1. 研究现状
目前国内注册商标已达200多万,传统的商标检索是基于文本的检索,包括基于类目的检索和基于关键字的检索。随着注册商标数目的增多,传统的商标检索显露出如下几个弊端:
1) 检索系统基于手工分类管理,管理成本太高;
2) 出现比较抽象的商标图像时,不易以文本的方式来描述图像,不易归类;
3) 对于图像的相似性,没有一致的衡量标准,不能保证商标分类是否正确。
鉴于以上这些缺点,人们开始考虑将基于内容的图像检索技术应用于商标图像检索领域中,从而实现更准确、高效和直观的商标检索。因此研究基于内容的商标图像检索系统是非常有必要的。
基于内容的商标图像检索是基于商标视觉特征的相似性检索技术,传统的视觉特征包括颜色、纹理和形状特征。商标图像大部分都是人工设计的,一般不存在纹理特征,且大部分商标的形状特征要比颜色特征更为显著,所以商标图像检索使用形状特征检索效果更好。因此本文的主要工作目标就是:1) 提出一种改进的商标图像形状特征提取方法;2) 将该方法应用于商标图像检索系统中,设计出一个性能良好的商检图像检索系统 [1] 。
2. 研究内容
在基于形状特征的商标图像检索系统中,商标信息通过形状特征传递给上层检索操作,形状特征提取是否全面准确影响着整个系统的检索结果,所以形状特征提取方法是商标检索系统中最核心的技术,也是本文的研究重点。基于形状特征的商标检索系统的检索过程如图1所示,其中实线方框内部分是本课题的主要研究内容。
基于形状特征的商标检索流程包括商标预处理、边缘检测、形状特征描述、商标特征匹配和返回检索结果五个部分,其中边缘检测和形状特征描述是本文研究重点。
边缘检测对商标形状特征提取非常重要,直接反映了商标的物质属性和空间属性。本文在Canny算法的基础上提出一种新的边缘提取算法——自适应Canny边缘提取算法,该方法通过两次使用最大类间方差法获得商标边缘检测的阈值,实现Canny算法 [2] 的自适应性,解决其过分依赖人为经验的问题。
形状特征描述是本文研究的另一个重点,是商标形状特征提取的核心。本文在形状上下文(Shape Context)的基础上提出一种新的描述方法——内角形状上下文(Inner-Angle Shape Context),该描述方法不
受商标旋转的影响,并且能够很好的描述内部有洞的商标图像。
3. 系统商标预处理
商标预处理是系统对商标处理的第一个阶段,目的是去除商标中的无用信息,增强商标中的有用信息,为以后商标特征提取提供最有用的视觉信息。常见的预处理过程有灰度化、归一化、二值化、去噪和效果增强处理等步骤,处理流程图如图2所示。
3.1. 商标灰度处理
灰度处理是将商标图像转换为灰度图的一系列操作,灰度图在计算机上以位图的形式保存,即一个矩形点阵,每一点代表一个像素(pixel),矩阵的大小代表灰度图像的大小。一幅大小为m*n的商标,是由m*n个灰度值不等的像素点构成的。灰度值的大小决定着图像明暗程度的变化,它直接的反应了图像的视觉信息。灰度值的取值范围为[0,255],值的大小指图像中像素点的颜色深度 [3] ,让像素点从黑过度到白,其中0为黑色,255为白色,也就是人们常说的256级灰度。我们采用文献 [4] 提到的算法对商标进行灰度处理。
3.2. 商标归一化处理
商标归一化是将待处理的商标灰度图转化成相应的唯一的标准形式的过程。商标的某些性质是固定的,比如目标区域的面积、边缘的周长等,不会因为旋转、平移而改变,所以为了消除或减弱周围环境对图像的影响,我们需要事先对商标灰度图进行归一化处理。常见的商标归一化的方法有灰度归一化、

Figure 2. Trademark preprocessing flow chart
图2. 商标预处理流程图
几何归一化和变换归一化。本文采用的是基本的几何归一化。
几何归一化是为了将大小不一的商标图像变换成统一的尺寸,方便后续商标特征的提取、特征点匹配、以及相似度的计算。由于平时我们输入的商标图像都会出现大小不一的情况,当商标图像过小时会影响系统识别率;当商标图像过大时,图像信息过多,数据量过大,增加了图像处理的计算量。所以,为了方便后续图像处理,需要对输入商标图像进行统一的大小归一化处理。对于较小(宽度 < 100,高度 < 30,单位为像素)或较大的图像(宽度 > 250,高度 > 80,单位为像素),按照原始图像比例进行缩放,这样就能保证图像归一化后宽度与高度的比例关系保持不变,避免归一化处理引起的图像形变,进而影响后续的商标图像处理操作 [5] 。
3.3. 商标二值处理
目前主流的二值化方法有双峰法、P参数法、最大熵法和最大类间方差法。最大类间方差法的应用广泛,尤其是对前景和背景差别明显的图像,处理效果非常好。考虑到本文商标图像的目标和背景灰度差别明显,本文采用最大类间方差法确定Canny边缘提取时的双阈值,通过计算机自动确定图像阈值,无须依靠人工来确定阈值,实现阈值自适应性。
3.4. 商标去噪处理
高斯滤波器是较其他滤波器能够更好地去噪,但滤波器仍有很多问题,比如滤波器在去噪的同时也去除掉很多图像的细节,针对此缺点已经提出了很多改进意见 [6] [7] [8] 。一种改进思路就是将图像中未被污染的和被污染的像素点分开,只对被污染的像素点进行去噪处理,从而最大限度的保留图像中的有用信息,去除无用信息 [9] 。另一种改进思路是与数学形态学相结合的滤波方法,将中值滤波和形态学滤波相结合,既能有效的去除图像中的噪点,又能很好的保留图像原有的边缘信息 [10] 。
高斯滤波器是一类线性平滑滤波器,它能有效去除服从正态分布的噪声。一般情况下,商标图像结构相对简单,噪声也多是由于拍摄和输入造成的点状噪声,所以本系统采用高斯滤波器来消除商标图像的噪声。
高斯滤波去噪时,需要人为设定平滑系数σ,σ较小时定位准确,但去噪效果差;σ较大时定位不准,去噪效果好。故本系统使用一种自适应高斯平滑滤波器 [11] 。该方法通过移动滤波窗口,自动计算并获取图像当前像素点的空间尺度参数值,从而实现高斯平滑滤波的自适应性。
3.5. 商标图像效果增强处理
商标图像去噪后的视觉效果削弱好多,为了方便后续特征提取、特征点匹配和相似度计算,我们需要对去噪后的灰度图像进行效果增强处理,在增强图像主要信息的同时不削弱相关信息,使图像视觉效果更强。
本文采用形态学算子 [12] 对灰度图像进行增强处理。形态学算子属于数学形态学研究的范畴,由G.Mathern和J.Serra提出,如今已经广泛应用于图像处理的增强、分割、边缘检测等领域中。本文采用形态变换中的膨胀运算,增加灰度图像边界像素点,从而达到增强图像的目的。增强后的图像在不削弱相关信息的同时能够突出图像的主要信息,视觉效果更加强烈。
4. 系统商标形状特征提取
商标预处理后,系统对商标梯度直方图进行形状特征提取,包括边缘检测、轮廓跟踪和形状特征描述三个步骤,具体系统对商标形状特征提取的流程图如图3所示。
4.1. 商标图像边缘检测
边缘检测是图像处理和计算机视觉中的基本问题,对商标图像特征提取非常重要。目前已经有许多方法用于边缘检测,检测效果也很好,比如Roberts Cross算子、Prewitt算子、Sobel算子和Canny算子 [2] 等。其中Roberts算子计算简单,但精度不高,只能检测出图像大致的轮廓,而对于比较细的边缘可能会忽略。Prewitt和Sobel算子比Roberts效果要好一些,但检测精度还是不高。Canny算子的检测效果优于Roberts、Prewitt和Sobel算子,能够检测出图像较细的边缘部分。但Canny算法也有它自身的缺点,Canny算法需要人为设定高低阈值,梯度值在双阈值范围内的像素点就是图像最可能边缘点。当高低阈值设置不合适时,商标图像背景中的点和曲线会被当做边缘,商标图像目标边缘被当做噪点,提取出来的图像边缘跟实际图像相差甚远。所以本文基于Canny算法提出一种自适应Canny边缘检测算法,该算法能够根据处理商标的内容,自适应生成高低阈值,不再过度依赖于人为经验。
自适应Canny边缘检测算法采用两次最大类间方差法求得高低阈值,该方法的理论思想是:根据商

Figure 3. Trademark shape feature extraction flow chart
图3. 商标形状特征提取流程图
标梯度直方图的特性,首先将直方图信息分为绝对边缘和非绝对边缘两类,采用最大类间方差法获得一个最佳的分割阈值,并用该阈值完成对所有划分为绝对边缘点的分类,对绝对边缘点进行定位并以此作为边缘连接的基础。对非绝对边缘部分的梯度直方图,再次采用最大类间方差法得到另一个分割阈值,以该阈值作为连接边缘的最低梯度值。根据两次得到的分割阈值结果完成对Canny算法中双门限值的设定。得到商标图像所有可能的边缘点后,需要对图像边缘进行进一步的跟踪处理,即将边缘点连接起来,从而获得商标图像边缘,具体跟踪算法如下:
1) 任取一个梯度值大于t1的像素点,将其设为绝对边缘点,作为边缘连接的起始点。
2) 在该绝对边缘点的八邻域范围内,判断是否存在其它的绝对边缘点,如果有则作为边缘点连接。如果八邻域范围内不再有绝对边缘点,则转向判断是否存在梯度值大于t2的边缘点,如果有也把它作为边缘点连接。
3) 当邻域内所有梯度值大于t2的像素点处理完毕后,转向下一绝对边缘点进行处理,当所有的绝对边缘点都处理完毕后,边缘连接过程结束。
根据以上跟踪算法得到商标图像边缘,下面需要在边缘点中均匀提取100个样本点作为图像特征点。
4.2. 商标图像形状特征描述
形状特征描述按照内容分为两类,一类是区域特征,另一类是轮廓特征。区域特征主要针对图像的整个形状区域,常见的形状特征描述方法有:限元法(Finite Element Method)、小波描述符(Wavelet Deor)等方法。区域特征描述符能很好的表现图像形状轮廓内部的信息,但计算量大,时间复杂度高。轮廓特征主要针对物体的外边界,常见的特征描述方法有:边界特征法、傅里叶形状描述法、几何参数法、形状不变矩法和形状上下文等。其中形状上下文经常被用在商标检索方面,但该方法不能描述内部有洞的商标,对于图像目标旋转比较敏感,所以本文提出一种新的商标形状特征描述方法——内角形状上下文(Inner-Angle Shape Context)来描述图像特征点,该方法是在形状上下文 [12] (Shape Context)基础上提出的,不仅能够有效的利用图像轮廓信息,更能表现图像内部区域的信息,对图像目标的旋转也不敏感。
IASC(Inner-Angle Shape Context)很好的利用了商标图像的区域连接点,利用连接点之间的最短路径和连接点切线之间的夹角来表示图像形状特征。当商标图像内部有空洞时,IASC能够保证两点之间的连线不会穿越形状边界,从而做到在不分解局部形状结构和连接的情况下,通过Inner-Angle反映出图像的局部信息。下面给出一个计算商标图像样本点距离的方法,从而保证商标图像样本点之间的连线完全落在图像前景中,解决商标图像内部有洞的情况。
首先定义一个形状
,且O是闭合的,由形状
组成,每一个形状Oi,
都是凸区域,每个Oi之间都有连接点Jij,则
,如图4所示,Oi和Jij需满足以下条件:
1)
,且
,
。
2)
,连接点Jij也是凸包的,它将Oi,Oj连接在一起,如果Oi,Oj之间没有连接点,则
,否则
,
。
下面定义图像形状O上样本点之间的距离。在形状O上取两个样本点
,它们之间的距离记为
。如果它们之间的连线完全落在图像前景中,则x和y之间的距离为欧氏距离,即
。如果x和y之间的连线没有完全落在图像前景中,则x和y之间的距离为两点间的最短路径,最短路径采用Floyd-Warshall [13] 提出的计算方法。如图5所示,
相当于区域O1O2O3内的欧氏距离的加和,这样就保证了样本点之间的连线全都落在图像前景中,在不分解局部形状结构的情况下,通过最短距离反映出商标图像的局部信息。
一般情况下,给定的x,y之间的最短路径是唯一的,但也会有不唯一的情况出现,当出现这种情况
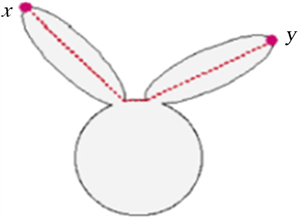
Figure 5. The shortest path between x and y
图5. x,y之间的最短路径
时,我们随机选择一条路径作为最短路径。
在SC算法中,图像特征点是通过计算每个bin中的像素点个数来表示的。同样的Inner-Angle Shape Context也是通过这种方法来表示特征点的。这两种方法之间的不同在于IASC计算的是两个样本点之间的相对内角,也就是Inner-Angle,而SC计算的是样本点跟X轴之间的夹角。
在本文提出的形状描述算法中,两样本点之间的相对方向用内角θ来表示,本文将内角θ取为最短路径
的起始点p的切线方向与最短路径
的第一条路径之间的夹角,表示为
,如图6所示,θ就是样本点p的内角,显然只要p和q点的相对位置不发生改变,p,q两点的内角就不会发生改变。所以,用以上方法表示样本点内角能解决图像旋转带来的问题。
以上就是本文提出的基于Shape Context算法的Inner-Angle Shape Context
描述方法。该方法通过样本点之间最短距离来表示商标形状,做到在不分解局部形状结构的情况下,将商标内部形状结构反映出来。通过样本点的内角来表示样本点之间的相对位置信息,在商标发生旋转时,只要样本点的相对位置不发生改变,样本点的内角不会发生改变,一定程度上能解决商标旋转带来的问题。
5. 系统商标检索
5.1. 商标特征点匹配
在形状上下文算法中采用匈牙利算法对商标样本点进行匹配,匹配效果较好,故本文也采用匈牙利算法对商标样本点进行匹配。
匈牙利算法是图像匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。通过该方法我们可以将图像100个特征点进行一对一的匹配。假设需要进行形状

Figure 6. The inner angle between sample point p and q
图6. 样本点p,q之间的内角
匹配的两幅图像分别为图像f和图像g,通过边缘检测和轮廓跟踪法,所提取的包含n个特征点的点集分别为
和
。设pi为图像f上的一个边缘特征点,而qj是图像g上的一个边缘特征点,则pi、qj之间的匹配代价cost值为Cij = C(pi,qj),定义如下:
(5.1)
则图像f、g之间的匹配代价为:
(5.2)
当匹配代价Cs的值最小时,图像f和g的特征点的匹配方式达到最优。
5.2. 商标图像相似度计算
由于在基于形状的商标图像检索中商标图像的特征多是用向量表示的,所以,常用的相似性度量方法都是向量空间模型。即将商标图像特征看作是向量空间中的点,通过计算两个点之间的距离来衡量商标图像特征间的相似度,例如在聚类问题中一个很关键的问题就是如何衡量两个数据间的相似性,就可以采用距离这样的相似性度量方法。最理想的距离度量机制应该能够反映人的感觉,也就是说,人们感觉相似的图像之间的距离应该较小,而感觉不同的图像之间的距离应该较大。
本文的相似性度量属于无序简单集合间的度量。无序简单集合间的度量分为两大类方法:分散性度量和整体性度量。从分散的角度,即分别度量两个集合之间各点的相似度,再按某种策略进行整合;从整体的角度,先获得对数据集合的一个整体性表示,基于整体性来度量。整体性度量的表示形式有代表点、统计量、统计分布、直方图和熵等,本文采用直方图表示数据集合。
本文采用χ2距离来表示图像之间的距离。假设需要进行形状匹配的两幅图像分别为图像f和图像g,通过边缘检测和轮廓跟踪法,所提取的包含n个特征点的点集分别为
和
。则图像f、g之间的距离为:
(5.3)
距离D(f,g)的值越小,表示图像f和g越相似。
6. 商标检索系统的设计与实现
6.1. 系统开发环境
本文商标检索系统在window8操作系统平台下,采用matlab进行开发。本文中商标图像数据是利用My SQL数据库来存储和管理。本系统中用户通过键盘、鼠标等外设与检索系统进行交互,操作简单方便。本系统的详细开发环境配置如表1。
6.2. 系统框架设计
基于内容的商标图像检索过程是对于给定的待检索商标图像,首先进行图像预处理;然后提取该商标图像的特征向量;最后将该图像特征向量与特征数据库中每幅图像的特征向量进行相似度计算、匹配,并将检索结果按相似度由大到小排列返回给用户。上述检索过程建立在商标图像特征库基础之上,在检索之前,图像特征库必须已经存在。因此,本系统主要包含商标图像特征库生成子系统和商标图像查询子系统两个部分。商标图像特征库生成子系统主要是提取商标图像的形状特征并存入数据库。在提取特征时还需进行相应的预处理操作。商标图像查询子系统主要是完成商标图像的匹配检索功能,即对于给定的待检索商标图像,提取相应的特征,并与特征数据库中的特征进行相似度计算、匹配,显示检索结果。系统的框架模型如图7所示。
根据系统的框架结构可知,本系统主要包括商标图像预处理模块、商标图像特征提取模块和图像匹配模块三部分,如图8所示。

Table 1. Trademark image system development environment configuration
表1. 商标图像系统开发环境配置

Figure 7. System framework structure model
图7. 系统框架结构模型
6.3. 系统应用
系统用户界面由input Selection区和Rank区两个部分组成。界面如图9所示。
用户在input Selection区中输入待检索商标图像地址和数据库地址,点击OK按钮,即可将待检索图像导入系统,图像在右侧白框内显示,如图10所示。
用户输入待检索图片后,点击运行按钮“RUN”,系统进入商标处理过程中,处理结束后系统返回相似度最大的15幅商标图像,并从大到小在Rank区排列显示,如图11所示。
其中A为与查询图像相关的图像集合,B为检索到的图像集合,a为检索到的相关图像子集,b为检
索到的不相关图像子集,c为未检索到的相关图像子集,d为未检索到的不相关子集。
在计算查准率和查全率时,先选定含有特有目标的图像作为一组相关的图像,然后根据返回的结果计算查准率和查全率。一般情况下,查准率和查全率的变化是相反的,当要求查准率提高时,查全率就会降低,当要求查全率提高时,查准率就会降低。因此,系统评价需要在两个评价指标之间找到一个平衡点,在该平衡下系统检索效果较好 [14] [15] 。
6.4. 实验结果
本系统实验所用的商标图像库包含大约1000张实验图像。每个商标均为JPG格式的图像,尺寸均为300*300,大多数大小在l0k左右。检索前事先对图像库中的商标进行预处理、提取商标图像特征向量,并将特征向量入特征数据库中;检索时对目标图像进行预处理、提取商标图像的特征,与特征数据库中的商标图像进行匹配,返回商标检索结果。
本文对商标检索结果进行了分析。实验过程分两步:首先,对同一检索图像,计算其检索结果的前3、6、9、12、15张图片的查准率和查全率;然后对同一检索图像进行5次检索操作,取5次检索结果的平均查准率和查全率。根据以上实验步骤得到表2商标图像的查准率和查全率,由此绘制的查准率与查全率曲线(PVR曲线)如图12所示。
本文对不同大小的数据库的系统检索时间进行了统计,记录结果如表3所示。由此绘制的检索时间曲线如图13所示。
7. 结论
基于形状特征的商标图像检索是基于内容的图像检索(CBIR)的一个重要研究领域。一方面在于形状特征比颜色和纹理特征更能表达图像内部信息,更容易将不同的图形区分开来;另一方面由于形状特征本身的特点给研究工作带来了一定的难度。所以基于形状特征的商标图像检索是基于内容的图像检索中一个极具挑战性的研究课题。
商标形状特征的提取和商标图像的匹配是商标图像检索中两个最重要的技术难点和工作重点。本文的工作重点在于形状特征的提取,针对Canny算法和Shape Context算法的不足提出相应的改进方法,并
Table 2. Trademark image registration rate - inspection rate table
表2. 商标图像查准率-查全率表
Table 3. System retrieval schedule
表3. 系统检索时间表
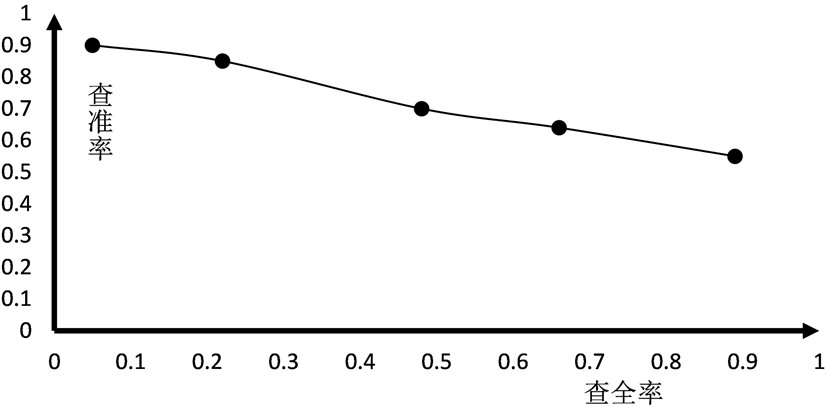
Figure 12. System precision and recall curve
图12. 系统查准率和查全率曲线
将改进方法应用于商标图像检索系统中,但由于作者研究能力不足,研究时间有限,基于形状特征的商标图像检索系统只是一个具备了基本功能的检索系统,该系统还存在着很多不足,还有很多问题需要进一步解决。