1. 引言
目前针对汽车上的噪声控制方法有主动噪声控制(主动降噪,ANC),和被动噪声控制(被动降噪,PNC)。被动降噪控制的方法通常采用隔声材料、优化车身结构等方式 [1],能够对大于500 Hz的中高频噪声进行有效滤除,在电路上常布置RC滤波电路或者LC滤波电路等方法来实现 [2],这样的控制方法需要采购有较高吸声的材料,较多的元器件来实现,有时会增加整车的整备质量以及整车成本。主动噪声控制则是基于声学中的声波相消干涉原理,通过扬声器发出与初级噪声幅值相等,但相位相反的次级声音来抵消噪声 [3],这才实现了降噪的目的 [4]。相比于被动控制,主动噪声控制更适合用来控制200 Hz以下的低频噪音,降低车内噪音,消除通话回声 [5],提高音效质量。尤其是数字信号处理器(Digital Signal Process, DSP)的发展,让主动降噪系统的运用越发灵活。本文对采用自适应滤波器,对滤波器算法诸如最小均方算法(LMS),以及基于LMS算法改进的归一化最小均方算法(NLMS)、基于最小四阶矩阵的组合算法的定步长算法(LMS/F)和变步长最小均方算法(VSS-LMS)进行了理论梳理,设计自适应滤波器的参数,并对设备上导出的音频信号在Matlab进行代码的实现,以对整个降噪的过程进行仿真并对仿真的结果进行分析。
2. 自适应滤波器及其算法
在主动降噪系统中有两种常见的线性滤波器,分别是有限脉冲响应滤波器(Finite Impulse Response, FIR)和无限响应滤波器(Infinite Impulse Response, IIR)。
2.1. 自适应滤波器种类
2.1.1. 有限脉冲响应滤波器(FIR)
构成自适应数字滤波器的基本部件是自适应线性组合器,FIR滤波器与IIR滤波器的不同在于,该滤波器的脉冲响应在经过N个采样周期后,逐渐衰减为零。设滤波器系数为N,在时间序列为n时,线性组合器的N个输入为
,其输出信号
是这些输入加权后的线性组合,即为:
(1)
(2)
(3)
上式中,
为输入矢量;
为权系数矢量。对系统做z变换,得到系统的传递函数为:
(4)
由于FIR滤波器的(N − 1)个极点全都位于z平面的原点位置,因此系统是稳定的,加之FIR滤波是线性系统,因此FIR滤波器是主动降噪系统中优先考虑的滤波器,其横向结构如图1所示。
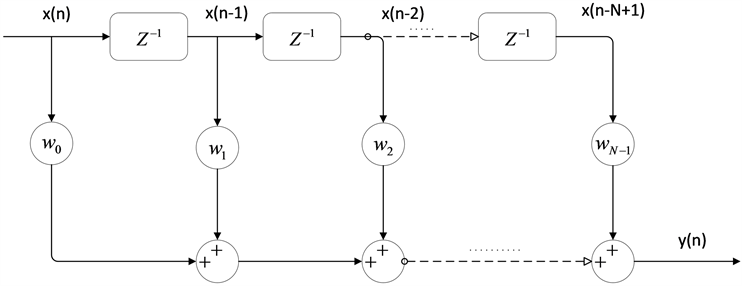
Figure 1. The transversal structure of FIR filter
图1. FIR滤波器横向结构
2.1.1. 无限脉冲响应滤波器(IIR)
FIR滤波器是让信号逐渐衰减至零,但IIR滤波器存在反馈环节,导致系统的输出与当前时刻输入的信号有关系,这种层层迭代的递归特性导致脉冲响应的序列是无限长的。在时间序列为n时,滤波器的输出信号为:
(5)
上式中,M为反馈滤波器阶数;
为n时刻下输入权系数;
为n时刻下递归权系数。
因此该系统的传递函数为:
(6)
由上式可知,IIR滤波器至少存在一个极点不在z平面的原点处,会导致在递归的某个时刻极点会偏移出单位圆,即所谓此时滤波器处于不稳定状态。在稳定性方面,IIR滤波器不如FIR滤波器。常见的IIR滤波器结构如图2所示。
2.2. 自适应算法
自适应滤波算法对抵消含噪声语音的降噪效果较好,因为使用这种方法比其他方法多用了一个参考噪声作为辅助输入,从而获得了比较全面的关于噪声的信息,因而能得到更好的降噪效果。特别是在辅助输入噪声与语音中的噪声完全相关的情况下,自适应噪声抵消法能完全排除噪声的随机性,彻底抵消语音中的噪声成分,无论在信噪比SNR方面还是在语音辨识度方面都能获得较大的提高。其工作原理实
质上以均方误差
或方差
为最小准则,对噪声
进行最优语音增强的目的。
2.2.1. 最小均方算法(Least Mean Square, LMS)
最小均方算法是最常见的自适应算法,其权系数的更新准则是保证其期望信号与实际输出信号之差的平方期望值最小,即最小均方误差最小 [6]。传统的N阶固定步长最小均方自适应算法通常采取如下步骤:
1) 定义滤波输出:
;
2) 定义误差信号:
;
3) 用瞬时梯度得到标准时域的更新公式:
。
上式中,n为时间序列;
为期望输出;N为滤波器系数;
为步长因子,通常是个常数,为保证算法收敛,给出
的取值范围为:
,
是输入信号自相关矩阵的最大特征值。
2.2.2. 归一化的最小均方算法(Normalized Least Mean Square, NLMS)
在自适应滤波算法中归一化最小均方误差法是较为常用的一种算法。虽然LMS算法的运算比较简单并且收敛较快,但是如果输入的音频信号能量较高时,会导致迭代步长的增大,另一方面,若输入的音频信号能量较弱,又会使得迭代步长的减小,这样一来会导致最终的收敛状态不稳定,为了避免对算法收敛造成的影响,在LMS算法的基础上进行归一化处理 [7],即每当滤波器权系数发生变化时,可以通过算法对步长进行调整,对信号能量归一化,使得补偿迭代不会受到信号能量的影响,保证算法的鲁棒性和较快的收敛速度 [8]。
NLMS算法中,通过归一化的方式对迭代步长加以控制,滤波器权系数更新如下式:
(7)
上式中,
为步长控制参数,在仿真阶段取值为0.6;
为输入信号矢量的欧式范数;算法的收敛条件为
,R为输入信号的自相关矩阵,求法为
。
2.2.3. 基于最小四阶矩阵的组合算法(LMS/F)
LMS/F算法是基于基本LMS算法和最小四阶矩阵算法LMF结合而来的。LMF算法又是是在LMS算法上提出的,旨在不改变计算复杂度的前提下,改善LMS在低信号强度下收敛不稳定的问题 [9]。LMF的权重系数更新公式为:
(8)
LMF算法在权系数距离最优解较远时可以比LMS算法收敛更快并且稳态性能更好,不过在权系数距离最优解较近时其收敛速度和稳态性能又不及LMS算法,这导致计算的复杂度大大增加了。为了同时克服LMS和LMF算法的缺点提出了一种LMS/F的算法,兼顾了较高的稳态精度和较简易的计算度。LMS/F的权系数更新公式为:
(9)
上式中,
为阈值参数,为一正值,通过选取合适的值来平衡稳态精度和收敛速度。此文中取
。
2.2.4. 变步长最小均方算法(Variable Step-Size LMS-VSS-LMS)
VSS-LMS算法的基本思想是:在初始收敛阶段或者系统参数发生改变时,权系数与理想的未知的权系数相距较远时,为了保证有较快的收敛速度及对时变系统的跟踪速度,会选取较大的步长 [10]。在算法接近收敛时,会选取较小的步长,以减少稳态误差。此算法的一大特点就在于迭代步长可以根据下式进行调整:
(10)
上式中,
均为常数,并且有
,
。典型的取值有
,
,且有边界条件:
(11)
初始步长通常取
,且步长
是正值,此值的大小收到两个控制常数
的影响,直观上看,最小值通常比较接近正常LMS算法的步长值,耳较大的预测误差会导致步长增大,保证收敛速度的迅速。保证
最大有界的一个充分条件为:
3. 基于Matlab的自适应滤波仿真
3.1. 仿真条件
本文借助Matlab和某车机安卓系统进行自适应滤波降噪的仿真,仿真流程的结构如图3所示。
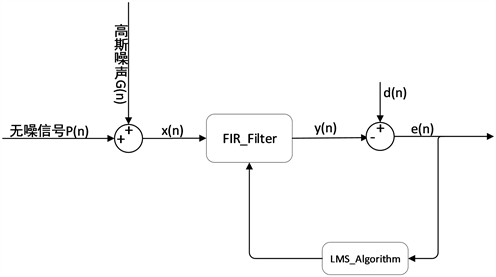
Figure 3. Diagram of the simulation structure
图3. 仿真流程结构图
本次仿真的输入利用安卓车机系统,通过对着麦克风说话来模拟真实司机的实车操作,通过安卓的adb命令将麦克风输入的语音信号以.wav的形式提取出来。
基于某产品车机的实验设备如图4所示,所需的设施需要:
1) 芯科科技的DSP芯片Si47925所在车机开发板,用于处理音频;
2) 开发板线束电源;
3) 2路车载数字麦克风和2路音响,并且集成在线束上;
4) 计算机用于使用adb命令将音源输出到PC路径;
5) 一根安卓数据线用于连接开发板和电脑PC端。
利用adb命令进行录音并保存到PC本地的命令如下所示:
tinycap /sdcard/test.wav –D 0 -d 33 -c 2 -r 48000
adb pull /sdcard/test.wav E:\

Figure 4. Diagram of the simulation equipment
图4. 仿真设备图
其中,/sdcard是安卓linux系统下的地址;-D 0代表设备号;-d33表示DSP芯片的第33号端口是用来输出音频的;-c 2表示频道选择2通道;-r表示采样频率。操作窗口如图5所示。
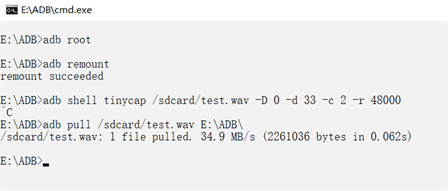
Figure 5. Diagram of exporting audio from Android
图5. 从安卓系统导出音频
3.2. 程序设计
由于本车机并未安装在实车上,并且在较为安静的封闭环境进行语音输入,因此在Matlab中需要额外提取麦克输入的长度并添加高斯噪声来模拟真实场景。基于Matlab的语音输入和噪声添加的代码 [12] 如下:
[y_sign, fs] = audioread('E:\ADB\test.wav'); %本地语音输入
x_sign=y_sign(:,1); %提取输入语音的列向量
speh_in=x_sign'; %转置
input=( speh_in (:,(50001:60000))); %任取10000万个数据
noise = awgn(input,20); %输入高斯噪声
sigwn=input+noise; %合成带噪声的语音信号
随后进行滤波器的初始化,在程序中通过创造零函数来实现 的初始化,代码如下:
X=zeros(1,N); %初始化输入矩阵
W_LMS=zeros(1,N); %初始化权系数
E_nm=zeros(1,10000); %定义误差且与input维数一致
在初始化滤波器之后,再结合之前对信号的采样,计算误差信号得到梯度,回到LMS算法中更新权系数方程,并循环更新直至结束,得到输出序列和误差序列。代码实现如下:
for k=1:n %定义时间序列开始循环
X(1,2:end) = X(1,1:end-1); %输入从初始后开始迭代
X(1,1) = noise(k); %输入的初始值更新
y= W_LMS * W_LMS '; %更新输出
E_nm(k)=sigwn(k)-y; %得到误差值
W_LMS = W_LMS + 2*mu*E_nm(k) .*X %更新权系数
end
在上述代码中,W_LMS代表了基本的最小均方算法的权系数迭代公式,由于改进的LMS算法的本质还是在于由原先的固定步长变为可变步长,因此在代码中最直观的改变是权系数的改变。考虑到对变步长的取值,此处定义步长的最大值
,步长最小值
,而输入的自相关矩阵可用命令下方命令来实现:
R=xcorr(X); %取自相关矩阵R
由此,根据第二节的公式,针对不同的改进LMS算法可对权系数更新代码进行跟新,代码如下所示:
W_LMS = W_LMS + 2*mu*E_nm(k) .*X %LMS算法
W_NLMS = W_NLMS + alfa*((E_nm(k)*X)/(X*X')) %NLMS算法
W_LMSF = W_LMF +mu*((E_nm(k)^3)/((E_nm(k)^2)+0.001)).*X %LMS/F算法
W_VL = W_VL + 2*mu*E_nm(k)*X %VSS-LMS算法
4. 仿真结果及分析
将上节的代码进行整理,于Matlab中进行代码的完成,运行得到仿真结果。其中,初步取定步长
;取NLMS算法的控制参数
,带入权系数更新公式,进行仿真迭代。得到的初始音频信号、噪声信号和带噪信号如图6所示。后续利用四种算法得到滤波后的音频的幅频响应图如下图7~图10所示。

Figure 6. Diagram of the input signal、noise signal and noisy speech signal
图6. 输入语音信号图、噪声图、带噪语音图
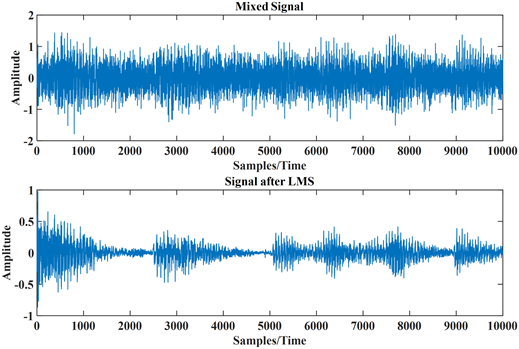
Figure 7. Diagram of the speech signal after LMS algorithm
图7. 经过LMS算法后的语音信号
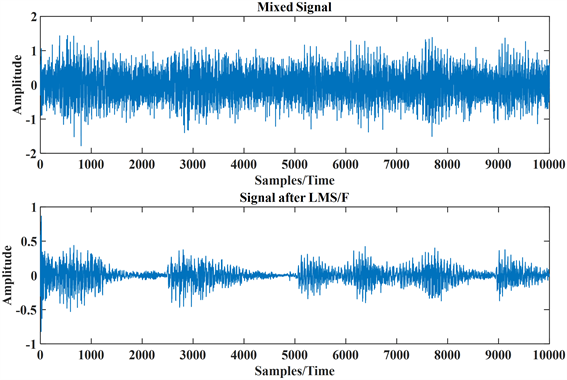
Figure 8. Diagram of the speech signal after LMS/F algorithm
图8. 经过LMS/F算法后的语音信号

Figure 9. Diagram of the speech signal after NLMS algorithm
图9. 经过NLMS算法后的语音信号
4.1. 总体算法性能分析
将各个权系数更新公式中的参数带入代码并运行后,在20 dB的噪声信噪比情况下,取迭代次数为1000次,得到图11所示的结果。其中黑色曲线是NLMS算法,红色曲线是VSS-LMS算法,黄色曲线是LMS/F算法,蓝色曲线是LMS算法。在结果中,四种算法都使得系统达到了稳态。其中,就迭代速度而言,NLMS算法的迭代速度是最快的,但在迭代初期会有较高的突变。VSS-LMS算法的速度其次,基于组合定步长的LMS/F算法是最慢的,但与传统的LMS算法的迭代速度相仿,并无较大区别,可见局部放大图12。四种算法在500次左右均逐步达到稳定,由于稳态误差值无法通过图直观描述,可见后文的表1~表3。

Figure 10. Diagram of the speech signal after VSS-LMS algorithm
图10. 经过VSS-LMS算法后的语音信号
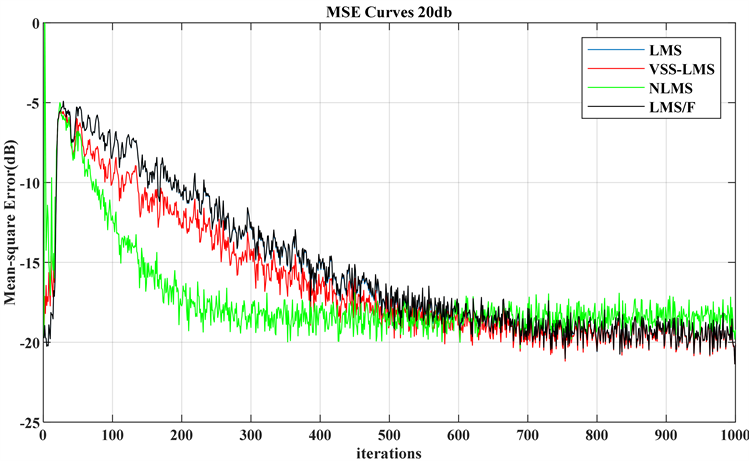
Figure 11. Performance curves of four algorithms with 20 dB noise
图11. 20 dB噪声下的四种算法的性能曲线
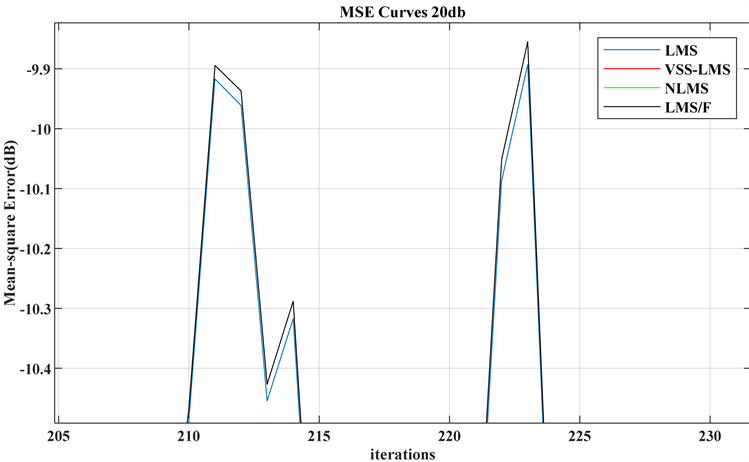
Figure 12. Localzoom between LMS and LMS/F algorithms
图12. LMS和LMS/F算法的局部放大比较
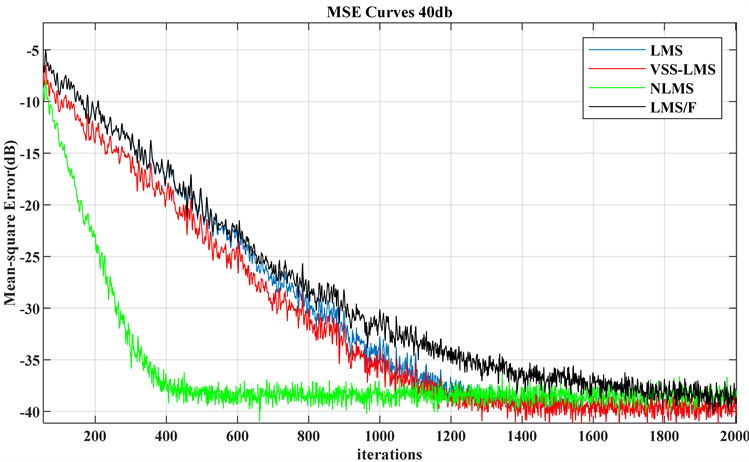
Figure 13. Performance curves of four algorithms with 40 dB noise
图13. 40 dB噪声下的四种算法的性能曲线
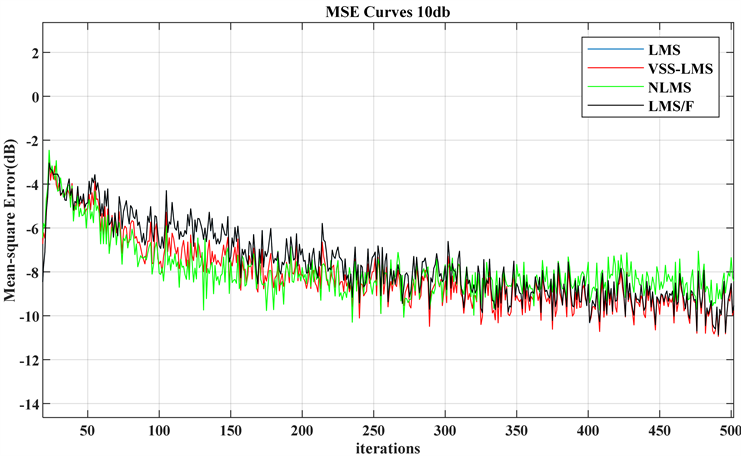
Figure 14. Performance curves of four algorithms with 10 dB noise
图14. 10 dB噪声下的四种算法的性能曲线
4.2. 不同噪音信噪比下各算法性能分析
分别对信噪比为40 db、20 db和10 db下四种算法的表现情况,20 db的情况可见图11,剩余两种情况的仿真结果如下图13和图14所示。
由图13可见,在高信噪比噪声的情况下,定步长NLMS算法的收敛速度相互对而言更加迅速,在500次即达到收敛,但初期的突变现象并无改善,LMS/F算法收敛速度最慢,并且相比于20 db的情况下,其收敛速度进一步放慢并且在1800次左右达到稳态。而VSS-LMS算法比LMS算法收敛稍快,但两者均在1200次左右收敛。
由图14可见,在低信噪比噪声的情况下,四种算法的收敛速度几乎相仿,均在250次作用达到收敛,并且在相同的步长值下,LMS算法与LMS/F算法并无差别。
4.3. 降噪效果分析
在评价语音降噪效果的指标中,常常使用的是降噪后语音的信噪比SNR和均方误差MSE两种性能指标 [6]。其中,SNR和MSE的计算公式可按照下式计算:
(12)
(13)
改变高斯噪音的信噪比,将基于公式(10)和(11)计算得到的数据记录于表1~表3中来分析四种算法在不同噪音强度下的降噪表现,表中的值均为多次仿真计算结果的平均值。

Table 1. Comparison of noise reduction effect between 4 algorithms with 10 dB noise
表1. 在加入10dB的噪声下四种算法间的降噪效果对比
Table 2. Comparison of noise reduction effect between 4 algorithms with 20 dB noise
表2. 在加入20dB的噪声下四种算法间的降噪效果对比
Table 3. Comparison of noise reduction effect between 4 algorithms with 40 dB noise
表3. 在加入40dB的噪声下四种算法间的降噪效果对比
通过上表可知,NLMS算法无论在较高信噪比和较低信噪比噪声环境下,都能保持较高的稳态精度和信号的保真度,是一种比较理想的算法,VSS-LMS算法在高信噪比噪声环境中要比传统的LMS算法精度高,而定步长LMS/F算法跟LMS算法在本次仿真中几乎相差不多,但是无论是在强噪声环境还是弱噪声环境下,LMS/F算法都要比LMS算法有微强的降噪效果。
5. 总结与展望
本文将LMS算法、LMS/F算法、NLMS算法和VSS-LMS算法进行了代码的实现,软件上结合数字滤波器FIR原理和自适应算法原理,在硬件上利用DSP芯片Si47925和安卓系统进行了对实车语音的模拟,将语音加以噪声后利用算法进行滤波降噪,并且由仿真结果可以知道,四种算法对降噪都有一定的优化。四种算法中,LMS算法的计算过程和代码实现最为简单,VSS-LMS算法最为复杂,但是收敛速度有所提升,定步长LMS/F算法在本次仿真中与LMS效果相差不多,NLMS在本次仿真中体现出了快速收敛,高精度,高保真的特点。
目前的自适应算法中,NLMS算法、VSS-LMS算法都有很多的优化的空间并且已被大力开发,都形成了较为成熟的改进算法,本文只是对这些基础算法进行了降噪仿真,来模拟车机系统环境下的降噪算法,不过基于基础算法的改进算法在本文中没有体现,可以在后续的工作中继续完成,运用更加先进的算法并实现车机系统下的麦克风语音降噪。