1. 引言
文本分类是自然语言处理领域的核心问题之一,也是大数据时代高效获取和处理数据的基础,使用范围非常广泛。近几年来,随着计算能力的提升,以及2006年Hinton [1] 等人提出了深度学习的概念以来,文本分类迎来了新一轮的技术进步。在图形计算单元(gpu)以及并行计算技术的支持下,研究者可以更轻易地训练拥有更深、更多参数的模型,深度学习开始被广泛应用于文本分类研究与应用中,如Yoonkim [2] 首次将卷积神经网络(CNN)应用在文本分类任务上,Liu等人 [3] 提出的基于循环神经网络(RNN)的文本分类方法,Joulin等人 [4] 提出的Fasttest模型,以及Szegedy等人 [5] 提出的Inception结构,都在文本分类任务中取得了优秀的成果。
但是随着互联网技术的发展,传统深度学习分类模型在面对文本类型越来越丰富的网络文本时,都存在着泛化性较差的问题,比如将处理新闻分类任务的模型用来处理商品评论分类或其他差别较大的其他文本时,分类准确率就会大幅降低,需要调整模型参数并再次训练。
针对这个问题,2018年华盛顿大学提出了预训练模型ELMO [6] [7],使用多层双向长短时记忆网络(multi-layer bilstm)对语句建模,并通过下一个词预测训练任务构建通用词向量表达。这种通过预训练的语言模型,能直接使用得到的词向量处理自然语言处理任务,不仅拥有很强的特征提取和学习能力,同时能极大提高文本处理的泛化性。实验表明ELMO模型在6个自然语言处理任务上取得了领先成绩,将结果平均提高了两个百分点。但不久之后,Radford等人 [8] 提出了预训练模型OpenAI GPT,使用Transformer [9] 模型中的解码器(Decoder)来代替Elmo中的双向长短时记忆网络,在同样使用下一个词预测的训练任务的情况下,在12个自然语言处理任务中刷新了其中9个任务的最好成绩。
但Elmo与GPT都受限于下一词预测的单向限制问题 [10],导致模型无法准确预测部分词语 [11]。针对这个问题谷歌实验室提出了预训练模型BERT [12],使用全新预测任务遮蔽语言模型 [13] [14] (MLM masked language model)来解决单向限制的问题。同时使用不同的Transformer编码器(Encoder)部分,使模型的参数量比GPT少4倍左右。通过大量实验,BERT模型再次刷新了11个自然语言处理任务上的最好成绩,是目前预训练方法中最优秀的模型。自此之后许多研究者开始着手于BERT模型的研究,如Liu等人 [15] 将预训练的BERT模型和多任务学习进行结合,以求获取更好的效果。Sun等人 [16] 通过修改模型的输入处理,将单句分类问题改造成BERT更擅长的双句分类问题进行处理。Sun等 [17] 着重研究了BERT在多个文本分类任务上的表现,详细分析了BERT的特点与优势。
然而,本文发现BERT模型在处理中文文本时,由于遮蔽语言模型只会遮蔽并预测单个的中文字符,而不是完整的中文单词,且输入模型的向量中,缺少中文单词位置信息的原因,导致模型构建的中文词向量表示差,分类准确率不如英语等其他语言。为了解决BERT处理中文时存在的不足,本文提出了一种基于BERT的子词级中文文本分类方法。在遮蔽语言模型中,通过子词级的文本表达,和独特的子词级遮蔽方法,实现了对完整中文单词的遮蔽。同时修改了BERT模型的输入处理,加入中文单词位置嵌入,弥补了中文单词位置的缺失。实验证明,相较于原始BERT模型,本文提出的方法在面对中文时,拥有更好的词向量表达能力与分类准确率。
2. BERT相关理论
BERT模型的全称是基于预训练的深度双向Transformer语言模型(Bidirectional Encoder Representations from Transformers),作为一种预训练模型,不同于卷积神经网络与循环神经网络,该模型使用Transformer模型的编码器部分作为模型的基础。得益于Transformer编码器的强大能力,BERT模型可以增加到非常深的深度,充分发掘深度神经网络模型的特性,提升模型准确率。
2.1. BERT模型的输入处理
BERT在设计之初就是为了构建出一个通用的语言模型,所以BERT在输入处理上充分考虑了各式各样任务的需求。BERT模型除了与Transformer一样在词向量嵌入(Token Embedding)的基础上添加位置嵌入(Position Embedding)之外,为了处理一些涉及句子对(Sentence Pair)的问题,还添加了句子位置嵌入(Segment Embedding)。如图1所示:
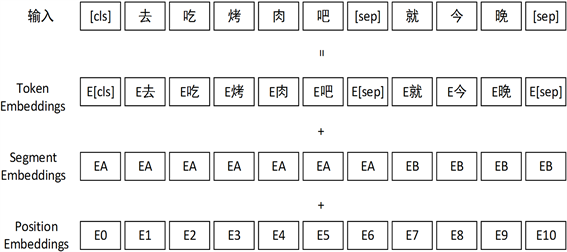
Figure 1. BERT model input processing
图1. BERT模型输入处理
由图1可知,每一个文本序列的首位添加了一个特殊标记[cls],不同句子之间也添加了一个特殊标记[sep]。[cls]标记是最终输出时整个句子或句子对的特征表征,[sep]标记是句子之间的界线。
2.2. 遮蔽语言模型
遮蔽语言模型是BERT模型中使用的全新预测任务。与传统预测任务的词预测不同,该预测任务通过完全遮蔽的输入文本中的部分单词,使得预测被遮蔽单词时能充分考虑上下文信息,以一种更符合人类语言习惯的过程来学习表达词向量。在遮蔽语言模型中,为了获得更好的训练效果,会进行以下两步操作:
第一步为遮蔽区域的选择,在BERT中模型会随机选择15%的单词作为遮蔽区域。保证训练的有效性。
第二步为遮蔽方式的选择,在BERT中,为了解决遮蔽语言模型在完全遮蔽单词后,被遮蔽的单词将无法被下游任务感知,从而导致模型预处理阶段与微调阶段文本不统一的问题,在训练过程中对遮蔽词会选择以下三种遮蔽方式:
a) 遮蔽词在训练中80%的时间会被特殊记号[mask]代替。如图2所示:
b) 而在训练中10%的时间会被词典中的一个随机词代替。如图3所示:

Figure 3. The replacement of BERT model
图3. BERT模型的替换
c) 在剩下的10%的时间里遮蔽词会保持不变。如图4所示:
2.3. BERT模型的分类任务
BERT模型不同于卷积或循环等传统分类模型,该模型会在分类之前,先在大语料环境进行预训练。通过预训练后的BERT模型虽然可以直接用来分类,但是往往准确率较差,需要在特定任务的数据集上进行进一步的预训练,在该阶段,模型会在原先预训练的基础上使用目标数据再次进行如遮蔽语言模型或下一句预测任务,使自身的参数适用于目标数据,这相当于将模型从一般领域到目标领域进行了一次迁移学习。最后通过对两次预训练后的模型进行分类效果的精加工(Fine-tuning),也就是微调训练后输出分类结果。BERT模型分类流程如图5所示:
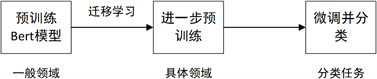
Figure 5. BERT model training process
图5. BERT模型训练流程
得益于预训练阶段后优秀的词向量表达与模型参数,模型能轻易地捕捉语句的深层抽象特征,所以模型微调阶段大多只是在训练输出层的参数和略微调整预训练模型而已,这保证了微调阶段的收敛速度和分类准确率。
3. 基于BERT模型的子词级文本分类方法
3.1. 中文子词级文本表示
本文使用的子词级粒度的文本表示最早应用于英文文本翻译任务中。通过词切片 [18] (Word Piece)的方法将英文单词再次切分,如“The highest mountain”这句话进行子词级表示后,结果如图6所示。虽然子词级的粒度小于词级,但是仍大于字符级,这就保证了子词级不会像字符级一样丢失文本语义信息,同时也解决了词级所需词汇库过大的问题。
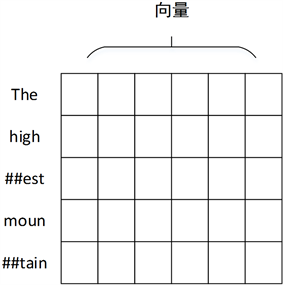
Figure 6. English subword level representation
图6. 英文子词级表示
而在中文使用子词级时,与英文的操作不同。在对文本进行分词处理后,会先区分单词中的词首和非词首字符,对所有非词首字符添加“##”号,并生成一行标记序列seg_labels,使用0来标记所有没添加“##”号的字符,使用1来标记添加了“##”号的字符,使用−1来标记其余标点符号与占位符等。该标记序列不仅区分了单词的界线,同时也标明了不需要处理的标点符号等,其具体操作如图7所示:
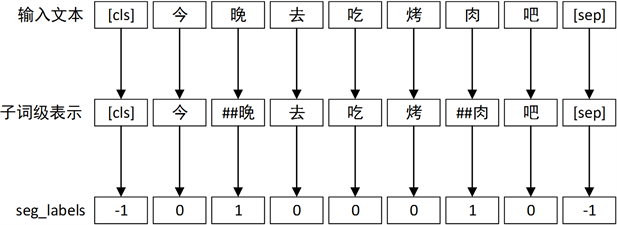
Figure 7. BERT model subword level text representation
图7. BERT模型子词级文本表示
添加了“##”号的字符拥有与原字符不同的数字或矢量,这样在仅增加一倍的词汇库大小的情况下,能够保留中文单词的语义信息。同时由于中文子词级表示中,词首字符就像是单词的主键一样,通过词首能有效减少对中文单词的操作流程和难度,对于需要提出遮蔽完整中文单词,以及中文位置的标注方法的本文来说是必不可少的。所以本文模型选择子词级的文本表示粒度。
3.2. 子词级遮蔽方法
在BERT模型中,由于英文与中文语言结构的差异,遮蔽语言模型在中文中选择遮蔽区域时,只会选择中文的字符,而不是完整的中文单词,为了解决这个问题,本文提出一种使用子词级遮蔽方法的遮蔽语言模型。对章节2.2中提到的遮蔽语言模型两个步骤做出以下修改。
第一步遮蔽区域的选择中,在模型随机选用15%的遮蔽区域前,使用章节3.1中的得到的标记序列seg_labels,按照词首决定整个单词是否遮蔽的原则,重新整合中文字符关系,使待遮蔽区域可以覆盖整个中文单词,同时排除占位符与标点符号。该方法步骤的伪代码如表1所示:

Table 1. Subword level masking area selection code
表1. 子词级遮蔽区域选择代码
在第二步遮蔽方式的选择中,按照非词首的遮蔽方式是否同词首一致的区别,子词级遮蔽方法可以继续细分为两种:
第一种子词级随机遮蔽方法中,一个单词中每个字符是否会被遮蔽服从词首,但是遮蔽方式都是单独判断。在某一个时刻可能都不相同,如同随机一样,如图8所示:

Figure 8. Subword level random masking method
图8. 子词级随机遮蔽方法
在第二种子词级遵从词首的遮蔽方法中,一个单词中非词首字符不再单独进行遮蔽方式的判断,而是同判断是否遮蔽时一样与词首保持一致。如图9所示:
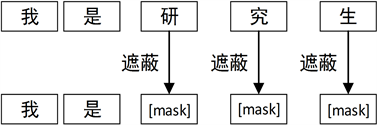
Figure 9. The method of concealing the first part of a subword
图9. 子词级遵从词首遮蔽方法
这两种子词级遮蔽方法都可以实现对整个单词的遮蔽操作,但哪个方法在真实数据中词向量表达效果更好,本文将在下文进行对比实验。
3.3. 中文单词位置嵌入
使在文本分类中大多数都是单句分类任务,不需要考虑句子位置的信息。所以本文模型的输入处理放弃使用句子位置嵌入(Segment Embedding)。同时由于BERT中原本用来标记单词位置的位置嵌入(Position Embedding)在面对中文时,标记的只是中文字符的位置,缺失了单词的位置信息。所以本文提出一种子词级的中文单词位置嵌入(Word Position Embeddings),使用章节3.1中得到的seg_labels序列标记的词首和非词首信息,对于不同字符:
a) 遇到于词首与占位符,位置计数加一。
b) 遇到非词首时,位置计数与其对应词首一致。
如图10所示:
并将模型的输入处理改为词向量嵌入(Token Embedding),位置嵌入(Position Embedding)和单词嵌入(Word Position Embeddings)的总和,如图11所示:
4. 实验与分析
本文所有实验都基于NVIDIA tesla V100 gpu与深度学习框架PaddelPaddel来实现,所使用的语言为python,并开启gpu加速,加速版本为CUDA9.0、cudnn7.3。
4.1. 实验数据集
本文使用来自网络的梨视频视频标题数据集、网易网络新闻数据集、京东商品评论数据集。三个数据集包含网络中常见文本类型,都由本文使用爬虫程序从网络获取。数据集具体情况如下所示:
a) 梨视频视频标题数据集:该数据集由本文收集整理,数据由爬虫软件从短视频网站获取,包含音乐、二次元、搞笑等共9个分区的共2万条文本数据。
b) 网易网络新闻数据集:该数据集也是由本文收集整理,数据来源自网易新闻频道,包含娱乐、体育、健康等8个频道的共1万5千条文本数据。
c) 京东商品评论数据集:该数据集由本文收集整理,数据来源于京东手机、笔记本电脑、图书、食品、家居5个分类下的商品评论信息,按好评、中评、差评三个评价等级收集,共7万7千条文本数据。
4.2. 本文模型参数介绍
该模型的部分参数如表2所示:
Table 2. Model parameters and super parameters
表2. 模型参数与超参
在预训练阶段,训练将最多进行3万个step,每10个step输出一次训练结果,每100个step在验证集上进行一次验证,每1万个step保存一次模型。
在模型微调阶段,为了取得更好的训练效果,将学习速率减为5e−5,同时为了减少计算资源压力,将模型每批处理大小减少为24。在该阶段,训练最大进行10个epoch,每10个step将输出一次训练结果,每100个step在验证集与测试集上进行一次验证,每1000个step保存一次模型。为了保证模型训练时每个epoch的模型保持不变,固定模型的随机种子(random_seed)。模型最后分类标签数(num_labels),与模型输入的数据集相关。
4.3. 评价指标
在衡量不同方法的词向量表达能力的实验中,本文采用文本置信度(Perplexity,ppl)来衡量好坏,在语言模型中ppl值可以认为是平均分支系数(Average branch factor),即预测下一个词时可以有多少种选择,如ppl值为60,可以直观地理解为,在模型生成一句话时下一个词有60个合理选择,可选词数越少,一般认为模型越准确。所以ppl值越小,词向量模型越好。其中ppl值的计算方法如公式1所示:
(1)
在衡量文本分类准确率的对比试验中,本文采用文本分类的准确率(accuracy)来衡量好坏,准确率是所有样本中分类正确样本所占的比例。
而在衡量文本预测效果的好坏方面,由于缺少相关评价标准,所以本文直接列出原始文本与预测文本,通过对比文本流畅度与预测词的准确性来衡量预测的效果。
最后在对比处理速度时,采用更为直观的每秒处理step数来表示,单位为step/s。
4.4. 评实验结果对比
4.4.1. 文本词向量表达能力对比实验
本章将从文本ppl值、真实数据的预测效果,和模型处理速度,三个方面来进行文本词向量表达能力的对比实验。在文本ppl值的对比实验中,为了使ppl值的对比更为明显,本文使用文本长度较长的网易网络新闻数据集作为实验数据集。同时为了充分对比本文方法的有效性,分别实现了以下4种BERT模型,如表3所示:
每个模型将在预训练阶段对大小为10,000与1500的数据进行训练,每个数据集训练三次,共9万个step,结果取训练完成后ppl的平均值。实验结果如表4所示:
Table 4. Comparison of ppl values
表4. ppl值对比实验结果
由上表结果可以看出,在加入中文单词位置后,word_char_BERT的ppl值较未使用的char_BERT有了明显的下降。而使用了本文提出的子词级遮蔽方法的word_random_BERT和word_allmask_BERT的ppl值相较于未使用该方法的word_char_BERT有大幅的下降。最后在两种子词级遮蔽方法中,使用子词级遵从词首的遮蔽方法的word_allmask_BERT的ppl值,相较于使用子词级随机遮蔽方法的word_random_BERT更低。由上述结果可以得到,子词级遮蔽方法和中文单词位置嵌入都能有效降低文本ppl,提高词向量表达。
但是单独对比ppl值无法体现本文提出方法在具体任务中的具体提升效果,所以本文在ppl值对比实验的基础上进行了真实数据上的遮蔽预测效果的对比实验,在该实验中使用word_char_BERT、word_random_BERT、word_allmask_BERT三个模型,在京东评论和网易新闻两个数据集中分别随机提取一句话,作为实验的预测文本。实验的方法为先遮蔽预测文本中的部分单词,然后观察遮蔽词的预测效果。实验数据与结果如图12和表5所示:
由表4可以看到,没使用子词级遮蔽方法的word_char_BERT模型的预测效果较差,不仅没有正确预测成都这个地名,同时也未正确预测评论文本。在使用子词级随机遮蔽方法的word_random_BERT中,对地名成都的预测准确,但在对评论文本的预测中,预测词与原词语义相反,由此构建的词向量在情感分析任务中会产生一定的不良影响。最后在使用了子词级遵从词首遮蔽方法的word_allmask_BERT中,不仅地名成都准确预测,同时对评论遮蔽词的预测结果也与原语义相同,在三种遮蔽方法中拥有最好的预测结果。
而在处理速度方面,由于本文提出的方法修改了BERT模型处理中文的粒度,同时额外添加了中文单词的位置信息,所以必然会对处理速度造成一定的影响。为了验证对速度的影响,本文将对比使用额外单词位置和子词级遮蔽方法前后的模型处理速度,使用的实验模型为char_BERT、word_char_BERT和word_allmask_BERT,使用的评价标准为章节4.3中提到的每秒处理step数,实验结果如图13所示。
由图13可以看出,虽然使用子词级遮蔽方法和中文单词位置后模型处理速度有略微的下降,但是综合前面两个词向量对比实验可以看到,加入了单词位置嵌入的模型拥有更好的词向量表达能力,使用子词级遮蔽方法后模型拥有更好的词向量表达能力与预测能力,相较于使用这两种方法带来的词向量表达效果提升,处理速度的略微下降在可以接受的范围内。而在两种子词级遮蔽方法的比较中,子词级遵从词首的方法拥有更好的词向量表达与预测的能力,所以在后续分类效果的对比中,本文将使用该方法。
4.4.2. 文本分类效果对比实验
本文主要的研究目标是中文网络文本的分类,所以为了验证本文提出的文本分类方法在文本分类任务中的有效性,将上文中拥有最好实验结果的BERT模型word_allmask_BERT,同基础BERT模型、CNN模型、RNN模型、Fasttest模型以及Inception-CharFcn [19] 模型,在梨视频视频标题数据集、网易网络新闻数据集、京东商品评论数据集,三个数据集上进行分类效果的对比实验,评价指标选用章节4.3中提到的准确率,结果将按百分比(%)表示。实验结果如表6所示:
Table 6. Classification accuracy comparison
表6. 分类准确率对比
由上列实验结果可以看到,使用了中文单词位置嵌入和子词级遮蔽方法的word_allmask_BERT模型在三个数据集上都拥有最高的分类准确率,并且分类效果明显优于原始BERT模型,证明了本文提出的子词级文本分类方法对BERT模型中文文本分类准确率的提升效果。
5. 结束语
本文就BERT模型对中文的文本分类任务进行了研究,提出的子词级文本分类方法能有效解决BERT模型面对中文时的不足,同时增加中文文本分类的准确率。但是在面对越来越多的网络文本时,BERT模型无法处理这类文本中容易出现的错别字问题,导致分类准确率下降。所以在下一步中,将尝试在微调阶段使用遮蔽语言模型中的遮蔽预测方法进行文本纠错。
基金项目
四川省科技厅重点项目(2017GZ0331)。