1. 引言
近年来由于网络视频日益扩张、娱乐内容愈加丰富,观众更加注重线上信息的交互,弹幕应运而生。作为一种新兴互动技术,弹幕在年轻群体中逐渐成为潮流,它被广泛应用于各大视频平台,不断发展、更新,成为了新的“网络舆情传播载体”,并开始对用户决策产生重大影响。相较于偏“理智”、“克制”、“守规矩”的传统式文本发言,弹幕作为一种新媒体盛行下的短文本表达,它以“随意”、“有感而发”的实时评论方式表达了大量的对于当前视频用户的即刻思维认知与即时情感倾向,具有更强情感色彩、时效性和研究价值。
弹幕文本出现初期,弹幕文本情感研究多利用短文本情感分析方法,其研究成果也广泛应用于视频推荐。弹幕文本情感分析是指对短小的弹幕文本进行情感判断,通常包括积极、消极和中性三种情感分类。实现短文本情感分析的方法有很多,其中最常见的是基于机器学习的方法,例如SVM、朴素贝叶斯等模型方法。这些方法通常需要大量标注好的训练数据,用来训练模型,从而使其能够自动识别文本中的情感倾向。但基于机器学习的方法不但需要大量的标注好的训练数据,而且在数据质量和特征选择上也有一定的要求。同时,模型的性能和泛化能力也会受到数据分布和样本不平衡等因素的影响。因此,在实际应用中,需要不断优化算法和改进数据处理方法,以提高短文本情感分析的准确性和鲁棒性。随着深度学习的发展,一部分学者将神经网络引入到弹幕的研究中。
另外,还有一些基于规则的方法,例如基于情感词典、否定词和程度副词等。这些方法通常需要手工制定一些规则,来判断文本的情感倾向。基于规则的方法具有可解释性和灵活性的优势,但基于规则的方法需要人工定义和调整规则,受到复杂的语义和上下文信息处理限制,因此对领域和语言的适应性相对较低。
然而,无论是基于机器学习的方法、基于深度学习的方法还是基于规则的方法,弹幕文本情感分析的关键在于特征提取。特征提取是指将文本转化为可供机器学习算法或规则引擎使用的特征向量。常用的特征包括词袋模型、TF-IDF、词向量等,这些特征可以帮助机器学习算法或规则引擎更好地理解文本,并进行情感分类。本文对节目视频的弹幕文本展开深度研究,探究弹幕文本数据结构及文本特征,寻求最优的特征提取模型,提高弹幕文本情感分析准确度。
弹幕具有话题开放性、多元化和情绪化等特点,弹幕文本的情感分析,对于多学科、多领域均具有十分重要的研究价值。海量的弹幕数据中蕴含着用户潜意识的行为认知和丰富的情绪价值,通过对弹幕进行文本挖掘、数据可视化、主题分类以及情感分析,不仅有助于视频作品传播、优化节目设置,而且有助于为网络空间管理提供一些指导方向,例如探究弹幕背后所隐藏的情感倾向和舆情热点,分析追踪网民关注热点,管控热点事件,动态把握网络舆情态势走向,为防范化解网络舆情风险,完善舆情分析机制,构建和谐稳定网络空间做出贡献。
2. 文献回顾
2.1. 弹幕研究
弹幕文本数据的流行,为短文本处理和实时数据处理提供了大量新的文本数据。由于弹幕数据中透露出大量的用户行为认知和情绪价值,众多学者围绕弹幕文本展开相关研究。在研究领域方面,国内有关关研究从传播学领域逐渐发展到教育学、社会学和计算机学科等领域,并朝着跨学科、多学科融合的方向迈进。裴淑红等 [1] 采用文献研究法和案例分析法,从哔哩哔哩弹幕平台的实际经营视角出发,分析五个盈利模式的共性要素,发现经营问题并提出有效建议;贺思萱 [2] 则从利用传播学共情理论,分弹幕表现风格、语言结构及表达方式、传播场景三个维度进行深入探究,从而总结出弹幕共情现象中的独特传播特征;刘梦梦 [3] 以语言模因论为理论依据,通过研究B站弹幕的语言结构、传播途径、流行动因三个方面,分析解读B站弹幕的流行与传播并寻找语言复制与传播的一般规律;过山 [4] 通过深度剖析弹幕文本,发现弹幕技术与动漫产业发展之间的相互融合有助于动漫产业的升级与发展;高百慧 [5] 通过引入弹幕功能,为大学语文课程的在线教学注入新的活力。
2.2. 弹幕文本情感分析
弹幕文本出现初期,弹幕文本情感研究多利用短文本情感分析方法,其研究成果也广泛应用于视频推荐。早期的弹幕文本情感分析方法主要有基于情感词典的方法和基于机器学习的方法。
情感词典的评分赋值是指通过对弹幕文本进行情感词汇的匹配,汇总出情感词条并进行每个文本的分值,就可以得出该文本中的情感倾向。情感词典可通过人工编写、启发式算法来构建,且不同领域的情感词典对文本情感分析结果也有较大的影响。洪庆 [6] 建立了网络弹幕常用词词典;金丹丹 [7] 等人使用融合改进的词林构建多维情感词典和改进情感值计算方法对弹幕内容进行情感分析;王文韬 [8] 融合多种通用词典后构建情感词典交集,对清洗后弹幕文本进行情感分析;付兵 [9] 通过合并现阶段通用情感词典,进行求并集、分词、词性标注、整合、删选情感词等操作完成了弹幕情感词典的创建;郑飏飏 [10] 建立了基于情感词典的分析模型。
基于机器学习的方法需要一定数量的训练数据,并且需要对一定规模的数据进行人工标注、标签化。辛雨璇 [11] 利用贝叶斯分类器将电影短评进行二分类;马梦曦 [12] 针对弹幕文本碎片化、口语化的特征,构建了基于词频–逆文本频率指数(TF-IDF)与支持向量机(SVM)的情感极性分析模型,可达到使用少量有标签样本即可对大量弹幕评论样本进行情感极性分类效果。
随着深度学习的发展,一部分学者将神经网络引入到弹幕的研究中。陈霞 [13] 利用神经网络算法及文本挖掘技术对弹幕文本进行多角度情感分析;陈志刚 [14] 等人针对弹幕文本口语化、网络化、一词多义等特点,引入BERT-wwm预训练模型,利用BiLSTM提取特征,构建了BERT-wwm-BiLSTM模型,有效提高情感分类准确率;曾诚 [15] 提出一种结合ALBERT预训练语言模型与卷积循环神经网络(CRNN)的弹幕文本情感分析模型ALBERT-CRNN;周卫桐等 [16] 对直播平台获取的弹幕文本数据进行清洗后,使用Word2vec训练得到词向量,并构建了CNN、BiLSTM以及改进的BiLSTM-Attention三种深度学习的模型进行实验,对比和评估三种模型得到最优的情感分析模型。
由于弹幕文本具有实时性、灵活性、匿名性、交互性等多种鲜明特征,对弹幕领域的情感分析研究仍有待发展。
3. 数据处理与模型构建
3.1. 研究设计
针对传统评论方式相对延迟、偏“理性”的问题,以实时、灵活的弹幕文本为研究对象,通过文本挖掘、情感分析等多种方式探究弹幕文本与网络舆情之间的潜在关联。首先利用网络爬虫技术搜集网络舆情相关弹幕数据,使用Jieba库实现分词,去除停用词、去除重复项、无效符号、表情、文本符号、机械降重及高频词统计,基于WordCloud库实现词频可视化,并通过SnowNLP库计算网络舆情中弹幕的情感得分,运用LDA模型进行主题词聚类,实现对弹幕的情感分类和主题分析。本研究利用Python编程爬取芒果TV《声生不息·港乐季》节目的视频弹幕信息,对弹幕内容进行文本挖掘、热点话题挖掘及情感分析,以探究这类节目的舆情传播规律和用户情感特征。
3.2. 数据采集
本文的数据来源于《声生不息·港乐季》视频的弹幕文本,首先对芒果TV网页进行页面分析,找到网页发送弹幕的异步请求包,并分析目标网页的URL变化,通过观察分析发现页面遵循的规律,利用变化规律就可以快速实现数据的分段爬取处理。其次对目标网页结构进行分析之后,找到数据的接口,由于网页返回的数据是JSON格式,我们可以利用json.loads对数据进行直接解析,最后进行数据的存储。其中存储的数据内容包含用户名、评论内容等字段。本文通过Python获取了芒果TV网页上《声生不息·港乐季》全十二期的弹幕,得到弹幕数据共499,552条,其中第一期58,624条,第二期32,854条,第三期31,867条,第四期29,911条,第五期33,714条,第六期43,984条,第七期43,015条,第八期36,424条,第九期40,763条,第十期32,429条,第十一期34,885条,第十二期56,698条。
3.3. 数据清洗
通过Python爬取获得大量弹幕文本数据,形成初始的弹幕数据集。首先对收集到的弹幕数据进行预处理,清洗空数据项,去除重复项、无效符号、表情、文本符号以及机械降重。然后,利用哈工大停用词表,同时自设停用词表,形成较为完善的停用词表。最后,根据清洗后的弹幕数据集进行分词。原始弹幕见表1,清洗处理后弹幕见表2。

Table 2. After cleaning the danmu data
表2. 清洗后弹幕数据
对清洗后的弹幕进行分类,加入人物提及标签并进行人物提及次数统计,见图1:
下图图2为与“叶倩文”相关的弹幕,共3817条:
Figure 2. Ye Qianwen related danmu data
图2. 与“叶倩文相关弹幕数据”
3.4. 高频词统计
词频,是指一个词重复出现的次数。TF-IDF是一种常用于词语检索与文本挖掘的加权技术,其优点是能过滤掉一些常见的却无关紧要的词语,同时保留影响整个文本的重要字词。TF-IDF值越大则重要程度越高。
本研究通过TF-IDF得出高频词,表3为排名前十的高频词。
Table 3. Top 10 most frequent words
表3. 排名前十高频词
3.5. WordCloud词云图绘制
本研究通过Python绘制词云图,实现高频词的可视化。分别将每一期、全十二期的弹幕分别绘制成词云图,如图3、图4所示。词云图可以直观地体现出弹幕中的焦点和主题,例如“好听”“厉害”“可爱”“喜欢”“感动”等词语。在弹幕词云图中,还可以发现对节目嘉宾关注的相关词汇,例如“李健”“林子祥”“杨千嬅”等。

Figure 3. Word cloud map of the whole twelve phase
图3. 全十二期词云图

Figure 4. Word cloud map of the eighth phase
图4. 第八期词云图
对个别嘉宾个人弹幕进行词云图绘制,见图5:

Figure 5. Lin Zixiang’s personal word cloud map
图5. 林子祥个人词云图
剔除嘉宾名称后的词云图,见图6:

Figure 6. Word cloud map after removing guest names
图6. 剔除嘉宾名称后的词云图
4. 弹幕文本分析
4.1. LDA主题模型
LDA主题模型是一种文档主题生成模型,该模型假设每篇文章都是以一定概率选择某个主题,然后从这个主题中以一定概率选择一个词语,最后由若干个选出的词语构成。LDA主题模型在概率潜在语义分析的基础上利用狄利克雷分布得到文档主题和词语的先验分布,并通过Gibbs采样来得到文档中的文档–主题分布和主题–词语分布。
利用LDA模型对清洗后弹幕文本进行主题聚类,这里的主题分析实验将全部数据进行清洗、分词,然后建立词典、建立语料库,接着进行LDA模型训练,最后得到结论,输出结果。
本文使用主题一致性coherence作为LDA模型评价标准,主题一致性越高,说明模型效果越好。通过绘制主题数目与主题一致性曲线图(见图7),选择最佳主题数目。
根据观察图7的曲线,可以选择20作为最佳主题数,重新设置主题数运行并得出结果见表。获得20组主题关键词,选取前五组如下表表4:
Table 4. Five groups of subject keywords
表4. 五组主题关键词
同时运用pyLDAvis对LDA模型进行可视化得到各主题中词语的贡献度分布情况,见下图图8、图9。
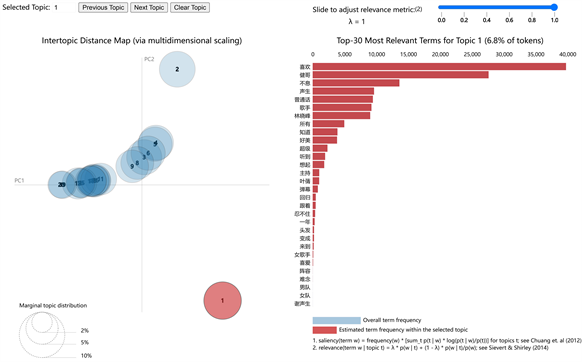
Figure 8. Distribution of contribution degree of the first group of topic words
图8. 第一组主题词语贡献度分布情况
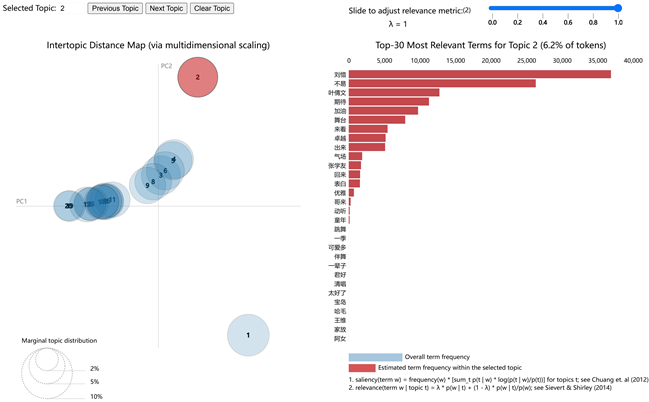
Figure 9. Distribution of contribution degree of the second group of topic words
图9. 第二组主题词语贡献度分布情况
4.2. 基于情感词典SnowNLP情感分析
文本情感分析常用技术常见的文本情感分类方法有两种:一种是基于情感词典的方法,一种是基于机器学习的方法。基于情感词典的方法通常需要建立情感词典,词典里面的词汇越全面准确,情感分析才能越准确。大部分的研究者选择整合多个情感词典来获得更加完备的情感词典,然后结合文本的句法结构对文本进行情感值的计算,根据情感分值判定文本表达的情感倾向。
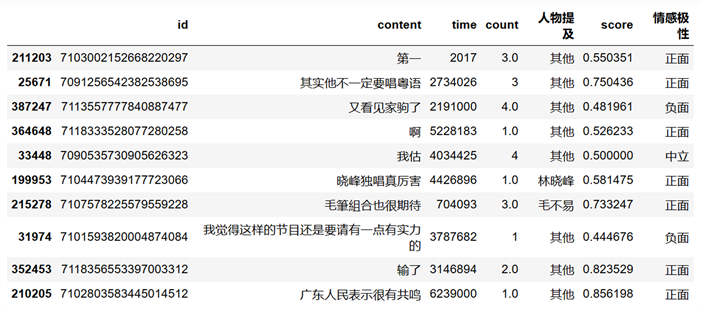
Figure 10. Emotional tendency of 10 random bullet screens
图10. 随机10条弹幕的情感倾向
本文主要运用Python的第三方库SnowNLP库对弹幕文本进行情感计算。情感score表示了弹幕文本积极的概率,越接近0情感越消极,反之,越接近1情感越积极。通过score将弹幕的情感倾向进行正面情感、中立情感和负面情感分类,部分弹幕情感倾向见图10。
绘制弹幕整体情感倾向图,直观了解弹幕的情感变化、走向趋势,见图11。
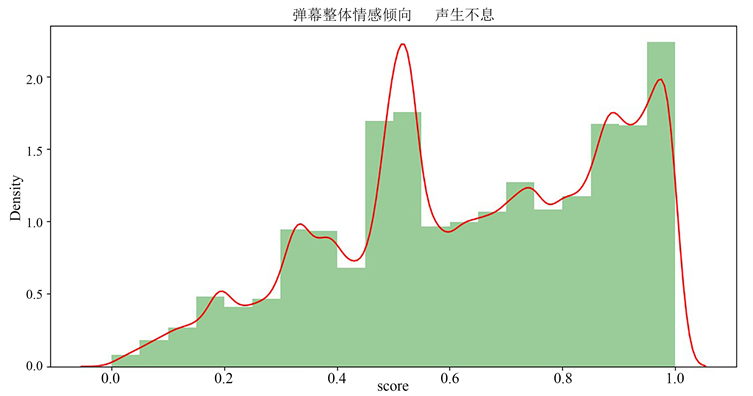
Figure 11. Overall emotional tendency of bullet screen
图11. 弹幕整体情感倾向图
同时对各个嘉宾个人的弹幕进行情感计算,得出各个嘉宾的情感得分与情感分布,可以更加清晰观众对于嘉宾的喜爱程度,见表5与图12。
将弹幕情感得分划分为两类,分别为积极类(得分在0.8以上)和消极类(得分在0.3以下),筛选出两大类分别进行分词。同样通过建立两大类别词典,建立两大类别语料库,其次,分别对两大类别弹幕进行LDA模型训练。与上一LDA实验结果进行对比讨论,有助于挖掘出观众情感产生的原因。
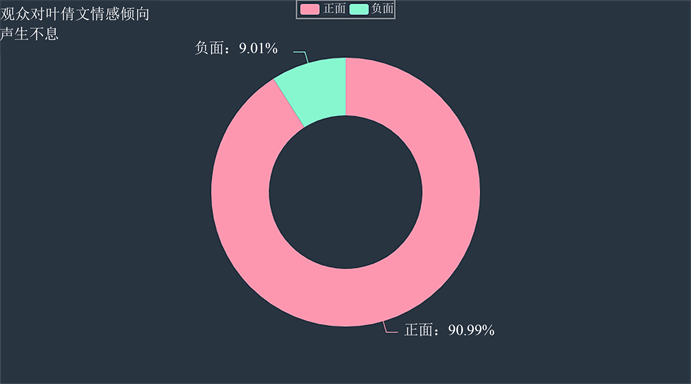
Figure 12. Audience’s emotional tendency distribution towards Ye Qianwen
图12. 观众对叶倩文的情感倾向分布
5. 总结
本文对弹幕文本研究进行了梳理,基于文本挖掘技术对节目视频弹幕进行深层数据分析,爬取弹幕,利用TF-IDF、WordCloud等工具进行高频词、词云图可视化,通过LDA模型对弹幕进行主题词分析以及利用进行SnowNLP完成弹幕情感倾向分析,深入探究弹幕文本大数据背后隐含的深层信息。
如今,国内关于弹幕文本的研究逐渐成为热门趋势,有关弹幕的情感分析、关键词识别等成为研究重点。弹幕中若出现低俗语言、敏感词汇、负面舆情信息,将导致弹幕氛围乌烟瘴气、负面情绪渲染,这不仅仅不利于弹幕文化发展、影响用户体验,而且有碍于弹幕用户实现文化认同,更有碍于动态把握网络舆情态势走向。通过对弹幕中的某些关键词进行适当屏蔽,建立敏感词识别系统监测,可以有效避免过多极端弹幕评论信息瀑布现象,可以有效减少用户发布负面情感弹幕的羊群效应,可以极大降低网络暴力发生概率,可以规范新媒体背景下的网络信息管理,这也是接下来弹幕研究的一大方向。
NOTES
*第一作者。
#通讯作者。