1. 引言
肺癌是一种常见的恶性肿瘤,2015年中国肺癌新发病例73.3万,死亡病例61.0万,发病率和死亡率均居恶性肿瘤首位 [1]。其中,约85%的肺癌是非小细胞肺癌(Non-small cell lung cancer, NSCLC),大部分NSCLC患者确诊时即为晚期。在临床上NSCLC多使用分子靶向药物进行治疗,EGFR-TKI作为一种分子靶向药物,具有疗效显著且安全性良好等优点,因而常被用作为晚期NSCLS患者的标准治疗方案 [2]。大部分患者在接受药物治疗后会出现肿瘤消退的现象,且其中绝大多数会在一年时间左右对EGFR-TKI产生获得性耐药 [3] [4]。2010年美国的Jackman等 [5] 提出了EGFR-TKI获得性耐药的临床定义,该定义的核心是患者使用EGFR-TKI取得完全缓解或部分缓解后出现耐药进展的患者,我国的Yang等 [6] 根据不同的耐药发生情况进一步将耐药类别分为三类:缓慢进展、局部进展和爆发进展。临床上通常采用不同的治疗策略来应对不同的耐药情况,例如,如果一个患者的耐药进展是爆发性的,则必须更换治疗药物,相反,则可以继续延用原来的治疗方案。因此,为帮助医生制定合理的治疗方案,提高临床治疗的精准性和有效性,NSCLC患者耐药性类型的预测研究受到很多学者的关注。
近年来,人工智能(Artificial intelligence, AI)在医学图像中的应用引起了学术界的广泛关注,深度学习(Deep Learning)作为一种新兴的人工智能技术,已经在自动驾驶、人脸识别、医疗卫生等多个领域得到了成功的应用。传统的机器学习算法需要人为地设计特征提取这一过程,这一过程往往会耗费大量的时间成本,而深度学习能够自动地提取图像的特征 [7],并且在图像识别、目标检测等领域的表现已经超过了许多传统的机器学习算法。卷积神经网络(Convolutional Neural Network, CNN)是一种在计算机视觉领域使用得最广泛的深度学习模型,它能够自动提取图像的不同层次特征并学习到大量复杂数据中的非线性关系。许多研究表明,经过大量自然图像训练的CNN可以通过迁移学习的方式应用于医学图像识别任务中,并能取得良好的效果 [8]。
在医学图像分析领域,多数研究都集中在单个时间点上 [9],即只考虑了数据的横向关系,而没有考虑数据的纵向关系。然而,肿瘤是一种动态生物学系统,意味着它会随着时间而变化,可能无法在单个时间点上完全捕获肿瘤的特征。为了更好地区分不同的耐药性类型,应分析患者在离散时间序列上的CT数据,从而捕捉到不同耐药类型患者肿瘤的变化规律。循环神经网络(Recurrent neural networks, RNN)是在自然语言处理(Natural Language Processing, NLP)任务中使用得最多的深度学习模型,主要用于分析诸如文本、语音和视频之类的纵向数据,它可以处理多个时间点的输入数据并计算得出一个结果,因此,在分析离散时间序列的相关问题上,RNN具备一定的优势。
本文提出了一种基于CNN和RNN的预测方案,考虑到数据集相对较小,使用了数据增强和迁移学习技术来构建网络模型,通过分析NSCLC患者的时序CT图像来提前预测他们的耐药性类型,实验结果表明该模型在预测NSCLC患者的耐药性类型任务上取得了初步的成效。
2. 数据和方法
2.1. 数据集构成
本次研究针对产生EGFR-TKI耐药性的晚期NSCLC患者,患者数据主要来源于广西医科大学第一附属医院。由于每个病例检查次数的不同以及用药后的反应差异,只有满足采集标准的数据才会被纳入研究,纳入研究的标准如下:1) 接受EGFR-TKI治疗时间超过6个月;2) 病理检查和基因检测证实了对EGFR-TKI产生耐药性;3) 至少具有3次CT检查图像资料:接受EGFR-TKI治疗后第1、第3以及第6个月的CT检查图像。最终共收集到168个满足标准的病例,并根据Yang的标准将这些病例分为快速进展组、局部进展组和缓慢进展组,同时对他们的CT检查图像进行标注。不同时期的肿瘤大小不一,为了能够获取更多的肿瘤图像的信息,选取2.5 mm薄层平扫CT成像来构成数据集,以3:1的比例将其划分为训练集和测试集,分别用于模型构建和性能评估。
2.2. 图像预处理
由于肿瘤存在时间上的特异性,每次检查的CT图像中含有肿瘤的切片数量通常都不同,一般选择病灶体最大的切片作为研究对象。图1显示了患者在接受药物治疗后3个不同时期的肺部CT影像,为了能够让模型更好地学习病灶体特征,输入模型的图像只包含了病灶体部分,通过从原图中裁剪出一个矩形ROI (Region of Interest)来实现 [10],如图1中的黄色虚线标注区域。
通过这种方式获取的ROI大小可能会受到不同时期病灶体大小变化的影响,针对这一问题,本文使用了三次样条插值的方法将裁剪图像统一调整为50 × 50像素大小,来满足CNN对输入图像尺寸大小的要求。此外,显现出病灶体区域较大的切片图像通常包含了更多的有用信息,可以采用图2中的方法将病灶体较大的切片及其上下两层的切片融合成一张三通道的图像作为CNN的输入图像,提升模型的学习能力。
2.3. 神经网络结构
2.3.1. 卷积神经网络
卷积神经网络的基本架构如图3所示,主要由卷积层、池化层和全连接层三个部分组成,一些卷积神经网络还包括批量归一化层(BN) [11] 和dropout [12] 层。
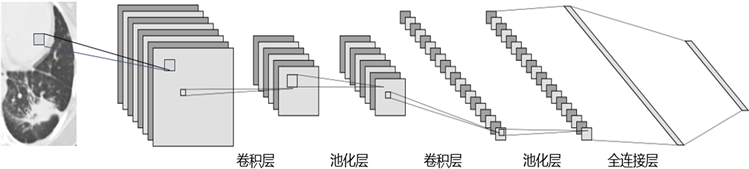
Figure 3. Basic structure of convolutional neural network
图3. 卷积神经网络基本架构
卷积层是卷积神经网络的核心部分,也被称为特征提取层,主要用于提取输入数据的特征。一个卷积层包含多个卷积核,不同的卷积核提取不同的数据特征,卷积核越多,能学习到的特征就越丰富。输入图像与卷积核进行卷积操作并通过一个非线性激活函数计算后可得到一系列特征图,即卷积层提取到的数据特征,可通过式子(1)表示:
(1)
式中n表示卷积核的高度和宽度,d表示卷积核的深度,
表示与卷积核相连区域的(h, w, d)处的值,
表示卷积核(h, w, d)处的权重参数,
表示卷积核的偏置项,
表示激活函数。
池化层也叫下采样层,通常紧跟在卷积层之后,可以降低特征图的分辨率,从而减少计算量,加速网络训练。
全连接层位于多个卷积层和池化层之后,是多层感知机(Multilayer Perceptron, MLP)的隐藏层部分,层中的每个神经元与前一层的所有神经元进行全连接。全连接层的作用是整合卷积层或者池化层中具有类别区分性的局部信息 [13]。
2.3.2. 循环神经网络
循环神经网络能够处理任意长度的时间序列,常用于机器翻译、对话生成以及语音识别等自然语言处理领域,网络结构如图4所示。
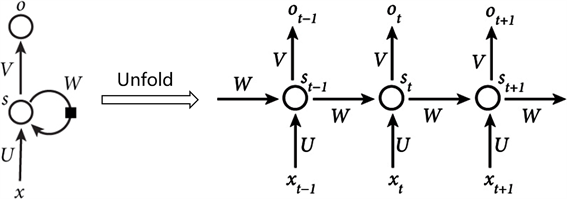
Figure 4. Structure of recurrent neural network
图4. 循环神经网络结构
其中,每一个圆圈代表一个全连接的神经网络,分别用来处理不同时间点的输入数据,两两之间通过一个权重矩阵相连,通过这种方式来将过去时间点的输入考虑到当前时间点的输出中,具体过程如式(2)所示:
(2)
式中
表示t时刻的输出向量,
表示不同时刻的输入向量,这些向量构成了时间序列,W表示连接不同神经网络的权重矩阵,U表示一个神经网络中输入层到隐藏层的权重矩阵,V表示一个神经网络中隐藏层到输出层的权重矩阵。
2.3.3. CNN + RNN融合模型
本文基于CNN和RNN的特点提出了一种融合二者的模型,该神经网络模型在Keras深度学习框架上完成构建,包括python 3.6.5、Keras 2.3.1以及TensorFlow 1.14.0等工具。模型由CNN和RNN两个部分构成,CNN部分用于提取病灶体的特征,这些特征在时间轴上存在特定的关系,这种关系可以被RNN处理。本文使用经过预训练的Inception-V3网络作为图像的特征提取器,即CNN部分,Inception-V3 [14] 是一种深度卷积神经网络模型,在各种计算机视觉任务中均取得了出色的表现;RNN部分,选择长短时记忆网络(Long Short Term Memory Network, LSTM)来处理特征提取器输出的时序特征向量。
据此可以构建出如图5所示的网络模型,其中CNN部分包含三个卷积神经网络,分别用来处理不同时期的病灶体输入图像。图像经过卷积及池化后再通过一个全连接层整合输出,输出向量包含该时期病灶体抽象信息的同时与其他输出向量构成时间上的联系。三个输出向量构成了一个时间序列,使用三个时间步的LSTM网络来接收这些时间序列,内部的神经网络结构可以关联这些时间序列信息,并在LSTM中前向传播,在网络的最后一个时间步输出。在输出端引入一个全连接层,用来汇聚LSTM网络的输出信息,同时提高模型的学习能力,并在其之后应用一个BN层和一个dropout层来提高模型的泛化能力,最后通过一个softmax层输出最终的预测结果。
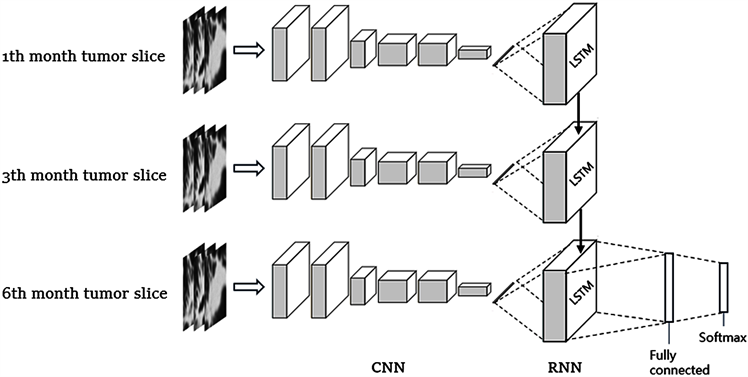
Figure5. The neural network architecture
图5. 神经网络结构
2.4. 迁移学习和数据增强
医学图像数据的收集相对比较困难,主要有两个原因:第一,医学图像数据涉及病患的隐私和安全等信息,因此公开的医学图像数据会比较少;第二,对医学图像进行标注的过程十分繁琐,需要至少一名该领域的专家才能确保数据标注的准确性,这个过程将消耗大量的时间成本。网络训练的过程中,数据集过小可能带来过拟合等问题,针对这些问题,许多医学图像领域的研究使用迁移学习和图像增强的方法来弥补数据集较小带来的影响。
迁移学习是一种知识共享技术,网络模型首先在一个具有大量自然图像的数据集上训练,学到了大量丰富的特征以及复杂数据之间的非线性关系,当迁移到一个新的任务上时,降低了对新数据的依赖,从而减少构建深度学习模型所需的训练数据并提高模型的泛化能力。另外,医学图像和自然图像也有一定的共性,如图像中的物体都会有轮廓、纹理、线条等低级的特征,因此当预训练模型在新的数据集上训练时,可以在一定程度上加快收敛的速度。本文使用微调的方式来实现模型的迁移学习,模型的每一个Inception-V3网络首先在ImageNet数据集上进行预训练,该数据集含有1.4亿张自然图像,卷积神经网络能够从中学习到大量的抽象特征。当训练迁移到我们的数据集上时,固定模型CNN部分的权重参数,只训练模型RNN部分的权重参数。
迁移学习使模型的训练更高效,但并未从根本上解决数据集较小的问题。为进一步扩充训练数据,可以使用图像增强的方法,利用相关算法或技术对现有的数据进行处理,以此获得新的样本数据,从而达到扩充数据集的目的。常用的数据增强操作有旋转平移图像、扭曲图像特征、改变图像尺寸大小以及增强图像噪音等。这些增强数据的操作只应用于模型的训练集,为了避免训练样本的类别不平衡,不同类别的训练样本将进行不同规模的数据扩充。
3. 实验结果及分析
3.1. 模型训练
训练过程在广西大学高性能计算平台上进行,其搭载AMD Opteron 8431 2.4 Ghz六核计算处理器以及Nvidia Tesla V100图形处理器(显存32GB,计算能力7.0),训练时可以根据具体情况调用多个GPU节点提高训练效率。为了使训练后模型具有更好的鲁棒性,使用了交叉训练的方法构建模型。即对于每个epoch,训练样本都会被分为训练部分和验证部分,模型会分别在这两个部分进行训练和验证。采用自适应梯度矩估计(Adaptive moment estimation, Adam)算法自适应调整学习率,并以式(3) softmax交叉熵损失函数作为目标函数,
(3)
式中,n为模型预测的类别数,
为模型预测每个类别的概率,
为样本的标签。
 (a) 训练准确率
(a) 训练准确率 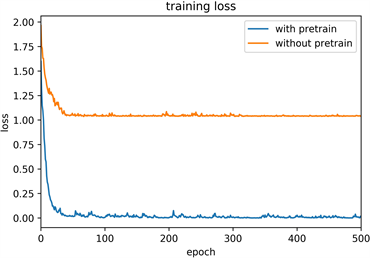 (b) 验证准确率
(b) 验证准确率 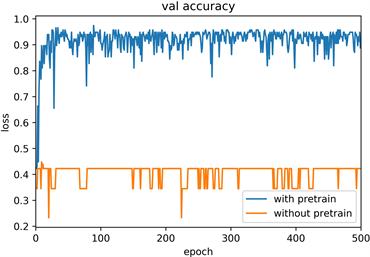 (c) 训练损失率
(c) 训练损失率  (d) 验证损失率
(d) 验证损失率
Figure 6. Training result
图6. 训练结果
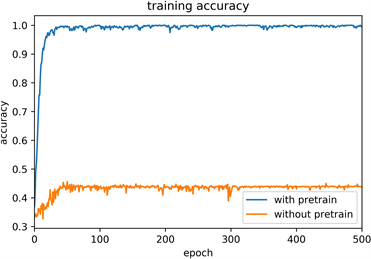
模型训练过程的平均准确率为98.76%,验证过程的平均准确率为95.16%,训练和验证过程中准确率的变化如图6(a)~(b)中蓝色曲线所示,损失率的变化也如图6(c)~(d)蓝色曲线所呈现,在迁移学习的基础上,模型迅速收敛,在60个epoch后loss值趋于稳定。为了进一步验证迁移学习的实际应用效果,实验对比了使用预训练模型前后对训练结果的影响,图6(c)~(d)中的黄色曲线为使用随机初始化参数模型的训练过程,模型基本无法收敛,证明了迁移学习对该模型训练的有效性。
3.2. 评价指标
本次研究的目的是预测非小细胞肺癌患者对分子靶向药物产生的耐药性类型,本质上是一个深度学习的分类任务,因此使用分类任务中的评估参数来作为模型性能的评价指标,如准确率(Accuracy, ACC)、精确率(precision)、召回率(Recall)以及F1score等参数。这些参数可以通过表1中的具体数值进行计算,其中,TP表示将正例预测为正的个数,FP表示将负例预测为正的个数,FN表示将正例预测为负的个数,TN表示将负例预测为负的个数,通过这4个值可以计算出上述评估参数的值,公式如下:
(4)
(5)
(6)
(7)
这些评估参数常作为二分类任务的评估指标,多分类任务的评估参数的计算主要有两种方法:第一种方法是微平均法(Micro Average),对于某个类别,除它之外的其他类别都当作负例,通过这种方式计算出每个类别的混淆矩阵,然后对每个混淆矩阵对应位置处的TP,FP,TN,FN求平均来得到一个平均混淆矩阵,再使用上述公式计算出APRF (Accuracy, Precision, Recall和F1 score)的值。第二种方法是宏平均法(Macro Average),该方法同样先求出每个类别的混淆矩阵,不同的是它先计算出每个混淆矩阵的APRF的值,然后再对这些值求算数平均来得到最后的多分类评估参数的值。
另外,本文还使用ROC (Receiver Operating Characteristics)曲线作为分类任务的评价指标。曲线的横坐标和纵坐标分别为假阳性率(False Positive Rate, FPR)和真阳性率(True Positive Rate, TPR),曲线下的面积大小(Area Under Curve)用来衡量模型分类结果的好坏,通常,AUC值在0.5~0.7之间时,模型的分类性能可能较低;在0.7~0.9之间时,分类性能可以认为是较好的;AUC值大于0.9时,则表示模型的分类性能非常好。
3.3. 测试结果
测试集包含44例NSCLC患者的病灶体图像,用来测试构建模型的分类性能。使用宏平均法计算上述4个评估指标,结果如表2所示,模型在测试集上的准确率适中,表明总的分类结果是良好的,而精确率(precision)、召回率(Recall)以及F1score的值都在70%以上,意味着模型对于每个类别的分类也取得了较好的结果。
为更直观的观察模型的分类性能,为每个类别单独绘制了ROC曲线,如图7(a)所示,以及它们的平均ROC曲线,如图7(b)所示,平均ROC曲线通过微平均法和宏平均法两种方法计算得到。从图7中可以看出,每一个类别的AUC值都在0.7以上,平均AUC的值也达到了0.8左右。尽管测试集的病例较少,可能无法体现模型的泛化性能,但是这些结果仍然说明了该方法在预测NSCLC患者耐药性类型的任务上的有效性。
 (a) 单个类别ROC曲线
(a) 单个类别ROC曲线  (b) 平均ROC曲线
(b) 平均ROC曲线
Figure 7. The ROC of classification results
图7. 分类结果的ROC曲线
4. 结论
NSCLC患者容易对EGFR-TKI产生获得性耐药,耐药发生情况的多样性,使临床的治疗变得十分困难。针对这个问题,本文提出了一种基于CNN和RNN的NSCLC患者耐药性预测模型,从纵向角度分析了肺癌肿瘤变化对于患者耐药性的影响。由于数据集大小的限制,仅用三个时期的病灶体图像作为输入数据,尽管这可能很难完全反映出肿瘤变化的过程,但实验结果同样证明了使用该方法来预测患者耐药性类型是可行的。从理论上讲,随着输入数据量以及时间步的增加,模型能够取得更好的表现。
基金项目
广西自然科学基金资助项目(2017JJA170765y);广西研究生教育创新计划资助项目(YCSW2020064)。