1. 引言
在现代经济与科技发展的浪潮中,机器学习无疑是最火热的领域。无论是alphaGo战胜了人类世界围棋冠军,还是ChatGPT一夜爆火,都是机器学习在某一领域的深度开发。文本分类也是机器学习领域一个比较热门的方向,是工业界能够实际应用的方向之一,比如将文本分类应用于投诉的自动处理、新闻的自动归类等。无论对于中文或是英文的文本分类,为了精确率的目标,都需要对文本进行预处理。但是,有一些敏感或者涉密行业,它们的数据无法对外提供,而这些行业又确实有相关的需求。本文就是对数据匿名化处理后的文本分类进行研究。
文本的匿名化 [1] [2] 指的是对机器学习中最重要的数据进行处理,将其处理成格式化数据的过程中,消除数据可识别的信息。匿名化的操作,对于个人信息和企业信息的保护和流通都有着非常重要的价值。
2. 相关技术
2.1. FastText
FastText是一种基于深度学习的字符级别的文本分类算法 [3] [4] 。它允许迅速建立和训练词向量模型,以解决文本分类和语义分析的问题。它可以处理不同长度的句子,而且还可以处理拼写错误和语义相似性,这使得它成为自然语言处理领域中被广泛使用的框架之一。FastText将字符串分割为单词,然后将每个单词映射到可以训练的特征向量,最后使用深度神经网络进行分类。FastText最大的优势是可以处理拼写错误、缩写、数字等文本的不规范形式,比传统的NLP方法更快、更容易,并且可以高效处理大型语料库。
国内外对FastText的研究进展一直在不断发展。例如,研究者们正在试图利FastText提供的技术来更好地理解语义和上下文间的关系 [5] 。此外,研究者们还在开发新的方法来改善FastText的性能和加快其训练过程,以实现更高水平的准确性 [6] 。另外,一些研究者正在利用FastText来处理网络语言分析,对社交媒体,短信和评论进行情感分析 [7] ,以及使用词向量进行自然语言生成等等。
2.2. 匿名数据
数据匿名化是指在数据传输及处理过程中,将个人身份识别信息(如姓名、身份证号码)经过特殊处理后,改变其原始形态,使得数据持有者无法识别个人身份信息的一种技术手段。数据匿名化可以减少被盗取的个人信息,防止个人信息泄露,有效提高信息保护的安全性 [8] 。
数据匿名化是一种策略,旨在通过减少数据的可识别性来保护用户的隐私。数据匿名化的常用方法有:
1) 数据混淆:通过添加噪声或者编码技术,使得真实数据变得模糊不清,以此来保护数据的隐私 [9] 。
2) 数据删除:删除不必要的数据,从而减少可识别数据的范围,从而提高信息隐私的安全性。
3) 数据整理:将原始数据转换为只包含统计信息的数据,从而在不影响数据分析的情况下提高信息隐私的安全性。
4) 数据匿名化:使用哈希函数、单向函数或者匿名标识符等技术,取消或替换可识别的数据,从而提高信息隐私的安全性。
2.3. TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency)是一种文本挖掘技术,可以统计一个词语在语料库中出现的次数,以及它在语料库中所占比重,这样从整体上来评估词语的重要性。它的主要思想是,一个词语在一篇文章中出现的次数越多,该词语就越重要,TF-IDF利用这一点,在每篇文章中都为每个词语计算一个权值,这个权值可以用来评价一个词语是否重要。TF-IDF是一种基于词频(Term Frequency)和逆文档频率(Inverse Document Frequency)的统计方法,它可以更好地反映一个文档的特征和主题,提高文本搜索和文档分类的准确性 [2] [10] 。
TF就是指词语在文件中出现的频率,即某个词语在文件中出现的次数除以文件中的词语总数。IDF就是指某个词语的逆文档频率,即某个词语在所有文件出现的概率的倒数。TF-IDF即是TF和IDF的乘积。
3. 材料与方法
本文采用的数据集是一个公开的中文新闻数据集,数据集共包含20万条数据,将其以8:2的比例划分成训练集和测试集。所有数据分为科技、股票、体育、娱乐、时政、社会、教育、财经、家居、游戏、房产、时尚、彩票、星座共14个类别,每一条数据以字符级别进行匿名处理后,数据如下表1所示:

Table 1. Anonymous processing of Chinese text data
表1. 中文文本数据匿名处理
其中,标签代表这条数据的类别,文本是一篇新闻的具体数据。字符集匿名化处理的规则如下:
1) 将所有文本以n_gram为1的滑动窗口进行分词。分词后形成了以字符为单位的一个集合,将集合中的字符按统计频率从低到高排序。
2) 将所有字符进行从0开始的编号,获得一个自然数集合。
3) 按顺序获取用户输入的10个英文字符,使用英文字符替换数字中的每一位,获得一个英文字符组合的集合
4) 将英文字符的集合替换原文本中的中文字符,形成了新的训练和测试数据集。
5) 将数据的标签类别
本文的训练集的数据分布如图1所示:
其中,类别0也就是匿名化前的科技类别数据最多,有38918条数据。类别13数据最少,只有908条数据。
通过对匿名化后的字符编码进行统计,可知所有训练数据中,总共包含不同类型的字符7550个。通过对所有字符进行统计,可得出现率最高的前3个中文字符为:DHFA、JAA、GEI,初步猜测可能是逗号、句号等标点符号。
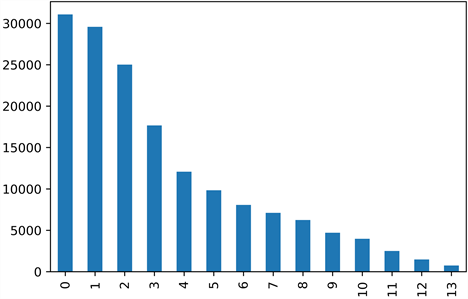
Figure 1. Training set data category distribution
图1. 训练集数据类别分布
4. 实验结果与分析
本文通过对数据进行匿名化后,使用FastText模型与其它模型进行对比实验。在相同的训练集和测试集下,其它模型为了提高其分类的准确性,均在训练前对数据进行TF-IDF的预处理。在四种模型准确率的表现上,FastText模型93.62%,逻辑回归模型90.68%,随机森林模型91.03%,LGBM模型94.42%,结果如图2所示。
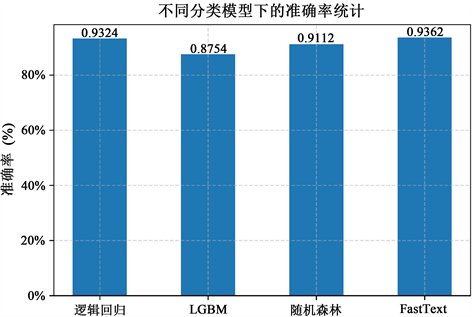
Figure 2. The accuracy of four classification models
图2. 四种分类模型的准确率
除了准确率以外,本文还通过精确率、召回率及F1值来评价不同分类模型的表现,如表2所示。根据实验结果,LGBM算法在各项指标上均优于其它模型。逻辑回归数据表现较差,并且其耗时远高于其它模型。从准确率来看,FastText算法仅次于LGBM,在运行速度上高于其它模型。
Table 2. The results of different models under four evaluation indicators
表2. 不同模型在四种评价指标下的结果
5. 对FastText模型的改进TT-FastText
在中文文本分类中,存在特征稀疏、分词效果不佳、无法处理语义信息、无法处理长文本等。因此,本文基于新闻数据的特征,使用两种方法改进FastText的分类效果:
预先使用TF-IDF对文本进行特征值处理。
将每个文本拆分成标题和内容,分别进行embedding后,提高标题的权重,加权拼接以获得更好的分类效果。
TT-FastText的算法步骤如下:
1) 将文本拆分成标题和内容
2) 分别对标题和内容计算每个词的TF-IDF值
3) 分别对标题和内容计算每个词的FastText向量表示
4) 将每个词的TF-IDF和FastText向量进行加权平均
5) 将标题和内容进行加权平均
经过实验,TT-FastText和FastText准确率如图3所示。

Figure 3. Compared with TT-FastText and FastText accuracy after improvement
图3. 改进后的TT-FastText与FastText准确率比较
TT-FastText与FastText各项指标如表3所示。
针对以上两方面的改进,TT-FastText模型在各项评价指标上均有明显提升,相比逻辑回归、LGBM、随机森林等模型,有更好的分类效果和运行效率。
Table 3. TT-FastText and FastText various indicators
表3. TT-FastText与FastText各项指标
6. 结束语
本文提出了FastText对匿名化数据分类应用的研究意义,说明了匿名化数据的需求与使用场景,然后介绍了目前的技术基础及采用的实验方法。通过处理实验数据,将其完全匿名化,然后使用FastText与逻辑回归、LGBM和随机森林模型进行对比,采用精确率、准确率、召回率和F1值进行评价,最后通过对FastText进行两方面的改进,突显FastText模型对匿名化文本分类问题的性能和效率。FastText模型亦可通过模型融合等方法,进一步提高其准确率。对于非全匿名化的数据,在数据预处理阶段,可通过人工标注等方式,进一步提高其效率。