1. 引言
随着计算机科学的迅猛发展,大数据时代来临,互联网数据爆炸式的增长,这些数据中蕴含着大量有价值的信息,如何对其进行提取和表达引起了大量学者的关注。知识图谱作为一个能对其进行有效的表达和组织的工具应运而生。知识图谱这一概念,由2012年Google公司所提出,用于Google浏览器的智能搜索引擎。自此以后,知识图谱得到了众多学者的关注和青睐,在许多领域得到了广泛的应用。然而,知识图谱大多都是由人工或半自动的方法构建,导致了知识图谱的不完整。据2014年统计,世界上最大的知识库之一freebase,存在着71%的人没有确切的出生日期,75%的人没有国籍信息 [1]。知识图谱的不完整制约着其下游应用的发展,如何对现有的知识图谱进行补全,扩大其规模成为人们迫切需要解决的问题之一,因此知识推理成为了人们关注和研究的重点之一。
Schlichtkrull等人 [2] 提出了关系图卷积神经网络模型(R-GCN)从微观上建模星形结构以建模知识图谱。R-GCN网络将目标实体与知识图谱中的邻居实体进行卷积学习,输入当前实体的相邻关系信息,包括关系类型、关系的方向以及实体自循环的信息,输出目标实体的隐性特征向量表示,然后通过节点损失函数进行实体分类。该模型充分地利用了知识图谱的关系信息,却忽略了实体的简明描述中蕴含了丰富的语义信息。本文提出了结合实体描述和关系图卷积神经网络的模型(DR-GCN),并将其应用于知识推理的实体分类任务。实验结果表明,该模型有效地提高了实体分类的准确度,验证了该方法的有效性。
2. 相关研究
知识推理是指利用知识图谱中已有的知识,通过某些方法,推理出新的知识或识别知识图谱中错误的知识 [3]。即已知知识图谱三元组中的任意两个元素,采用某种方法,推理出三元组中所缺失的另外一个元素或识别出另外一个元素的正确与否。例如,事实三元组(美国,首都,?),由这个三元组我们可以知道美国和首都这两个元素,不难推断出三元组的另外一个元素为华盛顿。知识推理根据推理任务的类型可分为:链路预测、实体预测、关系预测、属性预测、实体分类等。本文研究的主要内容为实体分类。
知识推理根据其推理方法的不同可分为基于规则的推理、基于分布式表示的推理、基于神经网络的推理以及混合推理 [4]。传统的基于规则的推理方法,虽然它推理的准确率非常高,但它需要知道全面的推理规则和本体约束,而在现实中很少能达成这一条件。基于神经网络的推理方法具有很强的学习能力、推理能力和泛化能力,既能从大量的文本语料中学习其特性,解决知识图谱中数据规模庞大的问题,也能对知识图谱中的事实三元组进行直接建模,解决了知识推理中的计算难度大的问题,还能通过巧妙的设计神经网络,使其在某种程度上模拟人脑进行知识推理。
基于神经网络的知识推理的研究最早始于Socher等人 [5] 提出的一种神经张量网络模型(NTN),为了能够有效了提取各个实体之间存在的潜在关系,该模型合理的使用了双线性张量层取代了常用的标准线性神经网络层。随后出现了各种各样的知识推理神经网络模型。例如,对于前人的知识推理研究一直没有用到的实体描述信息,Xie等人 [6] 提出了一个利用CBOW或卷积神经网络模型对知识图谱中的实体进行学习表示的基于实体描述的表示学习模型(DKRL),DKRL模型能够有效的提取知识图谱中实体的描述信息,利用实体描述进行实体和关系预测任务。受多候选项排名问题的启发,Shi等人 [7] 提出了一个投影嵌入的共享变量的神经网络模型(ProjE),该模型通过使用低维图嵌入学习知识图谱中的实体和关系的联合嵌入,将实体预测视为排序问题,在其输出结果中取最高得分候选项作为实体预测的结果。Tay等人 [8] 认为多任务的交叉学习表示能有有效提高非离散属性预测的准确性,提出了多任务神经网络模型(MT-KGNN),该模型能够有效的利用两个任务中的实体、关系和属性等信息进行非离散属性预测。Shi等人 [9] 提出了一个开放世界知识图谱补全的ConMask模型,该模型能够学习实体名称和实体描述等信息,将知识图谱外部的实体无缝的连接有现有的知识图谱内部,从而实现知识图谱的动态补全。Lukovnikov等人 [10] 认为对知识图谱中的主谓语进行排序学习有利于匹配给定问题的相似事情,提出了一个整体神经匹配模型(HNM),有效的提高了端到端智能问答的效率。Shen等人 [11] 提出了隐形推理网模型(IRN),该模型通过巧妙的设计神经网络,使其在某种程度上模拟人脑进行知识推理。Graves等人 [12] 提出了一个DNC模型,该模型通过合理的设计和使用辅助神经单元,模拟人脑中对记忆的增、改、删过程。Schlichtkrull等人 [2] 从知识图谱的内部结构角度出发,提出了关系图卷积神经网络模型(R-GCN),该模型充分的利用了知识图谱中的关系信息进行知识推理,其中包括了关系类型、关系方向、实体自循环等信息。Dan等人 [13] 从关系图卷积神经网络的基础上出发,加入了内部关系图注意力机制,提出了关系图注意力卷积神经网络模型(R-GAT),该模型进一步的提升了实验的准确率。
3. 模型设计与分析
3.1. DR-GCN模型
GCNs模型由Duvenaud等人 [14] 和Kipf等人 [15] 所提出,我们的模型作为GCN模型的一个扩展,是根据知识图谱的内部结构所设计的一类型神经网络。GCN通过知识图谱的局部邻域关系信息进行学习表示,从而扩展成完整的知识图谱。这一类型的神经网络模型,如GCN,可以视为是Gilmer等人 [16] 提出的简单可微消息传递框架的特殊情况。
(1)
其中,
是神经网络第l层节点
的隐藏状态,
是表示该层的维数,
表示函数中传入的消息被累计并通过
元素激活函数传递,例如
。
表示节点
的传入消息集,通常选择与传入边集相同。
函数通常被选为(消息指定的)类似神经网络的函数,或者简单地选为Kipf等人 [15] 提出的带权矩阵W的线性变换
。
这种类型的转换在知识图谱局部结构化邻域信息的学习特征表示方面非常出色,并且给Duvenaud等人 [14] 提出的图形分类和Kipf等人 [15] 提出的基于图形的半监督学习等带来了显著的提高,在图形领域作出了重大的贡献。2018年,Schlichtkrull等人 [2] 根据知识图谱局部结构化邻域关系信息,对此进一步改进,提出了关系图卷积神经网络模型,并将其模型传播方式定义为:
(2)
其中
表示在关系
下节点i的邻域索引集,r是可以预先学习或选择的问题特定的标准化常数,例如
。
受这些模型结构的启发,我们引入了实体描述这一信息,我们把该模型称为DR-GCN模型,并定义了以下简单的传播模型,用于计算知识图谱局部结构中实体
的前向传递更新:
(3)
其中
表示在节点i的邻域索引集,关系
下第j个节点的实体描述。
神经网络层的更新通过公式(3)对知识图谱中的每个节点进行并行计算。在实践中,式(3)可以通过使用稀疏矩阵相乘的方法实现。该DR-GCN模型利用了知识图谱局部结构化邻域的关系信息和实体描述,图1描述了DR-GCN模型中计算单个节点更新的过程。
如图1所示,收集来自目标节点(红色)相邻的节点(蓝色)的激活,然后分别对其中的关系类型、关系方向、实体自循环和实体描述进行类型转换,转换的结果(绿色)再以归一化的方式累加总和并通过激活函数(ReLU)传递更新。其中,每个节点的更新和参数的共享可以在整个图中进行并行计算。
3.2. 正则化
我们注意到,将式(3)应用到大规模知识图谱的时候,出现参数数量随着知识图谱中关系数量的增长而呈指数型增长的问题。
为了解决这个问题,我们效仿了Schlichtkrull等人 [2] 的做法,采用了偏置分解的方法来调整DR-GCN的权重。通过偏置分解,每个 定义如下:
定义如下:
(4)
即
通过偏置分解为
与系数
的线性组合。其中,
为基础系数,
为基础矩阵。偏置分解式(4)可以看作是不同关系类型之间有效权重共享的一种形式,偏置分解有效的减少了大规模关系数据中所需要学习的参数数量。
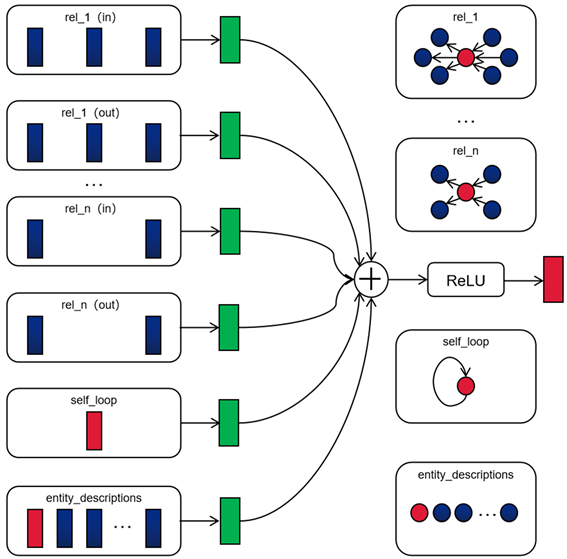
Figure 1. Update process of single graph node/entity(red) in DR-GCN model
图1. DR-GCN模型中单个图节点/实体(红色)的更新过程
3.3. 实体分类
通过堆叠(3)式的神经网络层,在输出层上使用softmax( )激活函数,组成DR-GCN模型用于实体分类实验。在DR-GCN模型中,我们将所有标记节点上的交叉熵损失将至最低:
(5)
其中,Y是具有标签的节点索引集,是第i个标签节点的网络输出的第k个条目,表示其各种的基本事实标签。在实践中,我们使用梯度下降技术训练模型。我们的实体分类模型示意图如图2所示。
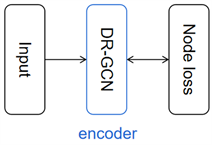
Figure 2. Depiction of a DR-GCN model for entity classification with a per-node loss function
图2. 用每个节点损失函数描述实体分类的DR-GCN模型
4. 实验结果分析
4.1. 数据集
我们将用Ristoski等人 [17] 提出的AIFB、MUTAG和BGS三个数据集对基线中的各个模型进行评估。在每个数据集中,实体分类的目标可以表示为节点的一组实体属性。数据集的各种指标书记统计见表1。关于数据集更详细的描述,可以参考Ristoski等人 [17] 的文献。

Table 1. Number of entities, relations, edges and classes along with the number of labeled entities for each of the datasets
表1. 每个数据集中的实体、关系、边和标记的实体以及类的数量
4.2. 实验设置
作为我们实验的基线,我们比较了来自Ristoski等人 [18] 提出的RDF2Vec嵌入、Vries等人 [19] 提出的Weisfeilaer-Lehman 内核模型WL和Schlichtkrull等人 [2] 提出的关系图卷积神经网络模型R-GCN,以及Dan等人 [13] 提出的关系图注意力卷积神经网络模型R-GAT。RDF2Vec提取标记图上的行走,然后使用Mikolov等人 [20] 提出的Skipgram模型进行处理,生成实体嵌入,用于后续的分类。R-GCN模型通过对知识图谱中的局部结构化邻域关系信息进行卷积学习,输入目标实体的相邻关系信息,其中包括关系类型、关系方向和实体自循环的信息,在输出层上使用softmax( )激活函数进行实体分类。R-GAT在关系图卷积神经网络的基础上出发,加入了内部关系图注意力机制。
对于数据集AIFB、MUTAG和BGS的训练,我们选择为具有16个隐层的DR-GCN模型,学习率设置为0.01,归一化常数选择为
,训练迭代次数为50次。所有实体分类实验均在16 GB内存的CUP上运行。
4.3. 实验结果
AIFB、MUTAG和BGS三个数据集在WL、RDF2Vec、R-GCN和R-GAT,以及DR-GCN等模型下的实体分类结果如表2所示:
Table 2. Comparison of classification accuracy of various model entities
表2. 各模型实体分类准确率对比
在表2中,我们评估了在AIFB、MUTAG和BGS上的DR-GCN模型,实验结果显示,在AIFB数据集上,实体分类准确率由高到低的模型为:1) DR-GCN,2) R-GAT,3) R-GCN,4) RDF2Vec,5) WL。我们的DR-GCN模型的实体分类准确率比R-GAT模型的实体分类准确率还要高0.24%。在BGS数据集上,实体分类准确率由高到低的模型为:1) DR-GCN,2) RDF2Vec,3) WL,4) R-GAT,5) R-GCN。我们的DR-GCN模型的实体分类准确率比RDF2Vec模型的实体分类准确率还要高0.35%。在MUTAG数据集上,实体分类准确率由高到低的模型为:1) WL,2) DR-GCN,3) R-GAT,4) R-GCN,5) RDF2Vec。在MUTAG数据集上,准确率最高是WL模型,但是,我们注意到,DR-GCN模型仍比同是关系图卷积神经网络类型的R-GCN和R-GAT模型的准确率分别要高出2.70%和1.55%。正如Schlichtkrull等人 [2] 在他们的文献中所提到的,理解MUTAG数据集的本质与其特性,是一系列的关系图卷积神经网络类R-GCN、R-GAT和DR-GCN模型在MUTAG数据集上准确性比较一般的原因。若想对MUTAG数据集的本质特性有进一步详细的了解,可以参考Schlichtkrull等人 [2] 和Ristoski等人 [17] 的文献。
5. 结束语
本文探索了利用基于实体描述和关系图卷积神经网络的DR-GCN模型进行知识推理的实体分类任务。与现有的R-GCN模型不同的是,DR-GCN模型加入了实体描述这一信息。通过多组的实验,实验结果表明DR-GCN模型的方法比其他的四种基线在AIFB和BGS两个数据集上取得了更高的准确率,验证了改进后的模型效果更佳。下一步将利用DR-GCN模型作为编码器和ComplEx模型作为解码器形成一个自动编码器,这更适合对知识图谱中存在的大量非对称关系的建模,并对其进行链路预测任务检验模型的有效性。
基金项目
本广东省科技厅项目(2016A070708002);广东省教育厅研究生教育创新计划项(2016SFKC_42, YJS-SFKC-14-05, YJS-PYJD-17-03)资助;教育部“云数融合、科教创新”基金项目(2017B02101);江门市创新科研团队引进和资助项目(人工智能三维数字化技术在大型场景(地理空间)方向的应用研究);江门市基础与理论科学研究类科技计划项目( 2017JC01021)资助。