1. 引言
异常检测的主要任务是识别不符合总体数据分布的数据样本。随着深度学习的发展,已经有很多学者将深度学习应用到物体瑕疵检测中,如列车钢轨的缺陷检测、医学影像中各种疾病的检测。但是瑕疵检测任务几乎都存在一个共同的难题:缺陷数据太少了。使用这些稀少的缺陷数据很难利用深度学习训练一个理想的模型,往往都需要进行数据扩充,即通过某些手段增加我们的缺陷数据 [1] 。GAN网络也是实现数据扩充的主流手段,在漫长的研究中,研究者纷纷考虑能不能使用一种无监督的方法来实现缺陷检测 [2] [3] 。
目前主流的深度学习模型是在计算机通用视觉领域发展起来的,先是对行人的检测,后定位车辆或在照片中区分猫和狗。医学影像分析研究固然重要,但与这些研究是存在差异的,其中包括CT和MR图像本身的大小和像素格式的差异,日常照片是2D和彩色的,也包括测试对象大小的差异。虽然疾病辅助检查的目标相对较小,只在图像中占据较小的区域,但人们对日常照片的关注往往是占据图像主要区域的大目标。因此,本文选择人类膝关节MRI图像和深度学习模型进行研究。分析深度学习相关模型在医学MRI图像病变检查中的可行性具有现实意义。
2. 数据及相关原理介绍
2.1. 数据描述
本文选取的MRNet数据集 [4] 来自官网:https://stanfordmlgroup.github.io/,数据包括了2001年1月1日至2012年12月31日期间在斯坦福大学医学中心进行的1370次膝关节MRI检查,平均年龄在38.0岁;且其中569例为女性患者。
该数据集包含1104次异常检查,其中319次交叉韧带撕裂和508次半月板撕裂,且从每次检查中提取矢状面T2 (sagittal plane T2-weighted series),冠状面T1 (coronal plane T1-weighted series)以及轴面PD (axial plane PD-weighted series)三种模态,如图1所示。为了对病例做出正确的决定,放射科医生通常会从不同的平面查看MRI扫描,以便有一个全局的视野。整个数据集分为训练集:1130例,1088名患者、验证集120例、111名患者,如表1所示,在这里将验证集暂且作为测试集开展研究。
MRI [5] 是一种用于放射学的医学成像技术,用于形成身体解剖结构和生理过程的图像。与CT图像非常相似,二者都是“数字图像”,并以不同灰度显示不同结构的解剖和病理的断面图像。与CT一样,磁共振成像也几乎适用于全身各系统的不同疾病,例如肿瘤、炎症、创伤、退行性病变,以及各种先天性疾病等的检查。磁共振成像无骨性伪影,可随意作直接的多方向切层,对颅脑、脊柱和脊髓等的解剖和病变的显示,尤优于CT。核磁共振成像利用磁场产生身体的详细图像。

Table 1. MRNet dataset distribution
表1. MRNet数据集分布
MRI的T1、T2方向切层是用于测量电磁波的物理量,它们可以用作成像数据。基于T1制作的影像被称为“T1加权影像”,在临床工作中缩写为“T1”,T2也是如此。从解剖结构上看,T1成像的整体感觉与“临床成像”的“习惯性配色风格”非常相似,可以看到各种截面解剖图像。在观察病变时,T2的信号与含水量有关。许多病变具有比周围正常组织更强的T2信号,通常表现为明亮。在序列中,可以清楚地看到病变的位置和大小等详细信息。
2.2. 生成式对抗网络原理
生成对抗网络 [6] 是由Good-fellow等人提出的作为训练生成模型的框架,也是实现数据扩充的一种主流手段,学者们一直都在考虑能不能使用一种无监督的方法来实现缺陷检测,2017年AnoGAN模型 [7] 得以提出,它不需要缺陷数据进行训练,而仅使用正常数据训练模型。GAN框架通常涉及两个模型:生成器G和鉴别器D.两个模型同时训练,在训练过程中,鉴别器将数据样本分类为真假,而生成器试图通过生成与真实数据样本相似的假数据样本来“愚弄”D。原始GAN框架同时具有G和D求解相同的值函数。
GAN模型的数学原理 [8] :针对GAN的目标,假定用于生成的噪声分布是
,真实数据分布是
,同时生成器和辨别器分别为G和D,则GAN的目标可以通过如下公式描述:
(1)
这里的公式形式和常见的交叉摘损失函数非常相似,只是没有负号。
表示x来源于真实数据的分布,理想情况下有:
。
如果分类器不是很理想,D(x)就输出越小,
则会越小。
表示噪声经过生成器后生成的样本,
则是分类器认为生成样本属于真实样本的概率,理想情况下这个数值为0,但当性能越不好,
越大,
就会越小。总之,后面两项期望的和越大,分类器识别能力越好。再观察估值函数
前面的
就很明显,而最终的一个目标是求外面的
,G的目标是让V最小;而内部嵌套的
,则代表D是在G给定的情况下,最大化V,即给定生成器,得到识别能力最好的分辨器。
得到了GAN的数学化建模后还有一个问题:假设G和D有足够的容量(没有参数限制),此时问题是不是有解的。分两步来求解:在G固定的情况下,求出最佳的分类器
;然后将最佳分类器带回,证明该问题的有解性。第一步:求最优D展开并对第二项进行换元
(2)
第一行实际上就是原有的
对期望公式的展开。第二行如何得到,一个直观的思路是令
,并进行换元。这里的
实际上代表了由z生成的x的分布,和二者都有联系。完整的推导相对繁琐,按照原文中的符号,令:
,得到积分内的积分函数:
(3)
再对
求一阶导和二阶导,并求出极值点:
(4)
(5)
(6)
是极值点,而由于二阶导恒小于0,该极值点是最大值,且
有且仅有这一个最大值。则有:
(7)
当x变换的时候,对于每个x,y都可以取到相应的唯一最大值,因此等号可以取到,当且仅当
得到的,即:
(8)
第二步:求最优G,令最优生成器为
,此时,
由于D已经固定,转化为根据G求最小值位置。再令:
(9)
这里通过添加分母2,构造了两个KL散度,而KL散度是大于等于0的。并且,假设存在两个分布A和B,且这两个分布的平均分布
,则它们之间的JS散度是A与C的KL散度和B与C的KL散度的二分之一,即:
(10)
因此,有:
(11)
由JS散度的性质,当且仅当
的时候,
取到最小值
。可以发现,此时最优生成器恰好恒为1/2,这和最开始的猜想一致。这也证明了这一优化问题是有解的以及最优分类器的解最终收敛到1/2。在实际应用中,尤其是DNN中,G和D都不能用数学描述,但是解的存在性可以得出在训练当中可以不断逼近最优解来得到近似最优解。
2.3. DCGAN网络原理
DCGAN [9] 也就是深度卷积对抗网络,它的主要是在网络架构上改进了原始GAN,DCGAN的生成器与判别器都利用CNN架构替换了GAN原来的全连接网络,同时DCGAN的生成器网络和判别器网络都去除了CNN当中的池化层,判别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层或者叫转置卷积层。在判别器网络和生成器网络中在每一层之后都是用BN层,实际上这有助于处理初始化不良而导致的一些模型训练过程中出现的问题,能够加快模型的训练速度,提升训练的稳定性。利用
卷积层替换到所有的全连接层。在生成器中除输出层使用Tanh (Sigmoid)激活函数,其余层全部使用ReLu激活函数。在判别器所有层都使用LeakyReLU激活函数。
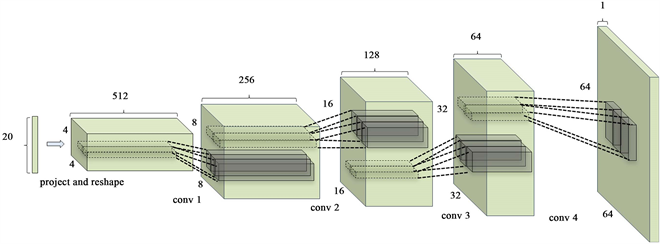
Figure 2. Schematic diagram of generator network for DCGAN
图2. DCGAN的生成器网络原理图
如图2这里的conv实际上是deconv,也就是Pytorch当中的Convtranspose。deconv的前向和conv的后向传播非常相像。如果从后往前地看待这个生成器,就会发现,这是一个非常典型的卷积神经网络,使用conv卷积,特征图逐渐减小而且通道数逐渐增加。且研究者认为使用DNN的GANs应该遵循如下原则:
1) 使用stride来替代pooling,而且不能有全连接层;
2) G和D中都要使用BN;
3) G中所有的层的激活函数都使用ReLU,但是最后一层使用Tanh约束生成图像的范围;
4) D中所有层的激活函数都使用LeakyReLU,但是最后一层使用Sigmoid输出概率。
下采样主要目标是创建与屏幕区域大小相匹配的图像缩略图。例如,比如说在CNN中得池化层或卷积层就是下采样。不过卷积过程导致的图像变小是为了提取特征,而池化下采样是为了降低特征的维度。而上采样实际上就是放大图像,增加图像特征,指的是任何可以让图像变成更高分辨率的技术。在这一点上,可以看到为什么可以使用噪声在网络上生成图像。
2.4. 技术特点分析
通过MRI的数据特点,异常病变数据具有罕见、稀少的特点,因此在模型的大框架上,GAN模型的数据扩充特性使其成为本文研究的第一选择,也可以说GAN模型对于MRI这个特殊数据的异常检测具有较高的适配性。而DCGAN在原模型的技术上进行的改进,加快了模型的训练速度,提升了训练的稳定性。因此选择DCGAN作为模型的内核所在进行MRI影像的缺陷检测研究,并判断其检测的模型效果,分析其在机器辅助医疗诊断方面的可行性及效果。
3. 实验过程
3.1. 实验原理
在生成式对抗网络和DCGAN的原理基础上,本文AnoGAN模型是分两个阶段进行的,如图3所示:首先是训练阶段,然后是测试阶段,训练阶段仅使用正常的数据训练对抗生成网络。如使用训练集中无异常的MRI切片作为本阶段的数据进行训练,也就是正常数据。训练结束后输入一个向量z,生成网络会将z变成正常数据。这个阶段也就是DCGAN [10] [11] 。训练阶段已经训练好GAN网络,后面的测试阶段GAN网络的权重将不再变换。测试阶段:就是要利用训练好的网络来进行缺陷检测。
例如有一些MRI病变影像的切片,记为1,此为缺陷数据,训练时使用正常切片进行训练,记为0。接着要做的就是搜索一个潜在变量并让其生成的影像与正常影像尽可能接近。然后计算生成的G(z)与缺陷切片的损失。
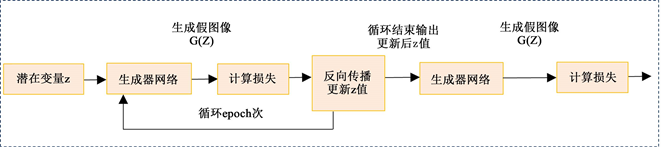
Figure 3. Experimental design flow chart
图3. 实验设计流程图
3.2. 模型框架设计
模型的框架如图4所示,主要分为(a)生成器网络和(b)判别器网络。具体实现如下:先定义一个潜在变量z,然后经过之前训练的好的生成网络,得到假图像G(z),接着G(z)和缺陷数据“1”计算损失,这时候损失往往会比较大,通过不断的更新z值,使损失不断的减少,在程序中设置更新z的次数,如更新5000次后停止,此时将如今的潜在变量z送入生成网络得到的假图像已经和图片“1”非常像了,便将z再次送入生成网络,得到G(z)。
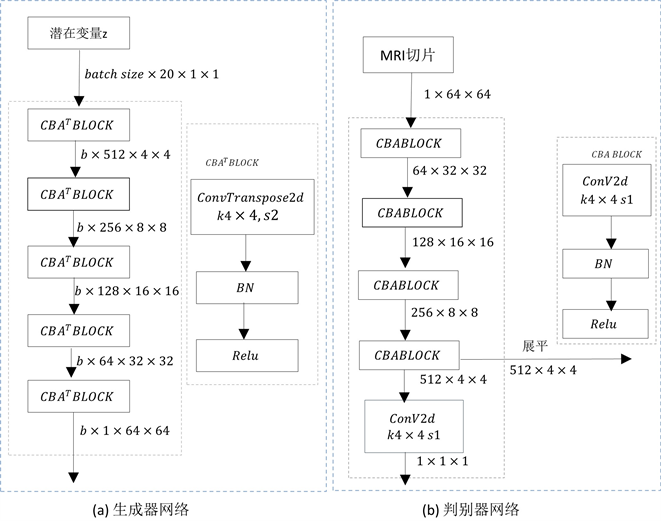
Figure 4. Model network framework diagram
图4. 模型网络框架示图
由于潜在变量z送入的网络是生成正常切片的,尽管通过搜索使G(z)和“1”尽可能相像,但还是存在一定差距,即它们的损失较大,最后就可以计算G(z)和图片1的损失,并将这个损失作为判断是否有缺陷的重要依据。在测试阶段传入的不是缺陷数据,而是正常的数据“0”,此时应用相同的方法搜索潜在变量z,然后将最终的z送入生成网络,得到G(z),最后计算G(z)和图片“0”的损失。由于潜在变量z送入的网络是生成图片“0”的,所以最后生成的G(z)可以和数据“0”很像,它们的损失较小。而实际上生成器和判别器就是一个DCGAN网络。测试阶段的难点就在于定义损失函数来更新z值,此部分的损失,主要分为两部分,即Residual Loss和Discrimination Loss,其中Residual Loss定义:
(12)
上式z表示潜在变量,G(z)表示生成的假图像,x表示输入的测试图片。上式表示生成的假图像和输入图片之间的差距。如果生成的图片越接近x,则R(z)越小。Discrimination Loss定义:
(13)
上式z表示潜在变量,G(z)表示生成的假图像,x表示输入的测试图片。
表示将*通过判别器,然后取判别器某一层的输出结果。这里使用的其实是判别器某层的输出,可以把判别器当作一个特征提取网络,将生成的假图片和测试图片都输入判别器,看它们提取到特征的差异。同样,如果生成的图片越接近x,则D(z)越小。
求得R(z)和D(z)后,定义它们的线性组合作为最终的损失,如下:
(14)
而通常取λ = 0.1来求总的损失。
3.3. 实验设置
设计的6次模拟实验涉及到了对三种不同模态数据,及前交叉韧带(ACL)撕裂与半月板撕裂这两种疾病数据的全面覆盖,如表2所示,对于PD、T2类型的切片实验都从样本中随机抽取6000张影像作为训练集训练模型,测试集则设定为1000张,而T1方向切片数据实验分为交叉韧带撕裂和半月板撕裂,对于训练集的设置分别为3000和6000。模型设置为CONV4代表生成器网络和判别器网络的层数,因而就该数据的缺陷检测来说,模型因此得到的实验结果能够更具说服力。
4. 结果分析
正如前一章的实验设计,通过PyCharm3.7进行实验,主要用到了Torch框架。首先不断调整训练集和测试及的数据比例,进行模型参数调整,以及模型生成器和判别器网络层数的设置,通过观察不同参数及模型生成的效果图及模型损失来调整,最终得出相对最优的模型及参数。
4.1. 模型影像分析
将设计的6次实验,分别在训练好的模型上进行实验。实验一:选取数据PD_ACL训练集6000,测试集1000,迭代300次得到模型生成器输出的影像,如图5(a)所示;选取数据PD_m训练集6000,测试集1000,迭代300次得到模型生成器输出的影像,如图5(b)所示;实验三:选取数据T2_ACL训练集6000,测试集1000,迭代300次得到模型生成器输出的影像,如图5(c)所示;实验四:选取数据T2_m训练集6000,测试集1000,迭代300次得到模型生成器输出的影像,如图5(d)所示;实验五:选取数据T1_ACL训练集3000,测试集1000,迭代300次得到模型生成器输出的影像,如图5(e)所示;实验六:选取数据T1_m训练集6000,测试集1000,迭代300次得到模型生成器输出的影像,如图5(f)所示。可以看出这六次实验得出的结果相对来说是比较好的,这6张模型生成的MRI影像与实际的MRI已十分接近。其中T1由于数据本身的限制,选取了训练集为3000,是其他实验训练集的一半,可以看到e图的效果也很好,所以训练集3000就足以用来训练模型了。
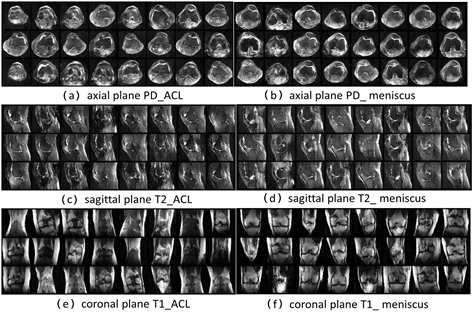
Figure 5. Generator network output image diagram
图5. 生成器网络输出影像示图
4.2. 模型损失分析
4.2.1. 生成器网络实验损失
从图6可以看到模型训练生成器损失迭代的收敛情况还是较为不错的,因此我们的模型的训练效果还是比较好的,这6次实验里,对所设置的训练集的膝关节的MRI切片进行300次训练后可以说模型已达到最优。从图模型训练损失波动图可以看出在D_loss在迭代150次后损失已趋于稳定,在0~0.1之间上下波动,这6次实验整体的一个趋势是前100次迭代波动幅度较大,200次以后,生成器的损失上下波动已趋于平稳。
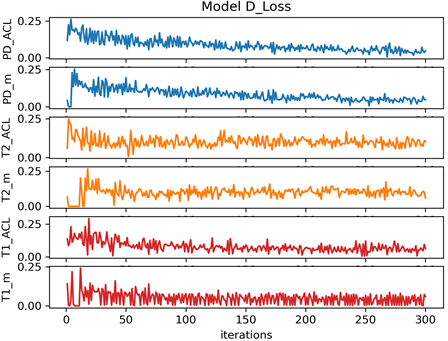
Figure 6. Model generator network experimental loss fluctuation diagram
图6. 模型生成器网络实验损失波动示图
4.2.2. 判别器网络实验损失
从图7可以看到模型训练判别器损失迭代的收敛情况还是较为不错的,因此我们的模型的训练效果还是比较好的,这6次实验里,对所设置的训练集的膝关节的MRI切片进行300次迭代。从图模型训练损失波动图可以看出在G_loss在迭代100次后损失已趋于稳定,在较小的范围之间上下波动,这6次实验整体的一个趋势是前50次迭代波动幅度较大,100次以后,判别器网络的损失已趋于稳定。
其中前交叉韧带撕裂数据的三次实验判别器网络的损失整体偏高,在2~4之间上下波动,且PD_ACL的G_loss随着迭代有一个缓慢向上增长的趋势,而半月板撕裂的三次实验中,判别器损失稳定在1~3之间,特别是T1_m的判别器损失在1.5左右上下波动,趋于平稳。
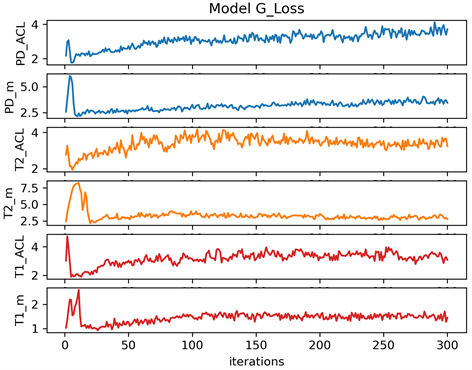
Figure 7. Model discriminator network experimental loss fluctuation diagram
图7. 模型判别器网络实验损失波动示图
4.2.3. 局部异常得分
接着对6次实验的模型测试集随机抽取的16个切片进行训练,通过生成器生成新图像,并计算他们的损失,如图8所示,分别是6次实验中测试集生成的MRI影像切片视图,可以看到随机抽取的切片得到的生成图像相对清晰,ACL数据整体输出的影像与实际的切片相似度更高。
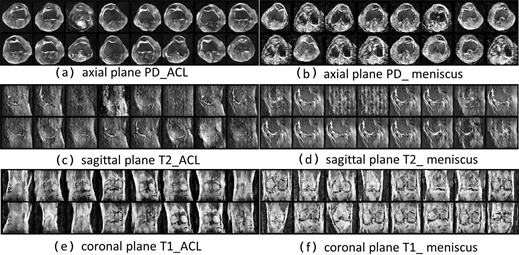
Figure 8. Image representation generated from sample extraction in the test set
图8. 测试集中抽取样本生成的影像示图
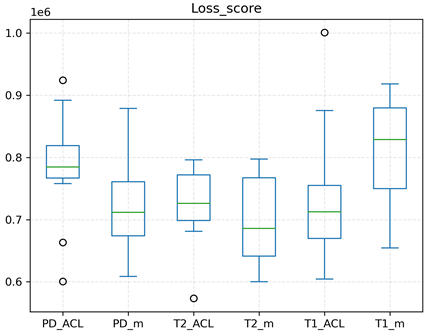
Figure 9. Experimental sample extraction abnormal score box chart
图9. 实验抽取样本异常得分箱线图
图9是6次实验中模型测试集随机抽取的16个切片影像异常得分的数据的损失得分箱线图,可以看到随机抽取的切片测试得到的异常得分较为稳定,只有个别异常值的存在,如在PD_ACL类型数据上进行的实验,整体得分分布的还是比较紧密,就是存在3个异常值,其中PD_m、T2_ACL、T2_m、T1_ACL这四次实验输出的得分相比差异不大,整体分布的范围也相差不大,T2_m相对其他三个较为分散,且T2_ACL含有一个最低的异常值,T1_m是6次实验中异常得分分布整体较高的,这与其数据特征或许有较大关系。总体上看,模型的缺陷检测结果变动幅度还是较为稳定的。
5. 总结
本文主要就MRI医学影像的缺陷检测展开研究,选取官网数据:人体膝盖部位的MRNet,根据数据患病的类型,前交叉韧带(ACL)撕裂与半月板撕裂这两种,将数据集分6次进行实验,分别划分训练集和测试集,在迭代300次以后,对比Ano-GAN模型生成器网络输出的MRI切片影像,观察影像效果;同时分析模型迭代过程生成器网络和判别器网络的损失波动情况来分析模型效果:6次实验之间的损失波动图存在些许差异,但生成器和判别器的损失波动在实验迭代一定次数后皆趋于平稳,同时判别器的损失在数值上整体高于生成器的损失。接着研究6次实验中,分别从测试集随机抽取的16个切片影像在模型训练迭代5000次,所得到的异常得分数据的损失箱线图,可以看到随机抽取的切片测试得到的异常得分较为稳定,只有个别异常值的存在,选取数据的不同得到的效果存在些许差异,但是整体的效果还是比较稳定。
而因为本文主要是针对数据集为人体膝关节前交叉韧带撕裂和半月板损伤的数据集MRnet进行的实验,尽管模型的效果较好,实验设计也相对合理,但是依然存在数据的偶然性,或许在其他的医学MRI影像数据集上的效果有待考究,因而不排除这种特殊情况,即缺乏通用性的探讨,模型可能缺乏对不同操作条件的概括,对于未验证过的数据集,可能存在性能上或多或少的差异。
NOTES
*第一作者。
#通讯作者。