1. 引言
知识图谱是旨在描述人类知识各种实体或概念之间的内在关系 [1] [2],将知识内容转化为图结构,由表达知识概念的实体和反映两个实体之间关系的边组成,是一种数字化的语义网络,计算机存储和理解知识语义关系的一种结构化处理方法,是实现机器认知智能的关键技术,目前已经拥有很多成熟的产品应用。
1955年,Garfield就检索文献提出了自己的看法——引文索引的思想 [3]。1965年普赖斯提出“引证网络” [4],从此开启当代科学发展脉络引文研究时代,初步形成知识图谱(Mapping Knowledge Domain)的概念。1977年,知识工程知识库概念出现,成为研究人员的研究对象,其中以专家系统为主要代表 [5]。20世纪的90年代,新的概念——知识库(Knowledge Base) [6] 被提出,人们开始深入研究知识将如何表示、知识怎样组织,并将此研究广泛应用到各科研机构和企业单位。2012年11月,Google针对如何提升搜索引擎的准确性、如何提升用户使用感的问题,创新性提出知识图谱(Knowledge Graph)的概念 [7]。
随后知识图谱被广泛应用于知识问答领域,相较于传统的问答系统,基于知识图谱的问答系统以其特有的结构化知识大大提高其处理庞大数据量时的搜索效率,且还提供一定的推理功能。知识图谱的存储包括两种形式:资源描述框架(RDF) [8] 和图数据库。由于Neo4j相较其它数据库的各种优势 [9] [10],成为大幅度领先的主流图数据库。现在,较为知名的知识图谱系统有Google的KG、微软的Probase [11]、百度的知心、上海交通大学的zhishi.me (中文)、中国科学院的CAS-IR (目前国内规模最大)、搜狗的知立方等 [12]。
知识图谱在医疗领域的研究较多,钟亮 [13] 对文档实体关系挖掘分析建立相关学科知识图谱、马晨浩 [14] 根据电子病历建立甲状腺结节类的知识图谱、王昊奋 [15] 等人通过网络开放医疗数据建立患者辅助监控知识图谱、付洋 [16] 从医学网站获取医疗数据构建心脏病中文知识图谱、翟兴 [17] 基于权威书籍和开放互联网数据建立心血管疾病知识图谱、卢严砖 [18] 获取各大百科类网站的半结构化知识,建立慢性疾病知识图谱。
虽然医疗领域的知识图谱研究成果颇多,但对骨科领域的研究却较少能查阅到文献。同时,由于人口老龄化、社会经济发展、生活节奏加快,骨科疾病的发生概率显著增多。在骨科康复关注度日益提高的行业背景下,为解决以上问题,本文通过权威书籍和医疗网站获取骨科康复和一般疾病相关医疗知识,而后通过专家进行修正和补充,建立较为权威的骨科康复医疗知识图谱,为骨科康复研究提供必要的数据支持。同时,本文对该骨科康复知识图谱进行数据分析,为人们提供诸如食物、药品、检查等方面的骨科医疗建议。
2. 知识图谱的构建
2.1. 知识获取
在数据的获取方式上,考虑到骨科医疗疾病数据库的专业性,选择三种方式进行知识获取(见图1):1) 利用爬虫框架爬取互联网医疗网站的半结构公开数据;2) 对《骨科康复学》等骨科康复相关权威书籍进行归纳整理;3) 通过专家医生对数据进行修正和增删,提高数据知识的专业化水平。由于爬取半结构知识的获取方式获取的信息量大、速度快的特点,本文以此种采集方式为主。
半结构化数据采集选择Scrapy框架,其属于一种应用比例较高的爬虫框架,在应用过程中可高效的爬取网页,抽取海量的数据信息为其后面的处理提供支持。Scrapy中涉及较多组件,主要的五个组件功能为:1) 引擎:对爬虫抽取满足要求的数据流;2) 调度器:主要抓取相关地址对象;3) 下载器:获取相关文本内容;4) 爬虫:可从相关设定的标签位置获取满足要求的目标数据。5) 项目管道:解析处理抓取的xpath信息。
本文基于Win10系统,采用Python语言进行编程,通过activate shell脚本文件激活虚拟环境,目标抽取数据基于Chrome7.0确定出。Scrapy获取半结构化数据过程如图1所示,引擎从调度器获取一个URL封装成一个请求发送给下载器,下载器根据请求从互联网上下载数据并发出一个响应,爬虫组件获取该响应进行解析,如果解析结果为实体项目则发送到项目管道进一步处理,如果解析结果为URL链接则传递给调度器,等待下一次爬取。本文利用requests库给server传递请求,采用json格式在线接收网页疾病数据。
2.2. 知识表示
本文将网上爬虫得到的数据保存在名为medical的表中,该表在mysql数据库中。后续需将数据导入图数据库,因此对原始数据进行预处理。本文在爬取医疗网站时,某些信息杂糅在一起,后续创建知识库时需要将其分开,如表1所示:“food_info”字段包括适宜吃的食物、忌口的食物和推荐的食谱,后续需将它们分解成三个信息do_eat (宜吃食物)、no_eat (忌吃食物)和recommend_eat (推荐食谱)。

Table 1. Fields containing various information
表1. 包涵多种信息的字段
另外,某些字段的信息值有多个,需要将多个值分隔开,例如:“下背部痛”的症状有牵涉痛、神经痛、骨质疏松,需要将其分割成“symptom”:[“牵涉痛”,“神经痛”,“骨质疏松”]。类似字段有symptom、cure_department、cure_way、common_drug、cheek。
疾病信息以两种形式储存在Neo4j中,分别为实体–属性–属性值以及实体–关系–实体(分别为一对一、一对多数据映射)。一对一数据映射的属性仅仅对应一个值,但关系能够关联大量实体,例如“骨关节炎–治愈率–70%”。而在一对多数据映射中,同一实体的同一关系可对应多个实体,例如“骨关节炎–宜吃食物–>芝麻”、“骨关节炎–宜吃食物–>腰果”。
最终,本文共创建17432条通用疾病条目,613条骨科疾病条目,每个疾病条目下包含23条子条目,以字典形式保存在json文件中。相较心脏病中文知识图谱 [16] 的565个心血管疾病数据、8条子条目,本文知识图谱涵盖的疾病信息范围更广。
2.3. 知识存储
本文将爬取所得初始数据导入图数据库Neo4j中,完成知识图谱的构建工作。结合实际情况来看,本文选择CREATE语句的方式将节点、关系和属性信息导入图数据库。
导入节点有两类,一类为中心疾病(Diseases)节点,包含各种疾病属性;另一类为普通的实体节点,不包含属性。共创建Drugs、Foods、Checks、Departments、Producers、Symptoms、Diseases七类实体节点信息。
最后,共创建属于(belongs_to,包括“科室属于科室”和“疾病属于科室”)、常用药物(common_drug)、宜吃食物(do_eat)、忌吃食物(no_eat)、在售药品(drug_of)、所需检查(need_check)、推荐食谱(recommend_eat)、推荐药品(recommend_durg)、疾病症状(has_symptom)、并发症(accompany_with)十一类实体间的关系。
最终在Neo4j中实体节点如图2所示:
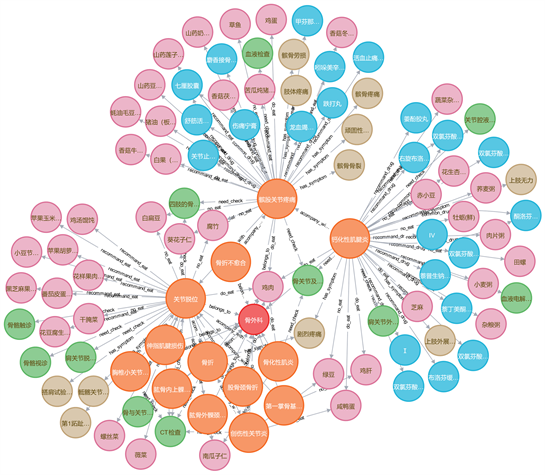
Figure 2. Partial knowledge graph visualization
图2. 部分知识图谱可视化
如图3所示,本文最终构建的骨科康复医疗知识图谱包含七个节点标签(药品、食物、检查项目、医疗科目、在售药品、疾病症状、疾病)共96983个节点,十一个关系类型(所需检查、推荐药品、忌吃食物、宜吃食物、推荐食谱、疾病症状、并发症、在售药品、常用药品、两个属于)共1099041条实体间的关系和九个属性。
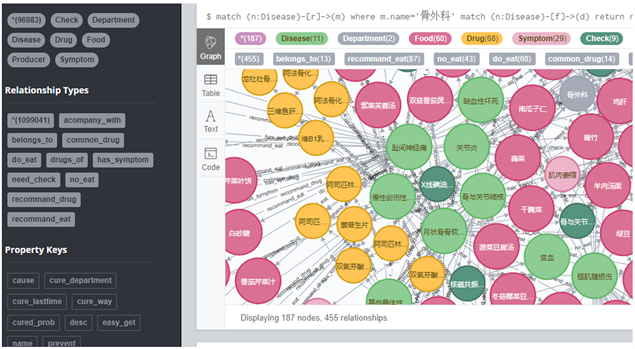
Figure 3. Knowledge graph Neo4j showcase
图3. 知识图谱Neo4j展示
3. 数据库分析
本部分对上文建立的基于通用疾病背景下的骨科疾病的医疗数据进行分析,对比实际医院使用的数据量来说,本文的数据量有所不足,下文分析仅针对本数据库而言,仅供参考。
3.1. 实体分布
在图数据库中,实体和其它实体间的关系用边表示,边数越多,表示该实体和网络的关系越复杂。图4给出实体关系直方分布,横坐标表示边数,纵坐标表示实体个数,由于纵坐标实体个数差异过大,故对纵坐标值取对数。从图中可知,本数据库无论是通用疾病或是骨科疾病,数据均服从幂律分布 [19]。
通用疾病的分布函数为:
其中,
表示通用疾病领域的实体边数,
表示通用疾病领域实体的个数。骨科疾病的分布函数为:
其中,
表示骨科领域的实体边数,
表示骨科领域实体的个数。
对比通用疾病和骨科疾病分布函数的指数数值,二者相差无几,大约为0.855,说明骨科作为通用疾病的子网络,满足同一分布。
3.2. 实体分析
图5为通用疾病和骨科疾病知识图谱的实体边数排行榜。图6为骨科疾病实体边数排行前50的部分可视化展示。实体连接的边越多,则表明该实体与其它实体的关联越多,该实体在知识图谱中的关系越复杂,该实体更容易被回答。例如骨科排行榜中,白酒、鸡蛋排名靠前,当用户意图与食物相关时,这两者会较大概率被检索回答。即排名越靠前,边数越多,被检索的概率就越大,作为备选答案的概率也越大。
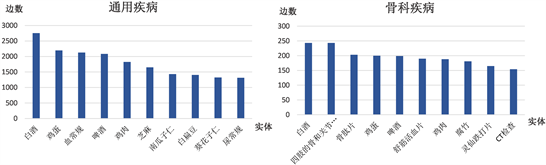
Figure 5. Ranking of the sides of the entity
图5. 实体边数排行榜

Figure 6. Partial visualization of the top 50 ranked orthopedic solid edge counts
图6. 骨科实体边数排行前50的部分可视化
3.3. 食物分析
图7展示本数据库排行前十五的宜吃食物和忌吃食物,左侧为通用疾病,右侧为骨科疾病。本文建议宜吃和忌吃排行榜需结合分析,例如:骨科宜吃食物中鸡肝虽然排名第十一,但忌吃曲线在此出现小峰值,结合骨科忌吃食物排行榜可发现鸡肝排名第十五,由此可见某些食材确实具有两面性,患者在食用时需稍加注意。

Figure 7. Ranking of suitable and forbidden foods
图7. 宜吃食物和忌吃食物排行
图8展示本数据库排行前十五的推荐食谱。骨科疾病推荐食谱与通用疾病推荐食谱排行榜大部分重合,除此之外,骨科食谱多出现草鱼食材的汤羹,另外例如豆腐、菠菜有关的食谱也可多考虑。从图中发现,排行靠前的食谱多为汤、羹、粥类,符合实际情况,本文由此建议患者切莫盲目滋养进补,患病期间应以清淡饮食为主。
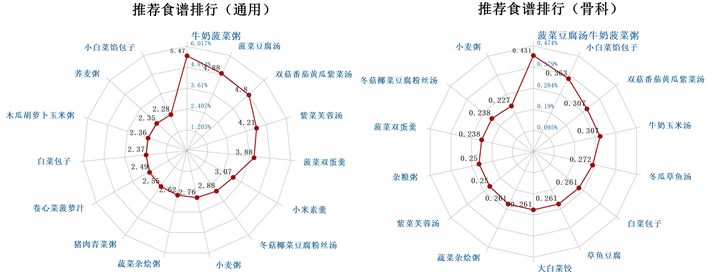
Figure 8. Ranking of recommended recipes
图8. 推荐食谱排行
3.4. 药品分析
图9罗列本数据库排行靠前的十五种药物,由图可见,常用药品和推荐药品排名情况并非完全一致,某些人们经常使用的药品并不一定是医生第一推荐的药品(如骨科排行图中的复方氨基酸胶囊),而某些相对使用较少的药品却是医生所推荐的(如骨科排行图中的舒筋活血片)。针对这种情况,本文建议以推荐药品为主要参考依据,辅助常用药品加以选择。
3.5. 症状分析
本文也对疾病症状进行排行分析(见图10)。骨科症状排行榜显示,骨科疾病前四个症状(肌肉萎缩、感觉障碍、剧烈疼痛、无力)大幅领先,这些症状是骨科疾病患者经常出现的症状。该图表给予人们一定参考,即当人们在日常生活中出现此类症状,特别是排行靠前的症状,需要引起重视,本文建议及时就医检查排除隐患。
3.6. 检查项目分析
四肢的骨和关节平片、CT检查、骨与关节MRI检查、骨关节及软组织CT检查为本系统骨科疾病排名前四的检查项目(图11),如有骨科疾病或考虑排查身体骨科方面问题,本文认为可考虑检查这四项项目。图中通用疾病的血常规、尿常规、心电图、便常规、CT检查排名前五,该五项检查是实际体检中常规的检查项目,利用这些检查项目可检查大多数身体异常,本文建议人们尤其是患者予以重视,定期检查该五项目。
3.7. 并发症分析
疾病引起的并发症往往令患者痛苦不已,本文对本数据库并发症排序(图12)发现,骨折、创伤性关节炎、骨关节炎是骨科最常引起的病痛,而休克和贫血是通用疾病最常引发的并发症。对于并发症,需要患者及护理人员多加注意。其次,上榜的其它并发症同样不能忽视,都需要引起注意。
4. 知识图谱应用
下面展示知识图谱应用于问答系统的对话测试示例。测试结果表明,系统根据用户问句,通过骨科知识图谱的知识检索,可以得出准确的知识回答,以此说明本文构建的骨科疾病知识图谱可进行实际应用。
5. 总结与展望
作为人工智能发展的一个重要分支 [20],知识图谱属于下一代搜索引擎主体部分,时至今日仍备受关注,尤其自然语言处理领域,已成为一个至关重要的研究课题,相关研究络绎不绝,由此取得一系列丰富成果。随着知识图谱研究的深入和市场的需求,知识图谱的研究目光逐渐聚焦于特定领域的知识处理。
由于社会、环境、生活等各方影响,医疗疾病特别是骨科疾病的发生概率显著增多。然而,对骨科知识图谱的研究却较少,目前尚无一个较为专业的骨科知识图谱以提供知识的查询和骨科疾病医疗建议。本文针对医学疾病,特别是骨科疾病,从海量数据的互联网抽取相关知识并进行清洗处理,同时利用权威书籍对数据进行补充,通过咨询专家提升数据的可靠性和专业化水平。而后将数据导入图数据库Neo4j中,构建以一般通用疾病为背景、骨科康复为主要内容的医疗疾病知识图谱。本文构建的9.6万规模实体和109万规模实体关系的骨科疾病知识图谱,为骨科康复的互联网远程智能问诊打下基础。而结合专业医疗知识图谱、健康医疗大数据和人工智能深度学习分析 [21] - [26],开发新一代智能化的疾病诊断分析和预测预警系统,将成为未来智慧医疗的一个重要发展方向。
本文知识图谱仍存在不足,后续可考虑深度学习技术,如可参考Liu Z等所建立的基于attention机制的CNN-LSTM-CRF中文命名实体识模型 [27]。对比实际医院的使用数据,本文知识图谱在疾病的广度和深度仍需进行补充;同时由于数据来源于开放性网站,虽有医生参与,但数据仍受个体化差异影响,可考虑与医院或医学研究所进行合作,以此提升知识图谱的专业性。
基金项目
本课题获得如下基金项目支持:国家自然科学基金资助项目(批准号:11874310和11675134)。
NOTES
*通讯作者。