1. 引言
滚动轴承在各种机械设备中应用广泛,小到汽车制造行业,大到重型机械、飞机轮船都能见到它们的身影。如果不能及时发现机械设备中的轴承损伤,其后果不堪设想。不管是机械损失,还是财产、人员损失,这些损失都是人们不想看到的,也是应该可以避免的,所以对滚动轴承进行监测和诊断必不可少。
大部分关于非平稳信号问题,首要任务都是提取表征初始信号的有效信息,轴承故障分类也不例外,也需要这样处理。轴承故障诊断由早期的人工检测到后来的计算机检测直到今天的智能化检测,现在人工智能检测方法很多,但是在机械故障诊断中应用最为广泛的还是支持向量机(Support vector machine, SVM)和神经网络。直至今日,中外的研究者们已经提出过很多科学的方法,其中就包括人工神经网络和支持向量机。Kankar等人利用多项逻辑回归与WPT相结合的方法来诊断故障 [1] 。Huang等人提出了一种基于改进的SVM的多故障诊断方法,该方法结合了经验模式分解方法和径向基核函数 [2] 。王欣彦等利用神经网络完成了对转子裂纹故障的定量精确识别 [3] 。姜涛等人对传统小波神经网络模型改进,使其能够对轴承故障有效诊断 [4] 。上述几种方法都能对故障进行有效的诊断,但是这几种方法在多分类或者精度上都有着自己的不足。
由于各种不同的因素我们采集的信号会渗杂一些噪声。奇异值分解原理如图1(a)中所示的,经过该过程原始信号变为了比较纯净的重构信号。因此,本文结合初始信号的特点,提出了如图1(b)所示的流程进行诊断。
2. 背景知识
2.1. SVD的特征提取算法
2.1.1. 奇异值分解原理
采样序列为
,其长度为K的电机振动采样数据,可以由y构造一个
的矩阵D,然后我们利用Hankel矩阵对离散信号y进行构造 [5] ,构造的D如下:
(1)
式中,D是
维。D的分解表达式为:
(2)
式中,
是
维,
是
维,
是
维。表达式如下:
(3)
分解后的值向量为
,其中
。并将
的值视为模型特征。
2.1.2. 轴承故障特征提取
对于机械轴承的初始信号
,对其采样得到尺寸为k序列
。将序列进行矩阵构造(Hankel矩阵)、然后将其分解并将分解后得到的奇异值
视为初始信号的特征。由于奇异值的特点:值越大越能反映该值对于初始信号的重要性,值越小往往反映为该值对信号影响小,比较小的值往往是噪声的体现。因此选取适当数量的较大奇异值,然后将其视为故障特征。
2.2. 深度学习方法
深度学习算法是多层网络,而单层网络是非线性的,所以它具有更好的数学表达能力。深度信念网络(deep belief nets, DBN)是由Hinton等人在2006年提出来的,它是在受限玻尔兹曼机基础上构建的 [6] 。(RBM) Roux和Bengio从理论上证明,只要网络单元足够多,RBM就能够拟合任意离散分布的信号 [7] 。在该算法中,从输入层开始每相邻两层组成一个受限玻尔兹曼机,这些玻尔兹曼机连接在一起,构成一个深度信念网络(DBN)。在DBN中上层网络会从下层网络中提取更高阶的特征,它是一种无监督的深度学习算法。RBM是由1个显示层v,一个隐藏层h组成的,它的特点是层间相互连接,层内相互独立的结构。受限玻尔兹曼机结构图如图2所示。图中的底部神经元v为显示层,W为两层相互连接层的连接权值矢量,上层神经元h为隐藏层。
RBM是一个层间相互独立并且全连接的条件概率模型。因此想得到每个隐层神经元的状态,可以借助于概率
,前提是显层状态已知。这里假设隐藏层单元个数为n。同样,通过隐层状态求导显层状态模式一样,只不过依赖的条件概率为:
,这里假设显层单元个数为M。在设计RBM时,我们需要设计显示层维数(等于输入数据维度大小)和隐藏层单元数目(提前设定)。假设训练一个RBM模型,可见层单元数目M,偏置为m维列向量,隐藏单元数目n,偏置为n维列向量,这样就需要训练
个值。RBM的训练算法采用CD [8] 算法,详细步骤如下:
第一步,初始化连接权重W,根据网络的训练规则,定义激励函数表达式为
,这里
,确定隐藏层的输入值;
第二步,将第一步得到的激励函数h作为隐藏层的输入,由网络稳定性要求,定义隐藏层神经元的
开启状态函数即开启状态的概率值
,隐藏层输出的激励函数采用logistic函数
,通过上述计算公式计算出每个隐藏神经元开启状态的概率值。用0代表关闭状态,用1
代表开启状态。由于隐层神经元的状态为二值,则为了确定每个隐元的状态,需要确定一个0,1均匀分布的概率分布
,将每次训练得到的概率
与随机得到的u比较,公式如下:
(4)
第三步,确定显层神经元开启状态。计算方法与第二步相似。
通过CD算法得到的训练结果为整体次优分布。进行DBN的训练时,采用贪心算法,即假设每一步得到的RBM视为每一层的最优结果,然而对整个DBN来说结果是次优的,为了得到全局最优的理想结果,下一步就是进行全局微调。DBN具体训练过程如下 [9] :
第一步,训练第一个RBM模型;
第二步,固定第一步得到的权值和偏置,将输出结果当作下一个RBM的输入;
第三步,根据设计的隐层数,确定下一个RBM。计算方法与前两步相同;
第四步,进行全局调优。
3. 奇异值分解与深度学习在轴承故障诊断中的应用
3.1. 数据预处理
机械设备中轴承原始数据为模拟信号,需要对信号进行离散采样,实验验证所使用的轴承故障数据由凯斯西储大学提供。这些数据来自于一个测试驱动系统,实验仪器主要部件是一个马达、一个力矩传感器和一个测力计。马达由6205-2RS JEM SKF轴承支撑。轴承被研究的位置为内圈、滚珠、外圈3点位置(这里简称外圈故障位置1)、外圈6点位置(这里简称外圈故障位置2)、外圈12点位置(这里简称外圈故障位置3),故障是通过电火花加工由人工给定的单点故障,采样频率为12k赫兹。图3数据的类别从上到下依次是健康、滚珠故障、内圈故障、外圈位置1故障、外圈位置2故障、外圈位置3故障。
轴承的转速为1797 r/min,根据旋转频率轴承旋转一周大约采集400个点,所以每400个采样点作为一次采样结果。为了能够更加全面的反映数据,在第一次采样基础上向后推移10个采样点,作为第二批采样数据,以此类推,直到推移轴承旋转一周时,采样点数为400个为止。
3.2. 奇异值分解进行特征提取
在对数据进行处理后,接下来进行奇异值分解,离散序列为
表示第i个采样点。根据Hankel矩阵构造规则,构造y为矩阵
如下式:
(5)
由于不同信号之间存在差异,所以得到的奇异值也存在差异,图4为不同故障所得到的奇异值,从图中可以看出奇异值前25维有明显的区别,这里选择前25维作为特征向量。
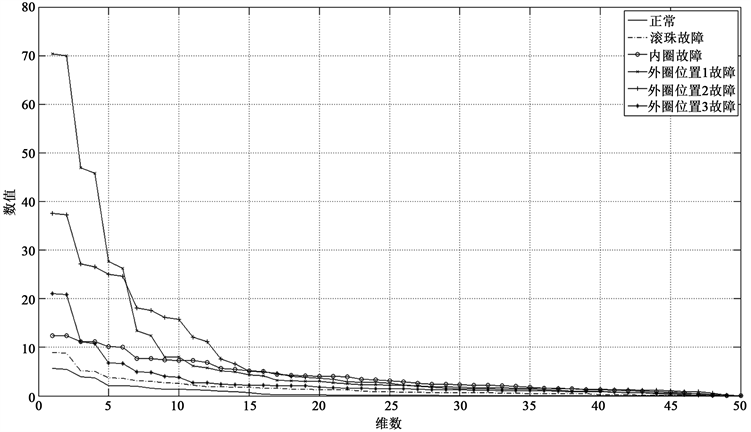
Figure 4. Singular value distribution curve
图4. 奇异值分布曲线
3.3. 模型训练
经过奇异值分解后的特征向量经过归一化处理后才能输入BDN模型。DBN是一个概率模型,不能够直接用作故障诊断模型,需要进行相应的设计。为了能够进行多分类,需要在模型的顶层添加分类器y,这里选用softmax分类器。DBN模型如图5所示,模型在进行数据识别时,先将从数据中得到的特征向量输入input层,然后经过一层一层的隐藏层后到达softmax层进行识别,最后得到数据的分类结果。
大量研究证明,理论上网络结构越深,网络结构越复杂,表达数据的能力也越强。但是网络结构越深,意味着训练的困难程度越大、稳定性越差、速度越慢,难以进行合适的训练,结果反而更不理想。在设计DBN时我们需要考虑网络的深度、各个隐层神经元数目以及训练过程中要考虑怎样初始化权值和偏置。
3.3.1. DBN网络深度
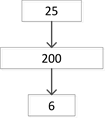
实验选择的隐藏层的层数及每层神经元的个数为下面a,b,c,d四种情况,结构图如图6所示。
通过这四种不同深度的DBN模型,对给定的输入数据进行分类识别。由仿真结果知,在同一样本情况下,采用不同深度模型其分类结果不同。这四种不同深度的DBN分类器对测试集的识别精度比较结果如表1所示。
从上表可以看出,DBN分类器精度随着隐层数目的增多先上升后下降,不难发现当隐层数目为3层时精度达到最高,因此这里选择隐藏层的层数为3。
3.3.2. 隐藏层单元个数
Hinton在2012年的研究 [10] 中指出,模型的训练过程中,用来表征样本的类别需要的比特数,通常等于一个训练样本施加在参数上的约束项的数量,可以用如下表达式计算:
 (a)
(a) 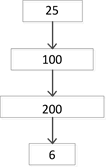 (b)
(b) 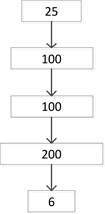 (c)
(c)  (d)
(d)
Figure 6. DBN four different depth classifiers
图6. DBN四种不同深度的分类器

Table 1. Recognition accuracy of BDN at different depths
表1. 不同深度BDN的识别精度
(6)
公式中,x是样本的类型数。确定比特数后,用其乘上训练集的容量,在这个结果基础上选择比其低一个数量级的值作为隐元个数 [8] 。对于高度冗余的训练集,可用更少的隐层神经元。可以用如下表达式计算:
(7)
其中
代表隐元数目,
代表训练集容量,根据以上公式(6)、(7)设置3个隐层神经元数目分别为100,100,200。
3.3.3. 权重初始化、批量选择和全局优化算法选择
在进行DBN模型的参数训练时,模型被训练的步骤主要包括以下两步:
第一步,贪心逐层训练。首先初始化每一个参数(包括每一层的权值和偏置),一般情况下,将每一层之间的权值W按照正态分布N(0,0.01)生成的值进行赋值 [10] ,而对于所有偏置设置为0。学习率应该在0到1之间,根据样本训练经验,在实验过程中学习率选为0.1比较合适,所以这里选择学习率为0.1。
更新DBN全部参数时,综合考虑计算量和训练时间应该选择小批量训练数据,即每次从全体训练集中选取一个容量小一点的数据集。再进行小批量训练时,批量容量大小的选择至关重要,如果批量选得太小则训练不够充分;如果选择批量容量太大则容易错过最优点。Geoffrey Hinton [10] 给的建议是,若数据集中数据类别是等概率的,则批量的理想尺寸应该与样本类别的总数量相等,并且尽可能批量中包含每个类别的样本。反之,凭经验选择10~100视为小批量容量。本实验数据集是等概率类别,我们选择的批次大小为6,选取每6个为一个小批量将训练集分批训练。在使用小批量数据后,在更新参数过程中也需要做相应的修改 [11] ,通常使用平均梯度,表达式如下式:
(8)
B为小批量的容量。
第二步,使用监督算法进行整体微调并进行识别。对整个网络用普通神经网络训练方法进行参数调整,在方法选择上分别采用随机梯度下降法(SGD)、动量项学习率法(Mom) [10] 、Adagrad变学习率法 [12] 。训练结果如图7所示。
图中横坐标为迭代次数,纵坐标为精度。由仿真可以得出,当应用Adagrad变学习率进行全局训练时精度最高,因此选择Adagrad变学习率进行识别。
3.4. 实验结果分析
本实验采取交叉验证方法。每一种类型数据的训练样本和测试样本的比例都设定为9:1,每次都是随机抽取训练样本,剩余为测试样本。进行10次实验,10次实验的结果如图8所示。
经过十次实验,奇异值DBN方法对轴承故障数据的分类识别精度分别是:0.997、0.982、0.979、0.991、0.975、0.982、0.985、0.99、0.98、0.984。求这10次精度的均值为98.4%,
方差是0.42。说明本文给出的奇异值DBN方法是可行有效的。
3.5. 奇异值DBN方法与现有识别方法的比较
为了验证采用本文方法进行故障诊断的优越性,本文还同时与小波变换、支持向量机、小波神经网络等方法进行了对比,结果如表2所示。由仿真结果知,本文给出的奇异值DBN方法对轴承故障的识别效果比现有这几种识别方法要好,因为本奇异值DBN方法不但具有较高的识别精度,而且稳定性好、鲁棒性强。
通过对比以上四种方法可以看出,采用本文奇异值DBN方法得到的精确度最高,其中本文方法的准确率为:98.4%,采用小波变换平均精确度为92.6%,采用支持向量机平均精确度为94.7%,采用小波神经网络精确度为95.3%。
4. 结论
实验使用的初始信号为轴承振动信号,由于各种原因,信号中难免会混入噪声,所以选择如本文图1所示流程进行轴承多故障诊断实验,最后的模型为深度信念网络。实验结果表明,采用本文给出的奇异值DBN方法是一种有效轴承故障方法,其对轴承的故障识别的正确率为98.4%。该方法优缺点总结如下:
表2. 比较结果
1) 首先对数据集进行了特征提取,可以滤除掉一部分的噪声,同时结合使用能够更好拟合数据的深度学习方法,所以能够取得更好的精度。
2) 本文应用的深度学习方法需要充足的数据作为支撑,实验数据以及应用数据需要充足,如果没有充足的数据作为支持,效果可能会很不理想。
3) 迁移学习可以进一步解决(2)中涉及的缺点,因此在数据不够充足的情况下可以借助与迁移学习、深度学习结合方法来进行一定的补偿。
NOTES
*通讯作者。