1. 引言
图像的自动语义标注是多媒体内容智能管理的重要环节。作为一种解决方案,基于概念分类器的图像自动标注方法被提出来了,其识别的语义标注概念可能包括自然(例如,地平线、倒影和瀑布)或者场景(例如,城市、非洲和港口),它们皆来自于一个语义概念单词本。很多标注方法 [1] 基于一种假设:标注概念是彼此独立无关的。然而,语义概念并非孤立存在。相反地,它们是高度相关的,或者说,在这些语义概念之间存在着语义关联。例如,单概念“树”和“山”往往与“天空”共同出现在图像中,表明它们之间是有强语义依赖的。反过来,三个单概念“海洋”、“桌子”与“沙漠”则没有什么语义依赖关系,它们不太可能同时出现在一副图像中。除此之外,这种语义依赖还可以延伸到场景多概念范围。例如,对于以城市为主题的图像库,一个单概念“城市”与一个场景多概念“街道,房子”很可能频繁地共现在图像中。可以考虑利用这些语义关联去更准确地推断图像的语义标注,尤其是当一副图像的底层视觉特征不足以判断出正确的语义标注的时候。
语义概念及其相互依赖关系可以被组织起来构成一个语义链接网,它由语义节点和带权重边组成。不同于已有的语义网,提出的语义链接网的每一个节点划分为两种类型:语义单概念(如“鲜花”)与场景多概念(如“网球,球场,球手”),它们皆抽取于图像集。每一个场景多概念节点被视为一个整体,即一个整体场景概念,它描绘了一副图像的场景或者某个语义主题。带权重边代表语义概念之间的语义依赖关系,含有较强语义依赖关系的节点边则具有较高的权重。对于上述这两类语义节点,分别使用单概念分类器和多概念分类器去学习它们。为了估算语义边的权重,采用了两个数据资源:全局图像语料库与本地图像语料库。使用这两类语料库去抽取语义是基于如下的考虑。
使用全局语料库可以抽取通用语义,具备一定的准确性,然而这种全局语义的抽取仅仅考虑了全局语料库,其是独立于本地图像库的外来异质语料库,并未完全反映本地图像集的独有特性,这可能会影响图像自动标注的准确度。另一方面,对于带有大单词表
的本地图像语料库,其语义概念ci的分布很有可能是高度不平衡的。假若仅以本地图像语料库为数据源,抽取的局部语义依赖很可能不能反映真实的语义关系,极有可能会导致过度拟合的现象,这会损失图像语义标注的鲁棒性。因此,仅考虑单个数据源的语义抽取方法具有一些局限性,而结合全局语义与局部语义的方法或许能够引起这种局限的弱化。
借助于语义链接网完成图像的语义标注,主要基于这样几个考虑。1) 在包含大单词表的图像库里,语义概念的不平衡性极有可能出现,传统的图像标注方法在频繁概念上性能较好,而在稀疏概念上的表现不尽人意。通过语义链接网技术缓解语义概念的不平衡性问题。2) 当图像视觉特征难以辨认的时候,分类器映射出的语义结果很可能会偏离正确的语义概念。例如,考虑抽象场景概念“城市”,相较于有形概念如“桌子”、“房子”、“路灯”和“街道”,它比较难以被语义概念分类器识别。一副包含有“城市”场景概念的图像,极有可能也出现它的依赖概念如“街道”、“街道,房子”和“房子,路灯”,可以利用这种概念依赖关系来推断图像的语义标注。对于一副图像I,假若发现了这些易识别的依赖概念,则可以增大图像I中存在“城市”标注概念的概率,于是,减少了误判语义概念“城市”的几率。
再考虑两个具有相近视觉外观的语义概念,如“天空”和“海洋”,因为二者具有近似的蓝色形状,概念分类器常常误判,难以分辨它们俩。由于语义概念“树”和“山”常常与“天空”共现于同一幅图像中,因此,可以借助于这种语义依赖去进一步区分辨识正确的语义标注。假如语义概念分类器有很强的视觉证据:图片I含有语义标注“树”和“山”,则I包含“天空”的概率应该大于“海洋”概率。
我们的语义链接网是一种语义数据模型,但又不同于传统的语义模型如本体模型:1) 本体是领域概念、概念属性、属性约束等知识描述模型,其独立于待标注本地图像库且并未完全反映本地图像的特性,所以可能影响图像语义标注的性能。2) 传统的语义模型仅仅考虑单概念节点,而适于标注的场景多概念被忽视了。我们的语义链接网既考虑了传统的单概念节点,也考虑了场景多概念节点。一个多概念节点被看作一个整体参与机器学习。3) 已有的语义数据模型仅考虑了单一语义信息源,而我们的语义链接网结合了全局语义与局部语义,弱化了其局限性。4) 我们的语义链接网可看作是一种特殊的轻量级本体语义模型,它包含两类节点即单概念节点与场景多概念节点以及含权语义边,移除了一些复杂而无用的通用本体特性如推理机制。总之,它是专用于图像标注的轻语义模型。
2. 基于局部语义与全局语义学习的语义链接网
假设
与
分别是含有T个样例的训练图像集与含有S个样例的测试图像集。
表示单词表,包含L个语义概念,每个概念
是一个单概念,例如“stadium”。在训练集A中的每个图像被赋予几个语义单概念ci,而在测试集B中的图像没有标记任何语义标注。每个语义多概念
(例如,“tennis,court,player”)是幂集V中的一个元素,即
或者
,l是Ci的长度。如果l = 1,那么Ci就退化成一个传统的语义单概念ci。
2.1. 语义链接网的构建
语义概念及其相互依赖被组织起来形成一个语义链接网(如图1),可以离线训练,由语义节点与含权边构成。每个语义节点表示为一个语义单概念
或者语义多概念
,Ci被当作一个整体或者一个场景概念。节点之间以语义边连接,表示两概念之间的语义依赖,边权重
可以基于全局语料库与本地语料库学习。自连接概率值设置为1,即
。为避免产生无意义的场景多概念Ci,如:“tennis,waterfall,ship”,在训练集A上通过如下共现规则产生出有语境含义的场景多概念Ci,于是生成一个语义节点集V+:
(1)
(2)
其中
表示所有l个语义概念ci在训练集A中的共现总数,即多概念频率。
用来控制多概念Ci的最大长度(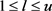 )。假若节点集V+太大,可以调节公式(2)中的共现数v以减小计算开销。于是,语义节点集V+生成了。
)。假若节点集V+太大,可以调节公式(2)中的共现数v以减小计算开销。于是,语义节点集V+生成了。
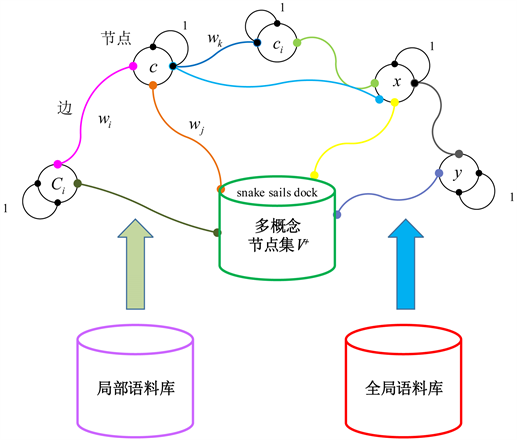
Figure 1. The system framework of semantic link network
图1. 语义链接网的系统框架
语义边用以连接语义节点,边权重表示两概念节点x与y的语义依赖概率p(x|y),其值介于0 (完全不相关)与1 (完全相等)之间。语义依赖值是对称的,所以该语义链接网是无向语义网络。
2.2. 边权重的估算
使用Web图像语料库作为全局语料库,使用图像训练集A作为局部语料库,综合利用(全局) Web图像语料库与(局部)训练图像语料库来计算边权重wi,即概念依赖概率p(c|Ci)。边权重采用如下两个语义度量方法计算。
1) Google距离
在Web级图像语料库上考虑使用Google距离 [2] ,它是一种新的基于信息距离与Kolmogorov复杂性 [3] 的语义相关性度量,且使用了由Google搜索引擎返回的Web点击页面数来计算两语义概念之间的语义距离。给出两个语义概念x与y,例如x = “city”和y = “street, building”,相应的Google距离d(x,y)计算可以参见文献 [2] 。于是,语义依赖概率p(x|y)可以按照公式(3)以d(x,y)的负幂来计算出:
. (3)
可使用任意的全局语料库计算边权重,不失一般性,使用Google图像搜索引擎索引的海量Web数据作为全局语料库,按照公式(3)去估算全局语义依赖概率pG(c|Ci) (即x = c和y = Ci)。
2) 共现距离
在训练图像语料库上考虑使用对称共现距离来计算局部语义依赖概率pL(c|Ci) (即x = c和y = Ci),可以按照如下对称共现度量方法计算:
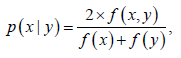 (4)
(4)
该方法描述了概念y与概念x共现的频率,然后被语义概念x与y的总频率归一化。它可以被理解为给定含有标注y的图像I,其包含语义概念x的概率有多大,其值介于0.0和1.0范围之内。最后,如下定义语义依赖概率p(c|Ci):
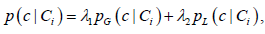 (5)
(5)
其中
和
是待估算的模型参数且服从约束条件:
。该参数可以用来调节全局语义依赖与局部语义依赖的合适比例,语义自依赖概率设置为1,即
。很显然,上述局部语义依赖概率p(c|Ci)是对称的,即
。
3. 基于语义链接网的图像标注方法
IA-SLN考虑了两类线索:语义线索和视觉线索,包含三个步骤:标注上下文生成、语义映射和语义标注增强方法。为了估算语义概念c与未标注图像I的相关性r(c,I),图中I被表示为低层视觉特征和标注上下文R(c)。集合R(c)中的每一个语义节点Ci被表示为一个圆圈(如图1),它可以是单概念节点或者场景多概念节点。概念分类器执行从未标注图像I到语义概念Ci的映射,并且输出图像I含有语义概念Ci的带权视觉证据p(Ci|I)。最后由概念标注增强方法方法精炼语义标注。
3.1. 标注上下文生成
给定任意标注概念
,从语义链接网中按照边权重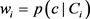 选择K个最近邻语义节点Ci以产生语义标注上下文
。其中每个元素
可以是一个单概念或者一个场景多概念,很显然,因为
,所以每个语义概念c与其本身是相关的(即
)。
选择K个最近邻语义节点Ci以产生语义标注上下文
。其中每个元素
可以是一个单概念或者一个场景多概念,很显然,因为
,所以每个语义概念c与其本身是相关的(即
)。
为了保持概率的属性,标注上下文R(c)中的所有元素值p(c|Ci)应该执行如下所示的规范化操作,使得元素和为1。
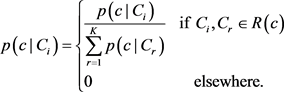 (6)
(6)
3.2. 语义标注映射
标注映射的任务是计算标注概念c与测试图像I的相关性r(c,I)。考虑由K个标注上下文元素
共同参与相关性计算,获得如下相关性估值r(c,I):
(7)
该后验概率p(Ci|I)指出了图像I与语义多概念Ci的相关性,它可以视为图像I包含有语义概念c的视觉证据vi,而两语义概念c 和Ci之间的概念依赖p(c|Ci)可视为视觉证据vi的权重wi,高依赖关系的语义概念具有较高权重。对于给定的标注概念
(例如“city”),假若有很强的视觉证据p(Ci|I)表明I包含有该概念c及其多个强依赖概念
(例如“street,building”和“building,light”等),则p(c|Ci) p(Ci|I)项变得很大,因此相关性r(c,I)也变大。反之,则r(c,I)会变得很小。
概率p(Ci|I)可以通过分类器来估算。由于近年来卷积神经网络在图像分类领域取得了巨大成功 [4] [5] ,因此IA-SLN选用了一种高效的卷积神经网络DenseNet [5] 。假若
(即传统的单概念ci),使用传统的单概念分类器训练方法:把标记有单概念ci的样例作为正例,而剩余图像样例作为反例。假若
(即一个语义场景多概念Ci),正例集S+(Ci)与反例集S−(Ci)可以如下方法构建:
(8)
其中As(Ii)是训练图像
的标注概念集。基于上述两个集合S+(Ci)和S−(Ci),训练出分类器作为多概念场景检测器。
为了找到最合适的模型参数值
,在训练数据上最大化概念预测值的对数似然函数。按照公式(3)与(5),相关性估值r(c,I)可以表达为如下形式:
(9)
(10)
IA-SLN使用
表示概念c不存在/存在于训练图像I中,因此概念c的预测值p(yci)可以如下形式给出:
(11)
于是,语义概念c的对数似然函数改写为如下形式:
(12)
其中nci是代价因子,它考虑了每一个概念c的正例数N+与反例数N−的不平衡性。如果yci = 1则设定
,否则设定
。将公式(10)和(11)带入(12),得到了下列对数似然函数:
(13)
其中
。对于每个对数似然函数
分别采用梯度下降法 [6] 进行最大化求解。
3.3. 标注增强及算法
为了获得图像I的最佳语义标注c,需要对所有概念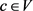 的语义相关性分数r(c,I)从大到小排序,从中选择出最好的w个语义概念c作为候选标注集Y。此外,一个图像的标注概念数量w并非是固定值,换句话说,一些图像的语义标注概念数可能小于w个。由于候选概念集Y可能包含有不相关的噪音标签,为了提升标注效果,IA-SLN基于阈值ti过滤掉一些噪音候选标签。给出图像I,选择最高α%个候选概念相关分数的算术均值作为该标注阈值ti。因为单词表中相关的概念标注总是远远少于不相关的语义概念,所以α被赋予一个较小的值,例如5,6或者7。
的语义相关性分数r(c,I)从大到小排序,从中选择出最好的w个语义概念c作为候选标注集Y。此外,一个图像的标注概念数量w并非是固定值,换句话说,一些图像的语义标注概念数可能小于w个。由于候选概念集Y可能包含有不相关的噪音标签,为了提升标注效果,IA-SLN基于阈值ti过滤掉一些噪音候选标签。给出图像I,选择最高α%个候选概念相关分数的算术均值作为该标注阈值ti。因为单词表中相关的概念标注总是远远少于不相关的语义概念,所以α被赋予一个较小的值,例如5,6或者7。
基于上述方法,如下给出IA-SLN自动图像标注算法。
输入:训练集A,标注字典V,测试图像
;
输出:标注结果集
。
1 构建多概念节点集V+;
2 计算任意两节点之间的边权重wi,生成语义链接网;
3 for each
4 构建标注上下文R(c);
5 映射语义标注,获得相关性估值r(c,I);
6 end for
7 执行标注增强方法;
8 返回标注结果集O。
4. 实验和评价
4.1. 数据集
IAPR数据集 [7] 包含有19,627副自然风景图像,包括人物、动物、城市、地标以及现代生活的方方面面,其语义标注更接近真实场景,每幅图像含有1~23个语义标注,单词表V含有291个语义概念(即
)。IAPR图像集被随机分割为两部分:17,665副图像作为带标注的训练集且余下图像作为未标注测试集。
4.2. 实验结果与分析
考虑使用四个标准性能指标来评估图像标注方法,即文献 [7] 使用的平均准确率、平均召回率、F1分数以及N+值,指标值越高表示标注性能越好。测试图像I的最相关w个语义概念的选择,受到了已有经典工作 [7] 的启发。按照这个思路,初步考虑w的近似值是5或者6。由于在单词表中,相关标注概念数远远小于不相关的概念数,所以考虑α赋予一个较小的值,例如5,6或者7。关于参数(w,α)的选择也得到交叉验证实验的证实。随机地把整个训练集划分为10份,一份做验证集而剩余9份做训练集,基于该验证集划分,在参数w = [5, 6]与α = [3, 4, 5, 6, 7, 8]上做了一组交叉验证实验。设置w = 6,α = 7,因为它们表现出最好的F1性能。为确定语义标注上下文R(c)的大小K,即语义链接网节点c的近邻节点数,再次执行10-路交叉验证实验。发现当K值到达20时获得最佳的F1分数,因此设置K = 20。

Table 1. Performance comparisons of automatic image annotation
表1. 自动图像标注性能比较
表1列出了与最新图像标注方法的对比实验结果。提出的IA-SLN方法超越了所有比较方法,相较于两种较好的已有标注方法即CNN-MLL和CNN-LDA方法,IA-SLN方法分别获得了12.2%或25.0%,4.8%或10.0%,8.6%或16.4%的性能提升(平均准确率,平均召回率,F1值)。IA-SLN不仅考虑了单概念,而且考虑了场景多概念以及结合全局语义与局部语义的边权重学习。全局语义侧重于语义概念的通用属性,而局部语义侧重于本地特定的图像属性,这两种类型的语义具有一定的互补性,因此,它们的结合可以较好地提高图像语义标注的效果。