1. 引言
随着发改委发布的《关于改革完善高铁动车组旅客票价政策的通知》,铁路总公司根据市场情况自行对火车票价进行定价的政策出台。铁路部门为了保持市场竞争力,实现利润最大化,需要了解日常铁路客运流量、淡旺季的变动指数等具体情况,所以对客流量的充分了解和预测是准确把握市场的首要条件,因此有关于铁路客流预测的研究也成了铁路客运服务需要重点研究的对象。
然而铁路客流量受诸多因数的影响,比如:节假日期间铁路客流量骤增,造成人多车少的情况,导致铁路客运量无法满足客户乘车需求,同时也给铁路局带来巨大压力,在非节假日期间,造成车多人少的情况,一些冷门线路区间上客座率不足,这样就造成铁路车辆资源的浪费,因此客流量进行预测,可以为之制定合理的价格,改善火车站运营方式、优化铁路资源配置、促进城市间之间的发展,从而更好的带动各城市间餐饮、住宿等服务业的发展。
2. 趋势客流量分析
趋势客流量预测的方法较多,如时间序列法、回归分析法、灰色预测法、BP人工神经网络模型、重力模型等。这些方法在各自的领域都有各自的优缺点,因为是研究贵阳到成都方向的铁路客流量,且数据是由时间顺序记录的,结合铁路客流量增长特点,以铁路历史客流量为基础,建立时间序列分析模型对趋势客流量进行预测 [1] 。
2.1. 数据处理
选取样本数据,在贵州省统计局的统计月报中得出数据如下表所示:
数据缺失原因:由于数据来源是贵州省统计局统计月报,在数据收集过程中,数据缺失的情况是无法避免的。因此,在大多数情况下,信息系统是不完备的,而处理不完备数据的方法有以下三类 [2] :
一:删除元组:也就是将存在遗漏信息的值进行删除,进而得到一个完备的信息表;
二:数据补齐:这类方法是用一定的值去填充空值,从而使信息完备化。通常基于统计学原理,根据决策表中其余值的分布情况来对一个空值进行填充。在数据挖掘中又有多种补齐方法:人工填写、特殊值填充、平均值填充、热卡填充等;
三:不处理:在进行数据挖掘时,也可以包含空值,这类方法出现在贝叶斯网络和人工神经网络中 [3] 。
在上述数据中,有缺失值的出现,我们采用的是均值填充的方法:数据的属性又分为定性型数据与定量型数据,如果数据为定性型数据,就以该数据的众数来补齐缺失的值;如果数据为定量型数据,就以该数据存在值得平均值来插补缺失的值;可知我们的数据为定量型数据,所以将已知的数据全部相加求和,最后取均值即可,整理后的数据如表1所示。
由图1可知:2015年9月到2016年7月这一期间,其中2月、7月的人数分别为468.53万、443.25万人,是这11个月当中最多的,且2月是春节期间,大量务工人员需要回家与家人团聚,人员迁徙量有所增加,7月是在夏季,天气好,旅游量会增加,而且又是暑假,也增加了火车的客流量。
下面用模拟数据的方法对数据进行处理,以下时间序列模型所用数据来源于第四届泰迪杯官方网站的B题部分数据。
2.2. 模型总体流程
ARIMA模型建立流程图(图2)。
2.3. 具体流程
对抽取列车进行数据分析,并通过残差分析来判断模型的拟合度,建立简单模型来反映客流规律,经过分析,我们发现在过去一年里节假日最多的是周六,所以我们对周六的客流量进行统计分析,得出节假日对客流量的影响规律。并对抽中的客流量数据进行统计分析以及构建ARIMA模型,考虑相关因素,通过指数平滑预测未来两周的客流量。
每个月的客流量都在随着很多因素(比如:节假日、周末、寒暑假等)的影响而变化,因此我们初步判断这些数据所构成的序列是非平稳的。
1:对K17次列车提取出来的序列值进行平稳性检验:根据时序图观察是否平稳
由图3可知:k17次列车总人数的时序图是非平稳序列。
2:差分运算与Hlot两参数指数平滑

Table 1. The passenger flow of railway, road and water transport in Guizhou province from September 2015 to July 2016
表1. 2015年09月至2016年07月贵州省在铁路、公路、水路的旅客运输量
注:数据来源于省交通运输厅、成都铁路局、省机场集团有限公司。

Figure 1. The number of the passengers of railway from September 2015 to July 2016
图1. 2015年9月到2016年7月火车客流量人数
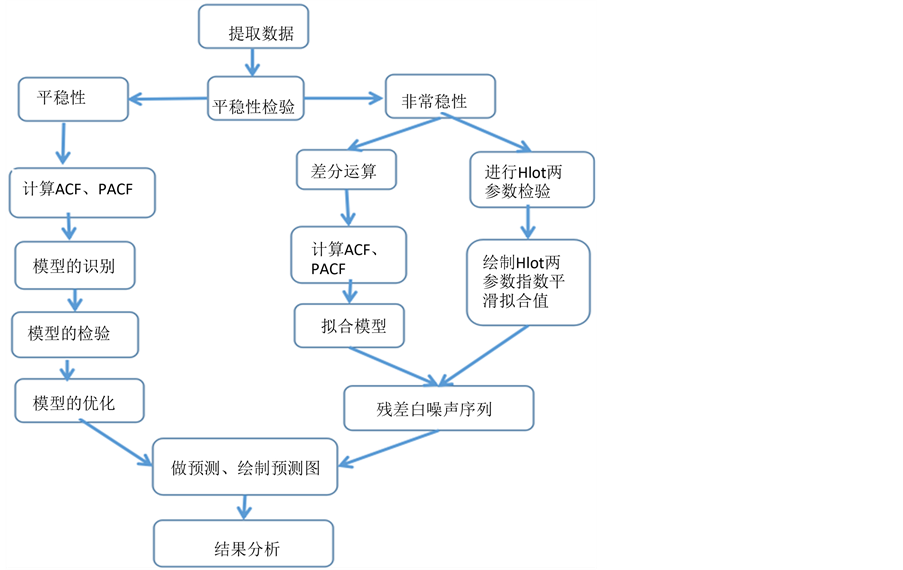
Figure 2. The flow chart of ARIMA model
图2. ARIMA模型建立流程图
a. 差分运算:
由图3时序图的确定性信息提取的情况来看,他们对确定性信息的提取不够充分,所以我们又采用
差分运算,对此序列进行一阶差分处理,从图4可知差分后的序列是平稳的。
一阶差分后序列时序图(图3)在均值附近波动平稳,借助差分后序列自相关图(图5)进一步考察差分序列的平稳性,除了一阶的自相关系数显著非零,其他阶的自相关系数有超过2倍标准差范围,可以知道它是拖尾的,而在偏自相关图中大多数值在负轴附近波动,且有明显的超过标准2倍差范围,也可以知道是拖尾,所以可以认为一阶差分后序列平稳,综合考察自相关图(图5)和偏自相关图(图6)的属性,可以认为自相关系数、偏自相关系数拖尾,所以对原序列拟合ARIMA模型 [4] ,得到的拟合模型:
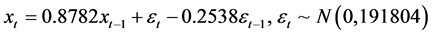
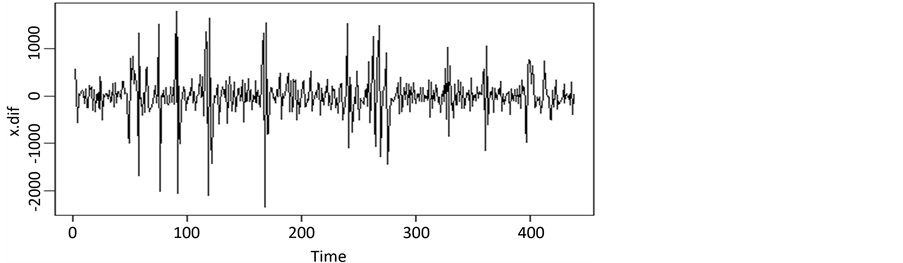
Figure 4. The sequence chart of K17 after difference
图4. K17次列车差分后的时序图
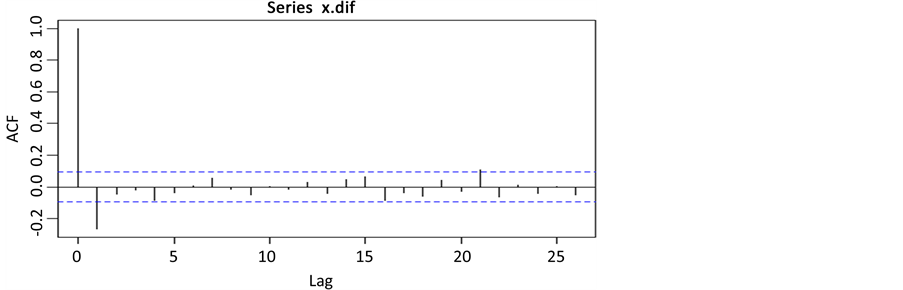
Figure 5. Autocorrelation figure of K17 train after the first order difference
图5. K17次列车一阶差分后的自相关图
由残差序列白噪声检验中,不管是自由度为6,还是自由度为12的P值明显都大于0.05,即接受原假设,说明该模型显著成立,这说明ARIMA模型对该序列拟合成功。
b. Hlot两参数指数平滑:适用于对含有线性趋势的序列进行修匀,假定序列有一个比较固定的线性趋势,每期的递增r或递减r,那么第t期的估计值就应该等于第t − 1期的观察值加上每期固定的趋势变动值,对序列值进行指数平滑,绘制Hlot两参数指数平滑拟合效果图,即可进行预测,拟合效果图如图7。
其中:黑色曲线为原始数据经R软件操作后的时序图,
红色曲线为Hlot两参数指数平滑拟合值。
由图7可知,因红色曲线为Hlot两参数指数平滑拟合值且与原始数据的时序图(黑色曲线)几乎重合,说明采用两参数指数平滑的方法得到的拟合值是正确的。

Figure 6. Partial Autocorrelation figure of K17 train after the first order difference
图6. K17次列车一阶差分后的偏自相关图
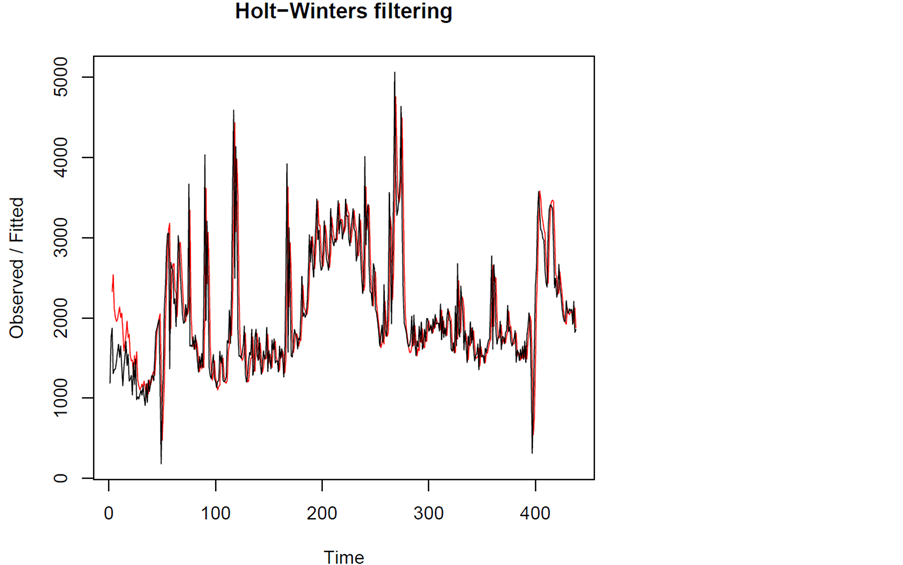
Figure 7. Hlot two-parameter exponential smoothing fitting values of K17 train
图7. K17次列车Hlot两参数指数平滑拟合值
3. 回归分析
回归分析研究的主要对象是客观事物变量间的统计关系,它是建立在对客观事物进行大量试验和观察的基础上,用来寻找隐藏在那些看上去是不确定的现象中的统计规律性的统计方法。
回归分析方法是通过建立统计模型研究变量间相互关系的密切程度、结构状态及进行模型预测的一种有效的工具 [5] 。
3.1. 数据处理
A:在时间的选取过程中,一天24小时,所以在起始时间的选取中,以小时为单位进行选取;
B:在选择时长的过程中,以分钟为单位对时长进行计算;
C:在回归分析中,对一些自变量是定性变量的情形给予数量化处理,处理方法是引进只取0和1两个值的虚拟自变量将定性数据数量化,由于贵阳到成都方向列车的座位分为:硬座、硬卧、软卧。所以在这里需要引进两个0~1变量,其中一个0~1变量为:1表示硬座,0表示软座;另外一个0~1变量为:1表示卧铺,0表示座位;
对数据进行以上处理,选取出来的数据如表2 (注:数据来源于成都铁路局、携程官网)。
Table 2. Each index of Guiyang to Chengdu direction
表2. 贵阳到成都方向各指标值
其中:因变量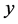 :列车的座位数;自变量
:列车的座位数;自变量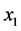 :火车的起始时间;
:火车的起始时间;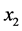 :贵阳到成都所需要的时长;
:贵阳到成都所需要的时长;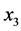 :表示列车分为硬座、软座;
:表示列车分为硬座、软座;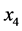 :列车分为座位、卧铺。
:列车分为座位、卧铺。
3.2. 设定理论模型
因为数据是非线性的,所以建立多项式回归模型,而多项式回归模型是一种重要的曲线回归模型,将多项式模型转化为一般线性回归模型,因而我们建立以下模型:
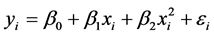 (3.2.1)
(3.2.1)
其中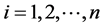 ,该数据中自变量的个数为4,所以我们拟合了一个二阶多项式回归模型:
,该数据中自变量的个数为4,所以我们拟合了一个二阶多项式回归模型:
 (3.2.2)
(3.2.2)
并打算检验是否有交互效应,在回归中,可以采用逐个引入自变量的方式,这样可以清楚的看到各项对回归的贡献,是显著性更加明确。在spss操作中引入自变量,并对自变量进行转化,其中 ;
;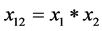 ;
;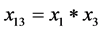 ;
;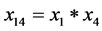 ;
;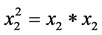 ;
;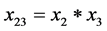 ;
;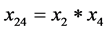 ;
;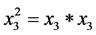 ;
;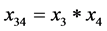 ;
; ;
;
对数据进行转化过后进行线性回归分析。
3.3. 参数估计
如果将曲线模型转化为线性模型,就可用普通最小二乘法估计未知参数,如果不能转化为线性模型,则参数的估计就要采用非线性最小二乘法,在该模型中,我们可以采用普通最小二乘估计 [6] 。
对每一个样本观测值 ,最小二乘法考虑观测值
,最小二乘法考虑观测值 与其回归值
与其回归值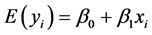 的离差越小越好,综合考虑n个离差值,其中离差平方和为:
的离差越小越好,综合考虑n个离差值,其中离差平方和为:
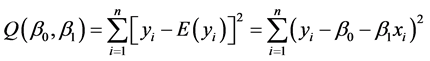 (3.3.1)
(3.3.1)
所谓最小二乘法,就是寻找参数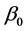 ,
,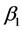 的估计值
的估计值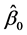 ,
,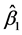 使公式(3.3.1)的离差平方和达到极小,即寻找
使公式(3.3.1)的离差平方和达到极小,即寻找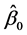 ,
,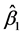 满足:
满足:
 (3.3.2)
(3.3.2)
根据上式求出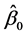 ,
,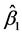 就称为回归参数
就称为回归参数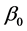 ,
,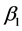 的最小二乘估计,称
的最小二乘估计,称
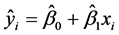 (3.3.3)
(3.3.3)
为 的回归拟合值,简称回归值或拟合值。
的回归拟合值,简称回归值或拟合值。
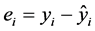 (3.3.4)
(3.3.4)
为 的残差。
的残差。
用一元线性回归方程拟合n个样本观测点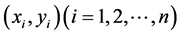 ,就是要求回归直线
,就是要求回归直线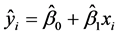 位于这N个样本点中间,或者使这几个样本点靠近这条回归直线。
位于这N个样本点中间,或者使这几个样本点靠近这条回归直线。
残差平方和
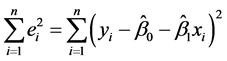 (3.3.5)
(3.3.5)
从整体上刻画了n个样本观测点到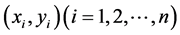 回归直线
回归直线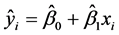 距离的长短。
距离的长短。
对 ,
,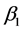 进行求导,使得
进行求导,使得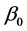 ,
,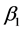 满足下列方程:
满足下列方程:
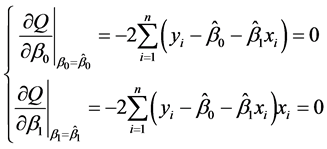 (3.3.6)
(3.3.6)
经过整理,后得到正规方程组:
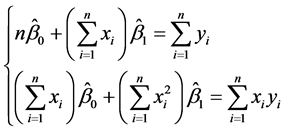 (3.3.7)
(3.3.7)
用正规方程求解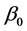 ,
,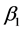 的最小二乘估计:
的最小二乘估计:
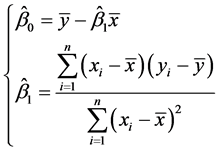 (3.3.8)
(3.3.8)
利用上述公式就可以具体计算回归方程的参数 [7] 。
3.4. 结果分析
由上述理论知识对数据进行spss操作,先对数据进行多项式转化,将二次多项式转化为一次线性的式子,再对数据进行逐步回归操作,剔除不重要的变量,再对剩余数据进行回归分析,结果如下所示:
由模型摘要可看出回归方程中的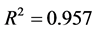 远大于0.9,说明拟合的模型是较好的。且是在方差分析表中可以看出:
远大于0.9,说明拟合的模型是较好的。且是在方差分析表中可以看出:
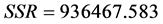 ,
,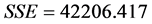 ,
,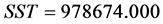 ,
, 的自由度
的自由度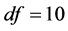 ,
, 的自由度
的自由度 ,
, 的自由度
的自由度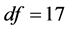 ,且
,且
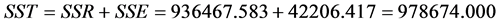
残差的平方和太没有上个模型的值大,说明拟合效果好。
所以得到模型为:
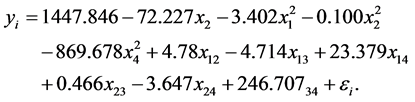
4. 结论
随着经济的快速发展,出行问题成为一重大问题,为了保持市场竞争力,实现利润最大化,我们采用时间序列、回归分析等方法对数据进行两参数指数平滑、多项式回归分析对数据进行整理、分析,获得精确结果。
本文以贵阳到成都方向为实例,经过部分节假日对客座率进行分析,可知在节假日前后旅客流量波动较大,铁路部门可根据节假日客流量波动对列车进行增减变动,而火车站附近餐饮业、服务业也可根据客流量为旅客提供便利;用时间序列法对趋势客流量进行分析,对数据进行平稳性检验,对原序列拟合ARIMA模型,后利用Hlot两参数指数平滑法对数据进行拟合;在回归分析中,将定性数据数量化,根据理论知识对数据进行分析,以起始时间、时长、座位的舒适度为指标,得出客流量与这几个指标之前的关系,这是关于客流量分析的一些方法,这对城市旅游管理部门根据客流量分析结果及时采取措施,有针对的应对淡旺季的不同需求,提高服务旅游质量,减少浪费,提高经济效益。
在多项式回归方法分析中,残差值经过处理依然较大,说明统计的数据尚不完备,给模型推广带来一定难度,初步断定影响客流量的原因还有季节因素、天气因素等,但随着旅游统计工作的进一步完善,运用ARIMA模型进行更加准确的客流量分析。
基金项目
贵州师范学院校级学生科研项目(项目编号:2016DXS099);贵州省2014年省级本科教学工程项目“计算机科学与技术”专业综合改革(项目编号:黔教高发[2014]378号);卓越工程师教育培养计划项目(黔教高发[2013]446号);2015年省级本科教学工程建设项目(黔教高发[2015]337号);2016年大数据视角下的贵阳市交通优化配置问题研究(项目编号:201614223037)。