1. 引言
改革开放以来,我国人均受教育水平不断提高,中国人力资本储备也由此增加。随着科教兴国、人才强国战略以及义务教育政策的实施,使得越来越多的人更容易接收到教育。但我国教育水平仍然是世界的较低水平。在现阶段发展对人才的竞争越来越激烈的情况下,如果促进我国教育水平的提高就变得尤为重要。
教育水平的增长对于经济的发展和科技进步有明显的促进作用这一点是不争的事实。也正是因为我国正在稳步发展经济和科技,因此对于提高国民教育水平来说是必要的。然而根据我国国情来看,人口素质依旧偏低,而且国土面积虽然很大,但西部地区地势较高、山林交错的特点导致交通不便、人群居住较散等问题也成了导致我国教育水平很低的关键因素。
对于教育水平的研究,大部分学者的研究方向均是以教育水平为自变量去探究其对科技发展水平、经济发展水平等的影响。但是很少有研究针对教育水平为因变量,去探究在各种影响因素的情况下,我国各省份教育水平的情况。本文正是再次背景下运用机器学习回归中一些方法来进行相关研究。
2. 影响因素分析
教育作为一个大众化的服务行业,收到很多因素的直接或间接影响。为了对受教育水平有更有效的分析,结合参考相关文献 [1] 和国家目前经济社会发展的实际情况。从人口、政策、经济、科技水平、服务供给、个人平均水平六大方面进行变量选取。针对以上方面构建概念模型,并分别解释各指标对教育水平的影响作用机理。从而更好的确认选取变量的角度以及是否有充分解释效果。如图1所示。
在人口方面,教育水平的直接体现就是人均受教育年限。在一系列对于人口因素中,男女比例无疑会对教育产生一定影响。部分农村及信息不发达地区依旧有重男轻女的腐朽思想,因此对男生进行教育,而女生则放弃教育。由此出现教育水平的区别,由此不仅说明了男女比例对教育的影响,同时也说明了城乡居住地的影响。城乡直接交通运输的发达程度存在差异,导致了人们接触外界的眼界存在不同。一系列差异最终使城市更倾向于教育投入,而农村部分则更加关注与目前生活温饱情况,对教育忽视度较高。然而也有一部分情况显示,城市人接触到外界之后变得更加放纵从而放弃教育,而农村为了能更好走出去发展而选择加大教育力度。此外人口的自然增长也同样影响着教育水平的变化。而这些影响整体上是正向促进了教育水平的提高还是负向限制了教育的发展,则需要具体数据来进行定量分析。
在经济方面,随着城镇化水平的推进和居民收入的普遍提高,一方面存在人们在满足自身衣食住行的需求之后在教育等方面加大投入,另外一方面同样有人更加注重奢侈的生活而放弃教育的机会。
在政策方面,国家始终在推行科教兴国和人才强国和战略、义务教育、高校扩招政策、经费投入以及教育公平。在诸多大环境的影响下,我国教育水平理应向更好的方向转变。然而根据获得数据显示并没有明显优势变化,则说明还有更大的负向影响。
在科技水平方面,科技的创兴和教育水平的提高往往是双向促进的。随着科技的不断发展,教育所能使用的资源和先进设备越来越多,从而推进这教育的发展。
在服务供给方面,学校数量的增加和专职教师数的增加使得可以同时接受更多人进行教育培养。学校数量的不断增加,各个地区政府针对教育方面的政策以及各种社会公益事业对于教育的重视,使得学校的创办更加简单快捷。而随着教师工资待遇的提升,国家专职教师数也出现了明显的增多。对于教育培养有很大帮助。
综上所述,从每一个方面可能都存在积极或者消极作用,因此需要定量进行分析。
3. 模型介绍
从以上情况可以看出,影响我国教育水平的因素很多,而且涉及到很多方面。因此变量选择是否全面和精确是重要的,本节这分别介绍岭回归、Lasso以及弹性网络的变量选择方法对所给数据处理的优势。
3.1. 岭回归
回归模型的标准化形式为:
。
岭回归是线性回归的正则化 [2] :将等于
的正则化项添加到成本函数中。这使得学习算法
不仅要拟合数据,而且还是模型权重尽可能小。超参数α控制要对模型进行正则化程度。岭回归的成本函数:
。
岭回归的目标是生成一个系数稳定的回归方程。系数稳定和选择好的变量有相似的目标,所以可以使用岭回归来进行变量选择。
条件:1) 剔除系数稳定但绝对值很小的变量。因为岭回归处理的是标准化数据,因此不同系数的数值大小可直接比较。2) 剔除系数不稳定而无预测能力的变量。即趋于0的不稳定系数。3) 剔除一个或多个系数不稳定的变量。用剩下的p个变量建立回归方程。
以上每进行一步就用剩下变量重新拟合模型,然后在进行下一步。
3.2. Lasso回归
Lasso回归是线性回归的另外一种正则化,叫做最小绝对收敛和选择算子回归 [3] 。其本质是用模型系数的绝对值函数作为惩罚因子的最小二乘估计,通过把OLS方法估计得到的系数压缩为0,从而实现变量筛选 [4] 。
成本函数为:
,后项增加项为权重向量的l1范数。
Lasso回归一个重要特点就是它倾向于完全消除掉最不重要的特征的权重。Lasso回归有传统方法的优点,并且有更有效的算法:最小角回归算法 [5] 。以此达到系数收缩和变量选择的目的。
局限:1) 当预测变量个数大于样本数时,最多只能选择样本数个变量;2) 如果有一组变量两两相关性很高,则只能选取其中一个;3) 当样本数大于预测变量数时,如果变量之间高度相关,则Lasso的预测水平并不高 [6] 。
3.3. 弹性网络
弹性网络介于岭回归和Lasso回归的中间地带,是岭回归和Lasso回归的正则化简单混合。成本函数为 [7] :
对于弹性网络算法,只要通过变化将弹性网络方法的解表达成类似于Lasso方法的节,就能利用Lars算法得出弹性网络方法的节。弹性网络回归在自动选择变量的同时还能实现连续收缩,并且具有很好的群组效应,预测能力上更优与Lasso方法 [8] 。
4. 实证分析
4.1. 变量设计
本文重点讨论教育水平的影响因素,参考文献及国内社会实际情况,从人口、政策、科技水平、服务供给、经济五个方面设计了11个预测变量。如表1所示。
注:1) 生师比为统计年鉴中直接数据;2) 学校数为小学以上地区学校总数/地区年末常住人口数;3) 教学质量设计为:当年毕业人数/招生人数。
4.2. 数据来源
文章所有原始数据均来自国家统计局网站上下载,包括2015年到2019年五年内31个省的数据供155例。
文章采用机器学习方法随机抽取70%样本作为测试集,30%为训练集。表2为样本数据详情。
5. 模型估计结果
文章选取了11个变量对教育水平进行分析,但所选取的变量并非都对其有显著影响,且变量之间可能存在多重共线性等问题。因此首先用线性回归做一下多重共线性的检测已经变量是否显著的初步观察。
5.1. 线性回归
根据图2简单线性回归结果,存在五个预测变量的t-检验的p值较大。说明不够显著。分别为:NNBL,KJSP,RJJYXFZB,SSB,ZZJSS。通过计算各个变量的相关系数矩阵特征值已经方差膨胀因子(VIF),如表3。
从表上看,存在两个较小的特征值0.099和0.041,以及一个大于10的方差膨胀因子。由此可以说明选择的预测变量之间是存在多重共线性的。则接下来就需要进行变量的筛选。
5.2. 岭回归筛选
根据第二节所示方法,对原始数据首先进行标准化处理,克服量纲影响。中心标准化即使:
对原始标准化之后的数据选择33个0~1之间的α值使用python中sklearn库中的岭回归方法,获得了随α之变化的各变量系数。如下图3所示。其中系数绝对值小于0.1的当做较小影响因素进行删除,第一次结果显示:NNBL,RJJYXFZB,SSB三个变量被删除;之后再使用删除过数据的新样本数据进行第二次岭回归拟合,如图3右所示,同理显示ZZJSS被删除;接下来继续按照此方法对之后数据再次拟合,结果如图4左所示,同样的删除KJSP。之后进行第四次岭回归拟合,如图4右所示。这次所拟合的结果中系数绝对值均大于0.1,证明均为显著性变量,由此保留如下变量作为岭回归最后筛选结果。
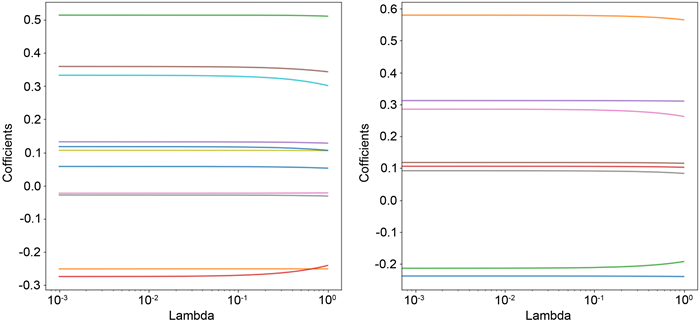
Figure 3. The first and second ridge regression
图3. 第一次、第二次岭回归
Figure 4. The third and fourth ridge regression
图4. 第三次、第四次岭回归
综合四次筛选结果,最终保留了六个变量分别为:RKZZL, CXBL, GJZC, RJKZPSR, XXS, JXZL,之后使用sklearn库中的交叉验证法获得最优的α值为1.0。因此选择α值为1.0的岭回归成本函数对剩余的六个变量做岭回归估计,得到其系数如表4所示。

Table 4. Results of ridge regression variable filtering
表4. 岭回归变量筛选结果
5.3. Lasso回归
进行Lasso回归的第一步同样是对样本进行标准化处理客服量纲影响。之后再1 × 10−5到1 × 102之间选择300个随机数作为拟合Lasso回归的α值。获得系数关于α值得关系如图5所示。可知当α的值在1 × 10−3到1 × 10−2之间时,对Lasso模型的拟合结果系数较多趋近,从而变得稳定。则可初步判断最优的α值应该位于1 × 10−3到1 × 10−2之间。
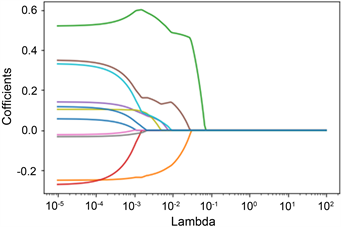
Figure 5. Regression coefficient selection of Lasso
图5. Lasso回归系数选择
在此图的基础上使用交叉验证的方法,获得最好的α值为0.007也刚好在这一区间内。因此选择此α值进行模型拟合并获得筛选结果,即提出变量:NNBL, GJZC, RJJYXFZB, SSB, XXS, ZZJSS。如表5所示为Lasso模型拟合后所选择变量的系数。
Table 5. Results of Lasso regression
表5. Lasso回归结果
5.4. 弹性网络
依照第二节方法,弹性网络为岭回归和Lasso回归的一种简单融合。按照交叉验证的方法最佳l1值为0.5,之后再1 × 10−5,1 × 102上选取100个α的值进行拟合,所得训练集测试集上效果对比如图6所示。黑色位置即为本次选择最佳α的位置,即0.115。
使用l1 = 0.5,α = 0.115来拟合测试集,最终删除了NNBL,GJZC,RJJYXFZB,SSB,XXS,ZZJSS。保留下来的变量如表6所示。
Table 6. Elastic network final choice
表6. 弹性网络最后选择
6. 模型预测效果评价
为了更准确地选取有效模型,应该选择一些合适的评价指标对以上使用的三组模型最终效果做出评价,获得最优的拟合结果。
6.1. 模型预测误差评价标准
1) 误差均方根RMSE
2) 绝对误差平均MAE
3) 相对误差绝对值平均MAPE
其中,T为样本容量、n表示样本外预测数即测试集样本数、
为预测值、
为真实值 [9] 。
6.2. 预测效果评价
利用三次使用的模型,即岭回归、Lasso回归、弹性网络。对教育水平测试集进行预测并对预测效果进行评价,结果如表7所示。
根据以上评价标准可以看出,在三个评价标准的选择下,弹性网络在拟合结果的测试上效果相对最好。其次是岭回归模型,最后是Lasso模型 [10] 。
7. 分析和结论
7.1. 分析与启示
1) 对选择的变量方面:城乡比例代表了城市人数与农村人数的差别,而其影响系数为正则说明了城镇人口更加注重于教育,因此国家城镇化发展对教育的提高有促进作用;人均可支配收入的增加使得人们在教育上的投入也逐渐增大,也由此促进了教育的发展;教学质量的提高,毫无疑问促使更多学生接触的教育更高,同时也是其对更高等的知识的探索的提升;人口增长率的增加使得学校在可接纳的人数范围内并不能完全满足所有增加人口的数量。因此导致了很多人口上学比例相对于总人口数变小。间接影响到了作为预测变量的平均受教育年限;科技水平的增加不仅没有促使教育水平的提升,反倒是存在负相关关系。原因可能是由于科技水平的增加,仅在更加发达的城市凸显出来,而教育的水平全国各个地方的总体变现、并且本次选取的科技方面的影响因素仅为R&D经费投入金额,并不能完全说明该地区科技发展水平是否提升。
2) 对删除变量方面:男女比例并没有对教育水平产生任何影响,就说明当今社会更加的公平,人民的思想也更加进步,任何人都有追求更高教育的权利。国家政策代表量中仅含国家经费投入,而国家对教育最大的措施:科教兴国、人才强国战略及义务教育的影响水平并没有很好地体现在变量上,因此被剔除;人均教育消费占比说明和人均可支配收入的影响存在明显相关性关系,被删除;师生比以及学校数则说明,一个地区学校再多、老师再多都并不能展示这个地区教育水平相较于其他地区有多强,而真正影响到的因素应该是该地区教师所展现出的教学水平,即教学质量更加重要。
7.2. 结论
本文选取的数据为2015到2019年的面板数据作为研究对象,从五个大方面选择了11个影响因素,并且运用岭回归、Lasso回归、弹性网络这三种模型作对比分析,得出以下结论。
1) 模型选择方面:Lasso回归对模型删减相对于岭回归和弹性网络稍弱,岭回归筛选效果合适,但是存在一个自身判断的问题,即在对最小系数做删除时,对于系数默认为零的范围为自身选择。因此最佳模型为弹性网络。
2) 变量选择方面:a) 城乡比例、人均可支配收入和教学质量与教育水平呈正相关关系,其中系数最大的为城乡比例;b) 人口增长率和科技水平对教育水平呈负相关关系。
3) 误差选择方面:针对于测试获得的结果,弹性网络效果最好;岭回归次之;Lasso回归最弱。虽然在训练集上的表现相较于岭回归弱,但将模型应用于训练之外的测试集时,其效果就相对最好。因此弹性网络有较好的外推性。