1. 引言
1.1. 研究背景
当今时代,大众传媒使娱乐偶像行业不断发展,在带来丰厚商业利润的同时,也在一定程度上引导着主要是社会青年阶层的想法,并且随着科学技术发展和资本的不断投入,全新概念的虚拟偶像不断诞生。虚拟偶像的诞生给娱乐产业带来一定程度的冲击,虚拟偶像和传统偶像逐渐形成竞争关系。新崛起的虚拟偶像的受众群体、消费关联以及TA们的未来发展走向成为当下备受关注的热点问题。
1.2. 研究意义
国内偶像发展如火如荼,且虚拟偶像正处于发展的黄金时期,但相较于发展火热的娱乐偶像产业,与之相关的发展现状及未来预测研究却寥寥。随着虚拟偶像商业价值被不断发掘,其带动周边产业发展的能力将会愈发强劲,商业应用领域也会更加广泛。在虚拟偶像产业还没完全建立时,对虚拟偶像进行深入分析,并从中探索虚拟偶像消费发展,从而为虚拟偶像行业发展提供具有理论支撑的可靠依据,同时引起学者对偶像产业关注,为后续学者研究虚拟偶像消费问题以及相关理论建立基础框架,对虚拟偶像行业具有显著意义。
2. 研究设计与模型建立
2.1. 变量选取
2.1.1. 消费意愿
消费意愿日益拉动经济增长,可以认为消费意愿就是自身时间、收入水平影响下对某一种产品的主观偏好 [1]。也有学者认为消费意愿是消费者购买使用某一商品的行为,是衡量消费行为的一种指标。还有学者把消费意愿定义为消费者对于某一服务或某一产品所持有的主观偏好 [2]。综上,结合本文研究方向,把消费意愿定义为对偶像行业以及行业衍生产品的消费行为意愿。消费的活力会为中国经济的增长提供动力,为此在对消费意愿的划分上,国外学者把消费者购买产品的意愿程度划分为考虑购买、可能购买、想要购买这几个层次 [3]。本研究参考以上文献对消费意愿做出具体测量,将意愿程度划分为愿意购买、不愿购买两个层次。
2.1.2. 其他变量构建

Figure 1. Word cloud chart of consumer consumption reasons
图1. 消费者消费原因词云图
本文确定主题后,研究小组通过先行问卷收集消费者愿意为偶像消费的原因,问卷回收后对收集到的样本数据进行原因分析,并进行词云图绘制,得到上图1结果。将出现最多的词云进行归纳整理,提取出影响消费意愿的四个原因,分别是能力感知、形象建构、信息感知、资本支持。
2.2. 建理论模型
本文为分析虚拟偶像行业发展现状及消费者对相关虚拟偶像的消费意愿,通过先行问卷分析提炼出影响消费者消费意愿的四个原因。现将消费意愿、能力感知、形象建构、信息感知和资本支持五个变量作模型潜变量,构建如下图2所示的理论模型。
2.3. 研究假设与变量选择
2.3.1. 研究假设
提出以下假设:H1:能力感知影响信息感知;H2:形象建构影响信息感知;H3:资本支持影响信息感知;H4:资本支持影响形象建构;H5:形象建构影响消费意愿;H6:能力感知影响消费意愿;H7信息感知影响消费意愿;H8:资本支持影响消费意愿。
本文结合研究对象和研究假设,选取5个研究变量,分别为能力感知(X1)、形象建构(X2)、信息感知(X3)、资本支持(X4)、消费意愿(X5),各个变量环环相扣。
研究假设如图3所示:
2.3.2. 变量选择
本文在确定潜变量后,对不可直接测量的潜变量赋予测量变量构建测量模型。采用声音、颜值、身材、服饰、人设5个测量变量对用户对虚拟偶像形象构建进行度量;采用专业能力、自我提升能力、互动能力、感染力4个测量变量对粉丝对虚拟偶像的能力感知进行度量;采用作品分享欲、偶像分享欲、热度、粉丝氛围、口碑5个测量变量对虚拟偶像粉丝的信息感知程度进行度量;采用宣传力度、广告投放量、周边产品量、公司运营公司硬件、活动数量6个测量变量对虚拟偶像背后公司资本支持程度进行度量;采用作品支持度、周边购买量、购买代言产品量、购票量、刷礼物量、打投量6个测量变量对虚拟偶像粉丝的消费意愿进行度量。对各个测量变量进行编号,方便后续数据分析,各变量关系如表1所示:

Table 1. Structural equation model variables table
表1. 结构方程模型变量表
根据建立的变量与对模型提出的假设,添加相应的残差变异项,构建相应结构方程模型,模型如图4所示。
2.4. 问卷设计与数据收集
2.4.1. 问卷设计
在确定调查变量以及初步构建模型后,团队根据上述信息进行问卷设计。首先问卷根据受调查者是否了解虚拟偶像并对其感兴趣进行A、B卷问卷分流,对虚拟偶像有一定了解或对其很感兴趣的受调查者回答A卷,而对虚拟偶像不了解并且不感兴趣的受调查者回答B卷。
A卷主要对受调查群体进行虚拟偶像应援方式、爱好虚拟偶像类型、了解虚拟偶像途径、关注虚拟偶像时间、每月为虚拟偶像花费金额、了解什么虚拟偶像动态进行群像调查,同时了解受调查者基本信息以此对虚拟偶像受众群体进行画像。同时根据2.3中所提及变量选择,对问卷进行量表题设计,从而获取相关数据对各变量相关关系进行结构方程模型建构。

Figure 4. Structural equation model diagram
图4. 结构方程模型图
B卷主要对受调查群体进行如何了解传统偶像咨询、如何支持传统偶像、每月为传统偶像花费金额以及对虚拟偶像不感兴趣原因、受调查者基本信息对非虚拟偶像受众群体进行画像,并了解原因,为如何转化其他群体为虚拟偶像受众群体、扩大虚拟偶像受众群体提出建设性意见。
2.4.2. 问卷设计
查阅结构方程模型相关文献,具有7个或更少结构,适度的公共性(0.5),和充分识别的结构,最少要达到150个样本量 [4]。本文选取了5个潜变量,每个潜变量具有4~6个测量变量,符合上述要求,据此研究小组收集样本量349份,其中有效量表样本量276份。
3. 样本数据可靠性分析
3.1. 信度分析
本文建立了包含26个题项的总量表,为了保证量表内部的一致性和所分析的数据的可信性,在进行探索性因子分析之前,首先需要对样本数据进行信度检验。信度检验,即为同一对象,采用同样的方法进行多次检测,最后结果是否能保持一致。信度检验用来探讨定量数据的可靠性和精确性,本文采用最常用的Cronbach’s Alpha (克朗巴哈系数法)进行信度检验。它的数学公式如下:
(1)
其中:k为题量,
为第i题得分方差,
为总得分方差。
公式(1)中,通常克朗巴哈系数值在0~1之间。对于α系数采用分段法,当数值超过0.8时,其信度较高;当数值在0.7~0.8范围内,其可信性较好;当数值在0.6~0.7范围内,其可靠性是可以接受的;若数值低于0.6,则表示不可信,应对数据作适当的修改或删除;在CITC值小于0.3的情况下,可以考虑删除项目。
由下表2可得,潜变量总体Cronbach’s Alpha系数为0.752,大于0.75,在可以接受的范围内。
Table 2. Overall Cronbach’s alpha coefficient for latent variables
表2. 潜变量总体Cronbach’s Alpha系数
下面分析,每个潜变量的Cronbach’s Alpha系数。从表3中可以看出,能力感知和消费意愿两个潜变量的Cronbach’s Alpha系数值均大于0.9,有优良的测量信度,形象构建、信息感知和资本支持这两个潜变量的Cronbach’s Alpha系数值也在大于0.8,在较好的范围内。综上所述,认为潜变量信度良好。
Table 3. Latent variable Cronbach’s Alpha coefficient statistics
表3. 潜变量Cronbach’s Alpha系数统计
3.2. 效度分析
本文使用了探索性因子分析。在判断问卷有效性之前,即在效度检验之前,首先通过KMO检验和Bartlett's球体检验的试验,以保证数据适用于进行因子分析。对于KMO检验,大于0.9就非常合适做因子分析;0.8~0.9之间比较适合;0.7~0.8之间适合;0.6~0.7之间尚可;0.5~0.6之间表示不太适合;0.5下不适合。对于Bartlett的检验,若显著性小于0.05或0.01,则拒绝原假设,说明可以做因子分析;若不拒绝原假设,说明这些变量可能独立提供一些信息,不适合做因子分析。KMO计算公式(2)如下:
(2)
验证结果如表4所示,KMO的取值为0.873,大于0.8,认为该数据适合做因子分析。Barlett球形检验卡方值为5198.873,显著性水平为0.000 < 0.001,即统计检验显著,说明该维度适合进行效度分析。
分析因子负荷矩阵与方差贡献率。通过对样本进行探索性因子分析,通过主成分分析的方法提取因子,提取五个主成分,累计方差贡献率达到了75.579%,大于75%,说明能够较为充分地反映原始数据;通过正交旋转法提取的共同因子,最终提取其中一个。因子组成与模型中的假设提出是一致的,说明本调查有较好的结构效度。
Table 4. KMO and Bartlett’s test
表4. KMO和巴特利特检验
4. 虚拟偶像行业分析
4.1. 虚拟偶像受众画像
对虚拟偶像的了解程度进行编码,“十分了解,并对其感兴趣”为“1”,“了解,对其有一定兴趣”为“2”,“不太了解,但有兴趣去了解”为“3”,“不太了解,并对其没兴趣”为“4”,“完全不了解”为“5”。
对虚拟偶像受众进行画像,对其年龄以及月可支配收入进行统计分析,绘制三维折线图,如下图5、图6所示。

Figure 5. Three-dimensional line graph of age and understanding
图5. 年龄与了解程度的三维折线图
从年龄来看,对虚拟偶像了解程度较深的群体年龄集中在18~25岁和26~35岁这两个年龄区间段,年龄在“36~45岁”和“>45”岁这两个年龄区间段的被调查者对虚拟偶像了解程度不深,由此分析虚拟偶像受众群体多为青年;
从月可支配收入来看,对虚拟偶像了解程度较深的群体月可支配收入集中在2500~4999元和5000~9999元这两个收入区间段,对虚拟偶像了解程度不深的群体月可支配收入集中在1000元以下和1000~2499元这两个收入区间段,中高收入群体对虚拟偶像的了解程度较深,且了解意愿更为强烈,而低收入群体对虚拟偶像的了解程度相对较弱。
将问卷中对虚拟偶像“十分了解,并对其感兴趣”、“了解,对其有一定兴趣”和“不太了解,但有兴趣去了解”作为虚拟偶像现有受众群体,对其关注时间和花费金额进行统计分析,绘制饼图,如下图7、图8所示。

Figure 6. Three-dimensional line graph of monthly disposable income and level of understanding
图6. 月可支配收入与了解程度的三维折线图

Figure 7. Virtual idol audience attention time pie chart
图7. 虚拟偶像受众关注时间饼图
从关注时间来看,大部分受众关注时间在一个月以上,占受众群体的75.4%,关注时间为一个月以内的新受众占24.6%,关注时间在两年以上的受众为13.0%。由此可以推测出虚拟偶像吸粉能力较强,但留存用户能力相对较弱;
从花费金额来看,花费金额在200元以下的受众占样本总体的26.4%,不花钱的受众占22.1%,低消费受众群体大约占据受众群体的50%,而2000元以上的高消费受众群体占比较少,虚拟偶像受众消费人数占比超过四分之三,意愿较为强烈,花费金额分布较为分散。
综上所述,虚拟偶像受众群体可画像为:多为青年群体、多为中高收入群体、新用户较多、消费欲望较强烈。
4.2. 虚拟偶像消费偏好探索
本次问卷调查针对消费者偏好设置了相应多选排序题,将排序次序赋值(降序赋分)并录入SPSS进行统计分析。如题目“您倾向于关注您喜欢的虚拟偶像的哪些动态?”,限选五项并排序。将次序为第一的赋分“5”,将次序为第二的赋分“4”,……将次序为第五的赋分“1”,没有选择的赋分“0”,计算均值并排序,虚拟偶像受众偏好统计结果如下表5所示:
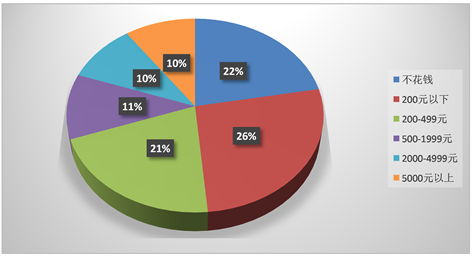
Figure 8. A pie chart of how much people spend or estimate to spend on virtual idols each year
图8. 受众每年在虚拟偶像上花费或预估花费金额饼状图
Table 5. Virtual idol audience preference statistics
表5. 虚拟偶像受众偏好统计
对于虚拟偶像类型,消费者更偏好虚拟idol,其次是虚拟歌姬和虚拟主播,虚拟idol市场蓬勃发展,涌现出A-SOUL、冷鸢等一系列高质量虚拟偶像和虚拟偶像团体,受众群体不断扩大,虚拟歌姬发展时间较长,从初音未来到洛天依,市场不断推出优质虚拟歌姬,其粉丝粘性较高,B站直播也在大力发展虚拟主播,在其指定官方直播、剪辑的软件中推荐虚拟形象,但其虚拟主播质量良莠不齐;
就动态关注来看,消费者偏好直播、生日会、社交媒体等形式的虚拟偶像动态,目前虚拟偶像与受众互动的主要形式是直播,同时生日会、演唱会可以拉近虚拟偶像与受众的距离,而在微博、loft等社交媒体发布动态可以增加虚拟偶像的真实感,广告代言、相关游戏联动等活动可以进一步宣传虚拟偶像;
消费者更偏好B站、QQ、抖音等平台,B站等互动平台是虚拟偶像爱好者的聚集地,比如目前A-SOUL等较大的虚拟偶像团体主营在B站直播,受众群体庞大;虚拟偶像受众群体多采用社交媒体互动、打投、购买周边等应援方式。
4.3. 虚拟偶像潜在消费用户探索
本次调研将问卷中对虚拟偶像“不太了解,并对其没兴趣”和“完全不了解”的人群视为传统偶像群体。部分传统偶像受众群体是虚拟偶像消费潜在用户,对此类用户进行“为何不喜欢虚拟偶像”统计分析,可将此类用户转化为虚拟偶像消费用户,从而拓宽虚拟偶像消费群体受众。
题目“您不喜欢虚拟偶像的原因?”,限选三项并排序。将次序为第一的赋分“3”,将次序为第二的赋分“2”,将次序为第三的赋分“1”,没有选择的赋分“0”。
Table 6. Statistics on the reasons why respondents do not like virtual idols
表6. 被调查者不喜欢虚拟偶像的原因统计
由表6可以看出不喜欢虚拟偶像人群主要原因为不符合审美、认为粉圈过于混乱、受众群体相较于传统偶像较少。将此类潜在用户吸引成为虚拟偶像受众者,可通过改善虚拟偶像形象,使其更贴合现实人物;改善粉圈现状;增加虚拟偶像曝光度,扩大受众群体,让潜在受众接触并了解虚拟偶像,从而达到吸引潜在用户的目的。
5. 结构方程模型分析
结构方程模型是用一种基于变量的协方差矩阵来分析变量之间的相互关系的统计方法。本文在SEM模型的基础上,建立了虚拟偶像消费意愿的理论模型。
5.1. 因子载荷系数
模型的系数表,包含了潜变量、分析项、非标准载荷系数、z检验结果等。当测量关系时,第一个项目将被用作一个参考,所以P的数值将不会被显示。因子载荷系数对因子内测量变量进行筛选,一般来说,测量变量通过显著性检验(P < 0.05或0.01),且标准负载系统的数值在0.6以上,可表明测量变量符合因子要求,条件差距太大可以考虑删除变量。如果测量关系良好,通常来说,标准化载荷系数值基本上均会大于0.6。
分析该模型路径系数表可知,各变量显著性P值均为为0.000***,呈现显著性,所以拒绝原假设,同时他们的标准载荷系数均大于0.4,可以认为他们有足够的方差解释率表现各变量能在同一因子上展现。
5.2. 模型回归系数
Table 7. Model regression coefficients table
表7. 模型回归系数表
注:***、**、*分别代表1%、5%、10%的显著性水平。
表7展示了路径节点的回归系数,可以理解为一个最小二乘法一元线性回归,通常只需要观察P值与标准化路径系数,确定该路径(X— > Y)是否存在直接的线性影响。根据显著性检验分析(P值小于0.05)模型变量之间是否存在影响关系。若存在显著性,说明变量之间存在影响关系,可通过标准化路径系数对影响效率进行深入分析。
由模型路径系数表可知:
基于配对项能力感知→信息感知,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为0.716;基于配对项形象构建→信息感知,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为0.264;基于配对项资本支持→信息感知,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为1.000;基于配对项资本支持→形象构建,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为0.358;基于配对项形象构建→消费意愿,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为0.657;基于配对项能力感知→消费意愿,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为0.987;基于配对项信息感知→消费意愿,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为0.991;基于配对项资本支持→消费意愿,显著性P值为0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为0.989。
综上所述,基于前文各潜变量之间的假设关系,显著性P值均为0.000***,水平上呈现显著性,则拒绝原假设,因此假设的路径均有效。
5.3. 模拟拟合指标
把数据导入Amos中运行,测算出相关指标如表8所示。
Table 8. Simulation fitting index table
表8. 模拟拟合指标表
表8展示了模型的拟合指标,可以适当选择一些指标进行评价,若所有指标均不满足,可以考虑根据输出对路径进行删除或者重构。
比较多个模型运用卡方和自由df度对比(Chi/DF),卡方值越小越好,自由度越多,模型越简单。
拟合优度指数(GFI):主要是运用判定系数和回归标准差,检验模型对样本观测值的拟合程度。其值在0~1之间,愈接近0表示拟合愈差。CFI > 0.9,认为模型拟合较好。
调整后的拟合优度指数(AGFI):取值在0~1之间,越接近1,模型整体拟合越好。AGFI = 0.91,大于0.9,认为模型整体拟合度优良。
近似误差均方根(RMSEA):一般情况下,RMSEA在0.08以下,越接近于0,模型越准确。RMSEA = 0.024 < 0.8,认为模型准确度较好。
Chi/DF为1.180处于1~3之间,处于较好的区间,反映样本共变异数矩阵和模型共变异数矩阵相似度的指标GFI和AGFI大于0.9,矩阵拟合效果较好,反映模型差异性的指标RMSEA为0.024 < 0.8,处于优良区间,认为该模型的结构效度可以接受。
5.4. 模型结论
根据结构方程模型分析可知,能力感知和形象构建对信息感知有正向影响,资本支持对信息感知和形象构建有正向影响,能力感知、信息感知、形象构建和资本支持对消费意愿均有正向影响,可知提取出的四个潜变量都可以促进虚拟偶像受众的消费意愿。
6. 虚拟偶像未来发展预测
6.1. 行业规模
根据艾媒数据和相关文献资料,整理得到2017~2021年虚拟偶像行业规模(带动市场规模和核心市场规模)数据,得出线性回归方程y = 264.76*(x − 2016) − 304.58,其中y为虚拟偶像市场规模,单位为亿元,x为年份,并由此简单预测2022年虚拟偶像市场规模约为1283.98亿元。

Figure 9. Virtual idol market size and forecast 2017~2022
图9. 2017~2022年虚拟偶像市场规模及预测
由图9可以看到,虚拟偶像市场规模保持增长态势,但近年来增长速度有所放缓。现今,字节跳动、乐华、网易等大公司在偶像设计、动作捕捉、直播等环节布局虚拟偶像产业,不断推出新的虚拟偶像和虚拟偶像团体,市场有同质化的趋势。
6.2. 产业发展趋势
虚拟偶像逐渐走进公众视野,想要进一步拓宽市场,让更多消费者接受虚拟偶像,其功能不能只局限在娱乐需求,且目前各大媒体推出的虚拟主持人、虚拟代言人等社会服务性质的虚拟偶像技术较为不成熟,在今后的发展中,虚拟偶像行业可向社会服务方向发展,同时完善相关技术,为用户带来更好的体验感。
随着虚拟偶像行业的发展和直播技术的完善,越来越多的人和公司加入到虚拟偶像这个行列,一时间市场涌现出大量虚拟idol、虚拟主播。这些虚拟偶像良莠不齐,且没有较为规范的管理制度,市场较为混乱;近期乐华公司旗下的虚拟偶像团体A-SOUL珈乐事件引发热议,由此可见,公司运营合理才能平衡好“中之人”和“偶像”,不能一味追求而去利益压榨偶像。在未来几年,虚拟偶像产业将会不断成熟,行业管理逐渐规范。
7. 研究结论
1) 根据本次问卷调查数据,进行描述性统计分析。得出虚拟偶像受众群体画像为:多为青年群体、多为中高收入群体、新用户较多、消费欲望较强烈。对虚拟偶像消费者偏好进行统计分析,发现虚拟偶像受众更加偏好虚拟idol;对于动态关注,虚拟偶像受众偏好直播、生日会社交媒体等互动形式;对于社交媒体平台,虚拟偶像受众偏好B站、抖音等平台;虚拟偶像受众群体多采用社交媒体互动、打投、购买周边等应援方式。
2) 对虚拟偶像潜在受众群体不喜欢虚拟偶像原因进行统计分析,得出不喜欢虚拟偶像主要原因是:不符合审美、认为粉圈过于混乱、受众群体相较于传统偶像较少。
3) 根据结构方程模型分析可知,能力感知和形象构建对信息感知有正向影响,资本支持对信息感知和形象构建有正向影响,能力感知、信息感知、形象构建和资本支持对消费意愿均有正向影响,可知四个因素都可以促进虚拟偶像受众的消费意愿。
4) 对近年来的虚拟偶像行业规模进行统计,得出虚拟偶像市场平稳发展,市场规模不断扩大的结论。根据产业发展趋势,拓宽虚拟偶像行业要进一步完善相关技术,可向社会服务方向发展,规范行业管理,进一步发挥虚拟偶像的优势。
8. 建议与展望
1) 在用户吸引和留存层面上,可基于受众群体画像,针对性的对此类群体进行定向吸引和巩固。
2) 根据潜在用户文娱资讯来源,可多通过影视作品、社交媒体、杂志书籍等媒体渠道进行传播,让更多传统偶像受众群体中的虚拟偶像消费潜在用户转变为虚拟偶像受众群体。
3) 虚拟偶像设计层面,可通过改善虚拟偶像形象,使其更贴合现实人物;改善粉圈现状;增加虚拟偶像曝光度,从而增加受众群体。
4) 关注虚拟偶像受众转化,提高受众消费。
目前市场上,粉丝经济依然是虚拟偶像最重要的变现手段,应更多关注如何转化更多用户为虚拟偶像粉丝、增加粉丝消费。随着二次元领域的主要受众群体90/00后的逐渐拥有了自主消费能力,虚拟偶像在流量变现、内容变现等方面将会获得更好的支撑,具有非常强的忠诚度、号召力以及商业变现前景。虚拟偶像IP在内容和周边产品的开发上拥有更多的空间和可能性,随着潮流的变化和时代的发展的基础上进行形象开发和内容开发,有利于持续吸收流量关注,提升变现水平。
5) 加速技术、内容、管理问题解决。
随着数字化时代的开启,虚拟偶像行业规模不断扩大,越来越多的年轻人加入到虚拟偶像受众群体,各大主流文娱公司在技术和形象设计上不断推陈出新,国家对虚拟数字行业也给予了相应技术支持,另一方面,在元宇宙概念下,在虚拟世界中创造专属身份将成为文娱市场的新潮流。虚拟偶像行业发展潜力较大,赛道异常火热,但技术问题、内容输出问题和管理问题仍需加速解决。
6) 打破次元壁,为用户带来更好的体验。
打破虚拟偶像和现实世界的次元壁,未来虚拟偶像在形象设计上应针对不同群体的偏好进行设计改进,使形象更加符合大众审美;未来虚拟偶像的互动交流实时性和真实性应加以提高,例如使歌曲、舞蹈等作品风格更加多样,能基本满足消费者需求,不断输出优质作品。
7) 规范虚拟偶像管理制度。
在公司和平台管理层面上,虚拟偶像行业应进一步规范管理制度,做到头部idol人设不崩塌,个人虚拟主播专业素质稳定。