1. 引言
关于青海省的植物种类及其特征 [1] - [6] 、植物识别 [7] [8] [9] 等方面的研究都取得了突破性的研究成果。但传统的遥感图像分类方法在进行植物识别时,由于图像具有较高的空间分辨率,会出现同物异谱等问题。植物的识别是复杂度高且数据量大的一项研究,因此深度学习在植物识别方面具有技术优势和广阔的发展前景。卷积神经网络 [10] [11] [12] [13] [14] (Convolutional Neural Network, CNN)是深度学习研究中具有代表性并且十分高效的方法之一。最早的卷积神经网络模型是由纽约大学的Yann LeCun教授提出来的 [15] 。经过了整整20年的发展,至今卷积神经网络技术已在计算机视觉领域确立了统治地位。
Lopatin等 [16] 使用地面高光谱仪器距地面2.5米的高度采集草地植物影像,证明在低结构异质性环境下,高空间分辨率的高光谱遥感适用于基于个体的草地植物物种分类。Shang等 [17] 分析了不同种类草地植被叶片高光谱数据的原始特征和灰度共生矩阵的纹理特征,设计了一种基于植被特征库的植物精细分类算法。Meyer等 [18] 用机器学习技术测试了高光谱和多光谱在现场测定的适用性,成果映射出在区域范围内的植被覆盖和地上生物量。
现有的针对草地的精细分类通常采用混合像元分解、端元提取的方式,处理航天航空遥感获得的地面光谱数据,空间分辨率很有限,限制了草地植物的识别,而前人对草地植物的识别多集中于大面积的种群识别。本文从全局特征、PCA + SVM (主成分分析法+支持向量机)、深度卷积神经网络三种方法出发,通过对比试验,对数据集中的草地植物进行分类检测,提高检测精度,为草地植物分类检测提供便利。本文采用地面采集的数据,空间分辨率较高,可以做到单株植物的识别。
2. 基于深度卷积神经网络的草地植物识别方法
本文使用的算法流程如图1所示。实验室实地采集获得青海地区6000余幅多光谱草地影像数据。有别于一般在划分数据集之前就进行图像预处理的做法,本文选择将预处理步骤放在训练前。这样做的好处一是保留测试集本身的客观性(没有经过人为处理),二是可以通过程序随机生成预处理所用方法的参数,使得进入网络的每一批次的数据都不尽相同,变相的丰富了数据量,防止网络过拟合。
2.1. 图像预处理增强
当拍摄者从俯视角度获取植物照片时,植物影像势必会由于拍摄者位置方位不同产生不固定的旋转偏移。此外,受拍照时的光照强度、遮盖、阴影等影响也会引起数据集影像信息的波动。本文通过多种图像增强手段对植物图像进行预处理以消除这些影响(图2)。具体步骤为随机加窗、图像大小调整、随机翻转、灰度调整。
2.2. 基于自选网络的识别方法
本文首先尝试使用表1所示的网络结构进行图像识别。该网络基于经典的Lenet-5 [19] 模型,在其基础上进行了一些改进。
1) 将原本5 × 5的卷积核替换成两个级联的3 × 3卷积核。
2) 参考AlexNet [11] ,在CNN中使用重叠的最大池化,让池化层的步长比池化核的尺寸小。
3) 学习AlexNet [11] ,使用修正线性单元(Rectified linear unit, ReLU)作为激活函数。
4) 增加局部相应归一化层(LRN),对局部神经元的活动创建竞争机制。
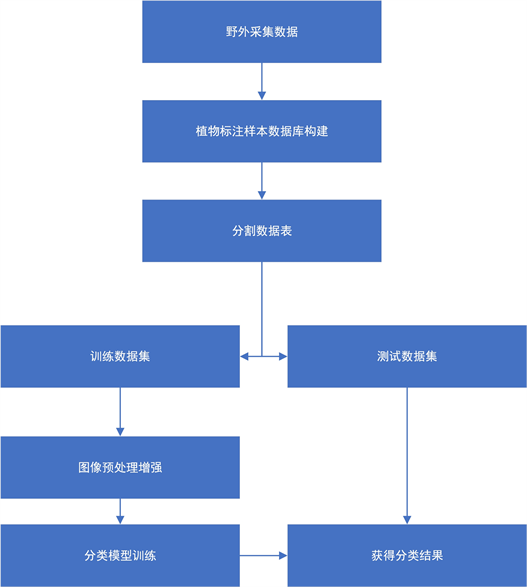
Figure 1. Flow chart of grassland vegetation image recognition method based on convolution neural network
图1. 基于卷积神经网络的草地植物图像识别方法流程图

Figure 2. A schematic diagram of the process of plant image preprocessing (a): initial input image; (b): random framing effect; (c): cut the image according to the frame and adjust the size; (d): image is randomly flipped
图2. 植物图像预处理过程示意图。(a) 初始输入影像;(b) 随机加框效果;(c) 将图像按框裁切,并调整大小;(d) 图像随机翻转

Table 1. A modified convolutional neural network model based on Lenet-5 model
表1. 基于Lenet-5模型改进的卷积神经网络模型各层属性表
2.3. 基于fine tuning技术的识别方法
有时难以获得大量的训练数据,数据量过小时,超参数难以调整,学习权重不充分,容易出现过拟合。这时采用迁移学习的策略,在一个已经被海量数据训练好的模型的基础上微调(fine tuning)就是一个理想的策略。基于fine tuning技术的图像识别算法可以概括为以下步骤图3。
针对植物图片数据量过少的问题,本文尝试使用经过海量数据集预先训练好的模型作为网络的超参数,并在其基础上用少量植物样本数据进行微调,获得适合与解决本文研究任务的分类模型。具体本文选择Google提出的Inception_v4模型 [20] 作为我们的预训练网络,将该模型学习好的参数输送到网络中作为初始参数,修改最后分类层的输出个数对应本文研究对象的类别数目。固定前面几层的参数,只学习最后的Logis层和Aux_logits层。最后用实验室的带标签的草类数据集微调模型。
3. 青海地区草地植物图片识别方法实验
3.1. 图片采集和样本库构建
3.1.1. 图片采集
实验室通过自主集成的手持多光谱图像采集设备,于2017年8月11日至8月18日在青海省海北州海晏县西海镇附近采集了6000余张草地的多光谱影像数据,原始数据参数如表2,图4所示。
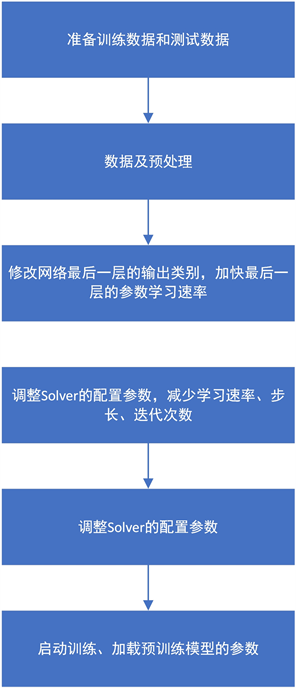
Figure 3. Image recognition algorithm based on fine tuning technology
图3. 基于fine tuning技术的图像识别算法

Figure 4. An example of the original image data after mosaicking (a): true color synthetic original image; (b): a’s partial magnification effect
图4. 拼接后的原始影像数据示例。(a):真彩色合成的原始影像;(b):a的局部放大效果
Table 2. Original data parameters of each multispectral image
表2. 每幅多光谱图像原始数据参数
由表2和图4可以看出,原始图像数据具有空间分辨率达毫米级、图像局部过曝,配准不精确、图像边缘存在光谱畸变等问题。
如此高的空间分辨率和光谱畸变使得传统的遥感影像分类方法在应用中,将面临严重的同物异谱现象。且研究对象大都是绿色植物,不同种类的草在光谱信息上的差异并不明显,即存在异物同谱现象。使用光谱信息进行草种的分类识别难度大,因而需借鉴目前主流的图像识别算法的思路。
3.1.2. 植物标注样本数据库构建
预处理流程图见图5(a)。实验室先将原始6个波段的数据对齐拼接,再使用真彩色合成获得彩色图像。通过人工裁剪(图5(b)),从合成的6000多张彩色图片中找出三种典型的青海湖地区草场的代表草种,分别是马蔺草、狼毒草和香青草。每种100张,共300张。样本库示例见图6。
3.2. 基于全局特征的图像识别实验
实验通过三种特征算子获取组合特征向量之后,经过归一化处理得到归一化的特征向量,每个特征向量长度为532。归一化的特征向量按9:1的比例随机划分成训练数据集和验证数据集。本文选取逻辑回归(LR)、线性判别分析(LDA)、k近邻(KNN)、决策树(CART)、随机森林(RF)、朴素贝叶斯(NB)和支持向量机(SVM)七种分类器模型训练。使用训练数据集训练好的模型采用k折交叉验证(k = 10),最后得分如表3所示。
本文通过k折交叉验证选取准确率最高的随机森林模型用于测试数据集的分类。实验测试了决策树数目取不同值时对分类结果的影响,当决策树取值在[1, 30]之间时,分类结果的各项指标会上下波段,当决策树数目取5时整体效果最好(平均召回率 = 0.7,平均精度 = 0.8,平均f1得分 = 0.64)。
表4所示是使用全局特征+随机森林分类法,在决策树数目 = 5时的各项分类结果统计表。该方法对狼毒草的识别能力很差,虽然精度很高,但召回率只有0.2,即10张狼毒草照片里只有2张被识别出来。马蔺草的召回率是1.0,表明所有马蔺草均被识别出来,但是精度只有0.59。这说明该分类模型倾向于把马蔺草和狼毒草都识别成马蔺草,显然也是不合理的。香青的召回率和精度都挺高,说明该分类模型能够较准确的识别出香青。
3.3. 基于PCA和SVM的图像识别实验
在使用主成分分析法对带标签植物样本数据集进行抽象降维时,主成分向量的个数N是重要的超参数。实验测试了五种取值下的评分表现,结果表明N取30时的识别性能最佳。表5展示出N = 30时该方法的分类结果评价。统计结果表明,该方法对三种草的识别精度和召回率比较平衡,而且都比较高(平均 > 0.80)。
使用支持向量机模型作为分类器时,需要注意超参数的选择,包括惩罚参数C、核函数模型kernel、核函数的参数gamma等。本文采用交叉验证的方法选取最优化的结果和参数。实验结果表明,kernel选择径向基核函数(Radial Basis Function, RBF),C = 10,gamma = 0.01时可以取得最优结果。
3.4. 基于卷积神经网络图像识别实验
本文首先尝试使用在Lenet-5的基础上改进的卷积神经网络做分类实验。网络结构和数据流动情况如

Figure 5. The construction method of database with labeled plant samples (a): tagging plant sample database construction flow chart; (b): image acquisition and tagging software developed by laboratory
图5. 带标注植物样本数据库的构建方法。(a):带标注植物样本数据库构建流程图;(b):实验室开发的图像采集标注软件
图7所示。输入数据的batch_size设置为12,图像大小为208 × 208 × 3。conv1和conv2使用16个3 × 3的卷积核,采用零填充方式,输出的feature map大小与输入图片的大小相同;pooling1和pooling2使用3 × 3的池化核,采用重叠池化方式,步长为2;全连接层的神经元数目是128;分类器选择的是SoftMax。分类结果评价表见表6。可以看出,分类的结果并不理想。狼毒草的召回率为1,精度只有0.59,说明模型倾向于把所有草都识别为狼毒草;马蔺草的召回率只有0.3,精度只有0.43,说明模型不能有效识别马蔺草;香青的召回率为0.60,精度为1,说明模型一定程度上可以识别出香青。使用Tensorflow提供的可视化工具考察模型的训练过程,见图8。考察损失函数的下降曲线(图8(a))和精度的上升曲线(图8(b)),可以看出,损失函数/准确率的下降/上升非常快,曲线的变化非常陡峭。在大约1000步时,损失函数已经下降到0,准确率已经上升至1.00。发生这种情况的原因一般是训练样本过少,网络深度过浅,优化器选择不当等导致的过拟合。
基于fine tuning技术的分类结果评价表见表7。可以看出,模型的分类效果非常好,各项指标均为1。表明该模型在测试数据集上能够完全识别出三种草,准确率为100%。考察模型训练过程中损失函数的下降情况如图9。在训练到1000步时,损失函数下降到0.48,之后一直在0.5左右上下波动。这种情况符合正常的训练过程。
4. 结论与展望
本文针对单株植物或小片群落的植物图像识别问题,总结出三种识别方法适用于解决该问题。基于预训练模型的深度卷积神经网络方法同其他方法相比,在识别带标注样本数据集的准确性上,具有显著的优越性。
虽然本文最后实验可以完全识别现有的带标注样本数据集,但仍有很多不足之处需要改进:
1) 带标注植物样本数据库数据量太小,且无季节性变化。这些有赖于实验室之后的建库工作持续进行。

Figure 6. Part of picture library with tagged plant samples. (a): the library of Stellera chamaejasme Linn; (b): the library of Iris ensata Thunb; (c): the library of Anaphalis sinica Hance
图6. 带标注植物样本图片库部分展示。(a):狼毒草库;(b):马蔺草库;(c):香青库
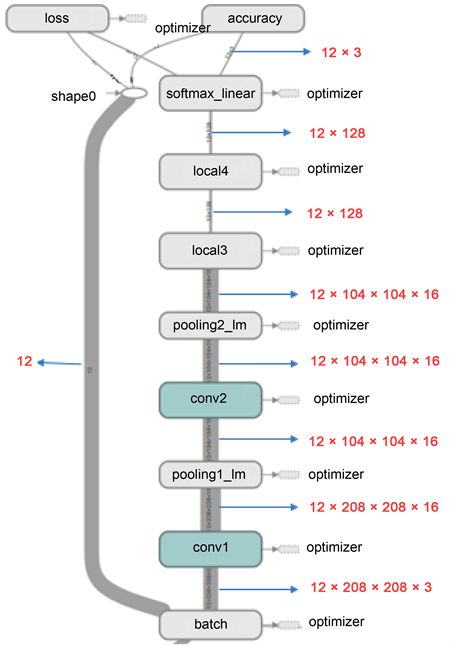
Figure 7. The structure diagram of the convolutional neural network used in this paper
图7. 本文使用的卷积神经网络结构图

Figure 8. Training process visualization using the self-selection network model. (a): loss function descent curve; (b): accuracy rise curve
图8. 使用自选网络模型训练过程可视化。(a):损失函数下降曲线;(b):精度上升曲线
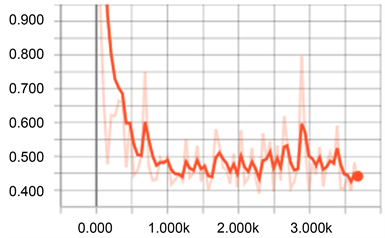
Figure 9. Loss function decline curve in training process of convolution neural network based on fine-tuning technology
图9. 基于fine-tuning技术的卷积神经网络模型训练过程损失函数下降曲线
Table 3. Seven classifier’s K fold cross validation score statistics table
表3. 七种分类器的K折交叉验证得分统计表
Table 4. Global characteristic + random forest classification result evaluation table, number of decision trees = 5
表4. 全局特征 + 随机森林法分类结果评价表,决策树数目 = 5
Table 5. PCA + SVM method classification result evaluation table, extracting principal component vector number N = 30
表5. PCA + SVM方法分类结果评价表提取主成分向量数N = 30
Table 6. Use of self-selected network classification results evaluation table
表6. 使用自选网络分类结果评价表
Table 7. Classification result evaluation table based on fine tuning technology
表7. 基于fine tuning技术的分类结果评价表
2) 选择的网络深度较浅,没有选择合适的优化器。关于CNN的理论知识还要加强学习受硬件条件制约,没有使用更新的RCNN,fast-RCNN技术,只能识别分割好的数据。
基金项目
国家自然科学基金(编号:41571369);青海省科技计划项目(编号:2016-NK-138);科技创新服务能力建设基本科研业务费(科研类) (编号:025185305000/143)。
NOTES
*通讯作者。