1. 引言
烟叶在采收、运输和加工过程中,不可避免地会混入非烟物质。烟叶中的非烟物质会极大地影响烟草原料的使用价值和卷烟产品的质量。非烟杂质是指非烟叶以外的各种物质,一般分为两大类:第一类为原生杂物,即在采摘运输过程中混入的非烟物质,包括杂草、石头、昆虫、麻绳等;第二类为次生杂物,即在生产过程中混入的非烟物质,包括金属、皮带、塑料、纸片等 [1] 。非烟物质的混入不仅会影响烟叶脱粒、复烤等设备,燃烧产生的有害物质也会严重影响人体健康 [2] 。为了保证卷烟的吸食安全,烟草行业对烟叶中的杂质含量提出了严格的控制要求 [3] 。
在卷烟生产加工线上,非烟物质的去除通常采用风力、磁力等方法 [4] ,但风力、磁力去除方法都依赖自动的非烟物质检测算法,基于可见光摄像机的视觉非烟物质检测研究已受到较多的关注,很多视觉检测模型被提出 [5] [6] ,但这些模型的识别性能不尽如人意,表现在虚警率和漏检率均较高。随着烟草行业对除杂系统准确性、可靠性要求的提高。近年来,研究者发现可见光谱段有限是制约性能提高的一个重要因素。随着高光谱成像技术的飞速发展,他们开始逐步关注多谱段的引入。现阶段,高光谱相关成像器件的性能已有很大提高,比如,线性推扫成像的高光谱成像仪可水平获取光谱信息,显示光谱像素的位置,提供物体的空间分布信息,实现不同被测物体的实时可视化成像。此外,高光谱像机的谱段不断丰富的同时,分辨率和采集速度也得到了保证。因此,高光谱成像仪在烟草领域越来越受到重视 [7] [8] [9] [10] ,比如烟叶水分含量的鉴定 [5] 、烟草花叶病毒的鉴定 [11] 、烟叶成熟度的判断 [12] 等。但是,利用高光谱技术对烟草脱粒和复干过程中的烟叶和杂质进行识别和分类的研究较少,代表性的工作主要有文献 [12] 提出的一种基于随机森林的方法,该方法首先对高光谱图像进行预处理,然后对烟叶和杂质的感兴趣区域进行建模和分析。最后,利用随机森林算法对烟叶和杂质进行分类,实现了非烟物质的检测,但基于高光谱的非烟物质检测和识别模型的准确率仍有很大提升空间。
本文采用了基于U-NET深度网络模型来实现基于高光谱非烟物质检测,通过模型改进获得高质量的分割结果实现非烟物质的空间定位与类型识别。U-NET模型被广泛运用到了各种目标分割和语义分割任务中,原因是其编码器结合解码器的两阶段架构可以很好把握图像的本质表征,而且编码器先逐次下采样、再由解码器渐进上采样的全卷积方式实现了多尺度的特征提取,特征提取的更全面。但是,很多工作在使用U-NET对高光谱数据进行处理时,也集中于调整编码器结合解码器架构,以及对下采样、上采样方式做一些调整,缺忽略了一个问题,即卷积方式的多样化,依然沿用标准卷积,多集中在调整卷积核的尺寸,多少和改进计算方式等。本文发现,使用U-NET处理高光谱数据时,给架构引入多种不同类型的卷积操作可以显著提升模型的性能。在这一观察指导下,我们在U-NET模型的下采样段,中间段和上采样段分别使用中心差分卷积,快速傅立叶卷积和标准卷积的特定混合,让模型更适合提取非烟物质区域,抑制正常烟叶区域的虚警。
既然模型的改进引入了不同类型的卷积去适配U-NET网络的不同阶段的特征提取,那么为了与改进模型相得益彰,训练改进模型的损失函数是否也需要混合,结果发现,使用加权交叉熵和Dice损失的组合比直接使用交叉熵损失、加权交叉熵损失、Focal损失,Dice损失更能使模型得到充分稳定的训练,达到最好的性能。
最后,基于以上模型我们设计了一个高光谱非烟物质检测系统,并在湖南中烟下属打叶复烤厂完成了实际部署与验证。验证表明:该系统在片烟中检测和识别面尺寸不小于10 mm × 10 mm的次生非烟杂物检测的虚警率为1.12%,漏检率为0.45%,对不考虑杂物类别,即把所有非烟杂物作为一类,且包含了部分训练集中未出现的杂物类别的检测,虚警率为3%,漏检率为2.4%。较好的支持非烟物质的预警和剔除,有效减少复烤过程次生非烟物质进入片烟造成的质量隐患与风险。
2. 多型卷积融合网络模型构建
本节我们给出了所提出的MCFnet模型的架构图,并对架构图进行了简要介绍;分析了在U-NET模型基础上引入多类型卷积的目的,详细介绍了新引入的两类卷积模块,即中心差分卷积残差模块和快速傅里叶卷积残差模块。
2.1. 模型架构
图1给出了MCFnet模型的网络结构图,MCFnet模型以U-NET作为基础骨架模型。U-NET是一种常用于图像语义分割任务的深度学习模型。U-NET的结构特点在于它的U形设计,具有编码器(下采样路径)和解码器(上采样路径)之间的对称结构,能够捕捉不同尺度的特征并保留高分辨率的信息。编码器(下采样路径)由多个卷积层和池化层构成,用于逐渐减小输入图像的尺寸和通道数。每次通过卷积操作,都可以提取出图像的高层次特征。通过池化操作,可以将图像的尺寸降低,从而加速计算并扩大感受野。编码器的设计有助于捕捉图像的全局特征。解码器(上采样路径)部分也由多个卷积层和上采样(反卷积或转置卷积)层构成,用于将编码器得到的特征进行逐步恢复到原始图像尺寸。解码器的设计有助于精确定位分割目标的边界和细节。跳跃连接(Skip Connections)用于在特征传递时,将编码器的某一层的特征直接连接到解码器相应层,这样可以将低层次的细节特征传递到解码器,帮助精细化分割。
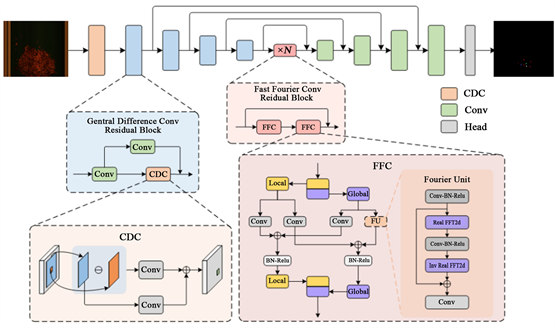
Figure 1. The overall architecture diagram of MCFnet model
图1. MCFnet模型完整架构图
本文将U-NET作为基础骨架模型的原因有三个:(1) U-NET对高光谱特征的提取性能较好,(2) 考虑到本项目杂物目标都比较小,U-NET被证明是一种适合检测弱小目标的骨架模型;(3) U-NET是全卷积网络,参数量小于其它主流骨架模型范式,推理速度快。
我们针对高光谱数据的通道维度高的特性,对U-NET网络结构在通道维度上进行了拓展,使其更适合于高光谱数据的分割问题。其次,引入多种不同类型的卷积操作来改进U-NET网络结构,这种结构可以使模型对杂物鉴别特征的提取能力更强。首先使用一个中心差分卷积操作做特征提取,让模型在浅层更关注提取非烟杂物有烟叶的差异特征。编码器部分采用4个中心差分卷积残差模块,它是中心差分卷积与标准卷积的混合,并结合了残差连接;其次,对得到的特征图采用傅立叶卷积残差模块,它是快速傅立叶卷积与标准卷积的混合,也结合了残差连接。解码器阶段使用4个标准卷积模块,最后是语义分割输出头,输出三维概率图,其宽、高与输入图像尺寸一样,通道数与杂物类别个数相同。
2.2. 多型卷积混合
通过改变卷积核大小实现通道适配,U-NET网络模型可以直接处理高光谱图像,实现非烟杂物的检测。但是,由于高光谱空间尺寸不高,而且部分非烟杂物本身就很小(如螺丝),或者被烟叶部分遮挡,导致高光谱图像中这部分杂物面积非常小,成为较难解决的小目标检测问题,必须特别考虑如何更好的突出杂物与烟叶差异,否则会在模型处理过程中容易丢失;同时成像系统在长时间运行后会出现一些负面因素(如光源均匀性,噪声影响等),导致部分杂物像素之间的光谱差异变大,不利于非烟杂物的检测。如图2(b)显示了一些成像系统运行良好时采集的正常烟叶与非烟杂物的光谱曲线,此时,非烟物质与正常烟叶的曲线可分性较明显。
 (a)
(a) (b)
(b)
Figure 2. The real picture and spectral curves of normal tobacco leaves and typical non-tobacco materials (a) The real picture of normal tobacco leaves and typical non-tobacco materials; (b) The spectral curves of normal tobacco leaves and typical non-tobacco materials
图2. 正常烟叶与典型非烟物质实物图与光谱曲线(a) 正常烟叶与典型非烟杂物实物图;(b) 成像系统运行良好时采集的正常烟叶与非烟杂物的光谱曲线
但是,图3(a)所示的黑色电线,在采集系统长时间运行后,观察拍摄出来的高光谱图像中的几个像素点的光谱曲线(图3(b))就会发现,这些像素的光谱曲线一致性变差。此外,受到了较大的系统噪声的影响,光谱峰值也在较大范围变动,容易造成模型对黑色电线像素的漏检和虚警(如图4)。因此,在高光谱U-NET骨架基础上,我们增加了中心差分卷积残差模块和快速傅里叶卷积残差模块,以期更加突出非烟杂物的同时,减少这些因素的影响。
 (a)
(a) (b)
(b)
Figure 3. The discrimination between non-tobacco materials and normal tobacco with aspect to their spectral curves and the heterogeneity of some non-tobacco materials. (a) The real picture of black wires; (b) The significant difference of spectral curves at six pixels of black wires
图3. 非烟物质与正常烟叶光谱曲线可分性与部分非烟物质光谱的不一致性,(a) 黑色电线杂物实物图;(b) 黑色电线上六个不同像素光谱曲线差异(光谱峰值在60到250范围变动,噪声强度差异大)
2.2.1. 中心差分卷积残差模块
标准卷积 [13] 通过考虑邻域像素特征的加权组合可以有效地提取二维图像的颜色、形状、纹理等信息,能够较好的实现图像的识别。但是对非烟杂物检测任务来说,标准卷积的特征提取性能受限。由于绝大多数非烟杂质尺寸比较小,其特征很容易在U-NET的下采样过程中被淹没,导致无法检测到非烟杂质。为了避免过度下采样导致的漏检,我们使用中心差分卷积来突显非烟物质与正常烟叶的差异信息。中心差分卷积先计算卷积核中心像素点和周围像素点的特征差异,并在此基础上进行卷积,从而引导网络模型学习差异特征,由于非烟物质与正常烟叶特征差异大于正常烟叶之间的特征差异,一定程度上提高了非烟物质的对比度,中心差分卷积的公式描述如下:
(1)
其中
为当前中心,
为卷积窗口大小。为了保留标准卷积的特性,一般将中心差分卷积与标准卷积进行加权融合,描述如下:
(2)
其中
为中心差分卷积和标准卷积的比例因子,其值越大,则中心差分卷积所占比例越高。用于计算差异的窗口大小
一般设置为卷积核大小,中心差分卷积模块的感受野会随着网络前向传播过获得多层次的对比度信息,帮助网络识别不同大小的非烟杂物。
尽管中心差分卷积层补充了多尺度的对比度特征,但学习上比标准卷积要复杂,为了易于学习,最大程度发挥其性能,我们在中心差分卷积基础上加入的残差模块,设计了中心差分卷积残差模块。如图1中的蓝色方块所示,它包含一个残差连接,在中心差分卷积前和残差连接上各引入一个标准卷积层。
2.2.2. 快速傅里叶变换卷积残差模块
基于高光谱图像的非烟物质检测的最显著优势在于采集较多精细的光谱通道,从而提供了更多辨识非烟物质的有效信息,但这些有效信息的提取对模型的信息挖掘或特征提取能力提出了更高的要求。尽管我们在U-NET模型基础上使用中心差分卷积,但整个模型与普通的只有三个通道的可见光图像相比,并没有特别考虑空–谱两维度上的特征提取。为此,我们采用了快速傅里叶卷积弥补这一不足,用其把经过编码器输出的特征图分成局部特征提取和全局特征提取两个分支,在局部特征提取分支中使用标准卷积进行空–谱通维度的细节提取,在全局特征提取分支中,使用傅里叶单元实现空–谱维度上的全局特征提取,并在两个分支间,使用捷径链接进行信息交流。
进一步的,在傅里叶单元中我们先将输入特征通过快速傅里叶变换从空间域转换到频域,由于频域上的每个点总是跟空间域的所有点相关的,在频域上只需采用小尺寸核进行卷积操作就能影响原空–谱域上的所有点,因此我们可以获得跟特征图尺寸同大小的感受野,最后再通过傅里叶逆变换得到包含全局信息的特征图。傅里叶单元的流程如下:
(1) 使用二维快速傅里叶变换将输入特征图从空间域转换到频域:
(3)
(2) 并在通道维度上拼接复数的实数部分和虚数部分,当做两个通道的实数来处理:
(4)
(3) 在频域上应用卷积、归一化和激活函数操作:
(5)
(4) 将两个实数通道组合成一个通道的复数逆变换到空间域:
(6)
(5) 快速傅立叶逆变换:
(7)
最后,在通道维度上将局部分支与全局分支进行拼接,得到包含局部信息与全局信息的特征图。
同样,快速傅立叶卷积引入增加了模型的学习负担,为此,我们对快速傅立叶卷积进一步引入残差连接,转变成快速傅立叶残差模块,这样不仅可以易于模型的学习,实验发现还能进一步提升模型的性能。此外,实验还发现对整个编码器处理完的高光谱特征进行快速傅立叶残差卷积层进行处理最有效,因此,我们把快速傅立叶残差卷积模块放在整个骨架的中间阶段。
2.3. 损失函数
我们首先使用交叉熵损失函数用于模型训练,根据模型的分类任务用到了二分类和多分类。
(1) 二分类
在二分类的情况下,模型最后需要预测的结果只有两种情况,即正常烟叶和非烟物质。对于每个类别我们的预测得到的概率为
和
,此时表达式为:(
以
为底):
(8)
其中:
表示样本
的类别标签,正常烟叶为1,非烟物质为0,
表示样本
预测为正常烟叶概率。
(2) 多分类
多分类的情况就是对二分类的扩展,公式为:
(9)
其中,
为所有非烟物质类别加正常烟叶类的总类别数(实验中为9类),
为符号函数,它表示如果样本
的真实类别等于类别
取1,否则取0,
为观测样本
属于类别
的预测概率。

 (a) (b)
(a) (b)
Figure 4. Typical cases of false alarms and missed detection (a) A false alarm case; (b) A missed detection case
图4. 典型虚警和漏检实例图(a) 虚警实例;(b) 漏检实例
由于非烟杂物和背景(烟叶和传送带)空间占比悬殊,直接使用二分类或多分类交叉熵损失,会造成模型关注空间占比大的背景像素的错分损失,而忽略了非烟杂物的错分损失,导致非烟杂物漏检(如图4(b))。为此,将交叉熵损失公式中的求和项按像素类别分成非烟杂物和背景两部分,对背景像素的损失求和后的损失值赋予一个较低的权重,而对非烟杂物像素求和后的损失值赋予一个较大的权重,这称为加权交叉熵损失
。此外,我们尝试了常用的Focal损失
和Dice损失
两种常用于样本比例不均衡的损失函数,并观察了这些损失与加权交叉熵损失联合形成组合损失的训练效果。实验发加权交叉熵损失与Dice损失等比例加权效果最好,即
,而单独使用这些损失函数中一种或其他不同的组合都达不到上述组合的效果。这里Dice损失定义为:
(10)
其中TP表示模型预测为正例,实际是正例;FP表示模型预测为正例,实际是反例;FN表示模型预测为反例,实际是正例;TN表示模型预测为反例,实际是反例。
取值范围在0到1之间。
3. 完整检测方法
在上一节模型构建和训练方法基础上,进一步设计合理的预处理和后处理步骤以实现完整可靠的杂物检测与识别方法。
(1) 黑白校正
在系统运行过程中,高光谱成像系统容易受到外界影响,如外界光照不均匀、相机镜头暗电流等。因此,为了获得更准确、更稳定的高光谱图像数据,需要在实验前对高光谱图像进行黑白校正。校正公式为:
(11)
其中,R是校正后的高光谱图像;I是原始高光谱图像;B是反射率为0的黑色校准图像;W是反射率为99%的白色校准图像,它由图5所示的反射率为99%白板获得。

Figure 5. The real picture of the used white board with 99% reflection
图5. 反射率为99%白板实物图
(2) 检测与后处理
利用训练数据集和前面设计的加权损失函数充分训练MCFnet模型,通过验证集对模型的超参数进行优化,最终确定的模型用于对测试图像分割并识别出非烟物质,用于性能评估。杂物区域后处理。对于MCFnet模型输出图,按非烟杂物的类别做连通域分析,再将所有类别的连通区域收集到一起。这是为了避免两种不同类的非烟杂物靠在一起而误认为是一个非烟杂物的错误。将每个连通域的面积与预先设定的面积阈值比较(测试中设置为2,相当于10 mm × 10 mm实物面积),滤除面积小于或等于该面积阈值的噪声区域,剩余区域全部作为非烟物质。
4. 实验与分析
本节我们先给出所设计的非烟杂物检测系统的实物部署图和软件界面;介绍了实验数据的构成、模型评价指标以及方法的实现细节;进一步给出了本文方法与当前非烟杂物方法的综合测试与比较实验,最后给出了MCFnet模型的消融实验。
4.1. 系统介绍

 (a) (b)
(a) (b)
Figure 6. System deployment and software interface (a) System deployment; (b) Software interface
图6. 系统部署与软件界面(a) 系统部署图;(b) 软件检测界面
如图6(a)在烟叶传送带上方1.5米处架设了高光谱摄像机,与皮带垂直,保证在宽度方向上覆盖整个皮带上的烟叶区域。其中,高光谱摄像机为LISEN公司的iSpecHyper-VS200系列高光谱相机,光谱范围400~1000 nm,分辨率优于2 nm,点列斑直径 < 0.5像元。系统光源采用覆盖400 nm~2500 nm全光谱的卤素灯光源,光学镜头焦距采用12.5 mm。采用VS2015开发了基于深度学习的非烟物质图像后处理系统。使用反射率数据作为采集数据格式,因为反射率主要与材料特性有关,而当光场发生变化,同一材料的反射率保持不变。
4.2. 实验数据
实验数据集共包含600幅高光谱烟叶图像。图像空间尺寸为300 * 480,每个像素有300个光谱维度。该数据集包含了电线、捆扎带、工布胶皮、PE、麻绳、PVC、胶片、螺丝共8类不同颜色和材质的烟草生产环境中的常见杂物。针对该数据集,我们提供了tif格式的高光谱图像文件,png格式和xml格式的带类别标注信息,可用于多分类的杂物检测。其中500幅用于模型训练(训练集),100幅用做参数验证(验证集),测试集是在复烤厂现场部署完系统后,共测试了半个小时,投放包含八个类的447个杂物和53个不属于训练集类别的杂物,主要包括烟盒、碎布、皮带,附件中给出了测试过程的部分视频。
4.3. 评价指标
模型评估主要采用平均交并比、虚警率和漏检率作为性能评价指标,平均交并比用于模型性能评价,而虚警率和漏检率用于检测与识别性能评价。
在语义分割的问题中,交并比就是该类的真实标签和预测值的交和并的比值。其中:TP、FP、FN和TN的含义与2.3节
中的定义一致。
(12)
就是该数据集中的每一个类的交并比的平均,计算公式如下,其中Pij表示将i类别预测为j类别。
(13)
(14)
此外,也使用虚警率(FA)和漏检率(MD)指标来衡量分割性能,他们的定义如下。
(15)
(16)
4.4. 实现细节
进一步使用水平/垂直翻转对训练数据进行数据增强。使用SGD优化器,学习率初始化为5e−2,并以余弦退火方式进行衰减,且衰减值weight-decay值设置为1e−4。模型的batch-size设置为8,执行400轮(epochs)可完成充分训练。
4.5. 综合测试与比较
我们使用所设计的模型组成高光谱杂物检测系统进行现场检测。我们选用随机森林方法,基于YOLOv5实例分割模型 [14] [15] [16] [17] 与本文方法作比较,8类非烟杂物共投放447个,每类的投测试个数及检测结果如表1所示,可以看到,本文方法FCMne的检测虚警率和漏检率分别为1.12%和0.45%,三者中最低,随机森林和YOLOv5的综合性能不如FCMnet,其中,随机森林虽具有较强的单个像素光谱特征表示和学习能力,但像素之间在图像空间上的语义关系建模并不强,导致较高的虚警率(5.82%)和漏检率(4.47%)。相比之下,YOLOv5不会出现较多虚警(1.79%),但受其模型本身对小目标的检测能力制约,特别是只有几个像素的非烟杂物的检测,容易出现漏检(漏检率达到3.80%)。FCMnet在抑制虚警和漏检两方面较为平衡,两种错误发生的更少些。

Table 1. Detection results of eight non-tobacco materials
表1. 八类非烟物质检测结果
此外,模型的混淆矩阵如图7所示,其中,0表示背景(正常烟叶和传送带)。从表中可以看出,除第8类(螺丝)易被识别成背景或其它类外,其余类的识别性能均达到了较高的水平,证明MFCnet具有较强的识别能力。
在实际测试中,我们还验证了将所有不同类非烟物质合并,统一看成一个类,即异常类,与正常烟叶进行区分,并且在前面实验采集的447个8种杂物样本基础上,还混入了53个不在8类中的非烟杂物,包括烟盒、碎布、皮带三类,于是共得到500个异常类样本。本测试希望以二分类方式来检验模型对“只需识别是否是杂物”这一任务下的检测能力以及对未见过的非烟杂物的检测能力。模型输出头改成二分类,训练样本将所有杂物归为一个类,具体测试方法与多类测试类似,其结果由表2给出。从已有的8类杂物图像上实验结果看(表2第三列),将8类杂物合为一个类别检测后,三种方法的检测虚警率和漏检率均增加了一些,总体不大,这主要是异常类的类内方差较大,给决策边界带来一些困难。MFCnet的虚警率和漏检率依然最低,分别维持在1.79%和1.57%。
对新引入的未见过的杂物进行检测时(表2第四列),三种方法的虚警率和漏检率都有不同程度的增大。YOLOv5的两种错误率增大的最明显,其中漏检率上升到了64.15%,主要原因是漏检的类似样本并没有出现在训练样本中,说明YOLOv5对训练样本的依赖较大;随机森林方法在检测新杂物时,受到的影响没有YOLOv5那么大,但其虚警率仍然较高,达到24.53%;本文方法MFCnet受到的影响最小,分别为13.21%和9.43%。在500幅图像上的综合来看(表2最后一列),MFCnet虚警率和漏检率最低,分别维持在3%和2.4%。
Table 2. Comparison of detection performance with all non-tobacco materials merged to an anomaly class and with instances from unseen class mixed
表2. 将所有杂物当成一个异常类并混入新类别杂物后的测试结果对比
图8给出了一组展示各方法检测结果的可视化图,从图中可以清楚的看到,对比非烟杂物的掩模真值,随机森林方法虚警较多,YoloV5方法漏检较多,且也存在好几个虚检,而本文提出的MCFnet虚警和漏检均较低。

Figure 8. Visualization results for all methods
图8. 所有方法非烟物质检测可视化结果图
4.6. 消融实验
(1) 不同模型骨架比较
我们分别使用U-NET及DeeplabV3模型架构中的不同骨架作为我们的模型骨架,并比较它们在我们的非烟杂物数据集上检测mIoU值,由表3可以发现,使用U-NET作为MCFnet的模型骨架,mIoU性能最高。其中,BaseConv就是图1给出的架构图,即降采样五层卷积,下采样四层卷积。
Table 3. Ablation study of the selection of model architecture and Backbone
表3. 模型架构及骨架选择消融实验
(2) 引入多类型卷积比较
在U-NET + BaseConv基础上,我们研究逐步引入多类型卷积的有效性,由表4可以看出,当上采样阶段五层全部使用中心差分残差模块时,mIoU从69.7达到71.0。而当上采样第一层使用中心卷积层,其它四层全部使用中心差分残差模块时,mIoU又达到71.2,在此基础上,进一步在中间层分别加入1、2、3个快速傅里叶卷积残差模块时,模型mIou均有了提升,其中,加入2个时指标最高。最后,我们还测试了如果将MCFnet的下采样层全部改为中心差分残差块,模型mIou反而下降了。
Table 4. Ablation study of involving multiple types of convolutions
表4. 引入多类型卷积消融实验
(3) 不同背景权重比较
由于非烟物质远远少于背景(烟叶与传送带),导致每幅图像中两者的空间占比严重不均,因此,我们在交叉熵损失中给背景赋予较低一些权重,让模型更更多的考虑非烟物质的分割。表5给出了交叉熵损失中使用不同背景权重时的模型性能。
Table 5. Ablation study of weight selection for cross-entropy loss
表5. 交叉熵损失权重选择消融实验
(4) 不同损失函数比较
表6给出了使用不同损失函数训练MCFnet后得到的模型性能比较,可以看出,加权交叉熵损失与Dice损失的组合损失得到最好的性能结果。
Table 6. Ablation study of using different loss function
表6. 不同损失函数消融实验
5. 结论
本文提出了一种新的基于高光谱的非烟叶杂物检测方法。该方法以U-NET语义分割模型为骨架,适配高光谱三维张量数据输入。采用中心差分卷积、快速傅里叶卷积和标准卷积三类不同卷积,分别嵌入U-NET模型的降采样段,中间段和上采样段,较好地提取了高光谱的空谱联合特征;进一步给出了与该模型相适应的组合损失模型,以保证模型的训练充分稳定;设计与实现的非烟物质检测系统,并在实际复烤烟厂进行了测试。测试结果表明所提模型及方法对杂物检测的具有较低的虚警率和漏检率。下一步将对模型进行压缩和参数优化,实现模型与除杂系统的联动测试。
基金项目
本文由国家自然基金支持,基金号:61703209,同时由湖南中烟工业有限责任公司科技项目资助,项目编号:KY2023ZB0010,项目名称:基于高光谱技术的复烤打包工序非烟物质在线识别监测研究与应用。
NOTES
*第一作者。
#通讯作者。