1. 引言
高效的除霜方式是减少冷库能源浪费的有效措施之一,随着冷库产业的不断发展,因冷库结霜造成的能源浪费也日趋增多,霜层的及时处理迫在眉睫。为解决人工除霜时造成的库温波动,二次结霜等问题,使用机器人进行除霜,以提高效率和减少成本。冷库除霜机器人采用双机协作方式进行除霜,实现管上除霜与协同收霜工作,地面协作机器人通过视觉对同伴进行识别、定位、跟随,同伴机器人清除的霜层通过连接管道传递给协作机器人,协作机器人完成对霜的收集与处理。但在冷库中光线不足导致收集的图片质量差,货物堆积等问题导致识别的模型精准率不高,无法及时识别同伴机器人,造成运动不同步,使得两者间的落霜传递管道脱落,造成地面落霜结冰,对工作人员生命安全构成威胁,霜层堆积引发细菌滋生,影响货物的品质,所以协作机器人对于同伴的高识别率至关重要。
国内外针对低光照收集的质量不佳图片的目标识别进行了广泛研究。例如李雷孝等提出一种利用直方图均衡化高斯滤波等方法对图像增强,通过YOLOv3和FasterRCNN对夜间安全带进行检测 [1] ,冯娟等使用MSRCR (multi-scale Retinex with color restoration)算法对图像增强,使用YOLOv4算法对光线不足的水下单环刺螠洞口识别 [2] 。司永胜等采用MSRCP (Multi-scaleretinexwithchromaticitypreservation)算法对图像增强后与YOLOv4算法结合对夜间奶牛进行检测 [3] 。但目前并未有冷库环境的相关物体识别研究。
故本文结合现有深度学习研究,针对协作机器人在冷库内因光照不足、货物遮挡和快速运动时空间信息丢失造成的对同伴识别率低问题,选用权重文件小,训练快的YOLOv5目标检测方法 [4] 。在图像预处理时采用具有色彩增益加权的AutomatedMSRCR算法 [5] 。对低光照下的低质量图像进行图像增强;使用kmeans++算法对数据集重新聚类,提供更好的识别效果 [6] ;在YOLOv5算法中使用双线性插值法(Bi-Linear interpolation)提供更精细的图像细节 [7] 。融入CoordConv卷积增加模型的位置感知信息更好的捕捉物体的几何形状特征,提升模型的识别精度 [8] 。
2. 图像获取与预处理
2.1. 图像获取
本文从徐州雨润冷库、七里沟等数十家冷库产品供应商企业与搭建的冷库排管模拟实验室中收集了冷库除霜机器人照片,获取同伴机器人的在低温冷库内的不同运动姿态,在顶管与侧管等不同位置下与不同空间环境下的机器人图片,采集到的部分数据集图片如图1所示,共计收集1800张图片数据集,其中1620张作为训练集,180张作为验证集。使用YOLOv5算法训练前对图像使用labelimg对图像进行人工标注,生成含有类别与位置信息的txt文件,便于网络的训练与测试。
 (a) 侧排管
(a) 侧排管  (b) 顶排管
(b) 顶排管
Figure 1. Image acquisition
图1. 图像获取
2.2. 图像预处理
冷库中的图像由于光照强度不足,拍摄的图像对比度低、清晰度低、质量退化,需要检测的物体轮廓和细节信息难以清晰表达对物体的识别增加难度。通过使用AutomatedMSRCR算法对图像进行色彩增益加权,该方法通过在R,G,B三个维度的上下限进行限制,可以去除较大较小的像素值,防止出现两极化使图像的亮度和对比度更加均衡,图像细节更加清晰,上述量化公式如式(1)所示。
AutomatedMSRCR算法的流程为首先将输入图像分解为不同尺度的图像,估计出每个尺度图像的亮度图像和反射图像,然后对图像进行局部对比度增强,更好的恢复图像的局部细节信息,最后合并所有尺度空间的图像重建出增强后的图像。通过算法可加强同伴机器的物体轮廓与细信息等关键特征点,找回更多的潜在信息。经AutomatedMSRCR算法得到增强后的效果图如图2所示,可看出通过算法增强后同伴机器人的特征更加明显,腿部和躯体的轮廓更加清晰细节信息更加充分,图像整体质量得到提升,增强后的图像更加自然。
(x, y)-二维图像对应的位置;
max,min-限定范围,
(1)

Figure 2. Automated MSRCR image enhancement process
图2. Automated MSRCR图像增强过程
3. 改进的同伴机器人识别模型
3.1. 改进的模型结构
YOLOv5模型的预设锚框是基于COCO [9] 数据集获取,与识别的同伴机器人在尺寸上差距较大,导致识别的精度降低,使用kmeans++算法重新设计新的锚框尺寸提高模型检测精度;同时为了保留图像的细节和纹理信息,更好地适应物体遮挡的情况,使用双线性插值替换YOLOv5模型的最近邻插值法;然后使用含有坐标信息的CoordConv卷积替换特征金字塔FPN (Feature Pyramid Networks)结构的传统卷积层和在Detect模块中添加CoordConv卷积缓解同伴机器人在运动时造成的空间信息丢失问题得到适用于冷库内的同伴机器人的识别网络。改进后的算法模型结构图如图3所示。
3.2. 锚框聚类分析
Yolov5所使用的初始锚框尺寸在检测时并不适用于所有的数据集 [10] ,为实现冷库机器人的最佳检测效果,采用典型的kmeans聚类算法对锚框尺寸进行重新设计,但kmeans算法随机性较大会对聚类效果会造成影响,选取效果更好随机性较小的kmeans++算法重新聚类锚框,该算法计算锚框过程中会判断锚框尺寸大小是否还会发生变化,当锚框大小稳定不变时输出锚框。Kmeans++的流程如图4所示。通过kmeans++算法重新聚类得到适合本文同伴机器人的9组锚框为(29, 44)、(46, 105)、(73, 229)、(109, 135)、(128, 65)、(143, 273)、(220, 147)、(251, 202)、(302, 328)。
3.3. 双线性插值
YOLOv5中上采样方式默认使用的是最近邻插值 [11] 。最近邻插值法直接复制领边的像素信息容易造成目标的边缘信息丢失,在遇到同伴机器人被货物遮挡的情况时,不能够有效提取特征。而双线性插值通过对图像进行适当的平滑处理和空间扩展可以将遮挡区域填充为合理的像素值,使得物体轮廓更加连续和自然,提供更平滑的图像边缘和更精细的图像细节,故本文模型使用双线性插值替换最近邻插值,提高遮挡时识别精准度。
双线性插值法的原理如图5通过在像素坐标系中距离目标图像的像素点P(x, y)点最近的Q11,Q12,Q21,Q22四个点在x方向进行插值得到R1,R2的像素信息,R1,R2通过在y方向进行线性插值后即可得到目标图像的像素值,计算公式如(2)~(3)所示。
通过4个点在X方向的线性插值得到R1,R2的像素信息:
(2)
R1,R2在Y方向的线性插值得到目标像素点P的像素信息:
(3)
3.4. CoordConv卷积
同伴机器人在运动时,其的空间信息(位置、尺度等)会发生快速变化。YOLOv5模型通过在neck网络使用了FPN和PAN结构完成对空间变化的感知,但由于neck中特征图经过多次卷积、池化等操作后,空间分辨率已经较低,部分细节和空间信息仍可能会丢失。CoordConv卷积具有引入表达坐标位置信息的特征通道,可增强模型对坐标信息的敏感度,提空间位置的抗扰性。
本文在丢失信息的neck层中引入CoordConv卷积。但若替换neck部分全部的卷积,会使推理的速度变慢,故本文选择在丢失空间信息较多的FPN层中进行替换,将FPN中传统的卷积层替换为CoordConv卷积,在保证推理速度的情况下完成优化。同时为保证获取更多的空间信息在Detect中加入CoordConv卷积,有效减少位置偏差问题。在Detect层中加入CoordConv卷积结构图如图6所示。N1,N2,N3为从neck层输出的特征图,使用CoordConv卷积将N1,N2,N3层的位置信息提取并逐通道地与输入特征图进行融合,得到增强版特征图,增强特征图在传递到后续处理中,被用来预测目标物体的位置、类别和置信度等信息。能够增强模型对目标特征的感知能力,有助于提高模型的检测性能。
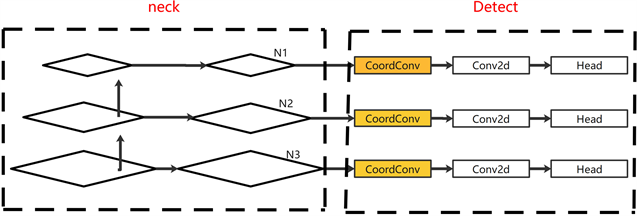
Figure 6. Adding CoordConv to detect
图6. Detect中加入CoordConv
4. 实验结果与分析
4.1. 计算机与训练参数设置
训练所用计算机配置:CPU使用IntelCorei5-12500H,2.50 GHz,电脑运行内存为16 G,GPU采用NVIDIA GeForce RTX 3050,应用Windows11系统,使用pycharm操作软件,python版本3.8,深度学习框架为torch1.9.1,CUDA 11.1。
训练参数的设置:训练迭代周期为(epochs)100,批次(batch-size)为8,学习率为0.01,余弦退火参数为0.2,学习率动量为0.937,置信度阈值0.40。本文采用精确率(Precision)、召回率(Recall)、调和平均值(F1)、mAP、几项对模型的性能进行评估。
4.2. 图像增强算法的性能对比
为了验证本文采用AutomatedMSRCR算法对低光照图像增强效果的有效性,本文选取500张不同光照强度下的图像分别经过MSRCR [12] 算法、MSRCP [13] 算法、AutoMSRCR算法增强后图像与原始图像在相同软硬件环境下进行目标检测效果对比实验,实验结果见表1。

Table 1. Comparison of enhancement algorithms
表1. 增强算法对比
由表1可知,与原始图像相比,MSRCR算法增强后的图像和精准率值提升7.3%,mAP0.5值提高0.5%,F1值下降1.5%,R值降低9.8%,经MSRCP增强图像精准率提升8.8%,mAP0.5值降低1.9%,F1值下降1.4%,R值下降10.6%,而经过AutoMSRCR算法增强的图像精准率提升10.1%,mAP0.5值下降0.3%,F1值提升1.1%,R值降低7.2%。增强后数据提升明显高于其他算法,图像质量效果提升最大。综合上述所示,本文选择AutomatedMSRCR算法对于低光照的图像增强效果最好。
4.3. 锚框结果对比
为验证新设锚框的优异性,采用预设锚框和kmeans,kmeans++重新设计的锚框分别对数据集进行训练,结果如表2,图7所示。
由表2和图7可知,不同锚框在迭代的初期都快速上升,在迭代到40次的时候开始趋向稳定,在80次的时候,新设锚框的优越性开始体现,kmeans++算法的锚框mAP曲线明显高于其它2组,模型性能更好。与YOLOv5的预设锚框相比,采用kmeans算法重新设计的锚框精准率提升0.4%,mAP0.5的值提高2.4个百分点,F1值提升2.2%,R值提升3.3个百分点。Kmeans++重新聚类的锚框在训练时较预设锚框精准率提升1.8个百分点,mAP值提升4.3%,F1值提升2.9个百分点,R值提高3.6%。通过实验结果表明本文采用的k-means++对模型提升效果更好。
Table 2. Comparison of results for different anchor frames
表2. 不同锚框结果对比
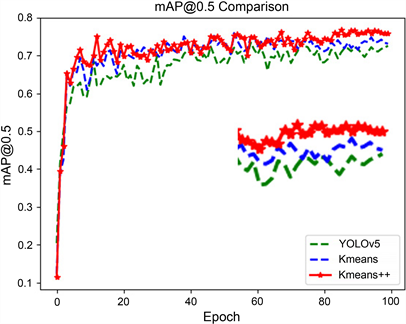
Figure 7. mAP values of different anchor frames
图7. 不同锚框的mAP值
4.4. 不同模型性能指标比较
为进一步验证模型效果,在相同软硬件环境下将改进模型与YOLOv5,SSD [14] , Faster-RCNN [15] , YOLOV4, YOLOv7-tiny [16] 等模型对比实验,对使用AutomatedMSRCR算法增强过的数据集进行实验对比,评估结果如表3。通过表3的对比试验结果可知,本文改进模型的检测精度mAP相较于SSD、Faster-RCNN、YOLOv4、YOLOv7-tiny和YOLOv5模型分别提升3.0%、3.6%、5.0%、4.5%、2.5%,综合上述所示,本文改进后的模型对在低光照冷库环境下运动的同伴机器人识别效果最好,模型的识别精准率更高。
Table 3. Comparison of test results of different models
表3. 不同模型检测结果对比
5. 结论
本文针对机器人在冷库环境中图像质量差,识别物的轮廓与细节信息不够清晰,造成目标丢失等问题,提出使用AutomatedMSRCR算法增强图像的质量,优化YOLOv5算法加强对识别物的细节信息保留与特征的提取的方法。对比原YOLOv5模型在低光照的冷库环境中检测置信度更高,可实现在冷库中对同伴机器人的识别。并有以下的结论:
(1) 提出对于冷库环境内双机协作机器人的同伴识别方法。满足在实际低光照环境中对同伴机器人的准确识别需求,实现在冷库检测方面的自动化与智能化,该方法为在冷库环境内的检测提供思路,为后续探索冷库内货物检测提供技术支持。
(2) 针对冷库内光照不均匀,图像质量差的问题,在图像预处理阶段使用AutomatedMSRCR的增强方法,增强后检测置信度更高,P值提升10.1%,F1值提升1.1%。
(3) 使用kmeans++算法对同伴机器人锚框尺寸重新聚类,得到更适合的锚框尺寸,提升识别的检测精度。使用双线性插值方法代替原有的最近邻插值法,保留更多的物体细节信息,使识别物更容易被检测到。在YOLOv5的FPN层中融合CoordConv卷积层,检测头前增加CoordConv层,增强网络对数据变换的鲁棒性,加强网络的特征提取能力。改进后YOLOv5模型对同伴机器人识别的较原有模型mAP提升4.5%,F1值提升3.1%,精准率提升3.5%,R值提升2.7%,模型的识别性能得到很大提升。