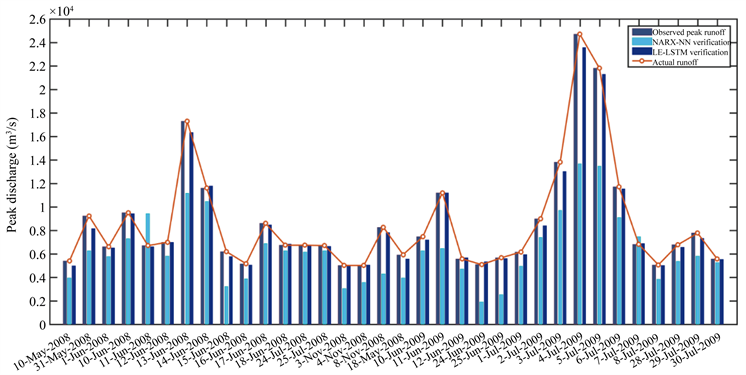
Figure 8. The forecasting result of two different models on the peak discharge in the training data sets
图8. 两种不同模型对验证数据集中径流峰值预测效果
Table 4. Forecasting performance indicators of two models for test samples
表4. NARX-NN和IE-LSTM模型对测试样本预测结果性能指标统计表
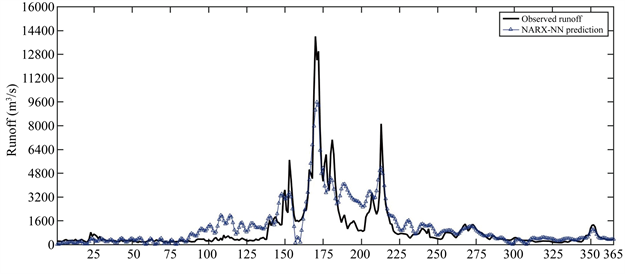
Figure 9. Effect of NARX-NN model on runoff prediction of 365 test sets
图9. NARX-NN模型对365个测试数据集径流预测效果
从表4结果可以看出NARX-NN模型对测试数据集预测的RMSE为843.2273,IE-LSTM模型对测试数据集的预测RMSE为93.0750,显然IE-LSTM模型的RMSE比NARX-NN模型小的多,同样IE-LSTM模型的MAPE也比IE-LSTM模型小很多,这说明IE-LSTM模型的预测值和实际值偏差小,其预测的精度高;对于PCC性能指标,NARX-NN模型是0.6730,IE-LSTM模型是0.9941,这说明IE-LSTM模型的预测值和实际观测值高度相关。
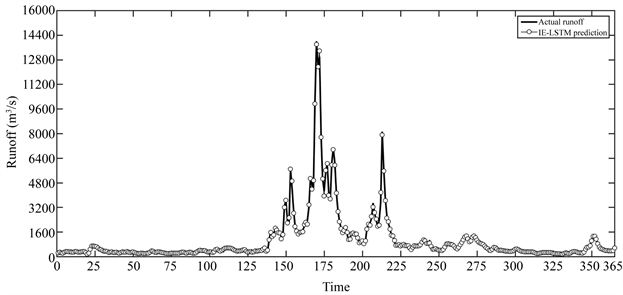
Figure 10. Effect of IE-LSTM model on runoff prediction of 365 test sets
图10. IE-LSTM模型对365个测试数据集径流预测效果

Figure 11. The forecasting result of two different models on the peak discharge in the test data sets
图11. 两种不同模型对测试数据集中径流峰值预测效果
大量数据中离群点(Outline)检测、识别和预测是机器学习挖掘数据中潜在特征重要组成部分,它的任务就是寻找观测值和参照值之间有意义的较大偏差,对这些异常记录的检测、识别和解释有很重要的意义。在一年中绝大多数时间径流数据序列处于稳定状态,每年汛期径流峰值会有很大波动,即整个数据中离群点。如何利用机器学习识别和预测径流峰值是预测灾害性洪水达到时刻和对径流峰值趋势跟踪重要指标,也是检验模型能否预测灾害性洪水以及在实际应用的重要指标。图11是两种不同模型对测试数据2010年6月~8月径流峰值预测效果,从表4的数据性能指标和图11预测效果的结果可以看出,在2010年全年365个数据中,流量大于5000 (m3/s)有15个,其中2010年6月18日径流峰值流量为:10100 (m3/s),6月19日径流峰值流量为:14000 (m3/s),6月20日径流峰值流量为:12400 (m3/s),6月21日径流峰值流量为13000 (m3/s),IE-LSTM模型可以学习径流数据忠离群点,并能准确跟踪离群点,及就是能够预测径流峰值的趋势,而且精度最高。这些结果均说明IE-LSTM模型可以用于预测灾害性洪水,并且能够在实际径流预测建模中应用,而且结果稳定。
4. 结语
流域内径流是水文系统中研究人员关注的重大课题,它关系到水利工程建设和水资源的开发利用,由于径流系统包含着系统空间和时间变化的非线性特性,传统的分析方法很难对它们的演化规律和变化特征做出清晰的了解和准确的预测。针对径流预测建模过程中难以筛选合适的建模因子问题和难以建立有效非线性径流时间序列模型问题,本文利用均生函数延拓矩阵分析原始时间序列周期函数间的统计关系,提取原始序列不同振荡周期特征形成径流建模因子,并结合长短期记忆神经网络对在非线性时间序列记忆特征和非线性时序动力系统控制的优势,建立柳江径流机器学习模型。通过实例计算得出如下结论:
(1) 在利用LSTM建立大规模、非同源异构数据机器学习模型时,如何选择有效数据特征是影响模型性能因素之一,本文利用一阶差分、二阶差分平稳后处理时间序列,在利用均生函数和信息熵复杂数据提取径流时间序列中系统空间和时间变化的非线性特性是一种有效时间序列特征提取技术。
(2) 针对径流非线性时间序列建模过程中,采用“理论 + 实验 + 计算”模式分析数据建立IE-LSTM径流模型,实例计算结果IE-LSTM适宜建立径流模型,对径流汛期峰值趋势跟踪预测效果最好,预测结果精度高,稳定性好。
(3) 本文LSTM建立径流模型,LSTM实质是一种深度神经网络模型,建立模型拟合和预测效果好,但是还有一些问题需要进探讨,如:深度神经网络模型是一种黑箱结构,模型接受输入–输出完成复杂非线性映射,但是无法解释模型表现好的具体原因;机器学习模式是建立在数据满足独立同步分布条件下获得的效果,但是无法判断整个训练数据满足独立同分布的条件;预测数据和验证数据集的增添无法判断其中反馈关系等,这将是下一步需要深入探讨的问题。
基金项目
国家自然科学基金资助项目(No. 41575051,No. 41565005),广西科技厅科技基地和人才专项(No. AD16450003),广西科技厅创新项目(No. 2018AB14003),广西高校中青年教师基础能力提升项目(No. 2018KY0699,No. 2018KY0700,No. 2018KY0701),广西来宾市科学研究与技术开发项目(来科能193305)。