1. 研究背景和意义
近些年我国致力于推动经济的高速增长,使得金融市场建设愈加完善,在其推动下股票作为金融市场的关键成分受到大范围普及和人们广泛关注,一直以来,准确有效地预测股票的趋势是一个挑战性与经济研究价值并存的课题。
股票时序数据本身就存在着非线性、高信噪比、非平稳的特点,其走势一般很难建模和预测,但这种无规律的波动性背后又隐藏着某种趋势,股价变化是一个随机的复杂动态过程,其波动受到多种复杂因素的控制,并且反映一个行业的发展状况。例如在2020年突发的新冠疫情期间,交通运输行业受到冲击,对中小企业的打击非常大,股票下跌严重,但生物医药,医用材料器械行业受益较大,这些行业的产品需求激增,股票市场呈现乐观形势。近年来,研究人员建立更多的数学模型去预测分析股价的变动规律,其共同特点是基于交易数据创建一些特征指标作为输入,借助特征的历史数据去拟合某种随机的趋势,太过简单的模型无法模拟复杂的股票市场关系,预测结果不佳。随着相关技术的发展,机器学习开始渗透于股票趋势研究领域,效果上得到一定程度改进,但相对依赖数据表示和特征提取。在这种背景下,一些基于深度学习算法的深度神经网络技术在金融投资领域应运而生,由于其高度复杂的非线性系统和强大的捕捉复杂特征能力获得了突破性进展,原因在于股票的涨跌变化受多种特征的互相影响与牵制,而深度神经网络在特征提取方面具备更广泛的潜在预测变量和灵活性,既能够融合多种因素来模拟股市运行又能训练得到可靠的预测结果,在一定周期内有助于维护金融市场稳定、提高投资的热情和水平以及防范金融风险等。
1.1. 研究现状分析
国内外大量研究人员研究了许多股票价格的预测模型,随着大数据技术的发展,数据分析法建立的数学模型可以投入实际应用,股票预测的结果也更具有实际指导意义,根据建模原理可分为以下三类。
1.1.1. 基于统计模型的传统时间序列的股票预测的研究现状
早期预测股票趋势是利用统计模型根据历史数据进行拟合,这类方法所选特征相对简单,预测结果存在一定滞后性但具有相对完善的理论基础和较强的解释能力。
ARIMA [1] 模型是股价预测中的传统模型。在实际应用中,主要是建立时序拟合模型来解释和分析股价波动规律。为了改善ARMA不能对非平稳数据建模的问题很多学者又提出了非平稳自回归移动平均ARIMA模型,之后的相关的研究证实了ARIMA模型在短期股价趋势预测中是相对有效的 [2] 。1986年,分析时间序列的异方差性的GARCH模型被Bollersler [3] 提出后涌现出一些相关研究,对GARCH模型在各个方面提出了改进,例如:GJR、EGARCH和GARCH-M模型等。
然而,随着金融市场的深度发展,量化金融的不断渗透,传统模型受自身线性结构的约束,股价预测精确程度难以突破,在实际情况中由于应用价值不高而被取代。但传统模型的理论完善,通常与机器学习、深度学习算法结合用来解释预测结果 [4] 。
1.1.2. 传统机器学习股票预测模型的研究现状
鉴于股票市场的随机波动性和高度非线性,传统模型受自身假设和建模能力的限制,不能有效地模拟真实的股市,研究开始转向机器学习算法进行股票的趋势预测,如支持向量机(SVM)、人工神经网络(ANN)、XGBOOST、随机森林(Random Forest, RF)以及它们的改进模型。
在SVM的发展中,Lin [5] 利用SVM选择多个因子分别对几个国家的股票市场进行预测;2019年,孙若愚等人 [6] 探讨了SVM和时间序列模型在股价预测中的差异表现。后来,Mizuno [7] 利用ANN对日本股市的股价涨跌进行了二分类预测,发现ANN对股价上涨的预测准确程度明显高于对下跌的预测程度,可以达到60%以上;Kara [8] 分别使用SVM和ANN模型对土耳其股市做实证分析,验证了两种分类器均有较好的性能;但是ANN是一种浅层网络容易陷入局部最小值导致泛化能力被削弱。据此,很多研究人员提出了多种机器学习算法集成的混合模型来综合提高泛化能力,如Kumar M等人 [9] 讨论了随机森林如何在股票市场发挥作用,发现随机森林可以提高泛化性能,避免过拟合问题。同时XGBoost算法的改进应用也十分受欢迎,伯易等人 [10] 于同年已经参考一致性系数对筛选后的指标,利用XGBoost模型预测股价的短期波动规律;王燕等人于2019年验证了经过网格搜索算法优化后的XGBoost模型对短期股价的预测性能有着显著的提升。
1.1.3. 深度神经网络类股票预测模型的研究现状
随着深度学习的发展,深度神经网络可以捕捉数据之间更抽象复杂的关系,股票时序数据的预测的相关研究证实了应用深度神经网络的效果要优于其他模型 [11] [12] 。
目前研究成果十分丰富,Chen W [13] 提出了一个RNN-Boost模型,利用技术指标、情绪特征以及Latent Dirichlet allocation特征来预测股票价格;黄丽明 [14] 提出了加入新闻文本特征的RNN模型来预测股价,为解决RNN的长期依赖问题,LSTM模型设置了三个门来缓解梯度消失问题。李勇 [15] 通过主成分分析处理多个输入特征后,构建了LSTM模型识别股票趋势;Nikou M. [16] 将LSTM模型与ANN、SVR和RF模型进行了比较,证实了LSTM这类深度网络特征捕捉能力优于其他浅层模型;Hossain M.A. [17] 提出了门控循环单元(GRU)模型,证实了LSTM和GRU都是强大的递归网络,在回归预测的准确性上GRU相比LSTM表现得更好更快。另外CNN所具备的平移不变性、权值共享等特点也十分适用于检测金融时序数据中的重要节点,在长时间内,某些影响股价的节点也能被准确检测到,Maqsood H. [18] 提出了一个以价格和情绪分析作为输入的CNN模型,并与线性回归和SVM进行了比较。Hoseinzade E. [19] 利用82种不同的技术指标提出了2D-CNN和3D-CNN两种模型,以上结构使基线算法的预测性能获得一定提升,Selvin等人 [20] 使用CNN,LSTM和RNN模型来预测上市公司的价格并比较它们的表现。
综上,国内外研究者在对股股价预测已经做了大量研究实证,使我受到很大启发,但国内股票市场相对起步晚前期发展缓慢,之前的研究大多是基于国外市场进行的。现在随着我国金融市场不断成熟,研究重心和趋势正在向国内市场偏移,考虑到预测和分析股票数据是一个非线性的、时变的问题,本文选取十支国内沪深300指数股票构建了CNN、RNN以及FFNN三类深度神经网络进行短期的预测和对比分析。
1.2. 论文的主要工作
本文主要工作是构建一套多指标的特征体系,基于加入门控循环单元的深度神经网络模型,分析不同模型对股票的上涨、下跌和震荡趋势的预测差异。
首先,从财经数据包Tushare中获取了金融、电子、钢铁、房地产和交通运输等各个领域的十支股票历史交易数据,行业范围广泛,有利于反应各个模型的预测稳定性。
然后,借助Python股票量化指标库Stockstats和技术分析库TA-Lib去刻画股价走势的特征,在了解各类技术指标的金融学含义后,我们构建了每支股票的数据集并定义了74维初始特征,分析三种深度神经网络的预测结果并用Python仿真训练,实验结果表明加入门控循环单元的GRU-RNN模型相较于CNN和FFNN具有一定的优势。
最后由于初始特征众多且复杂,为进一步提高训练效率和模型精度,我们使用卡法特征选择方法进行特征分析,根据特征重要性评分筛选出准确率最高、特征数量相对更少的集合,从而优化特征空间。本文实验的工作流程如图1所示。
2. 多指标特征体系与股票数据集的构建
2.1. 股票数据集构建
2.1.1. 数据来源
本文原始股票数据集的获取是利用Python的开源财经数据接口包Tushare。Tushare是一个免费、开源的python财经数据接口包,它有以下几个特点和优势:
1) 数据丰富:Tushare提供了各类数据,如股票、基金、期货、数字货币等行情数据,公司财务、基金经理等基本面数据,以及电影票房、龙虎榜、新股上市等其他数据。
2) 获取简单:Tushare提供了SDK开发包和HTTP Restful接口,支持多种语言,如Python,R,Java,C#等1。用户只需简单的代码就可以获取所需的数据。
3) 落地方便:Tushare提供了多种数据储存方式,如Oracle、MySQL,MongoDB、HDF5、CSV
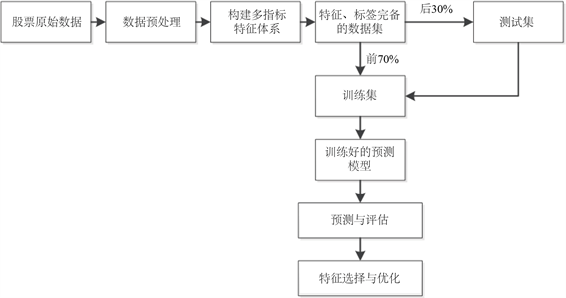
Figure 1. The work flow chart of this paper
图1. 本文工作流程图
等,为数据获取提供了性能保证。
4) 与投研和量化策略无缝对接:Tushare返回的绝大部分的数据格式都是pandas DataFrame类型,非常便于用pandas/NumPy/Matplotlib进行数据分析和可视化。Tushare还提供了实盘交易接口和期权隐含波动率数据等功能,为投资者提供更多的支持。
Tushare是一个优秀的财经数据接口包,它为金融分析人员提供了快速、整洁、和多样的便于分析的数据,使他们更加专注于策略和模型的研究与实现上。我们利用相应的Tushare Pro接口可以获取2014年1月2日到2021年12月31日近7年十支沪深300指数的股票数据(共2096个交易日)。沪深300指数股票是Tushare经典的股票数据服务项目之一,为投资者提供了十分稳定可靠数据,初始下载内容包含每日开盘价(open)、最高价(high)、最低价(low)、收盘价(close)、涨跌幅(pct_chg)、涨跌额(change)、成交量(vol)、成交金额(amount),以宝钢股份(600019.SH)部分数据为例,如下图2所示。
2.1.2. 数据预处理
(一) 数据转换
由于Tushare Pro接口已经十分成熟,数据丰富可靠性强,基本不存在缺失值、异常值、重复值。但是我们所下载的股票数据特征多样复杂,特征之间的量纲存在差异,单位统一难度较大,像成交额和交易量这类特征取值高达成百上千万,而有的特征甚至只取0和1,但并不代表该特征对股票趋势预测的影响力很弱。因此采取无量纲化处理,增加数据的稳定性、模型精度和预测的准确性,常用方法有以下三类:
1) MinMaxScaler标准化,即离差标准化,也称最大最小标准化,是对输入的数据做线性变换,从而将取值范围控制在[0, 1]之间,具体计算公式如下:
(2.1)
2) StandarScaler标准化,也叫Z-score标准化,将数据归一化到均值为0,标准差为1的高斯分布中,实现数据的缩放,其中
为该特征的均值,
为标准差,公式如下:
(2.2)

Figure 2. Baosteel Co., Ltd. (600019.SH) partial historical transaction data chart
图2. 宝钢股份(600019.SH)部分历史交易数据图
3) 归一化,具体计算公式如下:
(2.3)
考虑到股票数据的特征是既有正值又有负值,统一到[0, 1]内会使得不同样本的差异性减弱,所以在模型训练预测过程使用StandarScaler标准化,后续卡方特征选择阶段,最终特征取值需要统一为正值再进一步做出排序,该阶段选取MinMaxScaler标准化方法,考虑到本文的股票数据为日交易数据不存在极端值,为避免每个特征取值范围相差过大造成训练过程不收敛等问题使用最大最小值标准化是十分合理且可行的。
(二) 样本划分
本文按照7:3的比例划分股票数据的训练集和测试集,将2019年9月12日之前1300个交易日的数据作为训练数据集,训练股票预测模型,之后558个交易日作为测试集,以宝钢股份(600019.SH)近五年股价走势为例,绿色部分为训练集数据,红色部分为测试集部分,如图3所示,此股的每日变化相对稳定,在一定有界区域内上下波动,幅度相对平缓存在比较明显的周期性。
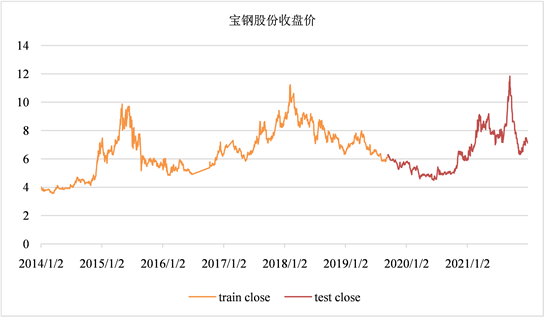
Figure 3. Baosteel Co., Ltd. (600019.SH) training set and test and data map
图3. 宝钢股份(600019.SH)训练集和测试及数据图
2.2. 多指标特征体系
2.2.1. 基本指标
基本指标是指在获取股票数据集时Tushare Pro接口自带初始分析特征,即图2中所下载下来的基本定量指标,这些基本指标可以反映日常交易状况、股价变动趋势,也是目前股票市场最常用的预测指标。
2.2.2. 技术指标
技术指标是我们在基本指标的基础上构造新的统计量,借助python中的股票量化指标库Stockstats和技术分析库TA-Lib进一步计算得到的,TA-Lib涵盖了十种类别的技术指标:重叠指标(趋向指标)、动量指标(流动性指标)、成交量指标(流动性指标)、周期指标、价格指标、波动性指标、形态识别、统计函数、数学变换、数学运算。这里主要涉及趋向指标、流动性指标、波动性指标,汇总结果如下表1所示。
1) 移动平均指标MA
这是一类用来描述价格变动的趋向指标,对某个周期内的收盘价之和做不同类型的平均处理,一般来说有以下三种形式:
简单移动平均SMA是将股票在一定周期内的收盘价进行简单的平均化处理,其中SMA(close,n)t表示在第t天,收盘价的简单移动平均值,移动平均的周期为n天,Ct表示第t天的收盘价。
(2.4)
我们引入指数、加权移动平均指标EMA和WMA,根据赋予权重时的分配的方式不同,计算公式分别如下。
(2.5)
(2.6)
为了对股市的行情进行客观评价,我们选取周期不同的移动平均指标作为特征变量,综合考量选用周期n为5,10,25天的长度的移动平均线,下面以中国国贸(600007.SH)为例绘制25天周期的移动平均曲线如图4所示,可以看出这些指标可以拟合与收盘价的趋势,不可避免存在一定的滞后性。

Figure 4. The 25-day moving average index curve of China International Trade (600007.SH)
图4. 中国国贸(600007.SH) 25天的移动平均指标曲线图
2) 平滑异同移动平均指标MACD
MACD是在指数移动平均指标基础上利用一快一慢EMA进行一系列数学运算处理得到的趋向指标,包括三部分:快速线DIF、信号线DEF和MACD柱(Histogram)。通常计算公式如下,其中EMA(DIF,12)表示DIF的12日均值,柱状值就是快线减慢线,反应两者间的距离,MACD除了可以用来刻画股价的涨跌趋势外还可以用来判断买入卖出的时机和讯号。
(2.7)
(2.8)
(2.9)
3) DMA平行线差指标
DMA指标也可以用来做股价趋势分析,它是基于快慢两条移动平均线的差去研判未来价格走向,下面以求10日、50日为周期的DMA指标为例,借助简单移动平均SMA具体计算公式如下。
(2.10)
4) BOLL布林线指标
BOLL趋向指标引入了“股价通道”和统计学中标准差的概念,它是由上轨线UP、中轨线MD、下轨线DN三部分构成了一条股价通道,通道的宽窄会随着股价的波动而调整,不同周期的BOLL指标计算公式如下,其中SD(close,n)t表示当天的前n天内收盘价的标准差。在上下界的通道内可以保证股价正常运转,如图5所示。
(2.11)
(2.12)
(2.13)
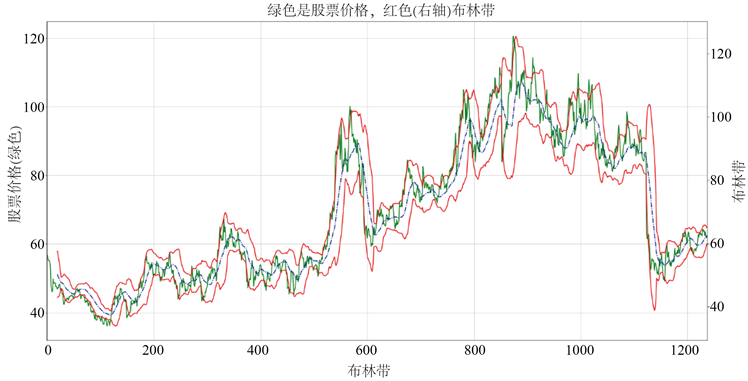
Figure 5. Hang Seng Electronics (600570.SH) Bollinger band chart
图5. 恒生电子(600570.SH)布林带图
5) TRIX、MATRIX三重指数平滑移动平均指标
TRIX趋向指标是在师指数移动平均的基础上,进行三次平滑处理,由此来判断股价长期走势,有助于对未来股价的整体趋势有直观的感受从而节省频繁交易的成本,MATRIX是TRIX的移动平均,具体计算如下。
(2.14)
(2.15)
(2.16)
6) TR、ATR均幅指标
真实波幅TR和平均真实波幅ATR波动性指标可以用来直观感受股价的波动幅度的强烈程度和变化节奏快慢,ATR原理是利用一定周期内股价波动幅度的移动平均值来判断股票买入卖出的时机,当出现极端变化的行情时,波幅上下变动剧烈,该指标只提供变动程度预示新的行情但不提供具体方向,还需结合其他指标一起使用,具体计算公式如下。
(2.17)
(2.18)
7) DMI移动方向指数
DMI指数是根据股票价格在一定周期内上涨和下跌过程中供需关系(买卖双方)的均衡点进行研判,借助供需关系从均衡到失衡的移动方向研究股价趋势的变动情况,它的计算过程相对复杂,涉及到四条线:上升指标线(+DI)、下降指标线(−DI)、平均动向指数线(ADX)和平均动向指数评估线(ADXR)以及相关趋向指标DX,前两条线的计算公式如下,其中+DM代表上升动向、−DM代表下降动向(均为非负数,若计算数值 ≤ 0则统一规定为0)。
(2.19)
(2.20)
(2.21)
(2.22)
若要使得上升下降指标线更具有指导意义,我们需要对其做移动平均处理,则+DI、−DI两条线的走势情况才是判断买卖讯号的重要依据,一般来说当+DI从下往上突破−DI时,是买入的良机;反之,当−DI从下往上突破+DI时是卖出的讯号,计算公式如下。
(2.23)
(2.24)
由计算得到的DI值可进一步计算出动向指数DX指标,DX能够反应股票的活跃程度,DX越高表明该股票变动的能量充足,平均动向指数ADX就是DX在一定周期n天内的简单移动平均,计算公式分别如下。
(2.25)
(2.26)
而ADXR作为平均动向指数评估线,即为ADX的评估数值,计算公式如下,其波动比ADX线平缓很多,根据+DI、−DI相交情况判断了买入卖出时机后,若出现ADX和ADXR交叉讯号,表明行情将会出现急剧变化,是最后出入市场的机会,要及时做出行情判断进行交易。
(2.27)
8) RSI相对强弱指标
RSI流动性指标可以提供股票震荡信息,来衡量价格的优劣性,当股价出现连续暴涨或暴跌的异常变化时会伴随转折点的出现,为分析预测股价未来变化趋势提供重要参考,这里我们选用6天和12天的周期来计算,具体公式如下。
(2.28)
(2.29)
其中,Averagegain(close,n)t表示当天的前n天内上涨的收盘价所增长幅度的均值,Averageloss (close, n)t表示当天的前n天内下跌的收盘价的跌幅均值,我们将RSI取值设定在[0, 100]范围内,如图6以贵州茅台(600519.SH)为例,一般情况下RSI的值在[30, 70]区间内,如果RSI过高超过70则表示股票处于“超买”状态,反之,如果RSI过低小于30则表示股票市场处于“超卖”区域。
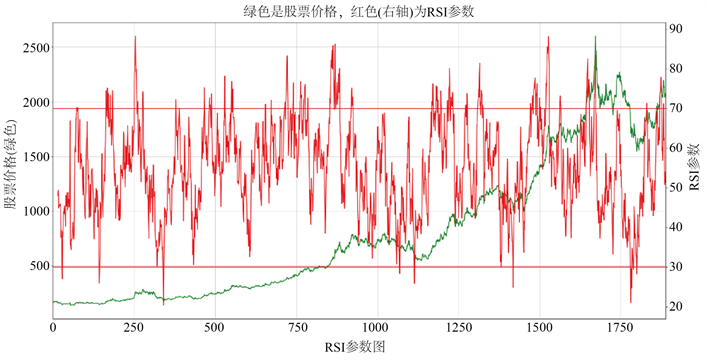
Figure 6. Kweichow Moutai (600519.SH) RSI relative strength index chart
图6. 贵州茅台(600519.SH)的RSI相对强弱指标图
9) WR威廉指标
WR流动性指标也是用摆动点来判断股市的超买超卖现象,以提供股价变动趋势反转的讯号,同样计算前要先确定周期天数,具体公式如下,其中H(close, n)t表示当天的前n日内的最高的股价,L(close, n)t是当天的前n日内最低的收盘价。
(2.30)
一般来说,当WR在[0, 20%]范围内时,表明股市处于超买状态,股价已达到一段时间的最高价可以考虑卖出股票;当WR在[20%, 80%]范围内时,此时股市处于盘整状态一般不考虑买入卖出可以再持股观望一段时间;WR在[80%, 100%]范围内时,股市进入超卖区域,股价接近周期内的最低价此时考虑买入股票。
10) CCI顺势指标
CCI流动性指标主要借助统计学相关知识,定义了股价和一定周期内股价平均区间的差距,体现了平均绝对偏差对预测效果的关键程度,CCI根据股价是否超出高斯分布的范围用来识别超买超卖状态,但与WR、RSI等其他指标不同,CCI的区间为
对股价波动更加敏感,更有利于把握投资时机,具体计算公式如下。
(2.31)
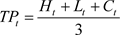 (2.32)
(2.32)
(2.33)
尽管CCI指标没有上下界的限制,但有一个相对参照运行区间,CCI在
时股市处于超买状态,
则为超卖状态,而
区域则为常态震荡区,此时CCI指标没有指导意义,因此CCI技术指标主要为股价的异常波动而设计的。
11) CR中间意愿指标
CR流动性指标的理论基础是中间价在股市价格中最具代表性,认为比中间价高的时候股价能量强,反之则弱。具体计算公式如下,可见CR指标是根据前一天的中间价来比较当天的最高最低价,其中
代表前一天的中间价,P1是n天内上升值的和称为多方强度,P2是n天内下跌值的和成为空方强度,由此测量价格动量的潜能可以提前预判股价的未来走向。
(2.34)
(2.35)
(2.36)
一般来说,当CR低于40时是减仓的好时机,一旦高于300~400要注意适当减仓。我们会同时结合CR和CR的四条移动平均线构成股价的压力带和支撑带共同分析,这里不再做详细描述,后期算法运行时会同时作为输入特征进行预测。
12) VR、MAVR成交量比率
VR流动性指标计算的是固定周期内股价上升日内的成交量与股价下降日内的成交量的比值,目的是研究股价和成交量之间的关系,有助于把握该支股票在股市的买卖人气,具体计算如下。
(2.37)
(2.38)
13) KDJ随机指标
KDJ随机性指标计算原则是基于统计学理论,进一步追踪每日股票收盘价和一定周期内(通常窗口选为9日)的最高、最低价格之间的比例关系,第一阶段计算出该周期内的RSV (未成熟的随机值)再对其进行移动平均计算得到快速随机K值、慢速随机D值和两者的差值J值。
RSV值的计算公式如(3.39)式,Ln、Hn代表当天的前n天内收盘的最低和最高价,K值、D值、J值计算公式如(3.40)~(3.42)所示,当J大于100时,表明股市处于超买状态,小于10的状态则为超卖。可见KDJ指标可以在市场未出现价格涨跌之前预先给出买卖信号,以便全面、快速、准确地把握股市行情,属于短期敏感的技术指标。
(2.39)
(2.40)
(2.41)
(2.42)

Table 1. Technical indicator types and cycle parameter statistics
表1. 技术指标类型及周期参数统计
2.2.3. 构造指标
为了减轻股票市场中时间序列数据的自相关性以及降低噪声,在上述呈现的有技术指标基础上我们又构建了若干特征,关于多指标特征体系中构造的其他特征的详细介绍如下。
(1) 混合移动平均(Mix_MA)
混合移动平均值是将若干个移动平均的算术平均值作为一个新的指标,可以包含更多的股价信息消除多个周期移动平均值之间的相关性,这里我们使用3、6、12和24的移动平均线来计算,公式如下。
(2.43)
(2) 价差(Price_Diff)
价差指标是衡量一段周期内的收盘价波动情况,有助于判断股价的整体变动趋势,有效消除掉一些不重要的噪声数据,这里我们定义每五笔交易之间的价差。
(2.44)
(3) 移动平均之差(MA_Diff)
移动平均之差指标刻画了不同周期的简单移动平均之差,周期大的移动平均线走势相对延迟,这里我们选用周期3天和6天的移动平均值做差。
(2.45)
(4) 平均交易量(Avg_Quantity)
平均交易量反映一段时间内股票的买卖情况能够体现股价市场的活跃度和资金规模,使用平均值更体现市场的整体供求状况,我们选择周期为过去5天的平均交易量。
(2.46)
(5) 量价之比(Quantity_Price)
量价之比指标是通过当天的交易量和收盘价之比计算得到的,具体应用体现在量价关系的各种不同规律中,例如:在上涨趋势早期阶段,如果出现出现价格上涨交易量增多,则可以考虑投资,如果价涨量平则可能只是瞬间的不应贸然买入,如果出现价涨量缩现象则要后续关注成交量,若继续上涨则可追加买入,否则应该考虑适当减仓。
(2.47)
(6) 涨价次数(Ct_Rising)
涨价次数指标用来表示一定交易次数中收盘价不断上升的次数,该指标可以反映一只股票在某个时期内是否值得买进的程度,如果上涨次数多于半数交易次数则表明此时是投资买入的好时机,反之则要慎重卖出。这里我们选择十次交易中的涨价次数。
(2.48)
(7) 中间价格(Middle)
中间价格是一只股票在当天的交易过程中最高价和最低价的平均值,有助于衡量当天股价的一个平均走势,同时计算它的简单移动平均值,这里我们选择14天和20天的中间价格移动平均。
(2.49)
(2.50)
3. 股票趋势预测算法的实现与优化
本章旨在利用十支股票的历史交易数据,预测未来股价的不同走势。利用上述多指标特征体系以克服时间序列数据的自相关和噪声。对于这个预测系统,我们建立了三种类型的深度神经网络模型:前馈神经网络(FFNN)、卷积神经网络(CNN)和加入门控循环单元的循环神经网络(GRU-RNN)进行实验,最后以准确率和科恩系数评价标准进行比较分析。
3.1. 问题定义
我们将股票的趋势预测问题定义为三分类问题,用连续N天的股票历史交易数据去预测未来股价趋势变动情况,我们用上涨、下跌和震荡三种情况来描述股价的变动趋势,生成每条交易数据标签的具体计算流程如表2。
上述标签1,0,−1分别用来代表未来交易价格的上涨、震荡、下跌。当前任务我们定义了50日的时间步长,这里T表示交易日,例如在交易日T50处,我们感兴趣的是预测交易T51的股票价格,将预测窗口内交易的平均价格(Avg_CT1到CT50)与之后交易的价格(CT51)作比判断涨跌情况,从而生成标签。为了减少噪音,我们确定了一个阈值,超过这个阈值,价格变化将被标记为上涨和下降变化,在阈值内的交易价格被记为震荡,这里由于大部分价格都会随时间发生变动,保持完全平稳不变的股价极少,为了确
Table 2. The label setting classification table under different conditions
表2. 不同条件下标签设置分类表
保训练集中三类标签的相对均衡性,我们选择了0.3%的初始阈值来设定标签。
由于股票未来变动情况是由之前多天的交易信息共同决定的,因此我们将当天之前连续多天的股票特征数据作为一个时间窗口输入到不同的深度神经网络中,对训练集和测试集均进行了重塑。例如,如果我们选定时间步长,也称为滑动窗口大小为50,那么在T50这次交易中将对应于该窗口中的所有50次交易,我们将有50*n的数据量(n是特征维数)输入到训练模型中去预测T51日交易的股价趋势变动情况。这种通过滑动窗口划分数据进行训练的方式如下图7。

Figure 7. Sliding window setup diagram for input variables
图7. 输入变量的滑动窗口设置图
上述滑动窗口运行流程中,windowsize代表窗口尺寸也就是时间步长,T代表第T日的股票交易数据,涵盖了所有的输入特征,可以表示为
,由于股票是时间序列数据做预测时要考虑与历史数据的关联,我们实际要输入的是一个二维矩阵,表示为
,标签是股票变动的三种趋势用向量Y来表示。
3.2. 实验设计
3.2.1. FFNN结构设计
深度前馈神经网络是是一类典型的深度神经网络,上述多层感知机、限制玻尔兹曼机、自编码器等都属于前馈神经网络的范畴。而前馈代表所有的信息都是从输入层经过隐藏层一系列计算后单向传递到输出层,而不会出现反馈信息。如果要满足“深度”前馈则至少要设置两层隐藏层,每层网络之间由权重矩阵连接,直观示意图如图8所示。
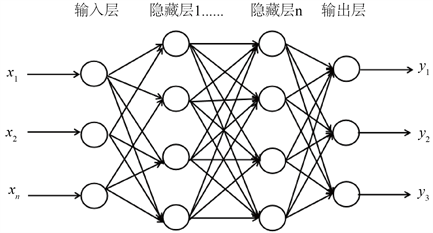
Figure 8. Deep feedforward neural network (FFNN) structure diagram
图8. 深度前馈神经网络(FFNN)结构图
同样
是输入的特征向量,输入层和隐藏层之间代表权重的矩阵中(i, j)位置的元素是wij,yj是输出的预测分类结果,在此基础上加入多个神经元个数不同的隐藏层就演变为深度前馈神经网络,其信息传递过程表达如下。
(3.1)
(3.2)
其中上标l表示不同的隐藏层,f是每个隐藏层对应的激活函数,
是给定的恰当初值,深度前馈神经的网络的本质上是简单的单层叠加,当隐藏层和节点数不断增加就可以表示更为复杂的非线性函数。
前馈深度神经网络FFNN设置了两个全连接的隐藏层,每层都选择ReLU作为激活函数。第一个隐藏层有64个神经元,第二层有32个神经元。输出层计算后输出值后通过Softmax函数进行激活。使用交叉熵作为损失函数,采用Adam优化器对模型参数(权重和偏差)进行优化,FFNN网络结构如图9,每
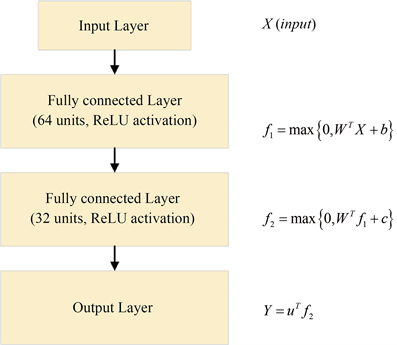
Figure 9. FFNN structure design diagram
图9. FFNN结构设计图
个实例的输入数为滑动窗口大小(默认为50)和输入的特征数量(全部特征为74维)的乘积,同样输出层对每个类输出3个概率,预测类别是由三者中概率最高的决定的。在训练过程中,批量调整到16,为确保收敛提高稳定性学习率设为0.001。将整个训练集按8:2的比例依次分为训练集和验证集,以宝钢股份(600019.SH)为例,前1300个样本数据位于训练集中,而其余558个实例位于验证集中,在FFNN训练过程中训练集和验证集上预测准确率和损失函数变化的情况如图10中(a) (b)所示。
 (a)
(a) (b)
(b)
Figure 10. FFNN training process loss and accuracy change diagram
图10. FFNN训练过程损失和准确率变化图
3.2.2. RNN结构设计
前馈神经的网络从输入层到输出层是全连接结构,输出结果主要取决于当前时刻外部输入并没有关注之前的处理结果,而RNN是一种具有记忆的反馈型结构神经网络,增加了循环神经元可以指向自身,使得神经元节点对先前发生事件具备了短期记忆,提高了对过去时刻的信息存储效率。RNN适用于输入前后有关联、依赖关系或周期变化规律的序列数据,能够有效记忆之前时刻的信息,从而运用到后面时刻的股票趋势预测中,也就是可以使得信息一直不断地保留,其循环处理信息的结构使其在时间序列数据的问题中有明显的优势和广泛的应用,而我们研究的股票数据正是一种金融时序数据,股票价格未来的趋势预测需要挖掘时间序列中的信息寻找特定规律,由此可见RNN在该问题中的应用是十分合适的。
常见的RNN整体结构如图11所示,按照时间顺序展开后就拓展为多层的深度神经网络,如图12所示。其中A是RNN中的一个神经元节点,hinit表示一个初始化的隐藏层状态,当前t时刻训练样本的输入为xt,输出结果为Ot,ht表示此时隐藏层的一个具体状况。具体循环运算流程为:在时刻t处,由于RNN的记忆功能,它会使用当前时刻的输入xt结合隐藏层前一时刻的ht−1对应不同的权重进行运算,经过激活函数映射更新后,输出当前的隐藏层状态ht (会传递到t + 1时刻的循环中作为输入向量)表示为
(3.3)
上式U和W分别的含义是从输入层到隐藏层和递归过程的权重矩阵,值得注意的是,训练过程中所有时刻的权重矩阵是相同的,可以说RNN在时间维度上的权重矩阵是共同享用的,b是隐藏层设定的偏置,当前时刻RNN的输出Ot见公式(3.4),其中V是隐藏层到输出层的权重矩阵,c是输出层的所设置的偏置。

Figure 11. The overall structure of the recurrent neural network (RNN)
图11. 循环神经网络(RNN)整体结构图

Figure 12. The expanded structure diagram of the cyclic neural network (RNN)
图12. 循环神经网络(RNN)展开结构图
(3.4)
但是在时间不断推移的过程中随着序列长度增加的增加,RNN对之前信息的记忆会随着新的输入而不断遗忘,使得模型更依赖后期的数据无法学习到较早的历史数据,即存在长期依赖的问题。在实际情况中,由于时间长度影响反馈的信息,误差经过反馈后消失,参数无法正常更新。据此研究人员又提出了RNN的变种,如LSTM、GRU以及SRU等来改进模型的性能提高学习效果,均有相关研究证明可应用于量化投资领域。本文我们选择引入可以克服长期依赖结构又相对简单的GRU门控循环单元,在实验设计RNN神经网络构造的时候再做详细介绍。
对于RNN存在的长期依赖问题,同时股票数据的预测问题中需要记忆的时间序列相对较长,因此我们对RNN进一步改造,采用门控循环单元(GRU)机制。LSTM和GRU较为类似,都是广泛使用的两种RNN变体,但GRU比LSTM的结构简单,表现为参数变量更少,训练速度更快,同时又保证更好的性能。GRU门控单元的存在为RNN增加了更新门和重置门来保存过滤信息,其中一个神经元具体实现的结构流程如图13所示。
以第t步的前向传播为例,其中式(3.5)根据前面所述,当前时刻的输入和上一时刻状态分别与对应权重点乘,重塑为一维向量得到进入各门前的输入信息xinput式(3.6) zt表示输入门神经元信息,
表示输入门激活函数,Wz,bz是输入门的权重参数和偏置;同理,式(3.7)中rt表示重置门中的神经元信息,Wr该门的权重参数,br是该门的偏置;式(3.8)中
是更新门神经元的信息,
表示元素点乘,由上图可知,上一时刻状态ht−1先与重置门信息做点乘运算,再与当前输入xt汇合,Wh和bh分别是是记忆门的权重和偏置,该门的激活函数设为tanh。最终t时刻的隐藏状态ht由式(3.9)计算可得。
(3.5)
(3.6)
(3.7)
(3.8)
(3.9)
(3.10)
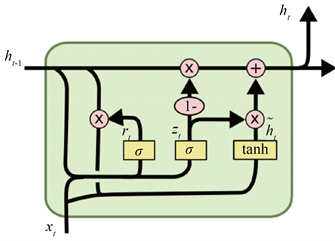
Figure 13. GRU gated recurrent unit structure diagram
图13. GRU门控循环单元结构图
在整个深度循环神经网络中,结构如图14所示,我们设置循环神经元的单元数为150,时间步长为50,输入的大小为特征维数(全部特征为74维)。然后,将上一个时间步的返回值输入稠密层(全连接层),利用tanh激活函数得到logits值,进一步通过Softmax激活函数得到对于每个类的三个概率,最高的概率对应于所预测到的类别。另外设置神经元的丢弃率(dropout rate)为0.5以防止过拟合,利用交叉熵计算损失,对于模型参数的优化问题选用Adam优化器。在训练过程中,批量调整到50,为确保收敛提高稳定性学习率设为0.001,将整个训练集按8:2的比例依次分为训练集和验证集。具体以宝钢股份(600019.SH)为例,前1300个样本数据位于训练集中,而其余558个实例位于验证集中,在GRU-RNN训练过程中训练集和验证集上准确率和损失函数的情况相应曲线如图15中(a) (b)所示。

Figure 14. GRU-RNN structure design diagram
图14. GRU-RNN结构设计图
 (a)
(a)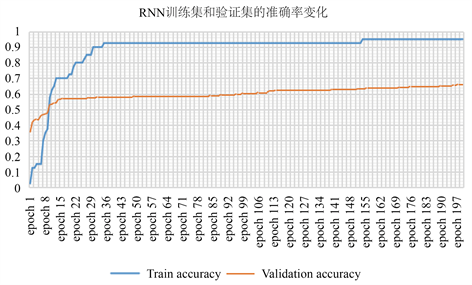 (b)
(b)
Figure 15. GRU-RNN training process loss and accuracy change graph
图15. GRU-RNN训练过程损失和准确率变化图
3.2.3. CNN结构设计
(1) CNN基本结构
卷积神经网络早期在手写数字的系统识别得以应用,此后,CNN经过不断改进发展,性能虽在提升,但实际应用中限制了计算速度和存储空间,现在CNN在保证精度的同时轻量化,近年来不仅在图像识别处理方面还在其他领域中取得了突破性进展。
CNN在网络结构上可添加更多的网络层来映射更复杂的非线性函数,相比于FFNN的优势在于虽然参数的数量显著增加,但是有效避免了过拟合问题,原因是卷积、池化操作有效避免了这一缺陷,二者是CNN的核心和关键组件,因此更适合深度神经网络的体系构建。如图16所示,CNN的基本结构主要各种层构成,卷积层激活后设置一个池化层随后紧连接一个卷积层,卷积池化操作可以进行多次循环,最后就是全连接层和输出层,对每层结构的作用做如下简要介绍。
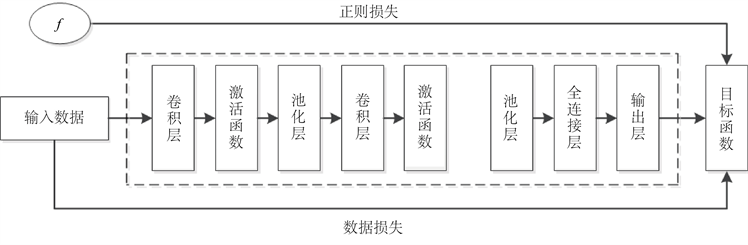
Figure 16. Convolutional Neural Network (CNN) expanded structure diagram
图16. 卷积神经网络(CNN)展开结构图
a) 输入层:CNN可以看作一个自动化特征提取器,模型的输入可以是图像、音频或者文本数据等,本文针对股票数据及各项指标输入层需要设置一个n × n的样本尺寸,CNN训练之前要做数据预处理,如果数据单位不统一或者量级差别太大会使得输入数据中值域大的变量权重过大,而其他维度数据的作用被CNN忽略。
b) 卷积层:在卷积层中主要进行的是卷积运算,在股票预测问题中有助于提取、合并一些有关联的预测指标,卷积层的每一层都可以从输入神经元中选择信息,之后神经元则会被相应的非线性激活函数激活。
一般CNN在提取特征的操作时需要将输入信息转化为二维或三维结构进行训练,当输入股票交易数据时也可设置为一个n × n的二维样本矩阵,在二维卷积运算时,我们需要在输入信息中设定样本矩阵为x,卷积核大小(核函数)为P × Q,不同的核函数尺寸可以提取不同样本信息,输出s是样本x与核函数的卷积,据此,我们对矩阵元素编号,样本矩阵x中(i, j)位置的元素表示为xij,卷积核中(p, q)位置元素记为
,卷积层的偏置向量为b,f表示某种激活函数,卷积过程依照如下公式计算。
(3.11)
这里为了方便说明CNN的卷积运算原理,在此例中为方便计算,我们选用Relu函数激活,偏置向量b = 0,根据公式(3.11)容易得到(3.12)的结果。以此为例,卷积操作的全部特征映射结果见图17,需要注意的是,以上计算的卷积没有涉及卷积核的翻转,实际应在元素乘积之前将卷积核旋转180˚,表达式为 (3.13)但由于很多卷积核已经满足水平垂直对称的要求,与不翻转的结果并无太大误差。
(3.12)
(3.13)
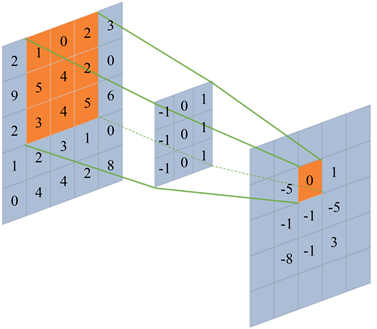
Figure 17. Convolutional Neural Network (CNN) expanded structure diagram
图17. 卷积神经网络(CNN)展开结构图
a) 池化层:池化层又被称为降采样层,该层结构是用来降低对输入的样本大小从而减少之前提取的特征维度。池化方式主要有两种,一是最大池化,二是平均池化,如果不特别说明则使用最大池化方式,两种池化过程的结果如图18所示。
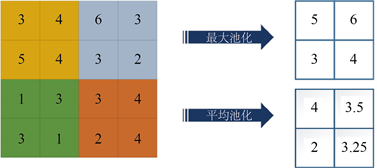
Figure 18. Convolutional Neural Network (CNN) pooling method diagram
图18. 卷积神经网络(CNN)池化方法图
引入池化层来降采样的作用主要包括两方面:一是当CNN中参数过多会导致模型过拟合,池化层可以忽略特征映射中影响不大的样本,简化模型参数,降低计算复杂度同时有效控制了过拟合缺陷;二是池化层可以进一步过滤、提炼有效特征。
b) 全连接层:由于卷积层只抽取了局部相关特征,该层可以对所有的局部特征进行集成和拼接,需要通过权值矩阵对每个局部特征分配不同的权值。通常CNN结构最后会设置两个全连接层,由于目标是输出分类结果,第一个全连接层的作用是整合卷积和池化后的特征,从而映射到标签空间,第二层全连接层通常是Softmax函数,保持该层节点个数与分类目标相一致,最终输出结果是每一类的预测概率。
(2) CNN的工作原理
CNN的工作原理主要有两点。第一点是局部连接,如图19所示,CNN在节点之间的连接上做了稀疏化处理,左图是常见的全连接形式,当输入的是一个n × n的矩阵时每个输出节点的参数就是n2个,相连的隐藏层节点为m个时模型所需训练的参数为mn2,随着隐藏层增加,参数就会成倍增长导致训练过程参数过多而过拟合,右图则是CNN中的局部连接形式,有利于简化模型参数,减少计算量。
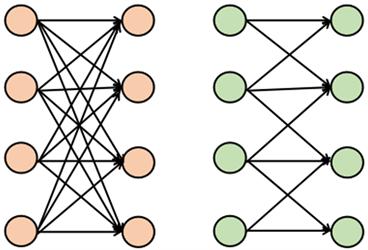
Figure 19. Sparse processing diagram of Convolutional Neural Network (CNN)
图19. 卷积神经网络(CNN)的稀疏化处理图
第二点是权值共享,即便局部连接一定程度上降低了参数数量,但在深度卷积网络中,隐藏层数较多,计算量依然十分庞大,而权值共享保证了每个隐藏层神经元节点的权重参数是一致的,很大程度上加快了CNN训练速度。实际上n × n的权重参数矩阵对应的正是卷积核,在遍历每个局部进行卷积运算,即提取特征时,使用相同的权重,该过程就是权值共享。
为解决该问题我们设置的CNN是由一个输入层、两层卷积和池化层、一个全连接层后紧随一个输出层组成,CNN结构如图20所示。输入层所含信息为特征变量,输入的数量等于一个网格的高(滑动窗口大小)和宽(输入的特征数量,全部特征为74维)的乘积,然后对输入特征进行进一步重构以适应网格的高度和宽度的卷积。由于股票预测问题的数据量不是很大,无需设置十分复杂的网络结构,这里选用两个卷积层结构,第一层使用了36个滤波器,第二层使用72滤波器,对该问题我们设置通道数为1,则滤波器即为卷积核的数目。这两层卷积核尺寸都是2 × 2,stride参数是1,参数padding设置为SAME,激活函数均选择RelU。在池化层中,选择最大池化方法,使用2 × 2尺寸的核和2 × 2的步长,将特征映射的维数降低到输入网格高度和宽度的一半,尽可能多的提取特征信息。接着全连接层将池化层的输出重新重构为一维向量,然后加入一层dropout层,设置神经元的丢弃率(dropout rate)为0.5以防止过拟合,同样使用了Adam优化器。最后,利用交叉熵计算损失并对模型进行训练,有助于提高预测性能,输出层最后将预测分类的结果。整个训练过程的参数在不断调试过程中将批量大小设置为50,为确保收敛提高稳定性学习率设为0.001,epoch设为50,以宝钢股份(600019.SH)为例,训练过程的准确率变化如图21所示。

Figure 21. The accuracy rate change diagram of CNN training process
图21. CNN训练过程准确率变化图
4. 实验与结果分析
4.1. 实验结果
4.1.1. 模型评价指标
本文预测股票的波动情况标签分为三类,上涨、下跌和震荡,属于多分类问题中的三分类问题,因此在评估时需考虑使用模型多分类的性能度量指标,与二分类类似,这里也可以选用准确率Accuracy、召回率Recall、精确率Precision和F1-score来评价模型。对于该三分类的情况,我们可以将其简化为二分类,例如当观察“上涨”这个类别时,将“下跌”和“震荡”看作“上涨”的对立面,即反例,从而构建一个二分类的混淆矩阵去计算“上涨”这个类别TPi、TNi、FPi、FNi,通过这种思想,一共得到三个二分类的混淆矩阵,不同预测的数目结果Ni,j整合在一起如下表3所示。
Table 3. Confusion matrix for three categories
表3. 三分类的混淆矩阵
根据定义,FPi表示原本不是第i类的样本被错误的分到了类i中,TPi表示原本在第i类的样本被正确的分到第i类,FNi表示原本在第i类的样本被错误的分到了类i之外的类别中,TNi表示原本不是第i类的样本被正确的分到了类i之外的类别中,我们计算出每个类别的FP、TP、FN和TN公式如下。
(4.1)
其中FPi又可以看作预测错误的样本以列为单位求和,FNi为预测错误的样本以行为单位求和,当混淆矩阵为正方形时
式成立,记为总的样本数目,此时在micro度量下的准确率、精确度、召回率和F1-score是相等的,所以下面我们用准确率来代表模型的差异,计算公式如下。
(4.2)
另外,我们根据混淆矩阵的特点引入科恩kappa系数来进行一致性检验,从而更准确的衡量多分类的精度,计算公式如下。
(4.3)
其中a0、a1、a2分别为下跌、震荡和上涨的真实样本数,其中b0、b1、b2分别为下跌、震荡和上涨的预测样本数,N为总的样本数量。通常kappa的取值在[−1, 1]内,对于分类问题根据kappa的不同值表示预测结果和真实结果的一致大小,如下表4所示。
Table 4. The meaning of different values of kappa
表4. kappa不同值的含义
4.1.2. 不同模型结果
在本文中,我们考虑到了多指标特征对股票趋势的刻画,包括基本指标、趋向指标、流动性指标、波动性指标和构建的指标,我们选取数10支不同行业的沪深A股的股票数据,分别将全部初始特征放入CNN、GRU-RNN和FFNN三种深度神经网络,预测测结果如表5所示,图22更直观清楚地展示了三种模型的预测结果曲线。
本实验在使用全部74维初始特征作为输入的情况下,使用三种深度神经网络GRU-RNN、CNN和FFNN进行预测比较,由表5结果可以看出,在不同股票数据集的测试集上的准确率大小存在差异,但预测性能的大小关系是存在一定规律的,GRU-RNN模型和CNN模型的准确率和一致性明显优于最基本的前馈深度神经网络FFNN的结构。
从平均水平来看GRU-RNN比CNN效果好的情况要多一些,在所选择的10支股票数据集上GRU-RNN的平均预测准确率为82.70%,而CNN平均预测准确率为81.87%,前者的预测的准确率也相对更高,可见循环神经网络中GRU单元的引入对股票预测能力的提升很有帮助,同时可以发现,CNN虽然常用于在图像识别问题,但在构建出一套完善的特征体系情况下对股票趋势的预测效果也是令人满意的,但是鲁棒性不强,预测性能有起伏,在不同的股票数据上预测效果不够稳定,下面以宝钢股份(600019.SH)训练结果为例绘制AUC-ROC曲线图,如图23所示。
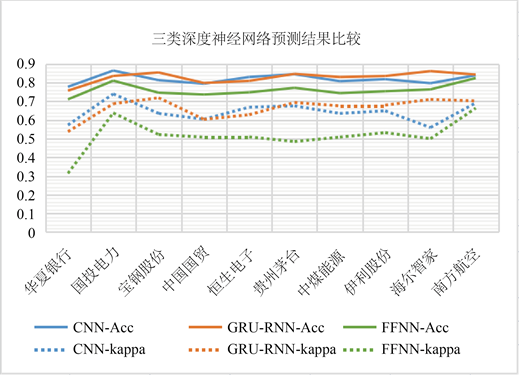
Figure 22. CNN, GRU-RNN and FFNN and the prediction results on different stock data sets
图22. CNN、GRU-RNN和FFNN和在不同股票数据集上的预测结果图
Table 5. The prediction results of ten stocks in different fields under the three models
表5. 十支不同领域股票在三种模型下的预测结果
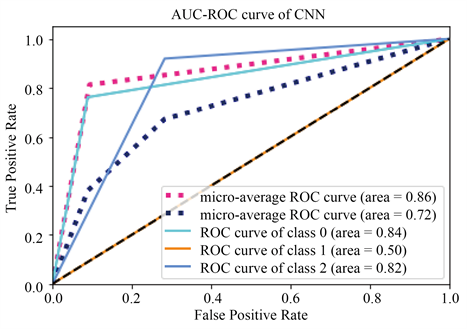

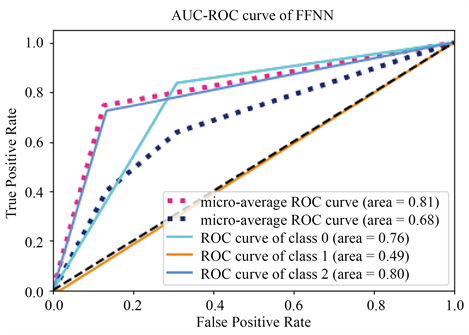
Figure 23. AUC-ROC curves of CNN, GRU-RNN and FFNN on the Baosteel data set
图23. CNN、GRU-RNN和FFNN在宝钢股份数据集上的AUC-ROC曲线图
4.2. 特征分析
4.2.1. 特征重要性排序
由于股票数据本身震荡标签的数量是较少的会导致类别的不均衡,因为股票是时间序列的数据集我们无法通过欠采样或者过采样去改变数据的数量,这样会打乱时间变化的规律,但本文构建多指标特征体系仍然存在发展空间。一般来说,针对图像数、文本、音频这类非结构化的数据而言,深度学习算法是可以自动筛选特征而不需要单独进行特征筛选的,但股票预测问题是使用的是结构化数据,数据量不是很大,但特征体系中指标构建较多容易造成模型预测的负担,降低运算速度,针对这个问题需要进行特征筛选。
为了分析初始的74个特征对于股价趋势的判断能力,方便进一步筛选特征,本文使用卡方特征选择方法对特征进行评分,卡方特征选择是一种基于卡方检验的特征选择方法,它可以用来评估特征和目标变量之间的相关性,从而选择出最有用的特征。卡方特征选择的原理和计算步骤如下:
(1) 原理:卡方检验是一种统计方法,它可以用来检验两个或多个分类变量之间是否独立。如果两个变量独立,那么它们之间没有相关性;如果两个变量不独立,那么它们之间有相关性。卡方检验的原假设是两个变量独立,备择假设是两个变量不独立。卡方检验的统计量是观察值和期望值之间的差异的平方和,差异越大,统计量越大,拒绝原假设的可能性越高。卡方检验的显著性水平是一个预先设定的概率值,用来判断统计量是否达到拒绝原假设的标准。卡方检验的p值是在原假设为真的条件下,观察到统计量大于或等于实际值的概率,p值越小,拒绝原假设的证据越强。
(2) 计算步骤:
a) 对于每一个特征,根据其取值和目标变量的取值,构建一个列联表,记录每个组合出现的频数。
b) 对于每一个特征,根据其列联表,计算每个单元格的期望频数,即行总频数乘以列总频数除以总频数。
c) 对于每一个特征,根据其列联表,计算其卡方统计量,即所有单元格的(观察频数 − 期望频数)的平方除以期望频数的和。
d) 对于每一个特征,根据其自由度(行数减一乘以列数减一)和显著性水平(通常为0.05),查找卡方分布表,得到临界值。
e) 对于每一个特征,比较其卡方统计量和临界值,如果统计量大于临界值,则拒绝原假设,认为该特征和目标变量有相关性;如果统计量小于或等于临界值,则接受原假设,认为该特征和目标变量无相关性。
f) 对于所有特征,根据其卡方统计量进行排序,选择出最大的k个特征作为最终的特征子集。
对不同数据集需要分别做特征筛选,下面任意选取了宝钢股份、恒生电子股票进行展示,它们的特征打分结果如下图24、图25所示,可以看到特征重要性的分布情况在不同数据集上整体一致,同时初始特征空间中有大部分冗余信息对标签的预测相关性不大,宝钢股份中位于重要性排名前10的得分均高于24,分别是boll_ub、ema25、sma25、atr_14、atr、wma25、middle_20_sma、mix_mv_avg、boll、ema10其中有6个趋向指标,2个波动指标以及2个构造的新指标,考虑到其中存在冗余信息,我们从初始特征中剔除掉冗余和无关的特征,筛选出准确率最高的指标集合组成一个相对精简的特征空间。

Figure 24. Baosteel Co., Ltd. (600019.SH) feature importance score map
图24. 宝钢股份(600019.SH)特征重要性得分图
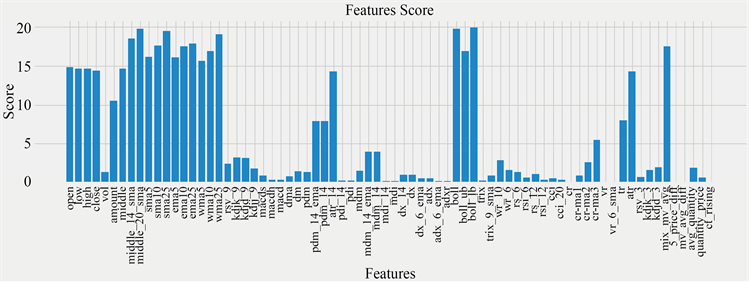
Figure 25. Hang Seng Electronics (600570.SH) feature importance score chart
图25. 恒生电子(600570.SH)特征重要性得分图
4.2.2. 简化特征空间
以宝钢股份(600019.SH)数据集为例,在上述三类深度神经网络里面预测效果最好的GRU-RNN模型中,按照图24所示的特征的重要性排序从1到74,步长为1,不断加入特征,不同特征组合下预测股票变动趋势的准确率变化曲线如图26所示,可以看出在初始阶段,随着特征数量的增加预测的准确率迅速升高,增加幅度明显,随后特征数量在[22, 33]区间内时,准确率呈现波动变化,比较平稳,在此之后,随着特征数量的增加,其相应的预测准确率稳步攀升,达到一个峰值后再加入特征则准确率开始呈现下降趋势,可以确定最优特征空间是由在前66个特征组成的,此时GRU-RNN的预测准确率可高达88.19%,相比全部特征85.43%的准确率有明显提高,AUC-ROC曲线图如图27所示,相比图23中曲线更向左侧偏移,但优化后的特征集合却包含了更少的特征,所以其中有对于预测股票的上涨、震荡和下跌三种形态的关键信息,也说明卡方特征选择能够正确地排序,反应不同特征对趋势预测的重要性。
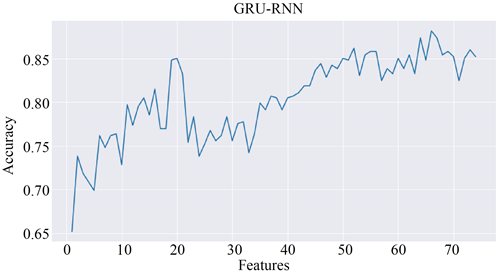
Figure 26. Changes in the accuracy rate of Baosteel Co., Ltd. data predicted by the GRU-RNN model under different feature combinations
图26. 不同特征组合下GRU-RNN模型预测宝钢股份数据准确率变化图

Figure 27. The AUC-ROC curve of the GRU-RNN model after feature selection
图27. 特征选择后GRU-RNN模型的AUC-ROC曲线图
从特征筛选的过程来看,并非把多指标特征体系中所有的初始特征都放在GRU-RNN模型里就能取得最好的效果,也并非特征越多该模型的性能表现越优异,由图26可以看出,前20个特征所取得的准确率和所有初始特征的结果相差无几,因为这些个股的各个指标之间可能互相影响,甚至加剧了信息冗余。
总之,为了提高效率我们要最大程度发挥已有特征的作用,特征空间的构建以精简、有效为原则,基于我们之前对排名靠前特征分析,明显可以看到趋向性指标在股票趋势预测特征中是核心也是关键,在未来的研究当中我们可以从股票变动的趋向变化中构造出更多类似的相关特征。
5. 结论
股票市场的趋势变化多样、复杂且随机,难以找到其中的规律,而股价趋势的预测却是量化投资领域不变的课题,随着大数据人工智能的蓬勃发展,如何通过深度学习算法挖掘其中实时变化的深层规律成为一个充满挑战与机遇的研究方向。针对这个热点问题,我通过查阅文献了解了股票市场的预测方法,学习各类技术指标,系统掌握了一些深度神经网络的框架和原理,重点利用多种技术指标基于三种深度神经网络模型对沪深300指数成分股中数十支不同行业的股票进行预测实现,主要工作内容如下:
1) 针对数据特征获取问题,详细介绍了趋向性、流动性、波动性和随机性等目前常用技术指标的构建过程,以此为基础根据相关金融学理论又衍生出7类新指标,形成了一个完整的多指标特征体系,之后根据数据的特点对其进行预处理,将原始数据进行划分,为模型的训练做准备工作;
2) 建立了CNN、GRU-RNN、FFNN三种深度神经网络来预测股票上涨、下跌和震荡的三种类别,同时进行优化设计,包括使用批量梯度处理、引入Adam优化器对学习率进行指数衰减,改良反向传播算法以及利用Dropout和早停策略来防止过拟合等。实验结果表明引入门控循环单元的GRU-RNN在时序预测上展现了明显的优势,由于解决了长期依赖问题预测性能显著提升;
3) 针对数据降维问题,本文使用了卡方特征选择方法,根据特征评分排序绘制了不同输入特征准确率曲线图,选择出对于预测目标准确率最高的特征集合构成更简单的特征空间,实验证明特征选择对提高预测的精度具有积极的作用。
最后,本文形成了“原始数据处理–多指标特征体系构建–深度学习模型训练–模型预测与优化”的系统框架,使用了多个领域的全新数据集进行实证分析,进一步展现了深度学习算法的优势,但股票市场充满了不确定性,影响因素复杂,本文仅从交易数据本身出发挖掘内在变化规律还停留在理论阶段还有完善空间,希望这一点改进与铺垫可以为将来的实际应用贡献微薄的力量。
尽管本文使用的GRU-RNN模型对于预测股票的变动分类情况的结果是令人满意的,但经过实验分析和总结还存在一些改进空间,归纳为以下几点:
1) 短期内收盘价每天都是在波动的,很少有保持价格不变的情况,仅通过与前一天的价格比值生成的三分类的结果会造成数据集的严重不均衡,因此本文在构造标签时通过设置0.3%的阈值衡量股价的波动程度大小分为三类,后续在模型优化过程可以进一步对阈值参数的寻优操作;
2) 在多指标特征体系中只考虑了大部分交易数据构建出来的特征,是结构化的特征,包含的信息较为单一不够多样化,而影响股市的因素是复杂的,未来应考虑从社会新闻、市场情绪和政府经济政策等文本信息提取更多特征,另外随着音频、视频等非结构化数据的披露,对多尺度大范围特征的深度挖掘将有助于构成更为完善的特征体系;
3) 在深度神经网络的训练过程中,对股票数据针对性较强,每只股票都对应一个训练模型而没有一个适用于所有股票的通用模型,存在可能对一些股票的预测结果很好但对个别股票结果不佳的情况,对每支股票模型单独进行优化无疑是需要很大的工作量,训练一个广泛而通用的高性能预测模型或者训练一个针对某行业领域的模型会是更有价值、有意义的研究方向。